7 Signs Your AI Agent is Failing in Production and What to Do

TL;DR
Production AI agents face critical reliability challenges, with over 40% of projects expected to be canceled by 2027. The seven key warning signs include inconsistent response quality, frequent hallucinations, security vulnerabilities, performance degradation, poor tool orchestration, memory loss in extended sessions, and rising error rates. Each failure mode stems from specific technical issues ranging from prompt design flaws to distribution shift. Solutions require comprehensive observability through distributed tracing, robust evaluation frameworks with automated quality checks, simulation testing across diverse scenarios, and continuous production monitoring. Maxim AI provides an end-to-end platform integrating experimentation, simulation, evaluation, and observability to help teams ship reliable AI agents 5x faster while addressing all seven failure modes systematically.
Production AI agents represent a significant investment for organizations seeking to automate complex workflows and enhance operational efficiency. However, the gap between prototype success and production reliability remains substantial. Recent data from Gartner reveals that over 40% of agentic AI projects are expected to be canceled by 2027 due to escalating costs, unclear business value, and inadequate risk controls. Furthermore, benchmarking studies indicate that leading AI models fail at office tasks 91 to 98 percent of the time, exposing the critical reliability challenges facing production deployments.
Understanding the warning signs of agent failure enables teams to implement corrective measures before system breakdowns erode user trust and business value. This article examines seven critical indicators that your AI agent is failing in production, the underlying technical causes, and evidence-based strategies for remediation using comprehensive observability, evaluation, and simulation frameworks.
Sign 1: Inconsistent Response Quality Across Similar Queries
Production agents that generate varying quality outputs for semantically similar inputs signal fundamental reliability issues. While some variability stems from the probabilistic nature of large language models, excessive inconsistency indicates poor prompt design, insufficient context management, or distribution shift.
Technical Root Causes
Response inconsistency manifests through multiple failure modes. Temperature and sampling parameters that favor creativity over consistency produce unpredictable outputs unsuitable for production use cases requiring deterministic behavior. Context window limitations force agents to discard relevant information as conversations extend, leading to degraded performance in multi-turn interactions. Models operating outside their training distribution encounter increased uncertainty, generating outputs that deviate from expected quality standards.
Recent research from S&P Global demonstrates that 42% of companies abandoned the majority of their AI initiatives in 2024, with inconsistent performance ranking among the primary failure drivers. Organizations report that agents handle routine queries successfully but fail on edge cases or contextually nuanced requests, creating unpredictable user experiences that undermine adoption.
Solution Framework
Establishing baseline quality metrics provides the foundation for detecting inconsistency. Teams should implement automated evaluations on production logs to continuously assess output quality across diverse query patterns. Semantic similarity evaluators measure response consistency for equivalent questions, while task success metrics quantify completion rates across different user formulations of identical requests.
Prompt versioning and optimization enable systematic experimentation with prompt designs that reduce variability. Explicit instructions encouraging consistent formatting, standardized reasoning approaches, and deterministic outputs help constrain model behavior. For critical workflows requiring high consistency, implementing prompt deployment with versioned prompts ensures controlled rollouts and rapid rollback capabilities when quality regressions occur.
Comprehensive observability through distributed tracing enables pattern identification across production interactions. By analyzing traces from successful and failed completions, teams can identify specific query characteristics, context patterns, or workflow states that correlate with quality degradation. This data-driven approach reveals optimization opportunities invisible during pre-production testing.
Sign 2: Frequent Hallucinations and Factual Errors
Hallucinations represent one of the most damaging failure modes for production AI agents, particularly in domains requiring factual accuracy such as healthcare, legal services, and financial advising. Research published in Nature demonstrates that semantic entropy-based methods can effectively detect confabulations, but proactive prevention remains essential for production reliability.
Understanding Hallucination Patterns
Hallucination rates vary significantly across tasks and model configurations. Studies show rates ranging from 3% on text summarization to over 90% on specialized tasks like systematic literature reviews or legal citation generation. The probabilistic decoding mechanisms in transformer-based language models optimize for linguistic fluency rather than factual accuracy, producing plausible but incorrect information when knowledge gaps exist.
