Prompt Experimentation with Maxim's Prompt Playground

TL;DR
Prompt experimentation is critical to building reliable, production-grade AI applications. Maxim's Prompt Playground provides teams with a comprehensive platform for iterating, testing, and deploying prompts at scale. Key features include side-by-side prompt comparison, multimodal support, prompt versioning, prompt tools, and seamless deployment workflows. This article explores best practices for prompt experimentation, the essential components of systematic prompt management, and how Maxim's platform enables AI teams to move from prototype to production with confidence.
Introduction
Prompt engineering is a discipline for developing and optimizing prompts to efficiently use language models for a wide variety of applications and research topics. Prompt engineering skills help to better understand the capabilities and limitations of large language models. As generative AI applications mature from experimental prototypes to mission-critical systems, the ability to systematically experiment with prompts becomes foundational to success.
According to a 2024 State of AI Engineering report by Anyscale, over 65% of LLM developers reported that prompt versioning and observability were the hardest challenges in scaling prototypes to production. Without proper experimentation workflows, teams struggle with reproducibility issues, performance regressions, and unpredictable model behaviors that undermine user trust and system reliability.
Maxim AI addresses these challenges with a comprehensive prompt management platform designed for modern AI engineering teams. This article examines why prompt experimentation matters, explores proven methodologies, and demonstrates how Maxim's Prompt Playground accelerates AI development cycles.
Why Systematic Prompt Experimentation Matters
The High Stakes of Prompt Changes
Every modification to a prompt can significantly impact model outputs, user experience, and business outcomes. A poorly phrased prompt may produce irrelevant or misleading results, even if the model is capable of doing better. In production environments where AI systems handle customer interactions, financial decisions, or healthcare recommendations, the consequences of unvalidated prompt changes extend far beyond technical inconvenience.
The Cost of Ad Hoc Approaches
Teams that treat prompts as disposable text strings rather than critical infrastructure face several persistent challenges:
- Reproducibility gaps: Without systematic tracking, recreating specific model behaviors or debugging production issues becomes nearly impossible
- Version confusion: Multiple team members modifying prompts across development, staging, and production environments creates inconsistency and deployment risk
- Performance degradation: Changes that improve one use case often unexpectedly degrade others, but without baseline comparisons, these regressions go undetected until users complain
- Collaboration friction: Product managers, AI engineers, and domain experts struggle to contribute effectively when prompt changes require code deployments
Without a single source of truth, teams waste hours just figuring out which prompt version is actually in use. When you cannot track which generative AI prompt version generated specific outputs, debugging becomes a nightmare.
The Business Case for Experimentation Platforms
Implementing structured prompt experimentation workflows delivers measurable operational benefits. Centralized version control systems boost collaboration efficiency by 41%. Teams report up to 60% fewer merge conflicts compared to traditional file-sharing setups. More critically, systematic experimentation enables data-driven decision making, allowing teams to quantify improvements in accuracy, consistency, and user satisfaction before deploying changes to production.
Core Components of Effective Prompt Experimentation
Prompt Versioning and Change Management
Just as software engineers rely on Git for code management, AI teams must adopt rigorous practices for prompt versioning, tracking, and deployment. This ensures reproducibility, facilitates collaboration, and supports robust evaluation and monitoring workflows. Effective version control for prompts includes several essential elements:
- Automatic version creation: Every prompt modification should be tracked with metadata including author, timestamp, and change description
- Semantic versioning: Major, minor, and patch updates help teams understand the scope and impact of changes
- Change documentation: Recording why changes were made and what they aim to achieve enables knowledge transfer and debugging
- Rollback capabilities: Quick reversion to previous stable versions minimizes production disruption when new prompts introduce unexpected behaviors
Maxim's platform provides comprehensive prompt versioning capabilities with visual diff views that show exactly what changed between versions, making it easy to correlate performance shifts with specific modifications.
Comparative Testing and Analysis
Determining which variations actually improve performance for your specific use case requires systematic comparison.
