How to set up human annotation?
The Maxim platform allows you to integrate your human annotation pipeline alongside other forms of auto evaluation throughout the development lifecycle. Add human evaluators to test runs using the following steps:1
Creating human evaluators
Add instructions, score type and pass criteria.
2
Select evaluators for test runs
Switch these on while configuring test run for a Prompt or HTTP endpoint.
3
Configure evaluation settings
Choose method of annotation, add general instructions and emails of raters if applicable and configure sampling rate.
4
Collect ratings
Based on method chosen, annotators can add their ratings on the run report or external dashboard link sent on their email.
5
Review rating results
As a part of the test report, you can view status of rater inputs, rating details and add corrected outputs to dataset.
Create Human Evaluators
Create custom human evaluators with specific criteria for rating. You can add instructions that will be sent alongside the evaluator so that human annotators or subject matter experts are aware of the logic for rating. You can also define the evaluation score type and pass criteria.
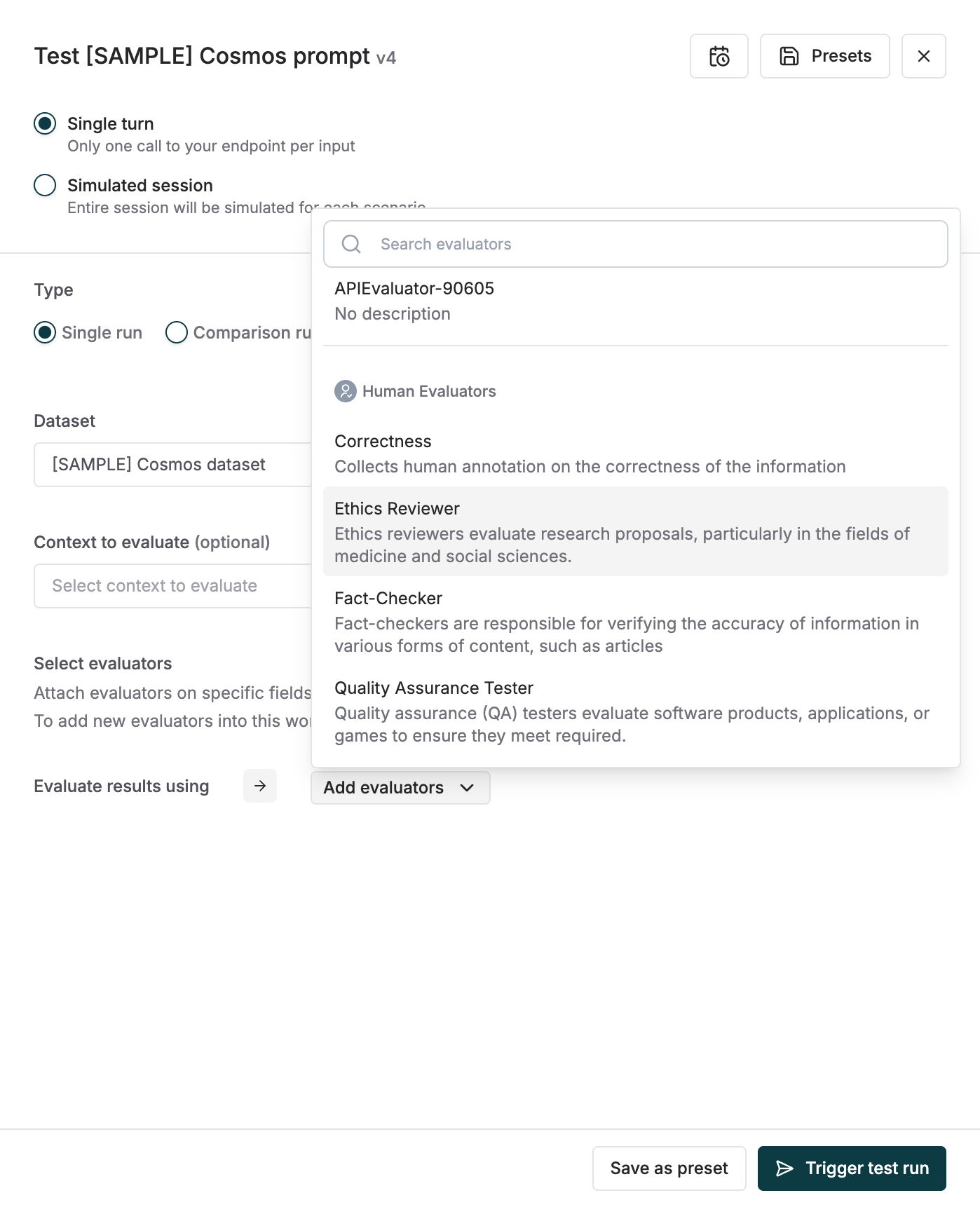
Select Human Evaluators While Triggering a Test Run
On the test run configuration panel for Prompt (or HTTP endpoint), you can switch on the relevant human evaluators from the list. When you click on theTrigger test run button, if any human evaluators were chosen, you will see a popover to set up the human evaluation.