Production environments exacerbate hallucination risks through several factors. Complex multi-step reasoning chains amplify errors as mistakes in early reasoning steps propagate through subsequent operations. Retrieval-augmented generation systems that retrieve low-quality or contradictory documents provide unreliable grounding for model responses. Context overflow conditions force truncation of relevant information, leaving models with insufficient context for accurate responses.
Detection and Mitigation Strategies
Implementing multi-layered hallucination detection provides defense in depth against factual errors. For retrieval-augmented generation applications, context precision evaluators assess whether retrieved documents contain information relevant to query answering, while context recall evaluators verify that retrieved content includes all information necessary for complete responses.
Faithfulness evaluation measures whether agent outputs remain grounded in provided context without introducing unsupported claims. This evaluator compares generated responses against source documents to identify speculative additions or factual deviations. Production systems should configure automated faithfulness checks to flag suspicious outputs before they impact end users.
Strategic prompt engineering significantly reduces hallucination frequency. System prompts should explicitly instruct agents to acknowledge uncertainty rather than generating speculative responses. Prompt partials enable reusable components encoding hallucination prevention best practices, such as requirements to cite sources or explicit uncertainty acknowledgment patterns.
Knowledge base integration through curated context sources grounds agent responses in verified information. By connecting production agents to authoritative data repositories with version control and quality validation, organizations establish clear boundaries around agent knowledge while enabling continuous knowledge base updates without model retraining.
Sign 3: Unexpected Security Vulnerabilities and Prompt Injection Attempts
Security failures in production AI agents carry significant consequences including unauthorized data access, system compromise, and regulatory violations. Unlike traditional software vulnerabilities exploiting code flaws, prompt injection attacks manipulate the linguistic interface between users and models to bypass intended constraints and trigger harmful behaviors.
Attack Vectors and Impact
Research from security conferences including IEEE Symposium on Security and Privacy demonstrates that current defenses remain imperfect, with sophisticated attacks circumventing safety measures through various techniques. Instruction hijacking embeds malicious directives within seemingly benign user inputs, overriding system instructions. Context manipulation crafts inputs that shift agent behavior toward attacker objectives across multi-turn interactions. Tool exploitation targets agent tool-calling capabilities to trigger unauthorized actions or access restricted resources.
Production systems face both direct attacks where users explicitly attempt manipulation and indirect attacks where malicious content embeds within documents or data sources that agents retrieve during operation. The increasing sophistication of adversarial techniques requires continuous security monitoring and defense updates.
Security Implementation
Establishing clear architectural boundaries between system instructions and user-controllable content provides foundational protection. While most LLM APIs process all content within the same context window, prompt positioning and explicit security instructions create logical separation. System prompts containing operational guidelines and access controls should appear before user inputs with clear delineation.
Input validation and sanitization filter potentially malicious content before model processing. Regular expression patterns and keyword filtering identify common attack signatures, while LLM-based content moderation provides semantic analysis of input intent. Organizations should implement PII detection evaluators to prevent inadvertent disclosure of sensitive information in agent responses.
Continuous monitoring for anomalous behavior patterns enables early attack detection. Alert configuration with thresholds for security metrics triggers notifications through integrations with Slack or PagerDuty when suspicious patterns emerge. Teams can analyze production traces to identify attempted injections and evolving attack strategies.
Regular security audits using simulation testing with adversarial scenarios reveal vulnerabilities before exploitation. Systematic testing across attack patterns helps validate defense mechanisms and identify gaps requiring remediation.
Sign 4: Degrading Performance and Increasing Latency
Performance degradation manifests through two distinct categories: infrastructure constraints limiting response speed and algorithmic inefficiency where agents perform unnecessary operations. Production latency directly impacts user experience, with studies showing that delays exceeding two seconds significantly reduce user satisfaction and engagement.
Diagnosing Latency Sources
Agent trajectory analysis reveals common inefficiency patterns contributing to latency. Production logs frequently show agents making redundant tool calls with identical parameters due to poor state management, executing unnecessary intermediate reasoning steps that consume inference cycles without advancing task completion, and following suboptimal solution paths before backtracking to viable approaches.
