- AI-based evaluators
- API-based evaluators
- Human evaluators
- Programmatic evaluators
AI-based Evaluators
Create custom AI evaluators by selecting an LLM as the judge and configuring custom evaluation instructions.
Configure model and parameters
Select the LLM you want to use as the judge and configure model-specific parameters based on your requirements in the Definition tab.
Choose evaluation scale
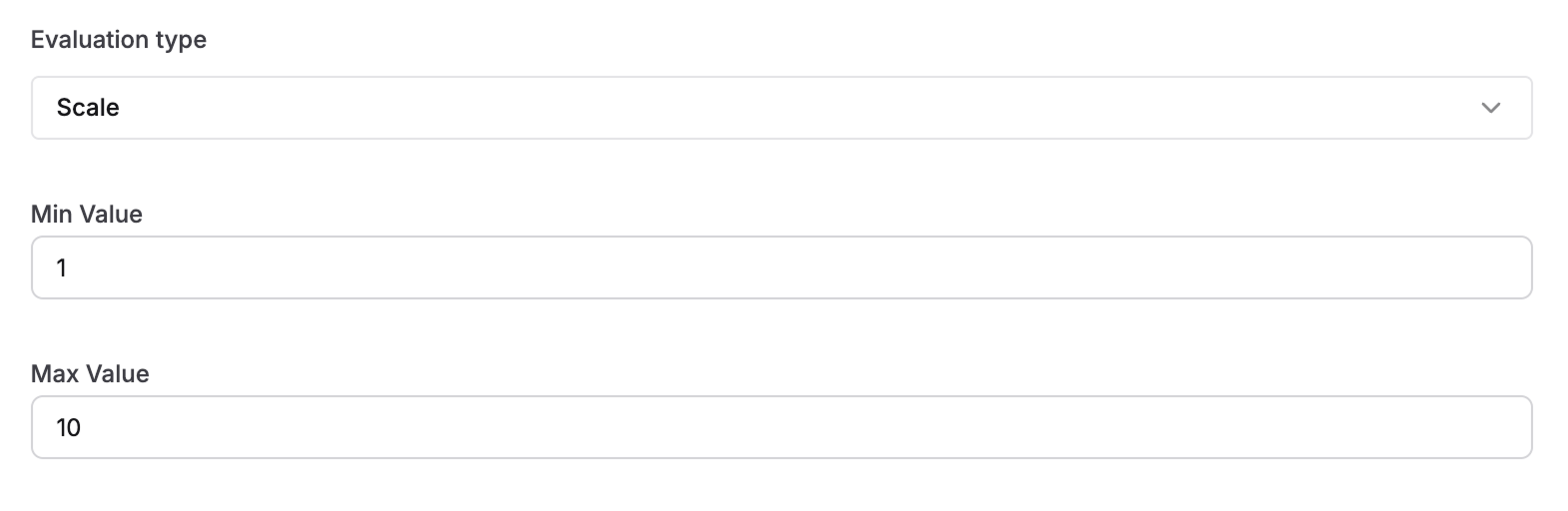
Select the evaluation scale from the dropdown:
-
Binary (Yes/No): Returns
trueorfalse - Scale of 1 to 5: Returns a numeric score from 1 to 5
- String values: Returns a string value
-
Number: Returns a numeric score
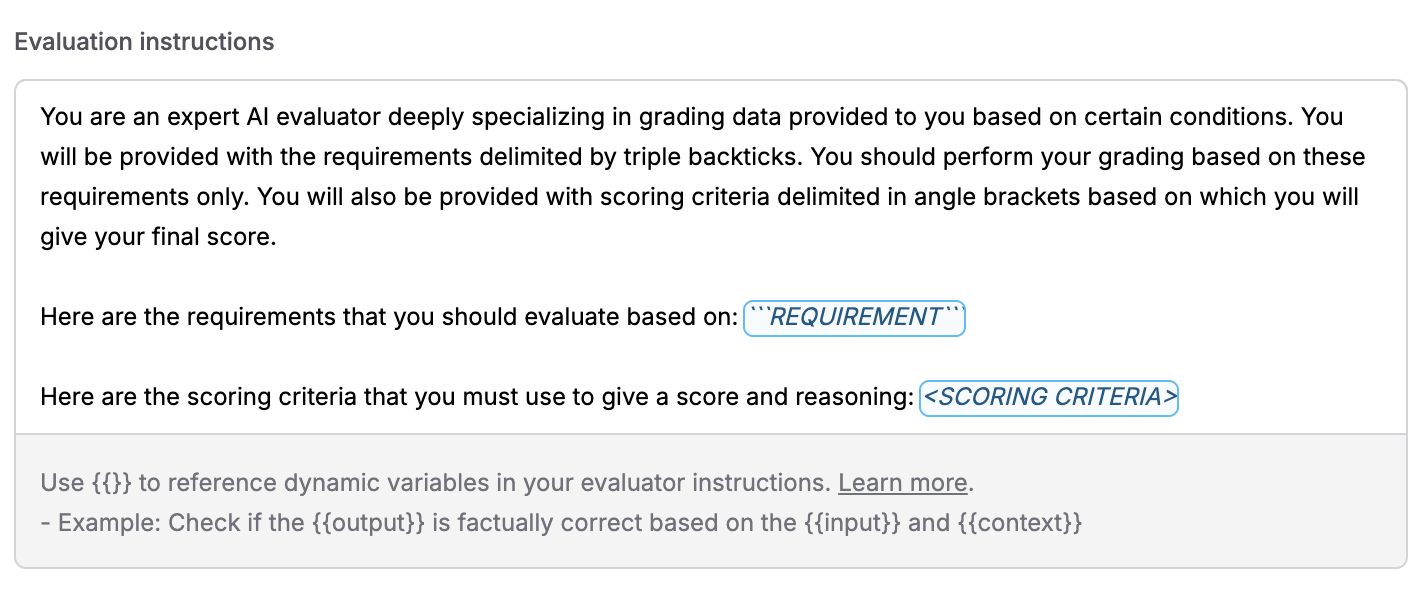
Configure evaluation instructions
In the Evaluation instructions field, write the instructions that tell the AI evaluator how to judge the outputs. You can use variables like Example for Binary evaluation:
