What is Node-Level Evaluation?
As your AI application grows in complexity, it becomes increasingly difficult to understand how it is performing on different flows and components. This granular insight becomes necessary to identify bottlenecks or low quality areas in your application’s or agent’s flow. By targeting the underperforming areas, you can optimize overall performance more effectively than using brute force approaches.
This is where Node-Level evaluation can help out. It enables you to evaluate a trace or its component (a span, generation or retrieval) in isolation. This can be done via the Maxim SDK’s logger using a very simple API. Let us see how we can start evaluating our nodes.
Before you startYou need to have your logging set up to capture interactions between your LLM and users before you can evaluate them. To do so, you would need to integrate Maxim SDK into your application. Understanding How the Maxim SDK Logger Evaluates
Two actions are mainly required to evaluate a node:
- Attach Evaluators: This action defines what evaluators to run on the particular node, this needs to be called to start an evaluation on any component.
- Attach Variables: Once evaluators are attached on a component, each evaluator waits for all the variables it needs to evaluate to be attached to it. Only after all the variables an evaluator needs are attached, does it start processing.
Once you have attached evaluators and variables to them, we will process the evaluator and display the results in the Evaluation tab under the respective node.
- The evaluator will not run until all of the variables it needs are attached to it.
- If we don’t receive all the variables needed for an evaluator for over 5 minutes, we will start displaying a
Missing variables message (although we will still process the evaluator even if variables are received after 5 minutes).
- The variables that an evaluator needs can be found in the evaluator’s page. The evaluator test panel on the right has all the variables that the evalutor needs listed (all of them are required).
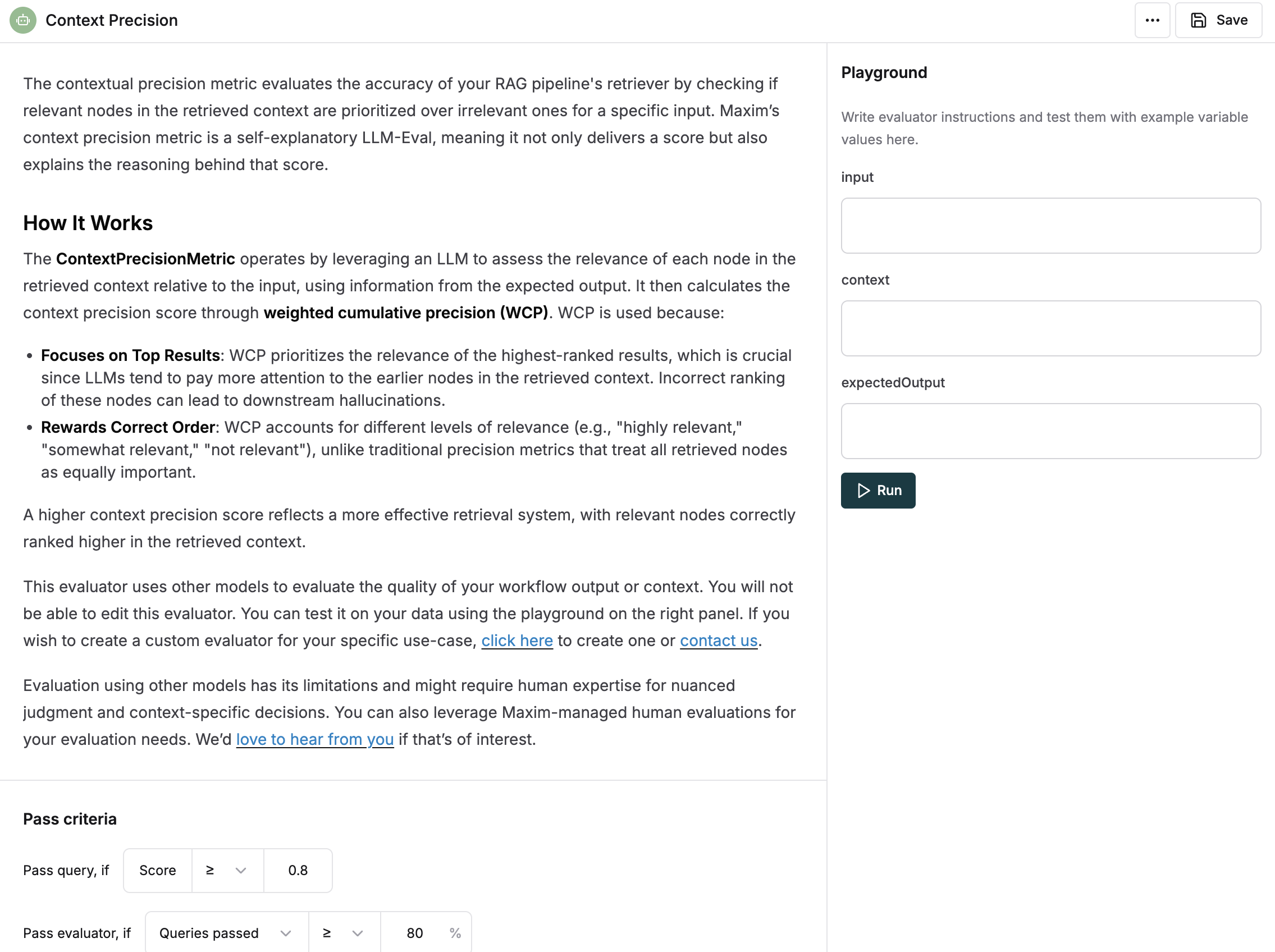
