Scenario-Based Testing: Maxim’s Test Suite for Reliable, Production-Ready AI Agents

TL;DR
Scenario-based testing makes AI agents reliable by validating behavior across realistic, multi-turn conversations, diverse personas, tools, and context sources. Traditional testing falls short because agents are non-deterministic, and multi-turn conversational. Maxim AI provides an end-to-end platform: Prompt IDE, agent simulations, unified evaluators, and enterprise observability to scale evaluations, track regressions, and ship agents with confidence. Maxim helps teams run end‑to‑end experimentation, simulation, evaluation, and observability for quick iterations, catching issues early, and shipping reliable AI agents with confidence.
Introduction: Why Traditional Testing Is Not Enough for AI Agents
Traditional unit and integration tests assume deterministic behavior, fixed inputs/outputs, and limited side effects. AI agents violate these assumptions. Outputs vary with model parameters, retrieved context, tool calls, and conversation state. Multi-turn workflows add branching and escalation paths, while policies and guardrails require nuanced checks beyond string matching. McKinsey reports 92% of companies plan to increase AI spend, but only 1% consider themselves mature in deployment. That gap demands rigorous, pre-release scenario simulations and continuous online evaluations to surface failure modes early and reach production reliability.
Challenges of Testing AI Agents
- Coverage blindness: Single-turn tests miss multi-turn context handling, tool call sequences, and policy adherence.
- Regression invisibility: Subtle prompt or model changes degrade faithfulness or task success without obvious failures.
- Scalability issues: Manual review does not scale across thousands of scenarios and personas.
- Non-deterministic behavior: Traditional tests expect repeatable outputs, but agents drift with prompt tweaks, model updates, or evolving context sources.
What Is Scenario-Based Testing?
Test your Agent Workflows with Agent Simulation:Scenario-based testing with Maxim AI
Scenario-based testing validates agent performance in realistic, constraint‑driven conversations before deployment. In pre‑production, each scenario encodes:
- A user goal and business policy context.
- A persona (e.g., frustrated customer or novice user).
- Tool availability and context sources (RAG).
- Success criteria: task completion, policy compliance, faithfulness, citation quality, and tone.
Maxim packages these scenarios as datasets and runs automated Simulated Sessions at scale to reproduce multi‑turn interactions, uncover failure modes early, and prevent regressions from reaching production.
Key Characteristics of Scenario-Based Testing
- Automated scenario testing: Trigger multi-turn simulations with predefined steps and tools; configure turn limits and persona behaviors. See Simulation Runs.
- Cross-functional collaboration: this helps product and engineering teams design agents, do experimentation with Prompt, simulate with different scenarios and user personas, and review results centrally. See No-Code Agent Quickstart and Types of Nodes.
- Continuous anomaly detection: Online evaluations on production logs with threshold-based alerts for quality and performance. See Online Evaluation Overview and Set Up Alerts and Notifications.
- Parallel testing: Scale runs across thousands of scenarios and personas; compare versions and models side-by-side.
- Confident iteration: surface failure modes across scenarios and personas, then version prompts and compare diffs to validate fixes. Deploy conditionally with variables for safe rollouts while you keep iterating fast.
- Quality metrics: Attach evaluators for faithfulness, toxicity, clarity, task success, context precision/recall/relevance, cost, and latency.
- Cost optimization: Track token usage, latency, and daily cost; alert on anomalies to prevent runaway budgets.