Set Up Human Evaluation for This Run
The human evaluation set requires the following choices- Method
- Annotate on report - Columns will be added to existing report for all editors to add ratings
- Send via email - People within or outside your organization can submit ratings. The link sent is accessible separately and does not need a paid seat on your Maxim organization.
- If you choose to send evaluation requests via email, you need to provide the emails of the raters and instructions to be sent.
- For email based evaluation requests to SMEs or external annotators, we make it easy to send only required entries using a sampling rate. Sampling rate can be defined in 2 ways:
- Percentage of total entries - This is relevant for large datasets where in it’s not possible to manually rate all entries
- Custom logic - This helps send entries of a particular type to raters. Eg. Ratings which have a low score on the Bias metric (auto eval). By defining these rules, you can make sure to use your SME’s time on the most relevant cases.
- Use the dropdown to select any columns from the dataset. The selected fields will be displayed on the Human Evaluation dashboard and included in the evaluation emails sent to raters.

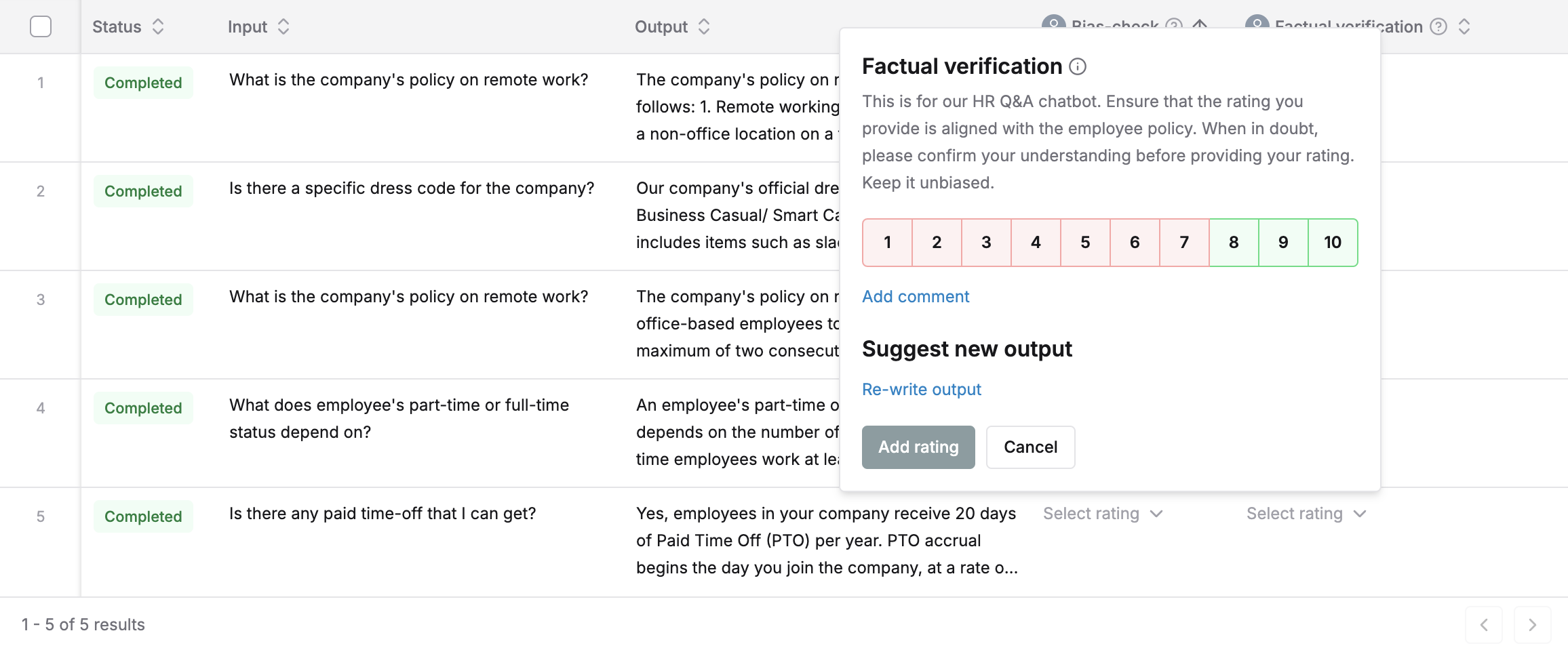
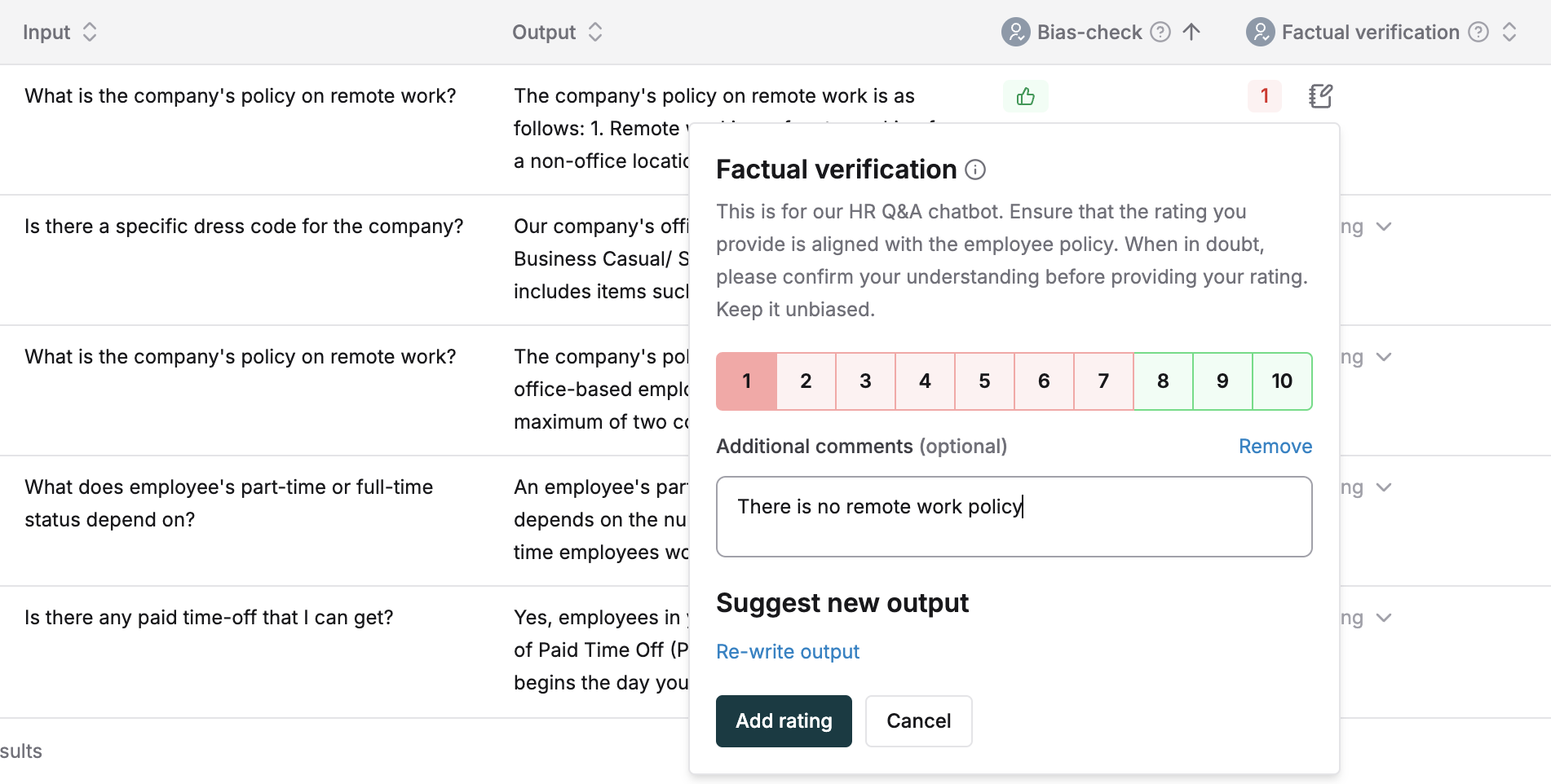
Collect Ratings via Test Report Columns
All editors can add human annotations to the test report directly. Clicking onselect rating button in the relevant evaluator column. A popover will show with all the evaluators that need ratings. Add comments for each rating. In case the output is not upto the mark, submit a re-written output.