As per the image above, we can see that the evaluator needs input, context and expectedOutput variables.
Evaluation Framework Architecture
The Maxim SDK provides a robust evaluation framework built on several key components:
Core Evaluation Classes
BaseEvaluator: The foundation class for all evaluators in maxim-py
from maxim.evaluators import BaseEvaluator
from maxim.models import LocalEvaluatorResultParameter, LocalData, LocalEvaluatorReturn
class MyCustomEvaluator(BaseEvaluator):
def evaluate(self, result: LocalEvaluatorResultParameter, data: LocalData) -> Dict[str, LocalEvaluatorReturn]:
# Your evaluation logic here
return {"evaluator_name": LocalEvaluatorReturn(score=0.85, reasoning="Evaluation reasoning")}
# The evaluate() method returns an EvaluateContainer
evaluation_container = generation.evaluate()
from maxim.models import PassFailCriteria, PassFailCriteriaOnEachEntry, PassFailCriteriaForTestrunOverall
criteria = PassFailCriteria(
on_each_entry_pass_if=PassFailCriteriaOnEachEntry(">=", 0.7),
for_testrun_overall_pass_if=PassFailCriteriaForTestrunOverall(">=", 0.8, "average")
)
Evaluation Types
The SDK supports multiple evaluator types:
- AI Evaluators: Use AI models to evaluate content (e.g., “clarity”, “toxicity”)
- Programmatic Evaluators: Custom logic-based evaluations
- Statistical Evaluators: Mathematical/statistical analysis
- API Evaluators: External API-based evaluations
- Human Evaluators: Manual human assessment
- Local Evaluators: Client-side custom evaluators
Attaching Evaluators via Maxim SDK
We use the with_evaluators method to attach evaluators to any component within a trace or the trace itself. It is as easy as just listing the names of the evaluators you want to attach, which are available on the platform.
component.evaluate.withEvaluators("evaluator");
// example
generation.evaluate.withEvaluators("clarity", "toxicity");
If you list an evaluator that doesn’t exist in your workspace but is available in the store, we will auto install it for you in the workspace.If the evaluator is not available in the store as well, we will ignore it.