How Maxim Provides Scenario-Based Testing with AI Agent Simulation
Maxim’s simulation engine evaluates end-to-end agent behavior across realistic conversations and personas:
Design Scenarios and Personas
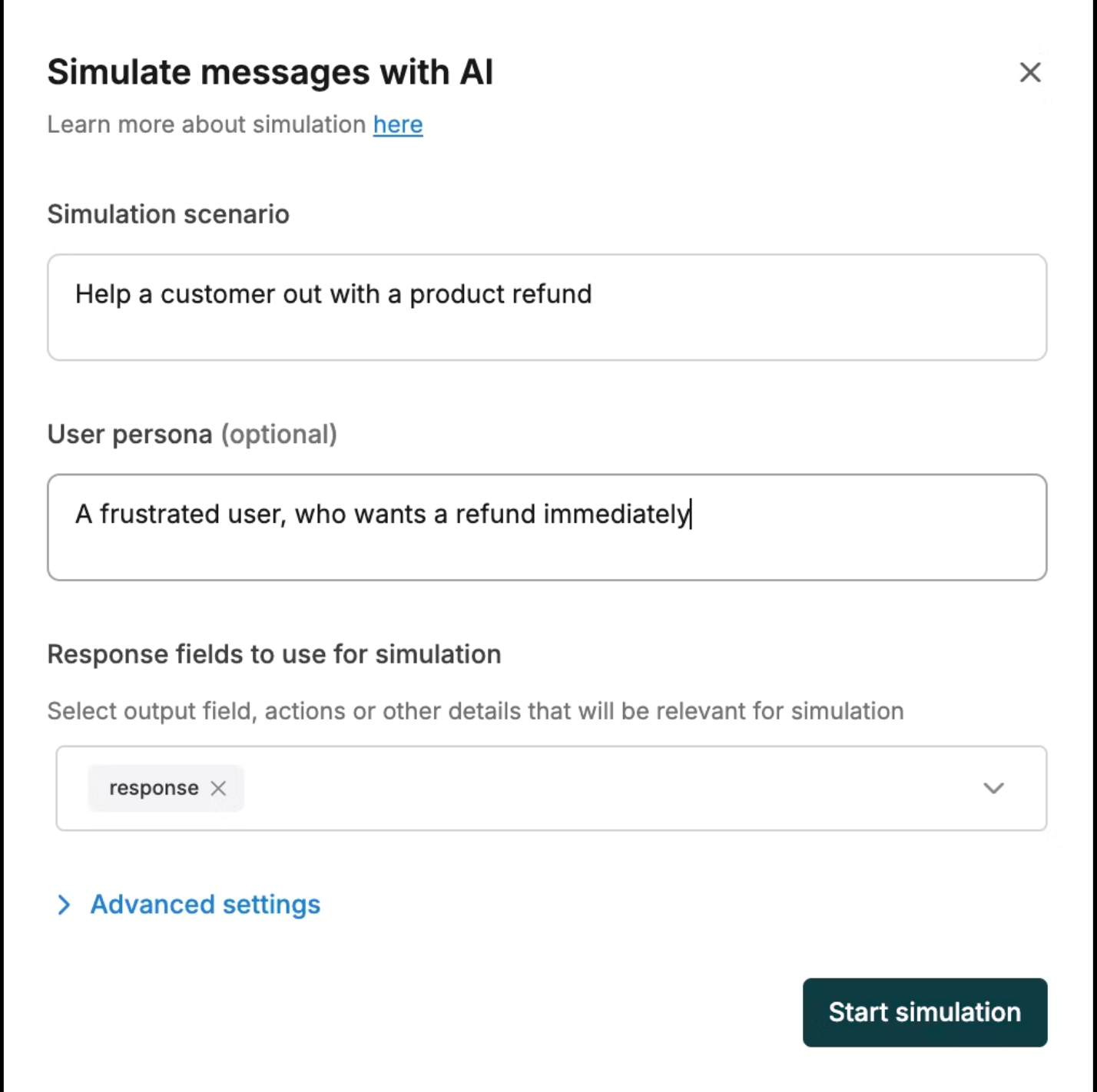
Define refund workflows, onboarding flows, billing disputes, or policy checks. Configure persona tone and expertise. Constrain maximum turns and attach tools or context sources. See Simulation Overview.
Create Datasets With Expected Steps
Build datasets describing agent scenarios, expected actions, and required checks for example, verify purchase, apply policy, resolve in five turns. See Simulation Runs.
Link Tools and Context Sources
- Tools: Attach tool definitions and test correct tool usage from prompts. See Prompt Tool Calls and Types of Nodes.
- Context Sources: Integrate RAG endpoints; evaluate retrieval quality with precision, recall, and relevance. See Prompt Retrieval Testing and Context Sources.