{{input}}, {{output}}, {{context}} to reference dynamic values from your dataset or logs. These variables will be automatically replaced with actual values during evaluation.Example for Scale evaluation:Variables are highlighted in the editor and can be inserted using the suggestions dropdown. The placeholders
REQUIREMENT and <SCORING CRITERIA> are also highlighted when present in your instructions if you’re using the default template structure.
Understanding the AI Evaluator Interface
The AI evaluator editor is organized into three main tabs:Definition Tab
The Definition tab is where you configure your AI evaluator:- Model selection: Choose the LLM you want to use as the judge
- Model configuration: Configure model-specific parameters (temperature, max tokens, etc.)
- Evaluation scale: Select the scoring type (Binary, Scale, String values, or Number)
- Evaluation instructions: Write the instructions that tell the AI how to evaluate outputs
- Score normalization (optional): Convert scores from 1-5 scale to 0-1 scale for Scale evaluations
Variables Tab
The Variables tab shows all available variables for your evaluator:-
Reserved variables: These are built-in variables provided by Maxim that you can use in your evaluator instructions:
input: Input query from dataset or logged traceoutput: Output from the test run or logged tracecontext: Retrieved context from your data sourceexpectedOutput: Expected output as mentioned in datasetexpectedToolCalls: Expected tools to be called as mentioned in datasettoolCalls: Actual tool calls made during executiontoolOutputs: Outputs of all tool calls madeprompt: Content of all messages in the prompt versionscenario: Scenario for simulating multi-turn sessionsessionOutputs: Agent outputs across all turns of the sessionsession: A sequence of multi-turn interactions between user and your applicationhistory: Prior turns in the current session before the latest inputexpectedSteps: Expected steps to be followed by the agent as mentioned in dataset
- Custom variables: You can define additional custom variables if needed
Pass Criteria Tab