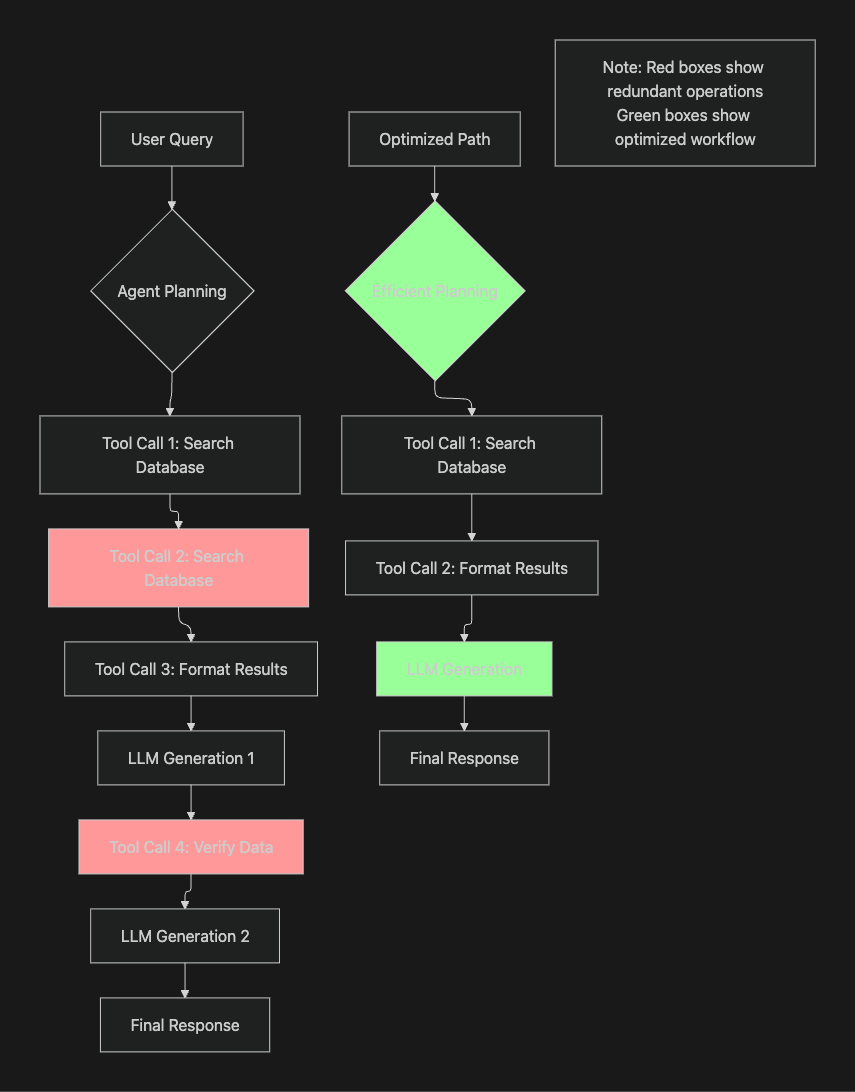
Infrastructure factors compound these issues. Model inference time scales with model size and sequence length, with larger models requiring proportionally more computational resources. Each tool call introduces network round trips and external API latency that accumulates across multi-step workflows. Multi-agent systems amplify delays through coordination overhead and sequential dependencies between agent operations.
Performance Optimization Approaches
Step utility evaluation enables quantitative assessment of each action's contribution toward task completion. By analyzing production trajectories, teams identify redundant operations and optimize agent behavior patterns. This analysis should examine both successful completions and failed attempts to understand efficiency-outcome relationships across different workflow paths.
Trajectory optimization through strategic prompt engineering guides agents toward more efficient execution. Instructions specifying preferred reasoning strategies, establishing tool usage hierarchies, and encouraging minimal-step solutions help agents avoid unnecessary verification loops and premature optimization. Clear success criteria in prompts reduce excessive validation steps.
Semantic caching through Bifrost, Maxim's AI gateway, stores responses for semantically similar queries rather than requiring exact text matching. This approach enables response reuse across equivalent requests phrased differently, significantly reducing redundant inference costs and latency for common query patterns.
Distributed tracing provides complete visibility into production execution paths including tool calls, reasoning steps, and timing information. This granular observability enables identification of specific bottlenecks and optimization opportunities that testing environments cannot reveal. Custom dashboards allow teams to monitor latency metrics across custom dimensions relevant to their specific applications.
Sign 5: Poor Tool Selection and Orchestration Failures
AI agents extend language model capabilities through connections to external tools, APIs, and data sources. Production failures occur when agents select inappropriate tools, misuse tool interfaces, or fail to properly orchestrate complex multi-tool workflows. Poor tool selection directly impacts task completion rates and user satisfaction.