Advanced Evaluator Configuration
You can also attach custom local evaluators with specific pass/fail criteria:
from maxim.evaluators import BaseEvaluator
from maxim.models import PassFailCriteria, PassFailCriteriaOnEachEntry, PassFailCriteriaForTestrunOverall
class CustomQualityEvaluator(BaseEvaluator):
def evaluate(self, result: LocalEvaluatorResultParameter, data: LocalData) -> Dict[str, LocalEvaluatorReturn]:
# Custom evaluation logic
score = self.analyze_quality(result.output)
return {
"quality_score": LocalEvaluatorReturn(
score=score,
reasoning=f"Quality analysis based on {len(result.output)} characters"
)
}
def analyze_quality(self, text: str) -> float:
# Your custom quality analysis logic
return 0.85
# Usage with custom criteria
custom_evaluator = CustomQualityEvaluator(
pass_fail_criteria={
"quality_score": PassFailCriteria(
on_each_entry_pass_if=PassFailCriteriaOnEachEntry(">=", 0.7),
for_testrun_overall_pass_if=PassFailCriteriaForTestrunOverall(">=", 0.8, "average")
)
}
)
generation.evaluate().with_evaluators("clarity", custom_evaluator)
Providing Variables to Evaluators
Once evaluators are attached to a component, variables can be passed to them via the with_variables method. This method accepts a key-value pair of variable names to their values.
You also need to specify which evaluators you want these variables to be attached to, which can be done by passing the list of evaluator names as the second argument.
component.evaluate.withVariables(
{ variableName: "value" }, // Key-value pair of variables
["evaluator"], // List of evaluators
);
// example
retrieval.evaluate.withVariables(
{ output: assistantResponse.choices[0].message.content },