The Pass Criteria tab allows you to configure when an evaluation should be considered passing:- Pass query: Define criteria for individual evaluation metrics Example: Pass if evaluation score > 0.8
- Pass evaluator (%): Set threshold for overall evaluation across multiple entries Example: Pass if 80% of entries meet the evaluation criteria
API-based Evaluators
Connect your existing evaluation system to Maxim by exposing it via an API endpoint. This lets you reuse your evaluators without rebuilding them.Configure Endpoint Details
Add your API endpoint details including: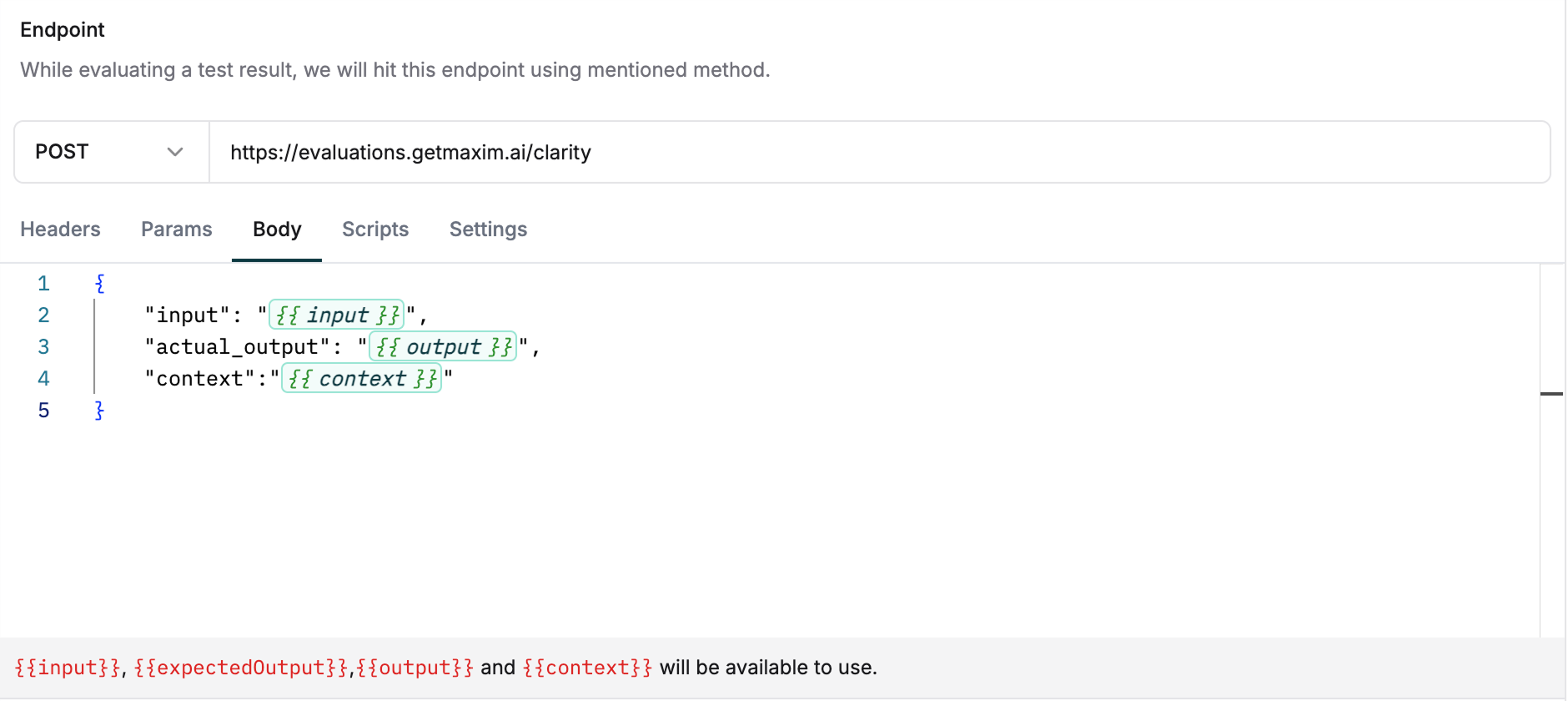
- Headers
- Query parameters
- Request body
Scripts tab.Use variables in the body, query parameters and headers
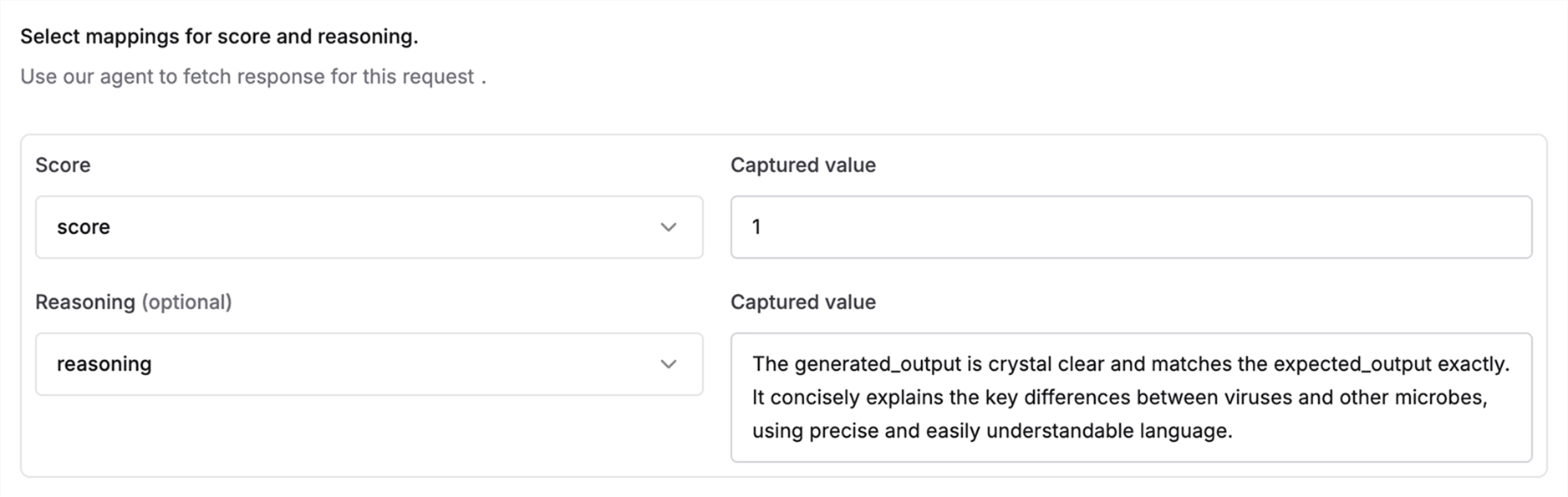
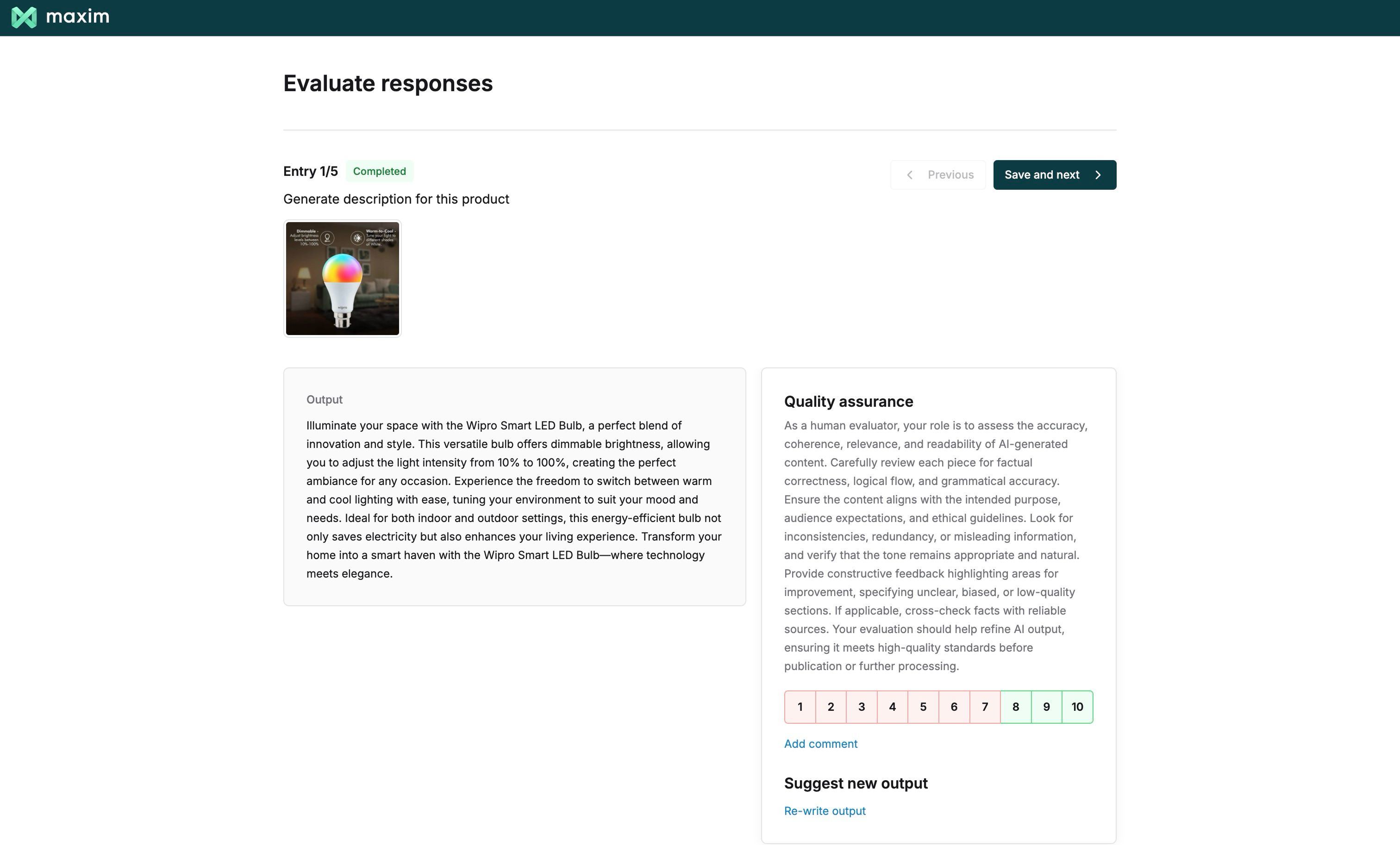
Human Evaluators
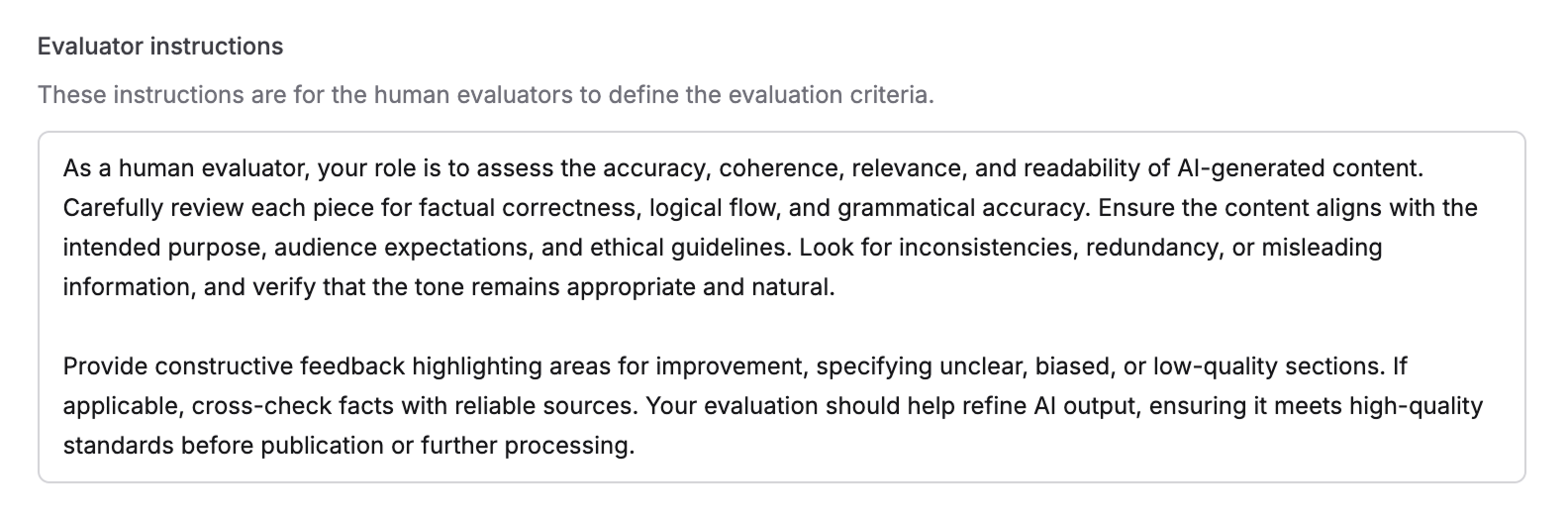
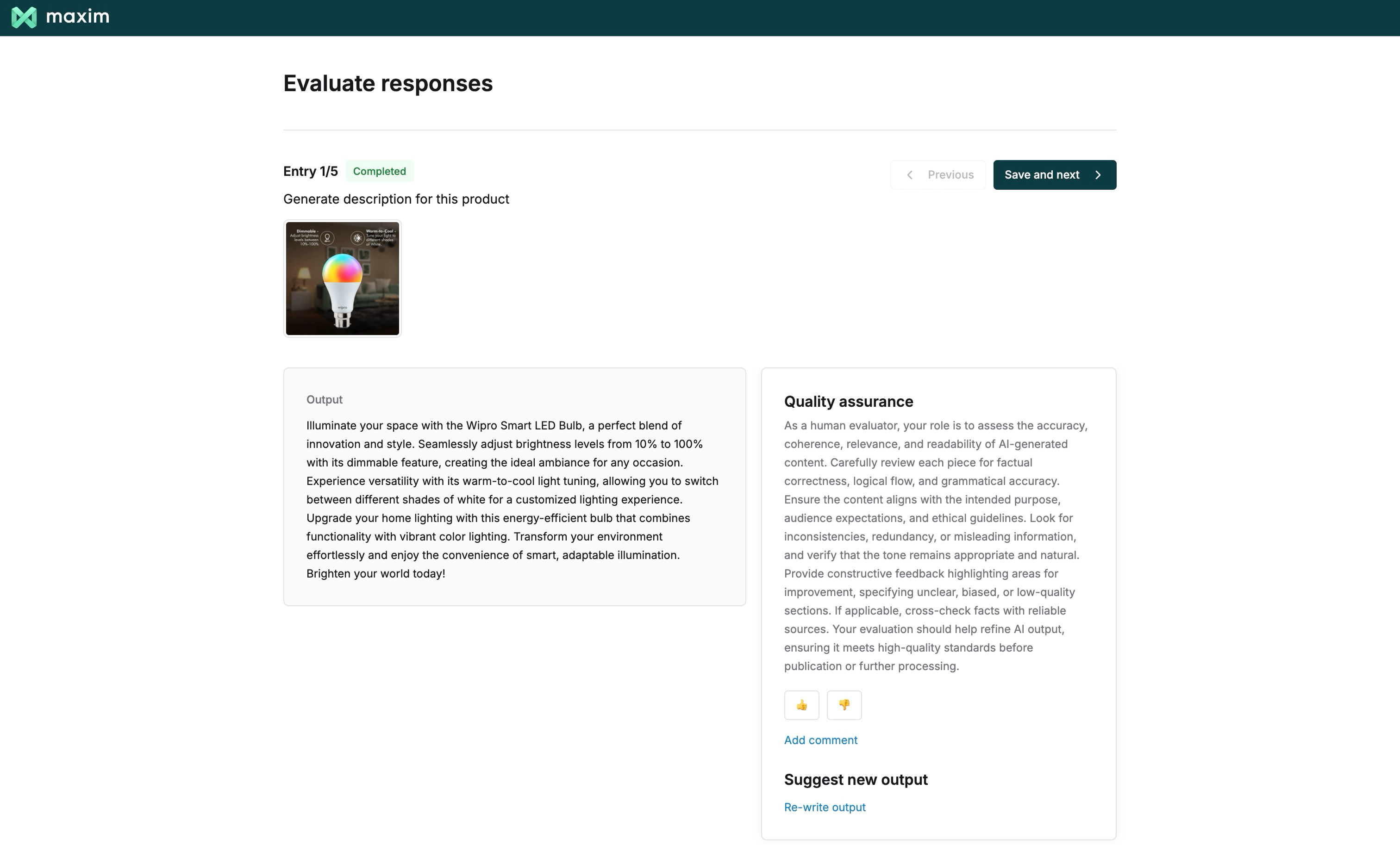
Set up human raters to review and assess AI outputs for quality control. Human evaluation is essential for maintaining quality control and oversight of your AI system’s outputs.Define Reviewer Guidelines
