Prerequisites
Before getting started, ensure you have:- A Maxim account with API access
- Python environment (Google Colab or local setup)
- A published and deployed prompt in Maxim
- Basic understanding of Python and data structures
Setting Up Environment
1. Install Maxim Python SDK
2. Import Required Modules
3. Configure API Keys and IDs
- API Key: Go to Maxim Settings → API Keys → Create new API key
- Workspace ID: Click on workspace dropdown and copy the workspace ID
- Prompt ID: Navigate to your published prompt and copy the ID from the URL
4. Initialize Maxim
Step 1: Define Data Structure
Local datasets in Maxim must follow a specific data structure with predefined column types:INPUT: Main input text (required, only one per dataset)EXPECTED_OUTPUT: Expected response for comparisonCONTEXT_TO_EVALUATE: Context information for evaluationVARIABLE: Additional data columnsNULLABLE_VARIABLE: Optional data columns
Step 2: Create Custom Evaluators
Quality Evaluator (AI-based)
Safety Evaluator (AI-based)
Keyword Presence Evaluator (Programmatic)
Step 3: Prepare Your Data Source
Option A: Manual Data (Small Datasets)
For small datasets, you can define data directly in your code:Option B: CSV File Data Source
For larger datasets stored in CSV files:Option C: Database or Other Sources
You can adapt the data loading function for any data source:Step 4: Create and Run Test
Configure Pass/Fail Criteria
Execute Test Run
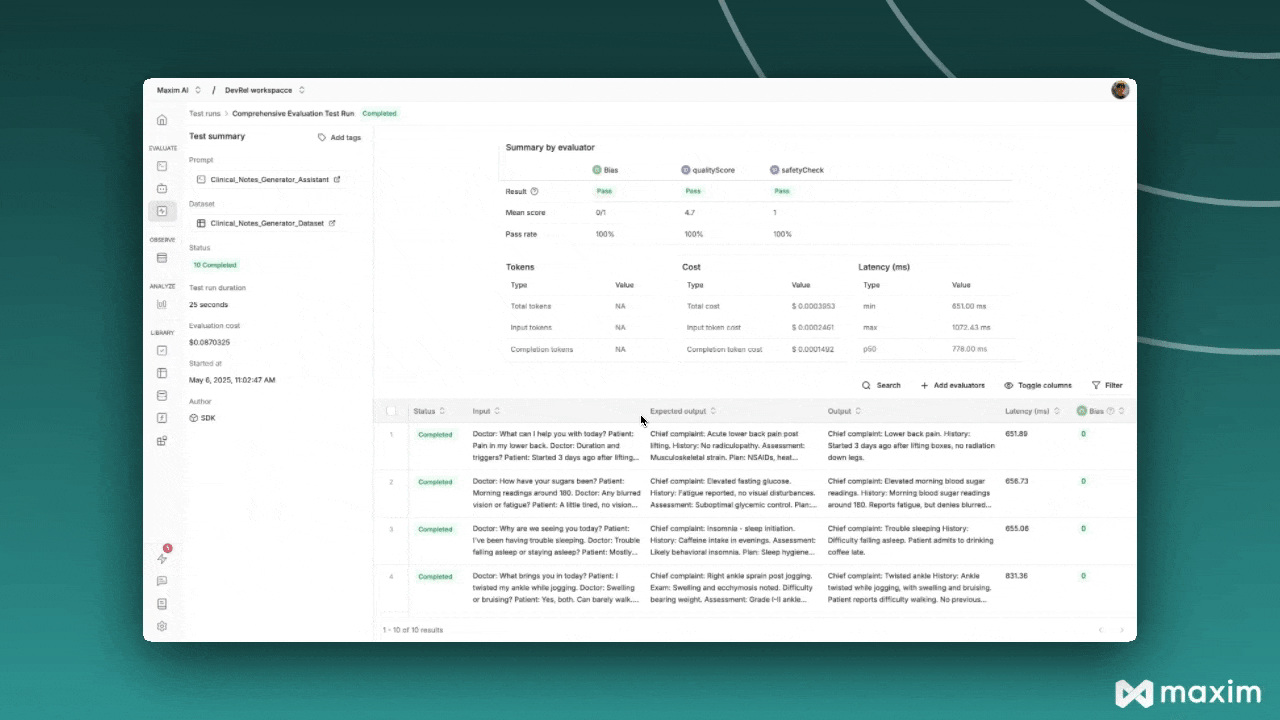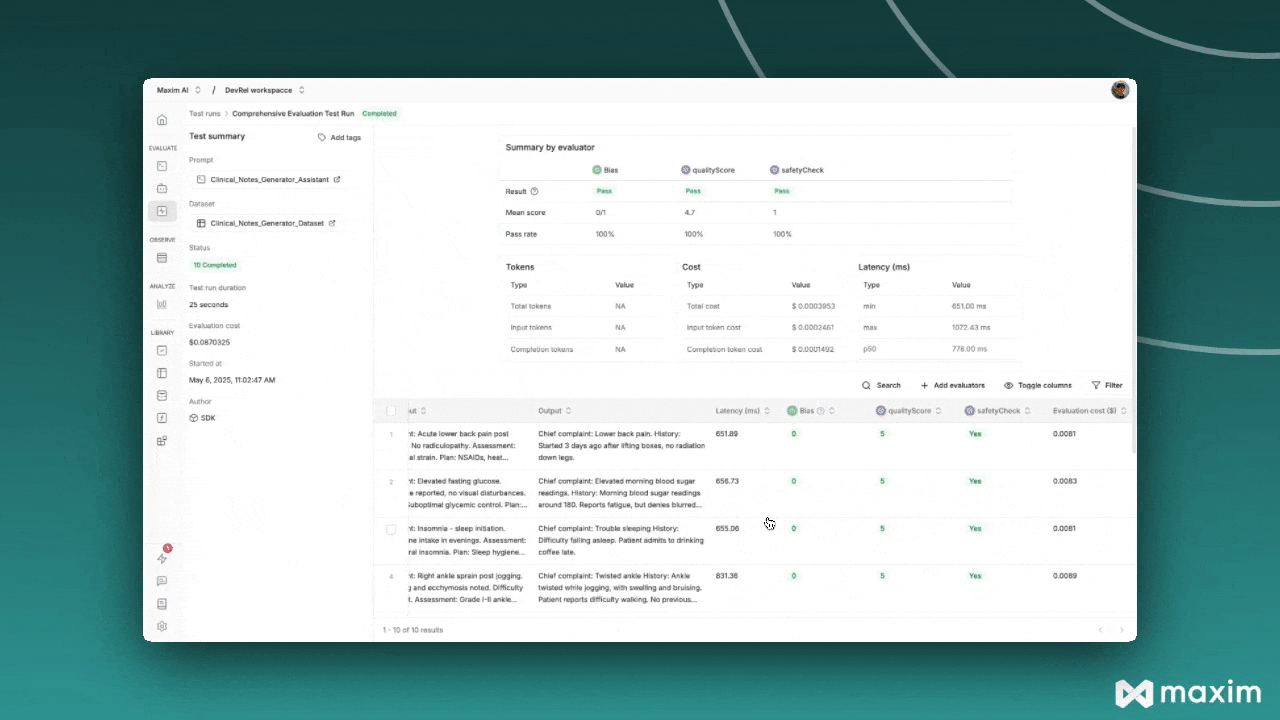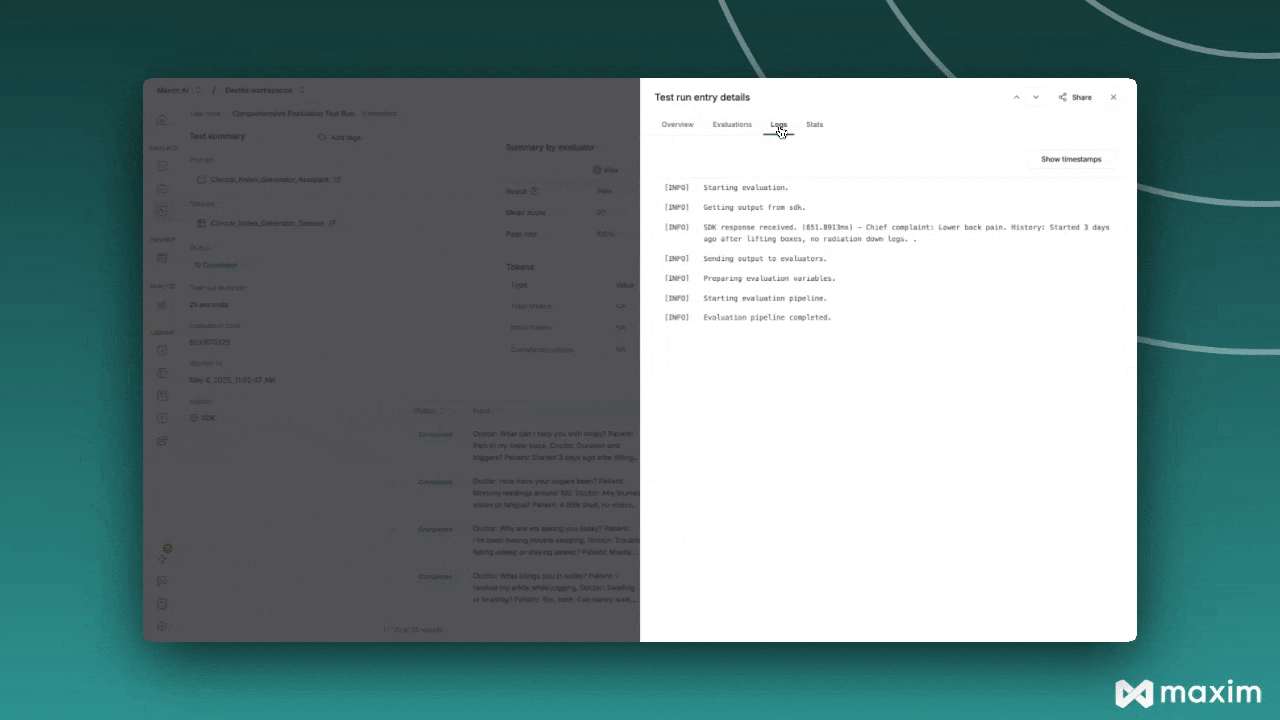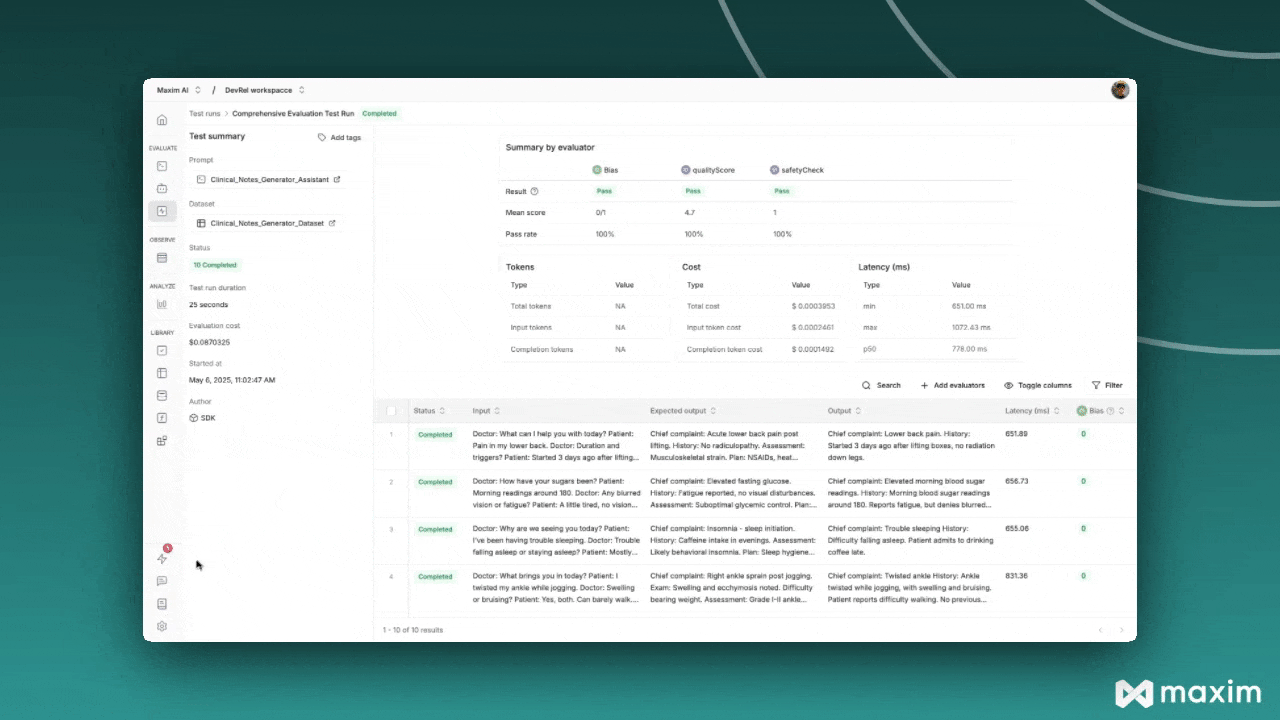
Step 5: Monitor Results
After triggering the test run, you can monitor its progress in the Maxim platform:- Navigate to Test Runs in your Maxim workspace
- Find your test run by name
- Monitor the execution status and results
- Review individual evaluations and scores
Best Practices
Data Structure Guidelines
- Always use the exact column names as defined in your data structure
- Ensure consistency between your data structure definition and actual data
- Include meaningful expected outputs for better evaluation accuracy
Custom Evaluator Tips
- Keep evaluation logic focused and specific
- Provide clear reasoning in your evaluator responses
- Test custom evaluators independently before integration
Troubleshooting
Common Issues
Data Structure Mismatch:- Verify your API key is active and has the necessary permissions
- Ensure workspace ID corresponds to the correct workspace
- Check that your prompt is published and deployed
Resources
Cookbook Code
Python Notebook for Local Dataset Test Runs via Maxim SDK