Prerequisites
Before starting, ensure you have:- Python 3.10+
- A Maxim account (sign up here)
- Maxim API key and repository ID
- Together AI API key
Installation
Environment Setup
Create a.env file in your project root:
Basic Setup and Instrumentation
Import Required Libraries
Configure Together & Maxim
Simple Chat Completion Request
This example demonstrates basic chat completion with Together AI models.Create Client and Make Request
Example Output
The model will provide a comprehensive response about fun activities in New York, including:- Iconic landmarks (Statue of Liberty, Central Park, Times Square)
- Museums and galleries (Metropolitan Museum, MoMA, Natural History Museum)
- Performing arts (Broadway shows, Lincoln Center, Carnegie Hall)
- Food and drink recommendations (pizza, bagels, delis)
Streaming Request
This example demonstrates how to use streaming for real-time responses.Streaming Chat Completion
Benefits of Streaming
- Real-time responses: See the model’s response as it’s generated
- Better user experience: Users don’t have to wait for the complete response
- Lower perceived latency: Content appears immediately
- Full traceability: Maxim captures the entire streaming interaction
Async Requests
This example demonstrates how to make multiple concurrent requests using async operations.Async Chat Completions
Benefits of Async Operations
- Concurrent processing: Multiple requests processed simultaneously
- Improved performance: Faster overall execution time
- Resource efficiency: Better utilization of system resources
- Scalability: Handle multiple requests without blocking
Advanced Usage Examples
Custom Model Selection
Error Handling
Multi-turn Conversations
Complete Example
Here’s a comprehensive example that combines all the features: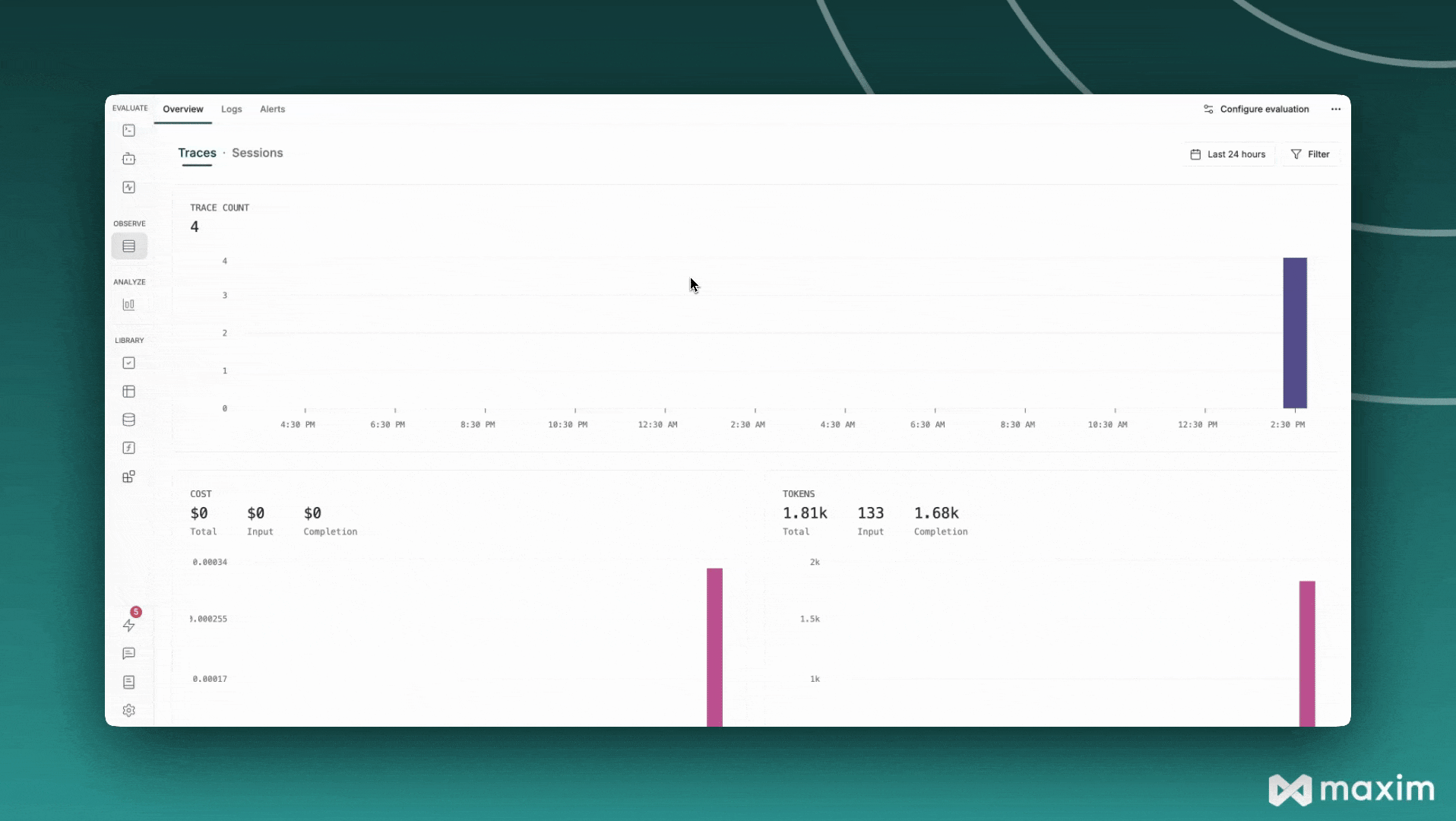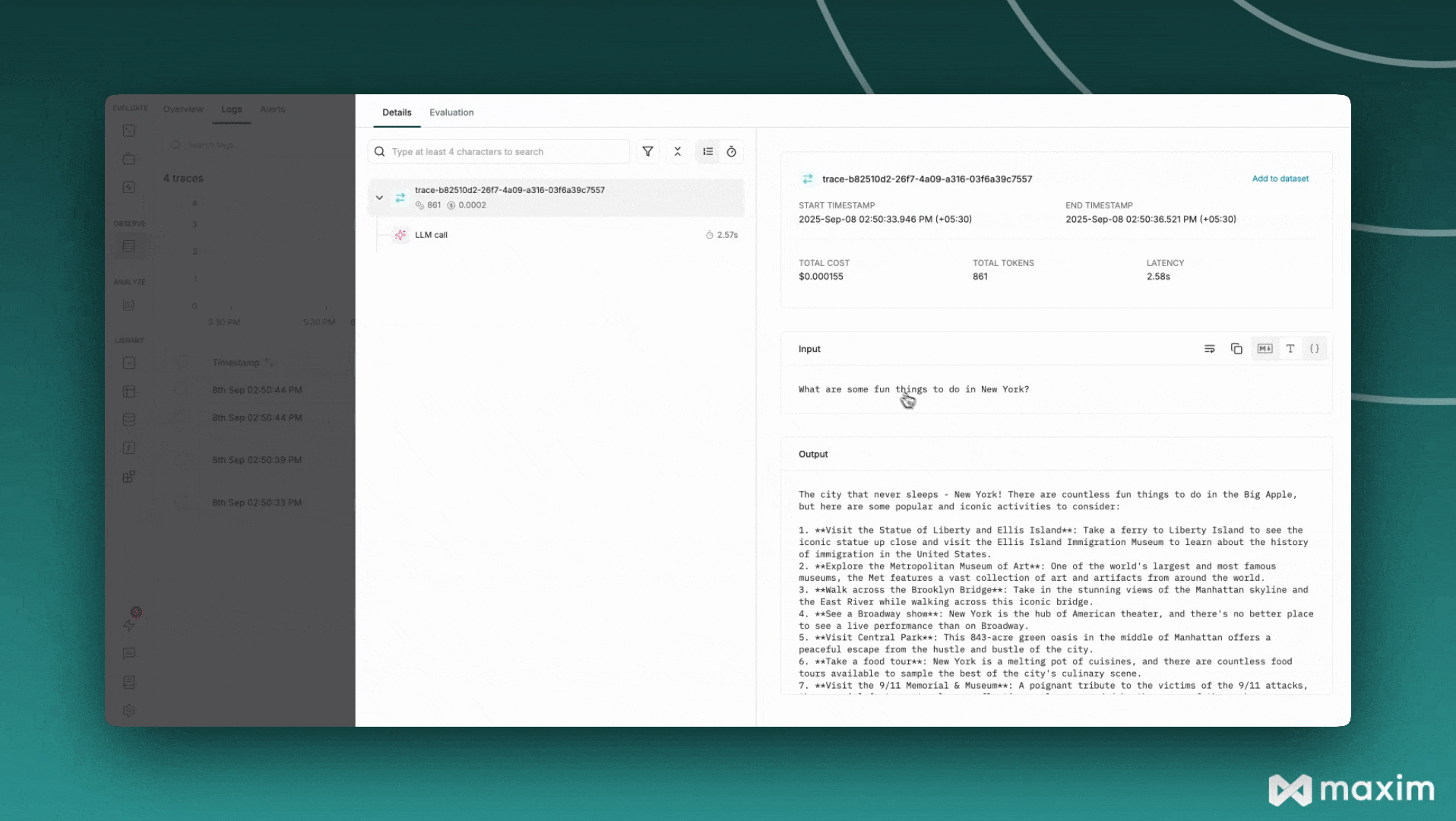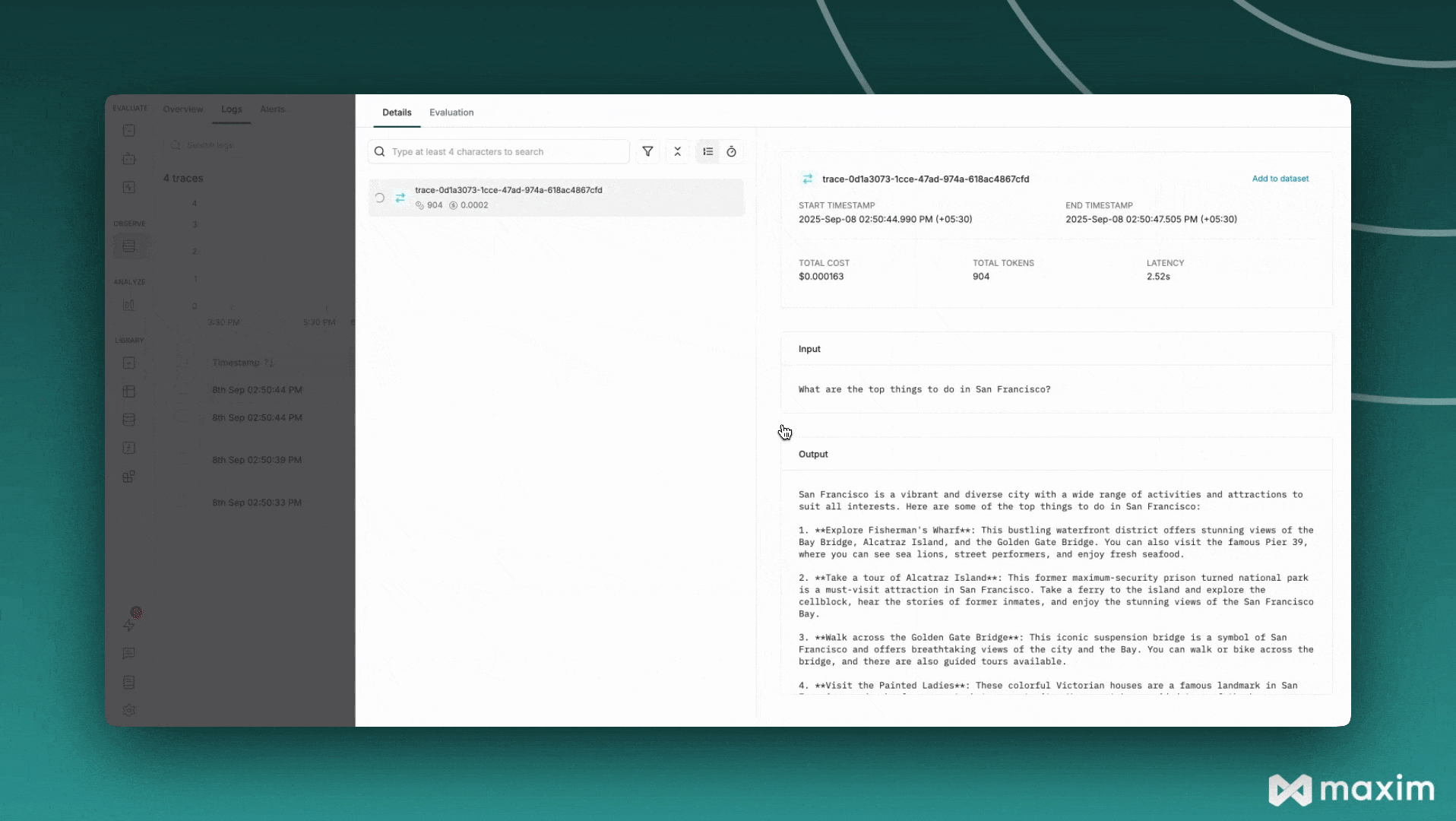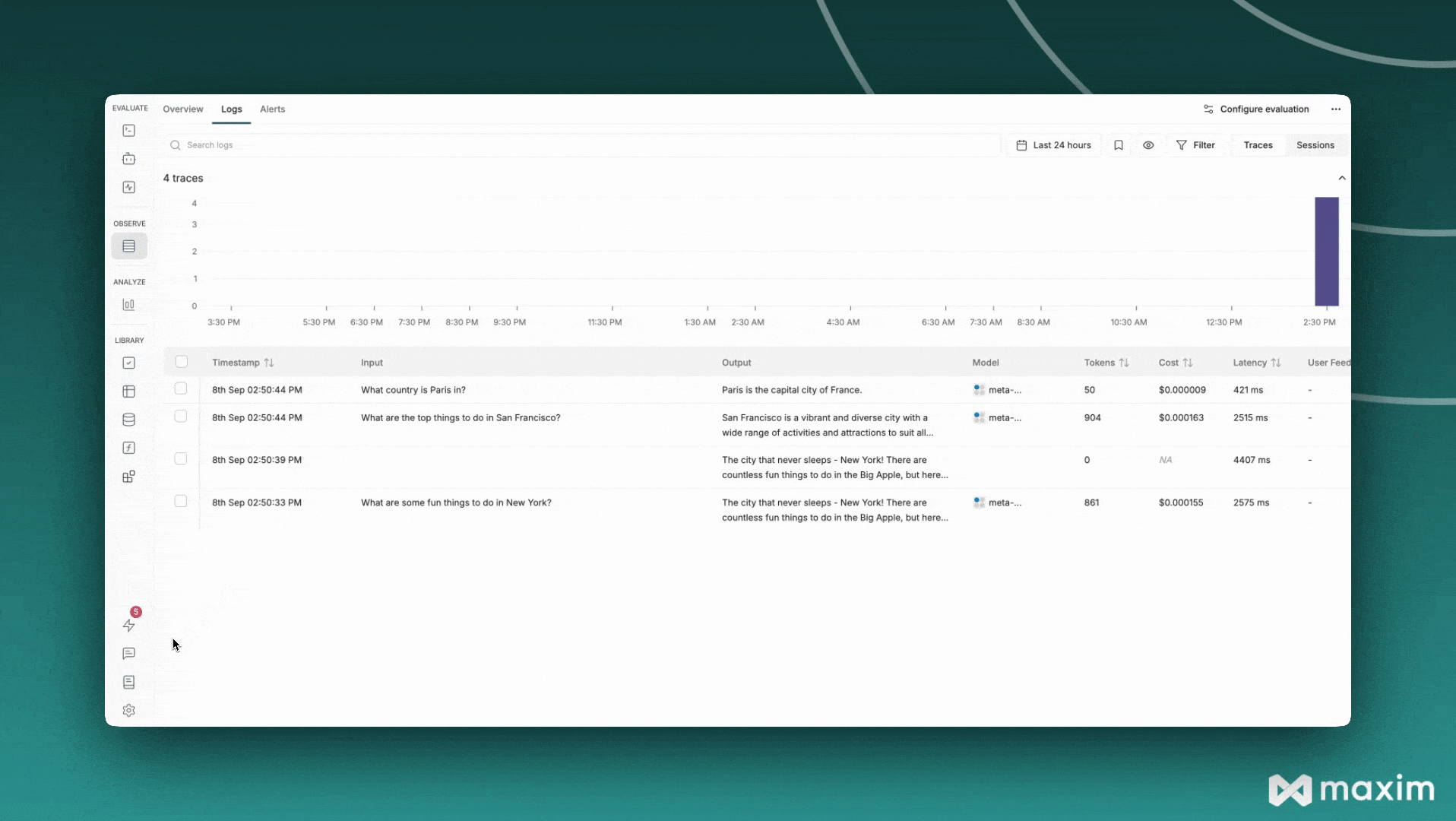
Best Practices
1. Environment Variables
Always use environment variables for API keys:2. Error Handling
Implement proper error handling for production use:3. Model Selection
Choose appropriate models for your use case:- Fast responses: Use smaller models like
Meta-Llama-3.1-8B-Instruct-Turbo - High quality: Use larger models like
Meta-Llama-3.1-70B-Instruct-Turbo - Specialized tasks: Use domain-specific models
4. Streaming for UX
Use streaming for better user experience:5. Async for Performance
Use async operations for multiple concurrent requests:For more details, see the Maxim Python SDK documentation.
Resources
Cookbook Code
Python Notebook for Together AI & Maxim AI