Write clear guidelines for human reviewers. These instructions appear during the review process and should include:
- What aspects to evaluate
- How to assign ratings
-
Examples of good and bad responses

Programmatic Evaluators
Build custom code-based evaluators using Javascript or Python with access to standard libraries.Select Language and Response Type
Choose your programming language and set the Response type (Number, Boolean, or String) from the top bar. The response type determines what your evaluator function should return:
-
Boolean: Returns
trueorfalse(Yes/No evaluation) - Number: Returns a numeric score for scale-based evaluation
- String values: Returns a string value for multi-select or categorical evaluation
The evaluator result can be a string value when using the “String values” response type. This is useful for categorical evaluations or when you need to return specific string labels rather than numeric scores.
Implement the Validate Function
Define a function named 
validate in your chosen language. This function is required as Maxim uses it during execution.Code restrictionsJavascript
- No infinite loops
- No debugger statements
- No global objects (window, document, global, process)
- No require statements
- No with statements
- No Function constructor
- No eval
- No setTimeout or setInterval
- No infinite loops
- No recursive functions
- No global/nonlocal statements
- No raise, try, or assert statements
- No disallowed variable assignments

Understanding the Programmatic Evaluator Interface
The programmatic evaluator editor is organized into three main tabs:Definition Tab
The Definition tab is where you write your evaluation code. Here you can:- Select your programming language (JavaScript or Python)
- Choose the response type (Boolean, Number, or String values)
-
Write your
validatefunction that contains the evaluation logic - Use reserved variables (see below) in your code
Variables Tab
The Variables tab shows all available variables for your evaluator:-