["clarity", "toxicity"],
);
You can directly chain the with_variables method after attaching evaluators to any component. Allowing you to skip mentioning the evaluator names again.trace.evaluate
.withEvaluators("clarity", "toxicity")
.withVariables({
input: userInput,
});
Viewing Evaluation Results on Evaluations Tab
This is very similar to Making sense of evaluations on logs, except that the evaluations for each component appear on their own card as it did for the trace.
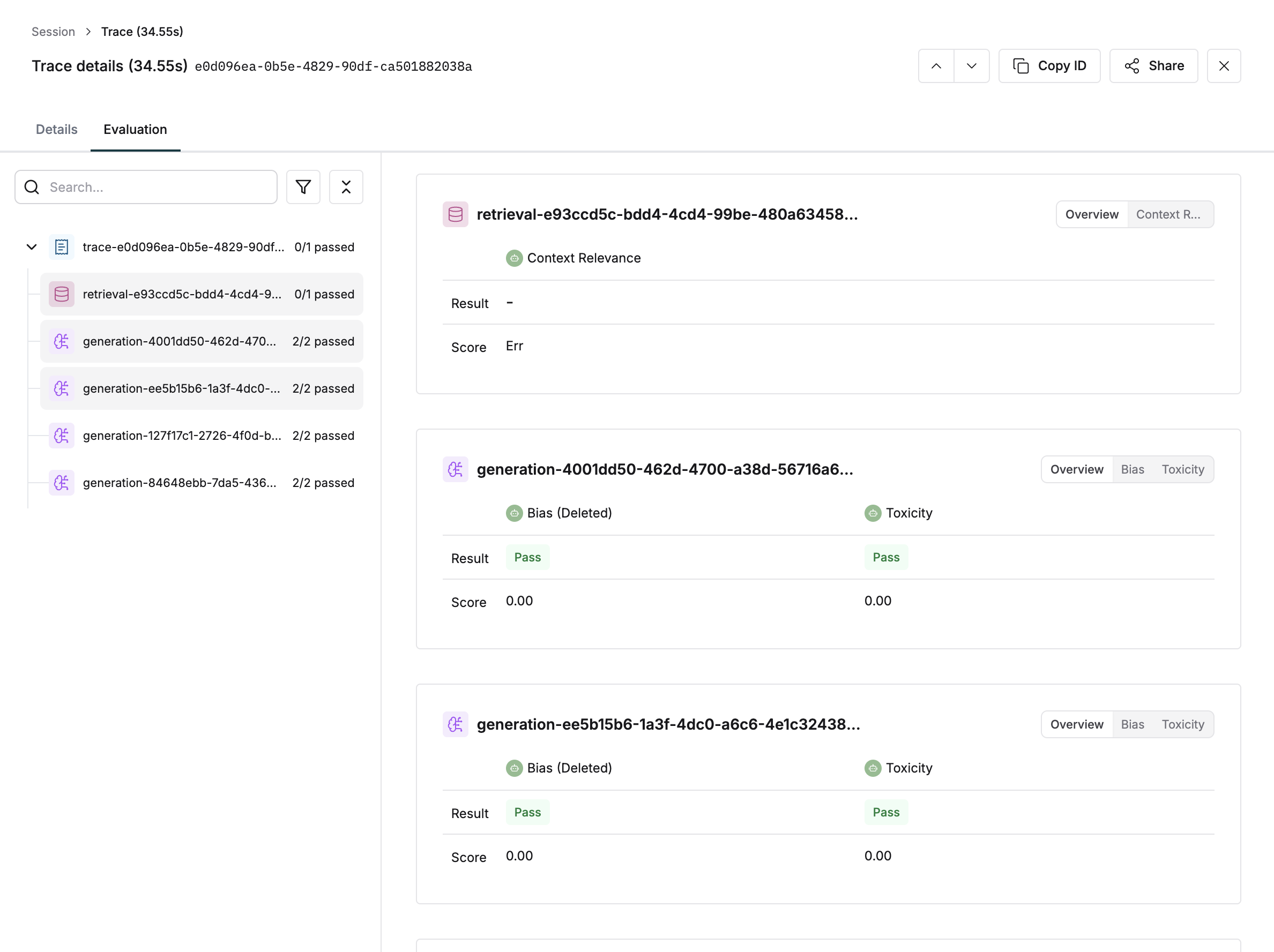
Comprehensive Code Examples
Basic Generation Evaluation
This example shows how to evaluate a simple text generation with multiple evaluators:
import maxim
from maxim.decorators import trace, generation
# Initialize logger
logger = maxim.Logger(api_key="your-api-key")
@logger.trace(name="customer_support_chat")
def handle_customer_query(user_message: str):
# Create a generation for the AI response
generation_config = {
"id": "support-response-001",
"provider": "openai",
"model": "gpt-4",
"messages": [
{"role": "system", "content": "You are a helpful customer support agent."},
{"role": "user", "content": user_message}
],
"model_parameters": {"temperature": 0.7, "max_tokens": 500},
"name": "customer_support_response"
}
generation = logger.current_trace().generation(generation_config)
# Attach evaluators to the generation
generation.evaluate().with_evaluators("clarity", "toxicity", "helpfulness")
# Provide input variable for all evaluators
generation.evaluate().with_variables(
{"input": user_message},
["clarity", "toxicity", "helpfulness"]
)
# Simulate AI response
ai_response = "Thank you for contacting us. I understand your concern about..."