Maxim's Prompt Playground enables side-by-side comparison of up to five different prompts simultaneously. Teams can:
- Compare across models: Evaluate how different LLM providers (OpenAI, Anthropic, Google, AWS Bedrock) respond to the same prompt
- Test prompt variations: Compare different phrasings, instruction structures, or few-shot examples to identify optimal formulations
- Benchmark performance: Analyze metrics including latency, cost, token count, and output quality across configurations
- Ensure consistency: Verify that prompts produce reliable outputs across model versions and deployment environments
Multimodal and Contextual Support
Modern AI applications increasingly require multimodal capabilities and dynamic context integration. Maxim's prompt IDE supports multimodal inputs, multiple model types (including open-source, closed, and custom), and provides real-world context integration; making it essential for high-quality, production-grade AI applications.
The platform supports:
- Variable injection: Dynamic variables using double curly braces allow teams to test prompts with realistic user inputs and runtime context
- Context source integration: Connect to databases, RAG pipelines, and external data sources to simulate production conditions
- Structured outputs: Configure response formats including JSON schemas and structured data for downstream processing
- Multimodal testing: Evaluate prompts that process text, images, and other media types
Tool Call Validation
For agentic AI systems that interact with external tools and APIs, validating tool selection becomes critical. Ensuring your prompt selects the accurate tool call (function) is crucial for building reliable and efficient AI workflows. Maxim's playground allows you to attach your tools (API, code or schema) and measure tool call accuracy for agentic systems.
Teams can create prompt tools within the library section, attach them to prompts for testing, and verify both tool selection accuracy and execution results before deploying to production.
Best Practices for Prompt Experimentation
Establish Baseline Metrics
Before modifying prompts, teams should establish clear baseline performance metrics. Best practice is to pair prompts with evaluation metrics. Tools like TruLens or LangSmith can benchmark LLM outputs against quality criteria like correctness and relevance. For production readiness, treat prompts like software artifacts.
Maxim provides access to comprehensive pre-built evaluators including:
- AI evaluators: Clarity, conciseness, faithfulness, context relevance, and task success
- Statistical evaluators: BLEU, ROUGE, F1 score, semantic similarity, and embedding distances
- Programmatic evaluators: Format validation, special character detection, and structural checks
Teams can also create custom evaluators tailored to specific business requirements and domain constraints.
Implement Iterative Testing Workflows
Prompt iteration is the practice of testing, tweaking, and rewriting your inputs to improve clarity, performance, or safety. It is less about guessing the perfect prompt on the first try—and more about refining through feedback and outcomes. Effective iteration requires structured workflows:
- Draft and experiment: Create prompt variations in a safe sandbox environment without affecting production systems
- Run systematic tests: Execute prompts against curated datasets representing real-world scenarios
- Compare results quantitatively: Use automated evaluators to score outputs on relevant dimensions
- Gather qualitative feedback: Implement human annotation workflows for nuanced assessment
- Document learnings: Record what worked, what failed, and why to build organizational knowledge
Maxim's Prompt Sessions feature automatically saves experimentation context, making it easy to resume interrupted work or review historical decisions.
Deploy with Confidence
Never deploy prompt changes blindly. Set up systematic testing: Run new versions against a test suite of common user inputs. Track how your prompts perform in production by setting up comprehensive monitoring.
Maxim enables production-grade prompt deployment with:
- SDK integration: Deploy prompts programmatically using Python, TypeScript, Java, or Go SDKs
- Environment management: Maintain separate prompt versions for development, staging, and production
- A/B testing: Compare prompt variants in live production settings with controlled traffic splitting
- Automated rollback: Quickly revert to previous versions if new prompts underperform or introduce errors
Leverage Continuous Monitoring
Having effective rollback methods in place is crucial for maintaining system stability and keeping operations running smoothly. Automated tools are key here—they help revert to earlier, stable versions when something goes wrong. A well-designed rollback system often uses feature flags and blue/green deployments to handle version changes efficiently.
Post-deployment monitoring should track:
- Performance metrics: Response latency, token usage, and cost per request
- Quality indicators: User satisfaction scores, task completion rates, and error frequencies
- Business metrics: Conversion rates, engagement duration, and customer feedback sentiment
Maxim's observability platform provides real-time visibility into production prompt performance with automated alerts for unexpected behavioral changes.
Maxim's Prompt Playground: Key Features and Workflows
Unified Experimentation Environment
Maxim consolidates the entire prompt experimentation lifecycle into a single platform. Teams can organize prompts using folders and tags, making it easy to manage hundreds of prompts across multiple projects and use cases.