Reserved variables: These are built-in variables provided by Maxim that you can use in your evaluator code:
input: Input query from dataset or logged traceoutput: Output from the test run or logged tracecontext: Retrieved context from your data sourceexpectedOutput: Expected output as mentioned in datasetexpectedToolCalls: Expected tools to be called as mentioned in datasettoolCalls: Actual tool calls made during executionscenario: Scenario for simulating multi-turn sessionsessionOutputs: Agent outputs across all turns of the sessionsession: A sequence of multi-turn interactions between user and your applicationhistory: Prior turns in the current session before the latest inputexpectedSteps: Expected steps to be followed by the agent as mentioned in dataset
- Custom variables: You can define additional custom variables if needed
Pass Criteria Tab
The Pass Criteria tab allows you to configure when an evaluation should be considered passing:- Pass query: Define criteria for individual evaluation metrics Example: Pass if evaluation score > 0.8
- Pass evaluator (%): Set threshold for overall evaluation across multiple entries Example: Pass if 80% of entries meet the evaluation criteria
Common Configuration Steps
All evaluator types share some common configuration steps:Configure Pass Criteria
Configure two types of pass criteria for any evaluator type: Pass query Define criteria for individual evaluation metrics Example: Pass if evaluation score > 0.8 Pass evaluator (%) Set threshold for overall evaluation across multiple entries Example: Pass if 80% of entries meet the evaluation criteria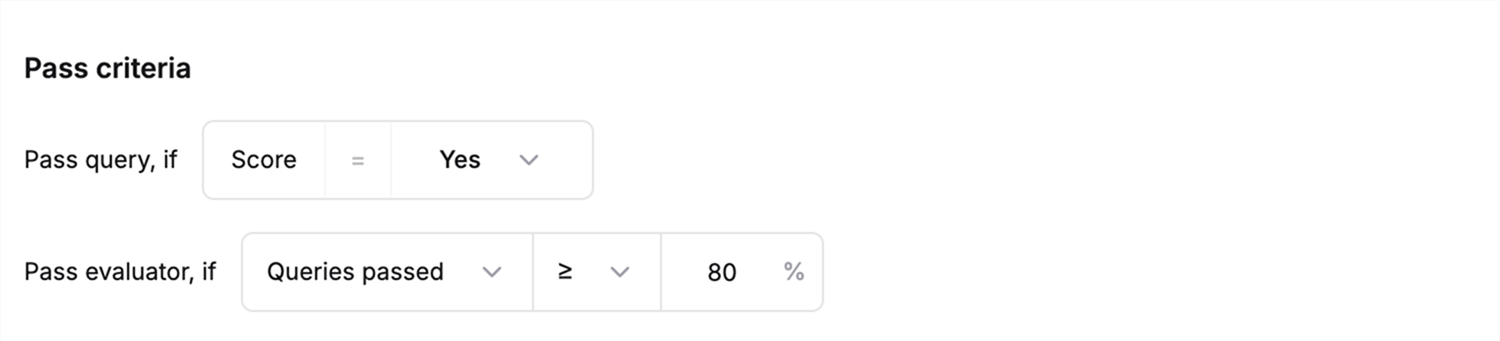
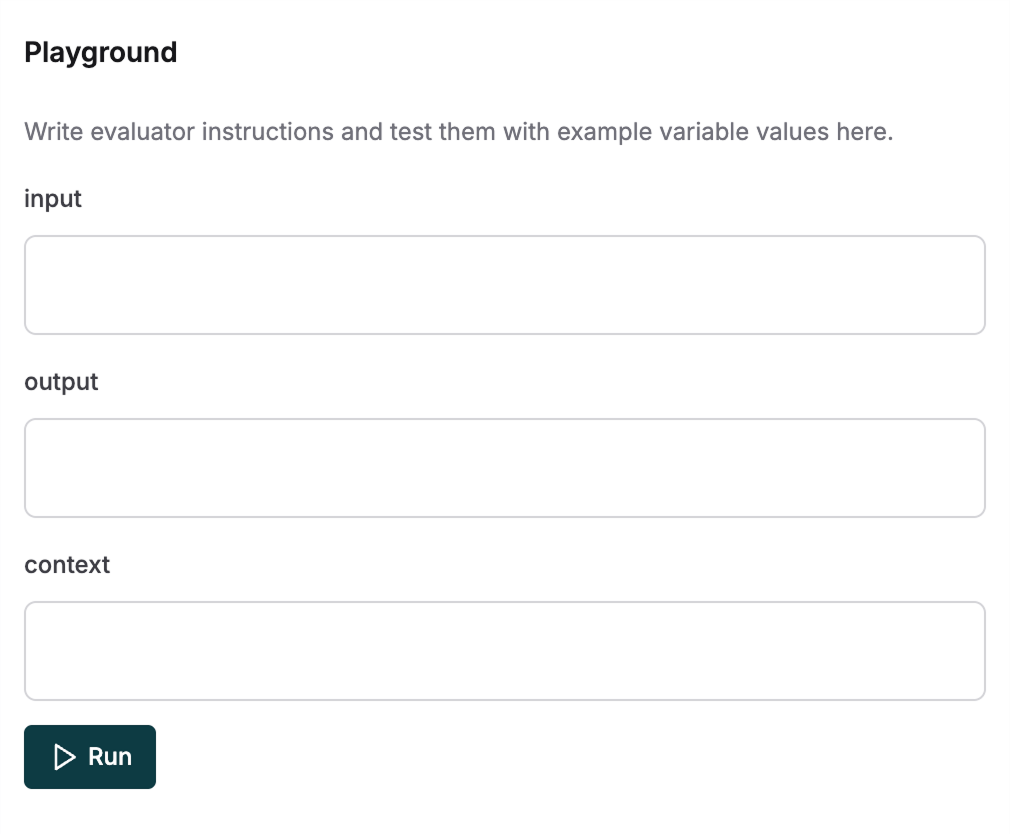
Test in Playground
Test your evaluator in the playground before using it in your workflows. The right panel shows input fields for all variables used in your evaluator.- Fill in sample values for each variable
- Click Run to see how your evaluator performs
- Iterate and improve your evaluator based on the results