Technical Orchestration Challenges
The challenge stems from the vast solution space agents navigate when multiple tools could potentially address a given task. Models must evaluate tool descriptions, match capabilities to requirements, and predict execution outcomes based on limited context. Ambiguous tool descriptions, overlapping functionality, and insufficient usage examples contribute to selection errors that cascade through downstream operations.
Orchestration complexity increases exponentially with available tool count. Multi-step workflows require agents to maintain state across tool calls, handle errors gracefully, and adapt plans based on intermediate results. Production data shows that tool call accuracy degrades as workflow complexity increases, particularly when tools have similar names or overlapping capabilities.
Implementation Best Practices
Comprehensive tool interface design significantly impacts selection accuracy. Tool descriptions should specify capabilities, input requirements, output formats, expected latency, and concrete usage examples. Prompt tools enable standardized tool definitions across agent implementations, ensuring consistent behavior and reducing selection ambiguity.
Evaluation frameworks measuring tool selection quality across diverse scenarios reveal systematic biases and failure patterns. Testing must cover edge cases, ambiguous requests requiring judgment, and workflows requiring multiple coordinated tool calls. Production monitoring identifies common tool usage patterns and selection errors that inform refinement strategies.
Hierarchical tool organization reduces selection complexity by grouping related capabilities into categories. Agents first select high-level tool categories before choosing specific implementations, narrowing the decision space at each level. This approach mirrors human problem-solving strategies and improves accuracy while reducing inference overhead from evaluating large tool sets simultaneously.
Error handling mechanisms ensure graceful degradation when tool calls fail rather than cascading failures that terminate entire workflows. Agents should implement retry logic with exponential backoff, fallback strategies using alternative tools, and clear error reporting that enables human intervention when automated recovery proves impossible.
Sign 6: Context Loss and Memory Degradation in Extended Sessions
Context window constraints represent a fundamental limitation of transformer-based language models. Production AI agents handling extended conversations or processing large documents encounter situations where relevant information exceeds available context capacity, leading to memory degradation and inconsistent behavior.
Understanding Memory Failures
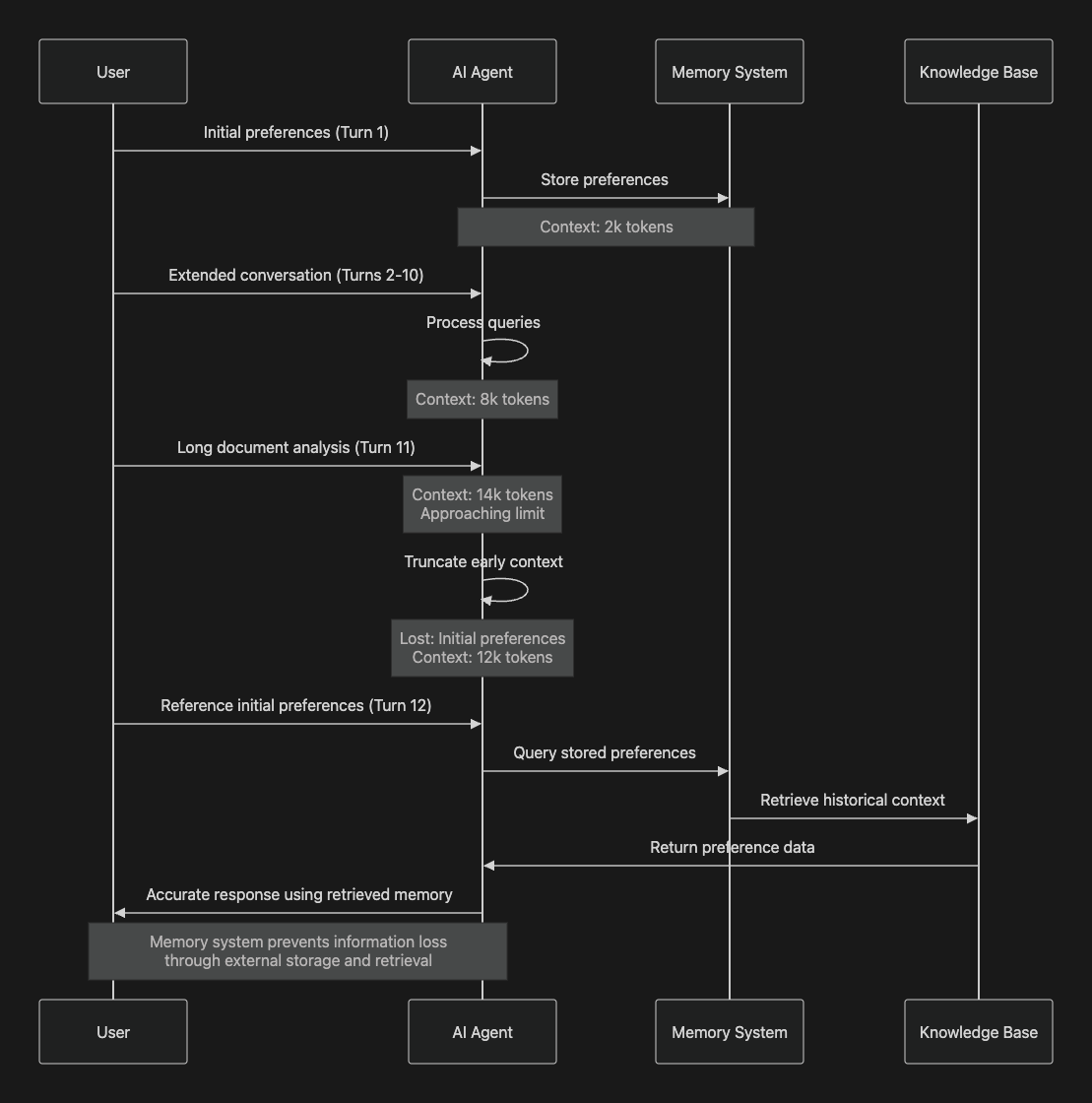
When conversation history exceeds the context window, agents must discard information to accommodate new inputs. Naive truncation strategies removing earliest conversation turns potentially eliminate critical context established during initial interactions. This manifests as agents forgetting previously stated user preferences, losing track of multi-turn instructions, contradicting earlier statements, or requesting information already provided.
