What is an LLM Gateway? Architecture, Features, Use Cases
An LLM gateway is a unified API layer that routes, governs, and observes requests across LLM providers. Architecture, features, and use cases explained.
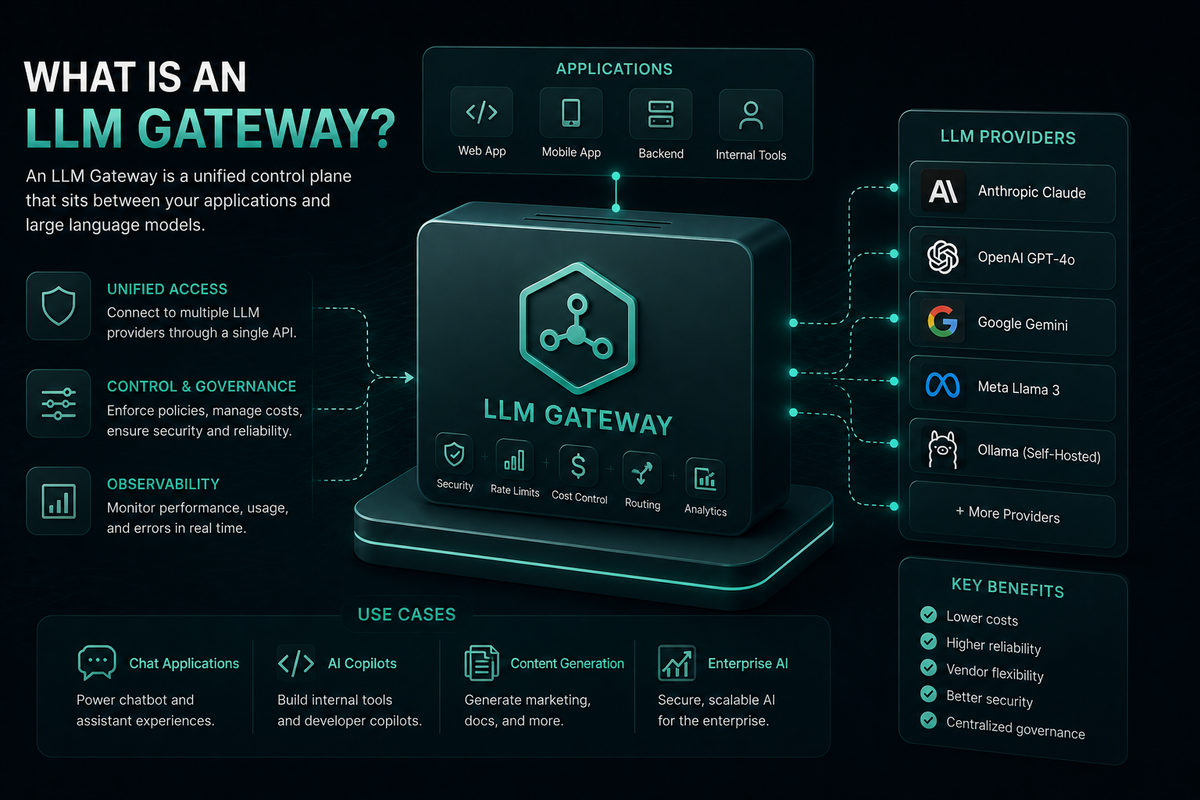
An LLM gateway is the central control layer between an application and the large language model providers it depends on. As AI workloads have moved from prototypes into production, teams have run into a predictable set of problems: every provider exposes a different API, outages and rate limits cascade into user-visible downtime, costs are opaque, and there is no single place to enforce security or compliance policy. An LLM gateway solves these by giving applications one consistent interface to many models while centralizing routing, observability, governance, and reliability features at the infrastructure layer. This guide explains what an LLM gateway is, the architecture and features that define a modern gateway, the production use cases it supports, and how Bifrost, the open-source AI gateway, delivers these capabilities for teams running mission-critical AI workloads.
What is an LLM Gateway?
An LLM gateway is a proxy that sits between client applications and one or more large language model providers, exposing a single API for sending prompts and receiving completions. It routes requests across models and providers, enforces governance and access policies, caches responses, and centralizes observability for every AI call running through it. The result is that application code no longer carries provider-specific logic for retries, fallbacks, key management, or cost tracking.
Why AI Teams Need an LLM Gateway
Direct, per-provider integrations work for prototypes but fail at production scale. Stanford's 2026 AI Index Report puts organizational AI adoption at 88%, and most of those teams now run multi-provider stacks with mixed models for different tasks. Five problems consistently push teams to adopt a gateway:
- API fragmentation. OpenAI, Anthropic, Google, AWS Bedrock, and Azure each expose different request formats, error semantics, and authentication models.
- Reliability. Provider outages and rate limits translate directly into application downtime unless retries and fallbacks are handled outside application code.
- Cost visibility. Without a central layer, spend is opaque until the invoice arrives, and there is no clean way to attribute cost to a team, feature, or environment.