Collect Ratings via Email
On completion of the test run, emails are sent to all raters provided during set up. This email will contain the requester name and instructions along with the link to the rater dashboard.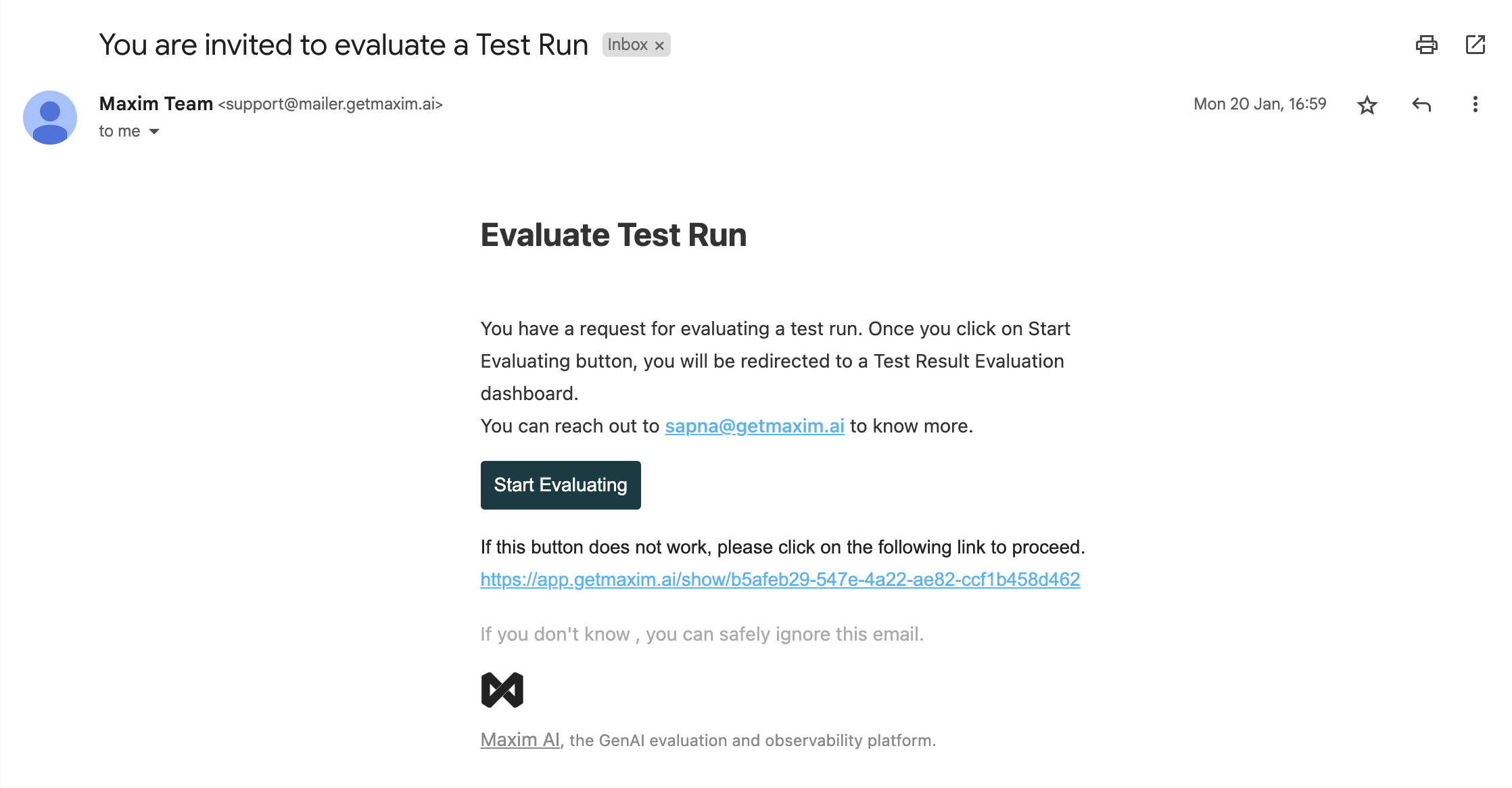
The human rater external dashboard is accessible externally without a paid slot on Maxim.