The platform supports:
- Cross-functional collaboration: Product managers can experiment with prompts without writing code, while engineers maintain deployment control
- Template inheritance: Prompt partials enable reuse of common instruction patterns across multiple prompts
- Model flexibility: Switch between OpenAI, Anthropic, Google, AWS Bedrock, Azure, and open-source models without changing prompt infrastructure
AI-Powered Simulations
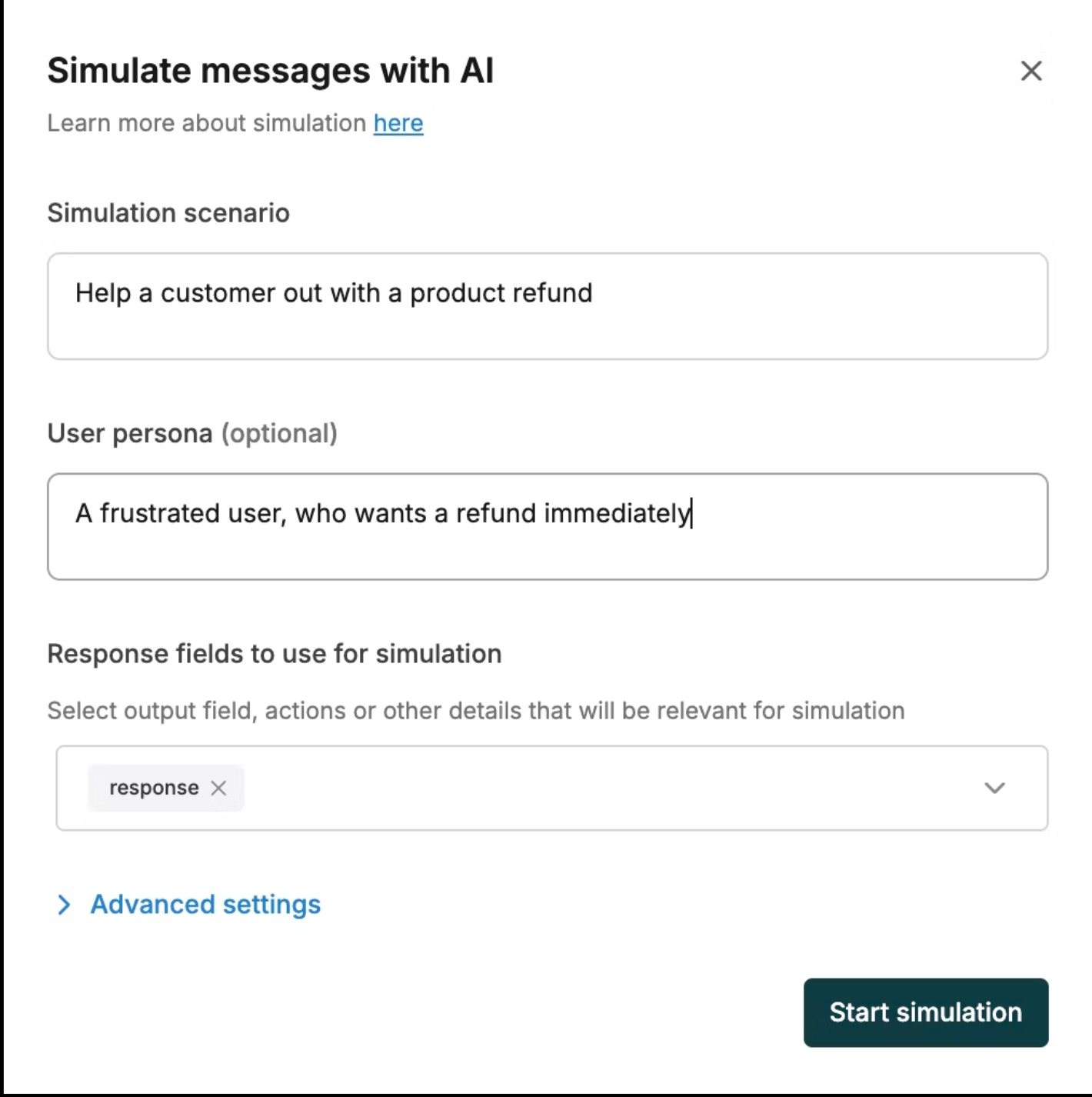
Recent platform enhancements include AI-powered simulation capabilities that allow teams to simulate multi-turn interactions and evaluate prompt performance across realistic scenarios and custom user personas. This extends experimentation beyond single-turn question-answering to complex conversational workflows.