- Security and governance. API keys scattered across services create rotation risk, no audit trail, and no enforceable access control.
- Migration risk. Hard-coupling application code to a single provider makes switching expensive even when a better or cheaper model exists.
A gateway addresses each of these as an infrastructure concern rather than an application concern.
LLM Gateway Architecture: Core Components
A production-grade LLM gateway runs as a stateless service in front of multiple provider backends. Its architecture typically includes five layers:
- Ingress and protocol layer. Accepts requests through an OpenAI-compatible HTTP API so existing SDKs work unchanged.
- Authentication and authorization. Validates per-consumer credentials, often through virtual keys that map to budgets, model whitelists, and rate limits.
- Routing and policy engine. Selects the right provider and model for each request based on weights, health, model availability, or custom rules.
- Provider adapters. Translate the gateway's unified request format into each provider's native API and normalize responses back into a consistent shape.
- Observability and persistence. Captures structured logs, traces, and metrics for every request, exports to monitoring systems, and persists configuration across restarts.
Bifrost implements these layers in Go as a single statically linked binary that runs on a laptop, in a container, or on Kubernetes. The Bifrost product page summarizes the full architecture and integration model.
Key Features of a Modern LLM Gateway
The minimum feature set teams expect from a modern LLM gateway in 2026 includes:
- Unified API across providers. A single OpenAI-compatible endpoint that routes to OpenAI, Anthropic, Google, Bedrock, Azure, Mistral, Groq, and other supported providers.
- Drop-in SDK replacement. Existing OpenAI, Anthropic, and Google SDKs continue to work by changing only the base URL.
- Automatic failover and load balancing. Request-level fallback chains and weighted distribution across API keys and providers.
- Semantic caching. Cached responses for semantically similar prompts, not just exact-match cache hits.
- Governance. Virtual keys, hierarchical budgets, rate limits, and role-based access control.
- MCP gateway support. Centralized management of Model Context Protocol tool connections for agentic workflows.
- Native observability. Prometheus metrics, OpenTelemetry traces, and structured logs out of the box.
A capability matrix for evaluating gateways against these features is documented in the LLM Gateway Buyer's Guide.
LLM Gateway vs LLM Proxy
The terms are sometimes used interchangeably, but the distinction matters at production scale. An LLM proxy forwards requests with minimal transformation, typically for one provider. An LLM gateway is a control plane: it terminates client requests, applies policy, makes routing decisions, normalizes across providers, and emits telemetry. A proxy handles traffic; a gateway integrates models, governance, observability, and security into a single platform that other systems depend on.
In practice, any team running more than one model or provider, enforcing per-team budgets, or operating regulated workloads needs the gateway layer rather than a proxy.
Production Use Cases for LLM Gateways
LLM gateways show up in five common production patterns:
- Multi-provider reliability. Route a chatbot request to OpenAI as the primary with Anthropic and Bedrock as fallbacks, so a single provider outage does not interrupt service.
- Cost-aware routing. Send classification and extraction tasks to cheaper models like GPT-4o-mini or Claude Haiku, and reserve frontier models for tasks that need them.
- Tenant isolation. Issue separate virtual keys per customer or per team, with independent budgets and rate limits, to prevent one workload from starving another.
- Agentic workflows. Use the gateway as an MCP host that exposes a curated set of tools to every agent, with central auth, audit logs, and tool-level access control.
- Compliance-bound deployments. Run the gateway inside a VPC with audit logging, vault-managed credentials, and identity provider integration to support SOC 2, HIPAA, or GDPR requirements.
The Model Context Protocol specification has accelerated the agentic pattern in particular by giving every gateway a standardized way to expose tools to models.
How Bifrost Delivers LLM Gateway Capabilities
Bifrost is an open-source LLM gateway purpose-built for high-throughput production workloads. Its unified, OpenAI-compatible API supports more than 20 providers and 1,000+ models behind a drop-in replacement integration that changes only the base URL in existing code. Bifrost's automatic failover reissues failed requests against a configurable chain of backup providers, while weighted load balancing distributes traffic across multiple API keys per provider.
Beyond routing, Bifrost includes semantic caching that reduces costs and latency on similar prompts, virtual keys for per-consumer governance with budgets and rate limits, and a native MCP gateway that lets a single Bifrost instance host external tools, hosted tools, and OAuth-authenticated APIs for downstream agents. Bifrost's published performance benchmarks measure 11 microseconds of gateway overhead per request at 5,000 RPS, so reliability comes without a latency tax.
Getting Started with Bifrost
An LLM gateway is no longer optional infrastructure for teams running AI in production. The reliability, governance, and observability features it consolidates are too important to scatter across application code. Bifrost gives platform and AI engineering teams a single open-source LLM gateway that unifies access to 1000+ models, supports MCP for agentic workflows, and enforces governance at the routing layer, all behind an OpenAI-compatible API. To see how Bifrost can replace fragmented per-provider integrations across your AI stack, book a demo with the Bifrost team.