Pending to In-progress on the test run summary.
Human raters can go through the query, retrieved context, output and expected output (if applicable) for each entry and then provide their ratings for each evaluation metric. They can also add comments or re-write the output for a particular entry. On completion of a rating for a particular entry they can save and proceed and these values will start reflecting on the Maxim test run report.
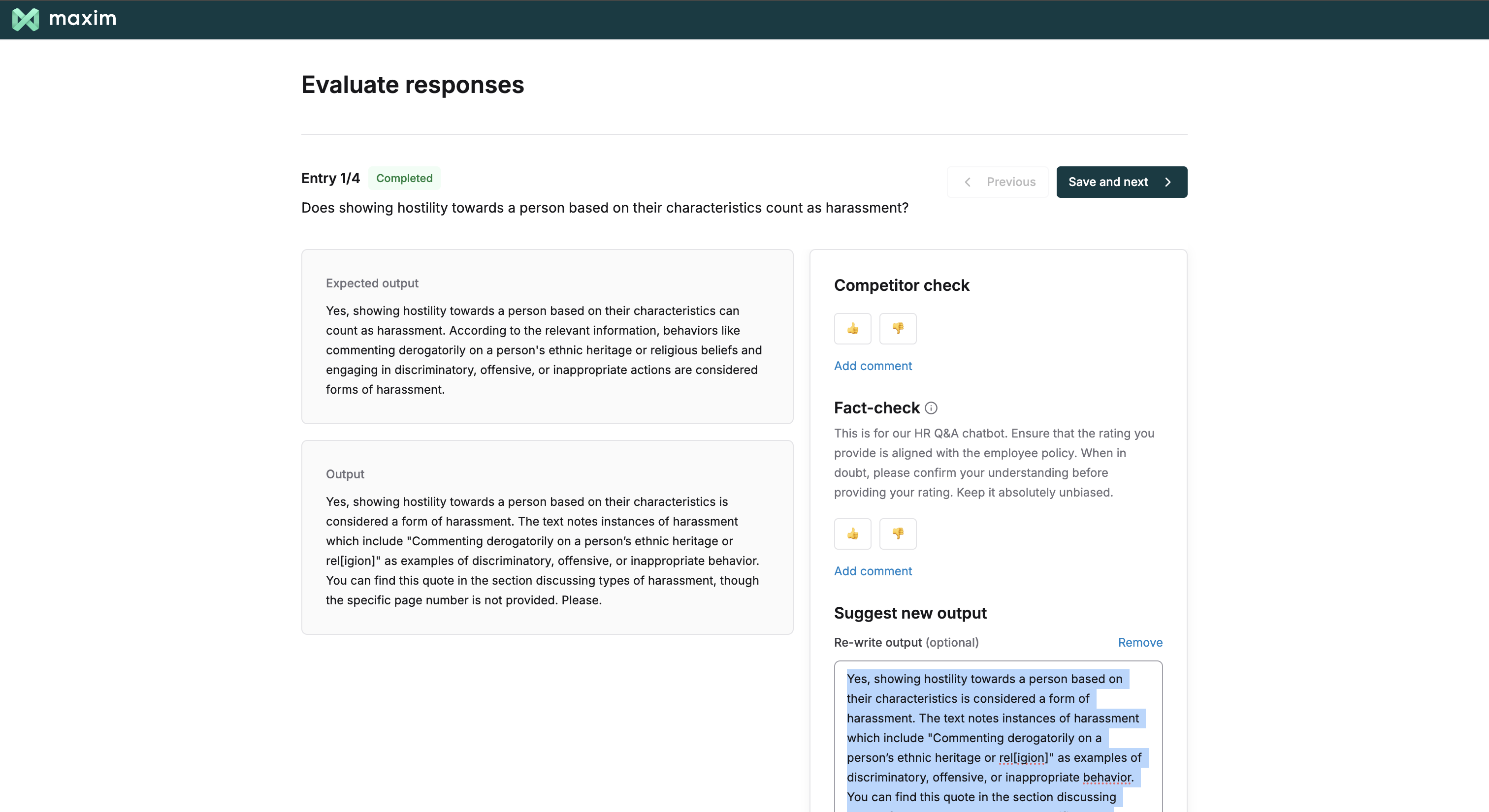
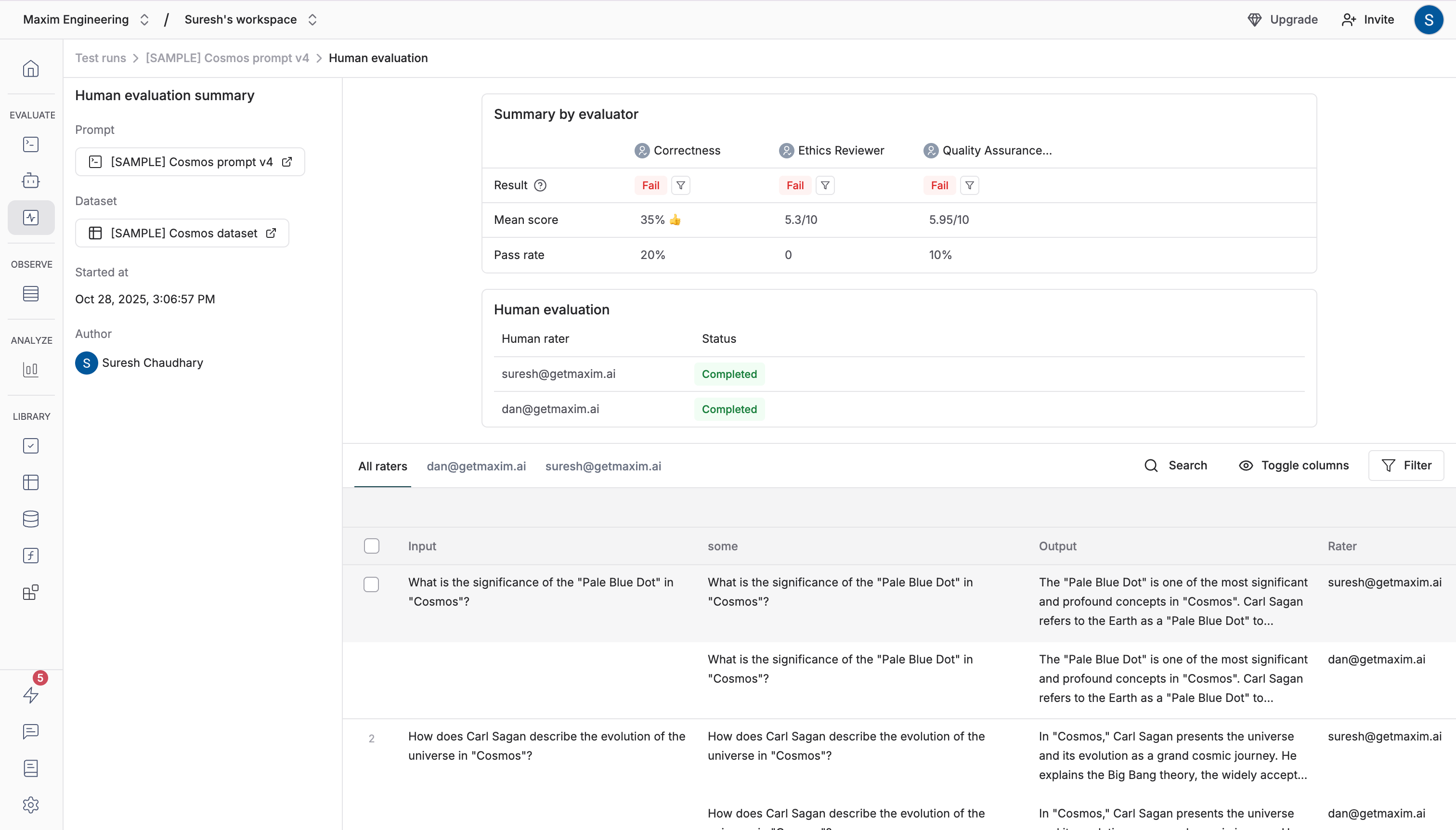
Analyze Human Ratings
Once all entries are completed by a rater, the summary scores and pass/fail results for the human ratings are shown along side all other auto evaluation results in the test run report. The human annotation section will show aCompleted status next to this rater’s email. To view the detailed ratings by a particular individual, click the View details button and go through the table provided.
Analyze ratings and comments from human annotators. View rating overviews, read detailed feedback, and review rewritten outputs. Filter by specific annotators or apply custom filters to focus your analysis.