Run Simulated Sessions
Navigate to the agent endpoint, select “Simulated session,” pick the dataset, configure persona, tools, and context sources, and trigger the test run. Each session executes end-to-end and records results. See Simulation Runs.
Evaluate With Unified Metrics
Attach pre-built and custom evaluators:
- AI and programmatic evaluators for correctness and policy compliance. See Evaluators.
- Retrieval evaluators for precision/recall/relevance. See Prompt Retrieval Testing.
- Human evaluators for high-stakes domains and last-mile accuracy. See Agent Simulation and Evaluation.
Iterate with Prompt IDE and Versions
Experiment with prompts across models, parameters, and tools, then publish versions and compare diffs. Use sessions to save state and tag work. See Prompt Playground, Prompt Versions, and Prompt Sessions.
Deploy with Control and Variables
Deploy agent versions without code changes, using variables to route rollouts by environment, tenant, or customer segments. Fetch via SDK with query filters. See Agent Deployment.
Monitor in Production with Tracing and Alerts
Instrument agents for distributed tracing to correlate prompts, tools, retrievals, and responses. Run online evaluations on sampled traffic and alert on regressions. See Tracing Overview and Set Up Alerts and Notifications.
Why Maxim Stands Out for AI Simulation and Scenario-Based Testing
- End-to-end lifecycle: Unified Experimentation, Simulation, Evaluation, and Observability—one platform to move from prototyping to production. See Experimentation, Agent Simulation and Evaluation, and Agent Observability.
- Multi-modal agent support: Text and voice simulations, real-time audio streaming, transcription, and voice evaluators. See Voice Simulation.
- Flexible evaluators: AI, statistical, programmatic, API-based, and human evaluators, attachable at session, trace, or span level. See Library Overview and Evaluators.
- Production-grade observability: Distributed tracing, online evaluations, saved views, and data curation pipelines for continuous quality improvement. See Tracing Overview.
- Cost and latency controls: Alerts for latency, token usage, and daily costs with Slack/PagerDuty notifications. See Set Up Alerts and Notifications.
- Collaboration and governance: No-code builder, prompt versioning, RBAC, SSO, in-VPC deployment, SOC 2 Type 2. See the Enterprise-ready section in Agent Observability.
Conclusion
Scenario‑based testing is essential to making AI agents reliable in real‑world conditions especially in pre‑production. By combining simulated sessions, precise evaluators, prompt/version management, and production‑ready observability, Maxim gives teams the controls they need to prevent regressions, reduce costs, and meet policy and quality standards. Crucially, session‑based testing surfaces hidden issues in agent workflows (routing errors, skipped steps, weak grounding, safety risks) before the agent hits production, enabling fast fixes and cleaner releases. Adopt this approach early and maintain a continuous loop from production logs to test suites and improvements.
Ready to test your agents at scale and ship with confidence? Visit Book a demo or sign up at Sign Up.
FAQs
What is scenario-based testing for AI agents?
Scenario-based testing validates agent behavior across realistic, multi-turn conversations with personas, tools, and context sources, using evaluators for task success, faithfulness, retrieval quality, and safety. See Simulation Runs.
How do I measure retrieval quality in RAG workflows?
Use context precision, recall, and relevance evaluators; attach a Context Source to your prompt and run tests at scale with datasets. See Prompt Retrieval Testing and Context Sources.
How can I detect regressions after prompt or model changes?
Publish versions, compare diffs, run comparison tests across datasets and evaluators, and monitor online evaluations with alerts in production. See Prompt Versions, Prompt Playground, and Online Evaluation Overview.
Can I simulate voice conversations and evaluate them?
Yes. Maxim supports voice simulations with real-time streaming, transcripts, provider integrations, and voice-specific evaluators. See Voice Simulation.
How do I monitor cost, token usage, and latency in production?
Configure Performance Metrics Alerts for latency, token usage, and cost with Slack or PagerDuty notifications. See Set Up Alerts and Notifications.
How does observability help with agent debugging?
Distributed tracing correlates prompts, tool calls, retrievals, and responses; saved views and online evaluators surface anomalies quickly. See Tracing Overview.
Further Reading and Resources