Research from UC Berkeley demonstrates that model performance degrades significantly when relevant information appears near context window boundaries, a phenomenon termed "lost in the middle" effect. Models exhibit recency bias, prioritizing recently processed information over content from earlier context positions. This bias compounds memory degradation effects in extended production sessions.
Memory Management Strategies
Intelligent context compression techniques preserve essential information while reducing token consumption. Summarization approaches condense conversation history into compact representations retaining key facts, decisions, and user preferences. Dynamic compression adjusts detail levels based on information relevance and recency, maintaining critical context while discarding verbose intermediate exchanges.
Hierarchical memory architectures separate short-term working memory from long-term knowledge storage. Agents maintain recent conversation context in the immediate context window while storing historical information in external databases. Session management systems track user interactions across extended timescales, enabling retrieval of relevant historical context when agents encounter references to previous conversations.
Retrieval-augmented memory systems query external knowledge bases to access information beyond immediate context windows. When agents detect references to previous interactions, they retrieve relevant conversation segments rather than maintaining everything in active context. This approach scales to arbitrarily long interaction histories while preserving access to historical information.
Context window expansion through strategic model selection provides direct solutions when available. Recent models offer significantly larger context windows, with some supporting over 100,000 tokens. However, teams must balance context capacity against increased latency and computational costs associated with processing larger contexts. Unified access through Bifrost enables seamless switching between models with different context capacities based on specific use case requirements.
Sign 7: Increasing Error Rates and Task Completion Failures
Rising error rates and declining task completion indicate systematic problems requiring immediate attention. Unlike isolated failures attributable to specific edge cases, systematic degradation suggests fundamental issues with agent architecture, training data distribution, or environmental changes.
Root Causes of Systematic Failures
Distribution shift occurs when production data diverges from training distribution. Agents optimized on specific datasets perform excellently in testing but fail when encountering production scenarios differing from training conditions. Temporal drift represents gradual distribution shift as user behavior, language patterns, or domain knowledge evolves over time. Without continuous monitoring, performance degradation from temporal drift remains undetected until user complaints emerge.