generation.result({
"choices": [{"message": {"content": ai_response, "role": "assistant"}}],
"usage": {"total_tokens": 150}
})
# Provide output variable for evaluation
generation.evaluate().with_variables(
{"output": ai_response},
["clarity", "toxicity", "helpfulness"]
)
return ai_response
Advanced RAG System Evaluation
This example demonstrates evaluation in a Retrieval-Augmented Generation (RAG) system:
import maxim
from maxim.decorators import trace, generation, retrieval
logger = maxim.Logger(api_key="your-api-key")
@logger.trace(name="rag_question_answering")
def answer_question_with_rag(question: str, knowledge_base: list):
# Step 1: Retrieve relevant documents
@retrieval(name="document_retrieval", evaluators=["Ragas Context Relevancy"])
def retrieve_documents(query: str):
retrieval = maxim.current_retrieval()
retrieval.input(query)
# Attach evaluation variables
retrieval.evaluate().with_variables(
{"input": query},
["Ragas Context Relevancy"]
)
# Simulate document retrieval
relevant_docs = [
{"content": "Document 1 content...", "relevance_score": 0.9},
{"content": "Document 2 content...", "relevance_score": 0.7}
]
retrieval.output(relevant_docs)
# Provide context for evaluation
retrieval.evaluate().with_variables(
{"context": str(relevant_docs)},
["Ragas Context Relevancy"]
)
return relevant_docs
# Step 2: Generate answer using retrieved context
retrieved_docs = retrieve_documents(question)
generation_config = {
"id": "rag-answer-generation",
"provider": "openai",
"model": "gpt-4",
"messages": [
{
"role": "system",
"content": "Answer the question using the provided context. Be accurate and helpful."
},
{"role": "user", "content": f"Question: {question}\nContext: {retrieved_docs}"}
],
"name": "rag_answer_generation"
}
generation = logger.current_trace().generation(generation_config)
# Attach multiple evaluators
generation.evaluate().with_evaluators(
"clarity", "accuracy", "completeness", "relevance"
)
# Provide input variables
generation.evaluate().with_variables(
{
"input": question,
"context": str(retrieved_docs)
},
["clarity", "accuracy", "completeness", "relevance"]
)
# Generate answer
answer = "Based on the provided context, the answer is..."
generation.result({
"choices": [{"message": {"content": answer, "role": "assistant"}}]
})
# Provide output for evaluation
generation.evaluate().with_variables(
{"output": answer},
["clarity", "accuracy", "completeness", "relevance"]
)
return answer
Multi-Agent System Evaluation
This example shows evaluation in a multi-agent system with different evaluation strategies:
import maxim
from maxim.decorators import trace, generation, span
logger = maxim.Logger(api_key="your-api-key")
@logger.trace(name="multi_agent_workflow")
def process_complex_request(user_request: str):
# Agent 1: Research Agent
@span(name="research_phase")
def research_agent(query: str):
research_generation = maxim.current_span().generation({
"id": "research-agent",
"provider": "openai",
"model": "gpt-4",
"messages": [
{"role": "system", "content": "You are a research specialist. Gather comprehensive information."},
{"role": "user", "content": query}
],
"name": "research_agent"
})
# Evaluate research quality
research_generation.evaluate().with_evaluators("completeness", "accuracy")
research_generation.evaluate().with_variables(
{"input": query},
["completeness", "accuracy"]
)
research_output = "Comprehensive research findings..."
research_generation.result({"choices": [{"message": {"content": research_output}}]})
research_generation.evaluate().with_variables(
{"output": research_output},
["completeness", "accuracy"]
)
return research_output
# Agent 2: Analysis Agent
@span(name="analysis_phase")
def analysis_agent(research_data: str):
analysis_generation = maxim.current_span().generation({
"id": "analysis-agent",
"provider": "openai",
"model": "gpt-4",
"messages": [
{"role": "system", "content": "You are an analysis specialist. Provide deep insights."},
{"role": "user", "content": f"Analyze this research: {research_data}"}
],
"name": "analysis_agent"
})
# Evaluate analysis quality
analysis_generation.evaluate().with_evaluators("clarity", "depth", "insightfulness")
analysis_generation.evaluate().with_variables(
{"input": research_data},
["clarity", "depth", "insightfulness"]
)
analysis_output = "Detailed analysis with insights..."