Integration with Evaluation Pipeline
Maxim's experimentation platform seamlessly connects with its comprehensive evaluation engine. After experimenting with prompts in the playground, teams can:
- Run bulk evaluations across test suites with hundreds or thousands of examples
- Compare evaluation results across prompt versions to quantify improvements or regressions
- Configure automated evaluations on production logs for continuous quality monitoring
Prompt Optimization and Auto-Generation
For teams seeking to accelerate prompt development, Maxim offers prompt optimization features that leverage AI to suggest improvements based on evaluation results and historical performance patterns.
Advanced Workflows: From Experimentation to Production
CI/CD Integration
Prompt versioning must be decoupled from application code, enabling rapid iteration and deployment without risking production stability. Platforms like Maxim AI support seamless integration with CI/CD workflows, allowing teams to deploy prompts with custom variables and conditional logic.
Teams can implement CI/CD integration for prompts by:
- Running automated evaluation suites as part of pull request checks
- Blocking deployments when quality metrics fall below defined thresholds
- Automatically promoting approved prompt versions through staging to production
- Maintaining audit trails for compliance and debugging
Multi-Model Strategy with Bifrost Gateway
Maxim's Bifrost gateway provides enterprise-grade LLM infrastructure that complements prompt experimentation workflows. The gateway offers:
- Unified API interface: Single OpenAI-compatible API for 12+ providers
- Automatic failover: Seamless switching between providers when primary services experience issues
- Semantic caching: Intelligent response caching based on semantic similarity reduces costs and latency
- Load balancing: Distribute requests across multiple API keys and providers for optimal performance
This infrastructure enables teams to experiment with prompts across different model providers without changing application code, making it easy to compare costs, capabilities, and performance characteristics.
Agentic Workflow Development
For complex multi-step AI workflows, Maxim provides Prompt Chains that let teams prototype agentic systems with greater clarity and control. Teams can create parallel chains for concurrent tasks, transfer data flexibly between workflow steps, and experiment with prompts directly within each block.
Measuring Success: Key Performance Indicators
Effective prompt experimentation requires clear success metrics. Teams should track:
Pre-Production Metrics
- Evaluation score improvements: Quantitative increases in accuracy, relevance, or task completion across test datasets
- Consistency measures: Variance in outputs across multiple runs with identical inputs
- Edge case handling: Performance on challenging or adversarial inputs designed to expose weaknesses
- Cost efficiency: Token usage and inference costs relative to output quality
Production Metrics
- User satisfaction scores: Direct feedback or proxy metrics like session duration and completion rates
- Error rates: Frequency of failed requests, timeout errors, or invalid outputs
- Business outcomes: Conversion rates, revenue impact, or operational efficiency gains directly attributable to AI features
- Technical performance: P50, P95, and P99 latency distributions, throughput capacity, and resource utilization
Maxim's dashboard and reporting capabilities provide comprehensive visibility into these metrics across development and production environments.
Conclusion
Prompt experimentation is no longer optional for teams building production AI applications. As a culmination of these efforts, comprehensive surveys on prompt engineering present the most complete understanding of this rapidly developing field, establishing structured taxonomies and best practices for effective implementation.
Maxim AI provides end-to-end capabilities for prompt experimentation, from initial ideation through deployment and monitoring. The platform's Prompt Playground enables teams to iterate rapidly, compare variations systematically, and deploy with confidence. By treating prompts as critical infrastructure rather than disposable text, organizations can build reliable AI systems that deliver consistent value to users.
Teams seeking to accelerate their AI development cycles should adopt structured experimentation workflows, leverage automated evaluation capabilities, and maintain rigorous version control. Maxim's platform makes these best practices accessible to both technical and non-technical stakeholders, fostering cross-functional collaboration and reducing time-to-production.
Start experimenting with Maxim's Prompt Playground today to experience how systematic prompt management transforms AI development workflows. For teams ready to see the platform in action, schedule a demo with our solutions team.


