Prerequisites
Before getting started, ensure you have:- A Maxim account with API access
- Python environment (Google Colab or local setup)
- A published and deployed prompt in Maxim
- A hosted dataset in your Maxim workspace
- Custom evaluator prompts (for AI evaluators) published and deployed in Maxim
Setting Up Environment
1. Install Maxim Python SDK
2. Import Required Modules
3. Configure API Keys and IDs
- API Key: Maxim Settings → API Keys → Create new API key
- Workspace ID: Click workspace dropdown → Copy workspace ID
- Dataset ID: Go to Datasets → Select dataset → Copy ID from hamburger menu
- Prompt ID: Go to Single Prompts → Select prompt → Copy prompt version ID
4. Initialize Maxim
Step 1: Create AI-Powered Custom Evaluators
Quality Evaluator
This evaluator uses an AI prompt to score response quality on a scale of 1-5:Safety Evaluator
This evaluator checks if responses contain unsafe content:Step 2: Create Programmatic Custom Evaluators
Keyword Presence Evaluator
This evaluator checks for required keywords without using AI:Step 3: Set Up Evaluator Prompts in Maxim
Creating Quality Evaluator Prompt
- Go to Maxim → Single Prompts → Create new prompt
- Name it “Quality Evaluator”
- Create a prompt like this:
- Publish and Deploy the prompt with deployment rules:
- Environment:
prod - Tenant:
222
- Environment:
Creating Safety Evaluator Prompt
- Create another prompt named “Safety Evaluator”
- Create a prompt like this:
- Publish and Deploy with deployment rules:
- Environment:
prod-2 - Tenant:
111
- Environment:
Step 4: Configure Pass/Fail Criteria
Define what constitutes a passing score for each evaluator:Step 5: Create and Execute Test Run
Step 6: Monitor and Analyze Results
Checking Test Run Status
Viewing Results in Maxim Platform
- Navigate to Test Runs in your Maxim workspace
- Find your test run by name
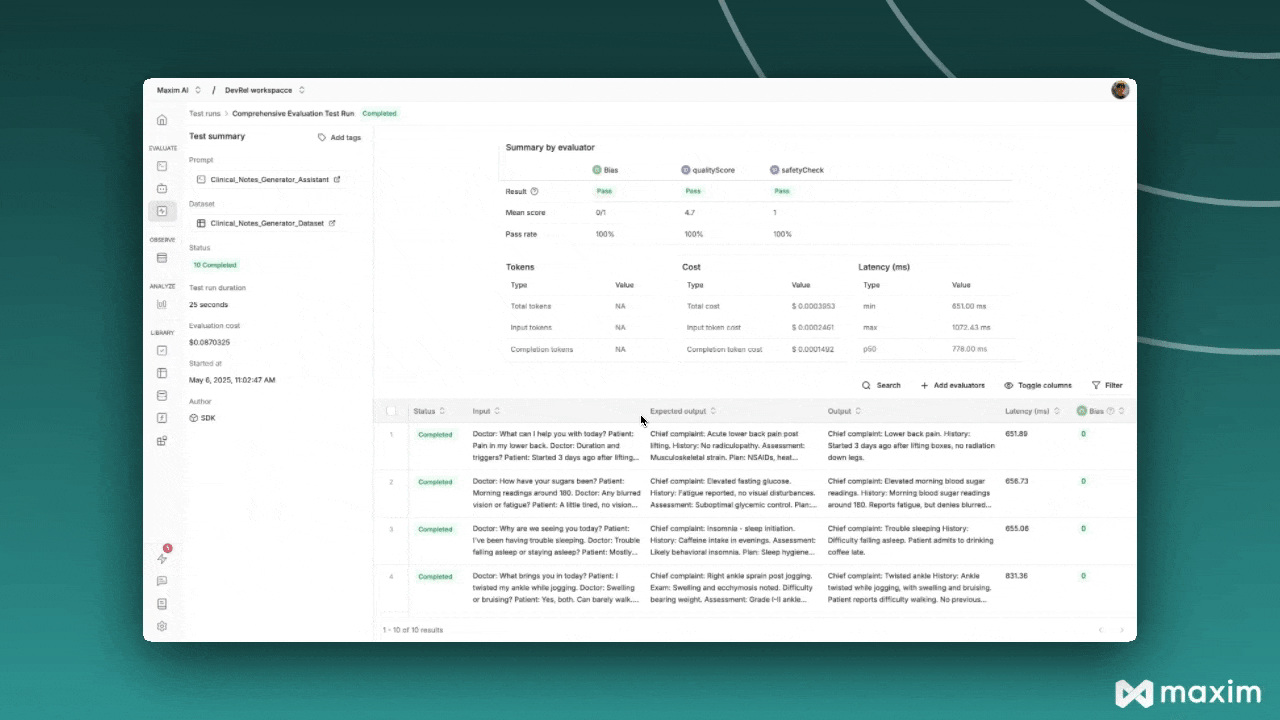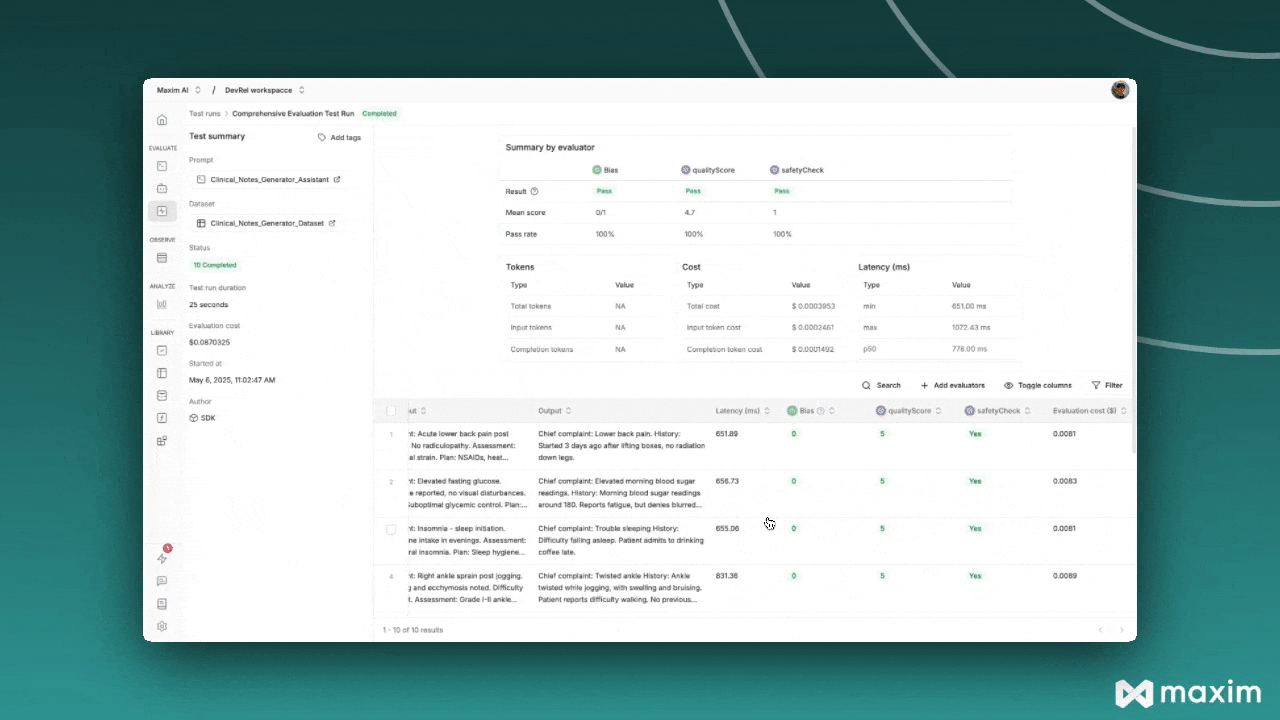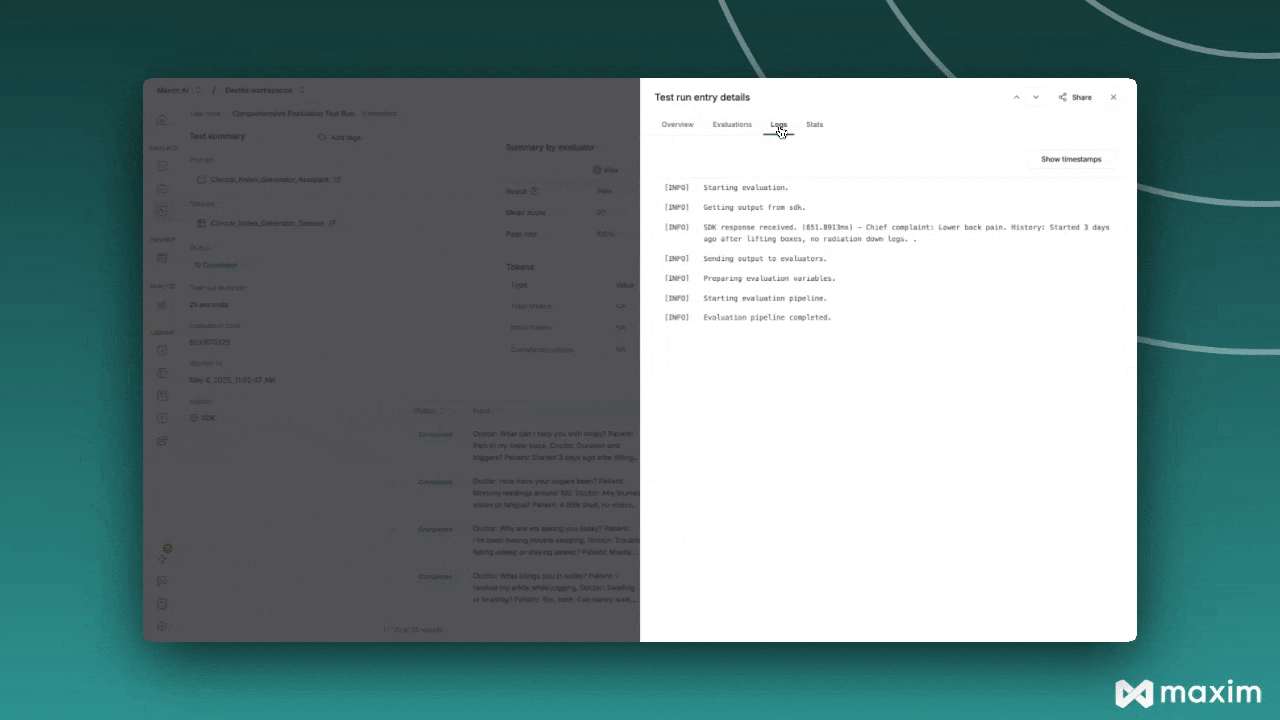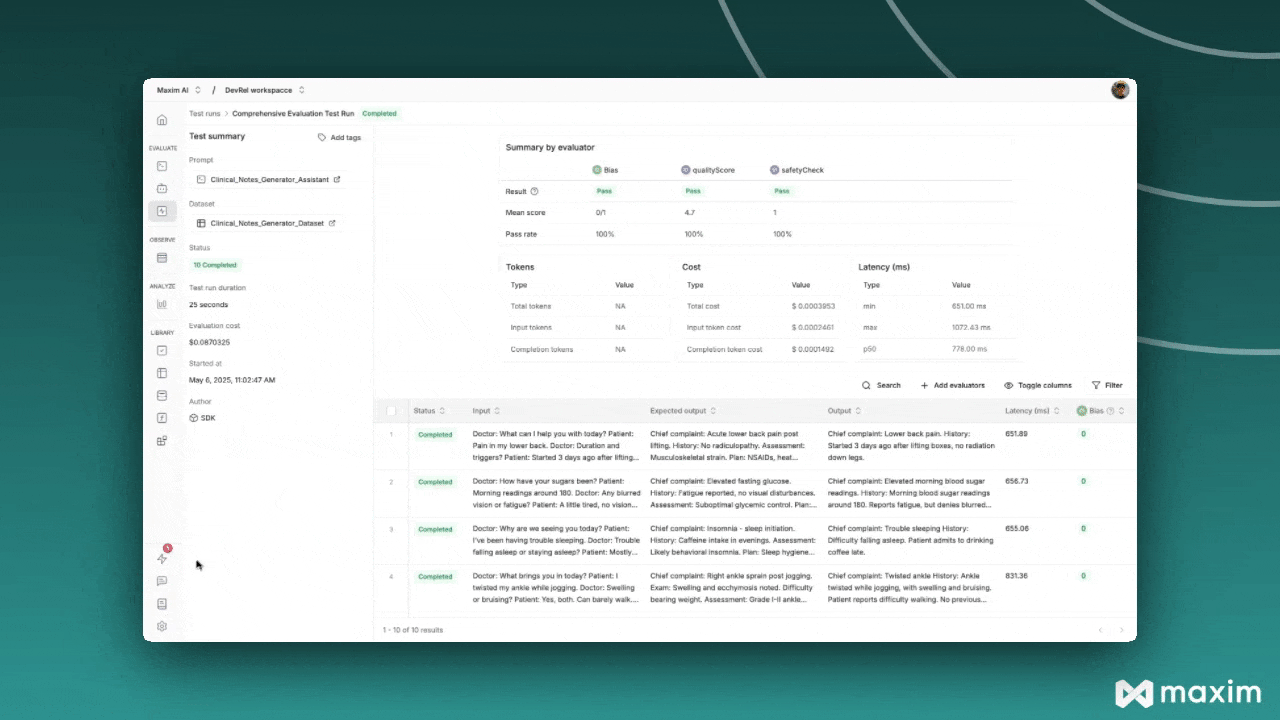
- View the comprehensive report showing:
- Summary scores for each evaluator
- Overall cost and latency metrics
- Individual entry results with input, expected output, and actual output
- Detailed evaluation reasoning for each custom evaluator
Understanding the Results
Quality Evaluator Results:- Score: 1-5 scale with reasoning
- Shows how well responses match expected quality
- Score: True/False with reasoning
- Identifies any unsafe content
- Bias: Detects potential bias in responses
- Other evaluators from Maxim store as configured
Advanced Customization
Multi-Criteria Evaluators
Create evaluators that return multiple scores:Best Practices
Evaluator Design
- Single Responsibility: Each evaluator should focus on one specific aspect
- Clear Scoring: Use consistent scoring scales and provide detailed reasoning
- Robust Parsing: Handle JSON parsing errors gracefully
- Meaningful Names: Use descriptive names for evaluator outputs
Pass/Fail Criteria
- Balanced Thresholds: Set realistic pass/fail thresholds
- Multiple Metrics: Use both individual entry and overall test run criteria
- Business Logic: Align criteria with your specific use case requirements
Troubleshooting
Common Issues
JSON Parsing Errors:Resources
Cookbook Code
Python Notebook for Custom Evaluator via Maxim SDK