analysis_generation.result({"choices": [{"message": {"content": analysis_output}}]})
analysis_generation.evaluate().with_variables(
{"output": analysis_output},
["clarity", "depth", "insightfulness"]
)
return analysis_output
# Agent 3: Synthesis Agent
@span(name="synthesis_phase")
def synthesis_agent(analysis_data: str):
synthesis_generation = maxim.current_span().generation({
"id": "synthesis-agent",
"provider": "openai",
"model": "gpt-4",
"messages": [
{"role": "system", "content": "You are a synthesis specialist. Create final recommendations."},
{"role": "user", "content": f"Synthesize this analysis: {analysis_data}"}
],
"name": "synthesis_agent"
})
# Evaluate synthesis quality
synthesis_generation.evaluate().with_evaluators("coherence", "actionability", "completeness")
synthesis_generation.evaluate().with_variables(
{"input": analysis_data},
["coherence", "actionability", "completeness"]
)
final_output = "Final recommendations and action plan..."
synthesis_generation.result({"choices": [{"message": {"content": final_output}}]})
synthesis_generation.evaluate().with_variables(
{"output": final_output},
["coherence", "actionability", "completeness"]
)
return final_output
# Execute the multi-agent workflow
research_result = research_agent(user_request)
analysis_result = analysis_agent(research_result)
final_result = synthesis_agent(analysis_result)
return final_result
Custom Local Evaluator Implementation
This example shows how to create and use custom local evaluators:
from maxim.evaluators import BaseEvaluator
from maxim.models import (
LocalEvaluatorResultParameter,
LocalData,
LocalEvaluatorReturn,
PassFailCriteria,
PassFailCriteriaOnEachEntry,
PassFailCriteriaForTestrunOverall
)
import re
from typing import Dict
class CustomQualityEvaluator(BaseEvaluator):
"""Custom evaluator for assessing response quality"""
def evaluate(self, result: LocalEvaluatorResultParameter, data: LocalData) -> Dict[str, LocalEvaluatorReturn]:
output = result.output
context = result.context_to_evaluate
# Calculate quality score based on multiple factors
clarity_score = self._assess_clarity(output)
completeness_score = self._assess_completeness(output, context)
relevance_score = self._assess_relevance(output, context)
# Weighted average
overall_score = (clarity_score * 0.4 + completeness_score * 0.3 + relevance_score * 0.3)
reasoning = f"Quality assessment: Clarity={clarity_score:.2f}, Completeness={completeness_score:.2f}, Relevance={relevance_score:.2f}"
return {
"quality_score": LocalEvaluatorReturn(
score=overall_score,
reasoning=reasoning
)
}
def _assess_clarity(self, text: str) -> float:
"""Assess text clarity based on readability metrics"""
# Simple readability assessment
sentences = len(re.split(r'[.!?]+', text))
words = len(text.split())
avg_sentence_length = words / max(sentences, 1)
# Penalize very long sentences, reward moderate length
if avg_sentence_length > 30:
return 0.3
elif avg_sentence_length > 20:
return 0.6
else:
return 0.9
def _assess_completeness(self, output: str, context: str) -> float:
"""Assess how completely the output addresses the context"""
if not context:
return 0.5 # Neutral if no context provided
# Simple keyword overlap assessment
output_words = set(output.lower().split())
context_words = set(context.lower().split())
if len(context_words) == 0:
return 0.5
overlap = len(output_words.intersection(context_words))
return min(overlap / len(context_words), 1.0)
def _assess_relevance(self, output: str, context: str) -> float:
"""Assess relevance of output to context"""
if not context:
return 0.5
# Simple semantic relevance (in practice, you'd use more sophisticated methods)
output_lower = output.lower()
context_lower = context.lower()
# Check for key terms from context appearing in output
context_terms = context_lower.split()
relevant_terms = [term for term in context_terms if term in output_lower]
if len(context_terms) == 0:
return 0.5
return len(relevant_terms) / len(context_terms)
# Usage with custom evaluator
custom_evaluator = CustomQualityEvaluator(
pass_fail_criteria={
"quality_score": PassFailCriteria(
on_each_entry_pass_if=PassFailCriteriaOnEachEntry(">=", 0.7),
for_testrun_overall_pass_if=PassFailCriteriaForTestrunOverall(">=", 0.8, "average")
)
}
)
# Use in your application
@logger.trace(name="custom_quality_evaluation")
def evaluate_response_quality(user_input: str, ai_response: str, context: str):
generation = logger.current_trace().generation({
"id": "quality-eval-generation",
"provider": "openai",
"model": "gpt-4",
"messages": [{"role": "user", "content": user_input}],
"name": "quality_evaluation"
})
# Attach custom evaluator
generation.evaluate().with_evaluators(custom_evaluator)
# Provide variables
generation.evaluate().with_variables(
{
"input": user_input,
"context": context
},
["quality_score"]
)
generation.result({"choices": [{"message": {"content": ai_response}}]})
generation.evaluate().with_variables(
{"output": ai_response},
["quality_score"]
)
return ai_response
Best Practices
1. Strategic Evaluator Selection
- Use evaluators selectively to monitor key performance metrics. Don’t overdo with attaching too many evaluators.