Overfitting manifests when models memorize training patterns rather than learning generalizable capabilities. While achieving high accuracy on test sets, overfitted models perform poorly on variations not represented in training data. Production environments introduce natural variation in user language, query patterns, and contextual factors exposing overfitting vulnerabilities.
Tool integration failures emerge as external dependencies evolve. API specification changes, service deprecations, or network connectivity issues disrupt agent tool-calling capabilities. Without proper error handling and monitoring, these failures cascade through workflows causing complete task breakdowns.
Comprehensive Solution Framework
Continuous evaluation on production data enables early detection of distribution shift and quality degradation. Teams should establish baseline performance metrics on representative production samples and monitor for deviations over time. Online evaluations provide real-time quality assessment as production conditions evolve, enabling proactive response before widespread failures impact users.
Simulation testing across diverse scenarios and user personas reveals brittleness before production deployment. Comprehensive stress testing with edge cases, unusual query patterns, and adversarial examples exposes failure modes that standard evaluation misses. Text-based simulations replicate real-world user interactions across multiple personas with varying expertise levels, enabling teams to validate agent robustness.
Regular model updates and retraining incorporate new production patterns into model knowledge. Data collection pipelines should capture representative production samples for inclusion in training datasets. This feedback loop helps models adapt to evolving distributions while maintaining performance on historical patterns. Dataset curation workflows support systematic collection and organization of production data for continuous improvement.
Agent trajectory analysis reveals systematic patterns in successful versus failed attempts. By comparing execution paths, teams identify specific decision points, tool selections, or reasoning steps that correlate with failures. This enables targeted remediation addressing root causes rather than symptomatic issues.
Establishing clear task success evaluation criteria provides objective measures of agent effectiveness. Production monitoring should track task completion rates, error categorization, and failure mode distribution to quantify quality trends and inform optimization priorities.
Building Production-Ready AI Agents with Maxim
Addressing production failures requires comprehensive tooling spanning the entire AI lifecycle from pre-production testing through continuous production monitoring. Maxim AI provides an end-to-end platform for simulation, evaluation, and observability, enabling teams to ship reliable AI agents 5x faster.
The experimentation platform accelerates prompt engineering through the Playground++, enabling rapid iteration, versioning, and deployment. Teams can compare output quality, cost, and latency across various combinations of prompts, models, and parameters to identify optimal configurations before production deployment.
Comprehensive simulation capabilities enable stress testing across hundreds of scenarios and user personas. Teams can evaluate agents at conversational level, analyze trajectory choices, assess task completion, and identify failure points. Re-running simulations from any step enables root cause analysis and iterative improvement.
The unified evaluation framework combines machine and human evaluations through an extensive evaluator library with AI-powered, statistical, and programmatic evaluators. Teams can quantify improvements across prompt versions and workflows while incorporating human annotation for nuanced quality assessment.
Production observability through distributed tracing provides complete visibility into agent execution paths including tool calls, reasoning chains, and external API interactions. Real-time automated evaluations assess production quality continuously, with configurable alerts enabling rapid response to quality degradation.
The data engine facilitates seamless dataset management with capabilities for importing, curating, and enriching multi-modal datasets for evaluation and fine-tuning. Continuous dataset evolution from production logs ensures evaluation remains representative of real-world conditions.
Conclusion
Production AI agent failures stem from predictable technical challenges spanning hallucination risks, security vulnerabilities, performance degradation, orchestration complexity, memory limitations, and distribution shift. The statistics remain sobering, with 40 percent project cancellation rates and 91 to 98 percent task failure rates for leading models. Organizations cannot approach production deployment casually.
Success requires systematic approaches combining comprehensive observability to detect issues early, robust evaluation frameworks quantifying quality across multiple dimensions, simulation testing validating behavior across diverse scenarios, and continuous monitoring tracking quality as conditions evolve. Organizations implementing these practices achieve measurable reliability improvements and sustained business value from their AI investments.
Teams seeking to build production-ready AI agents need platforms supporting the complete lifecycle from experimentation through production monitoring. By integrating evaluation, simulation, and observability into unified workflows, organizations move confidently from prototype to production with agents that deliver consistent, reliable performance.
Ready to eliminate production failures and ship reliable AI agents faster? Schedule a demo to see how Maxim helps leading teams achieve production reliability, or sign up today to start building AI applications with comprehensive quality assurance from development through deployment.