- Choose evaluators based on your use case:
- For customer service:
helpfulness, clarity, toxicity
- For content generation:
coherence, relevance, creativity
- For technical documentation:
accuracy, completeness, clarity
2. Variable Management
- Attach variables reliably to ensure no evaluation is left pending due to lack of variables.
- Use meaningful variable names that clearly indicate their purpose.
- Provide context when available - many evaluators perform better with additional context.
- Setup sampling and filtering according to your needs to ensure accurate evaluation processing without eating up too much cost.
- Use local evaluators for simple, fast evaluations that don’t require external API calls.
- Batch evaluations when possible to reduce overhead.
4. Custom Evaluator Development
- Inherit from BaseEvaluator for consistent behavior.
- Define clear pass/fail criteria that align with your business objectives.
- Include detailed reasoning in your evaluation results for better debugging.
- Test your custom evaluators thoroughly before deploying to production.
5. Error Handling and Monitoring
- Monitor evaluation results regularly to identify patterns and issues.
- Set up alerts for evaluations that consistently fail or score poorly.
- Review evaluation reasoning to understand why certain outputs are scored low.
6. Integration Patterns
- Use decorators for simple, repetitive evaluation patterns.
- Use programmatic evaluation for complex, conditional evaluation logic.
- Combine multiple evaluation strategies for comprehensive assessment.
Troubleshooting Common Issues
Missing Variables
If you see “Missing variables” messages:
- Check that all required variables are provided
- Verify variable names match exactly what the evaluator expects
- Ensure variables are attached to the correct evaluators
Evaluation Not Running
If evaluations aren’t processing:
- Verify evaluators are properly attached with
with_evaluators()
- Check that all required variables are provided
- Ensure the component (generation, retrieval, etc.) is properly ended
Custom Evaluator Issues
If custom evaluators aren’t working:
- Verify the evaluator inherits from
BaseEvaluator
- Check that
pass_fail_criteria are properly defined
- Ensure the
evaluate() method returns the correct format
- Test the evaluator in isolation before integration
Advanced Use Cases
A/B Testing with Evaluations
# Compare different models or prompts using evaluations
@logger.trace(name="ab_test_evaluation")
def compare_models(user_input: str):
# Model A
model_a_response = generate_with_model_a(user_input)
model_a_generation = logger.current_trace().generation({
"id": "model-a-response",
"provider": "openai",
"model": "gpt-3.5-turbo",
"name": "model_a"
})
model_a_generation.evaluate().with_evaluators("quality", "speed")
model_a_generation.result({"choices": [{"message": {"content": model_a_response}}]})
# Model B
model_b_response = generate_with_model_b(user_input)
model_b_generation = logger.current_trace().generation({
"id": "model-b-response",
"provider": "openai",
"model": "gpt-4",
"name": "model_b"
})
model_b_generation.evaluate().with_evaluators("quality", "speed")
model_b_generation.result({"choices": [{"message": {"content": model_b_response}}]})
return {"model_a": model_a_response, "model_b": model_b_response}