What is an AI Gateway? Architecture, Features, and Why It Matters

An AI gateway is the infrastructure layer that sits between AI-powered applications and the large language model (LLM) providers, model APIs, and tool servers they depend on. As enterprises move generative AI workloads from prototype to production, the AI gateway has emerged as the central control plane for managing reliability, cost, governance, and security across multiple model providers. Gartner projects that by 2028, 30% of the increased demand for APIs will come from AI and LLM-based tools, driving the rise of dedicated AI gateway infrastructure. Bifrost, the open-source AI gateway by Maxim AI, is purpose-built for this layer, unifying access to 23+ providers through a single OpenAI-compatible API with 11 microseconds of overhead at 5,000 requests per second.
This article explains what an AI gateway is, what it does, how it differs from a traditional API gateway, the core architectural components, and the considerations that matter when adopting one.
What is an AI Gateway in Production AI Systems
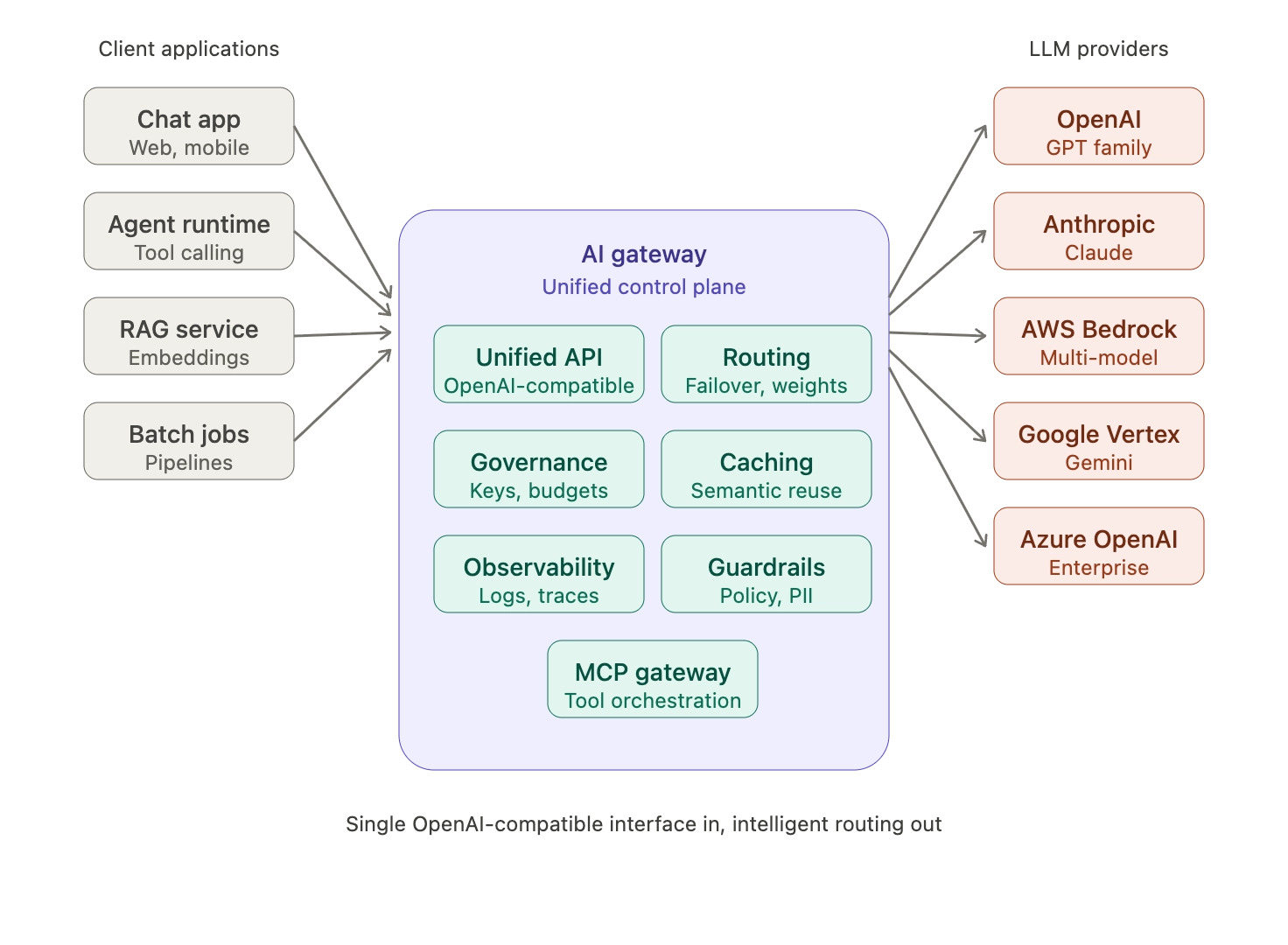
An AI gateway is a middleware service that intermediates all traffic between applications and AI model providers (OpenAI, Anthropic, AWS Bedrock, Google Vertex, Azure OpenAI, and others). It provides a single, consistent interface for applications while handling provider-specific concerns like authentication, rate limits, failover, caching, and observability transparently.
In a typical production architecture, every LLM request, embedding call, image generation, and tool invocation passes through the gateway. The gateway normalizes these requests, applies governance policies, routes to the appropriate provider, and returns a unified response. This pattern decouples application code from provider SDKs and turns the AI stack into something that can be operated, audited, and scaled like any other piece of enterprise infrastructure.
Three forces have made the AI gateway pattern essential:
- Provider fragmentation: Every major LLM vendor exposes a different API contract, authentication scheme, error model, and rate limit structure. Hard-coding to one vendor creates lock-in; supporting many creates integration sprawl.
- Multi-model workloads: Enterprises increasingly route different tasks (reasoning, summarization, coding, embeddings) to different models. Choosing the right model per request is a routing concern, not an application concern.
- Governance gaps: Direct provider API access offers no built-in mechanism for spend tracking, access control, audit trails, or content policy enforcement. These controls must live at the gateway layer.
How an AI Gateway Differs from a Traditional API Gateway
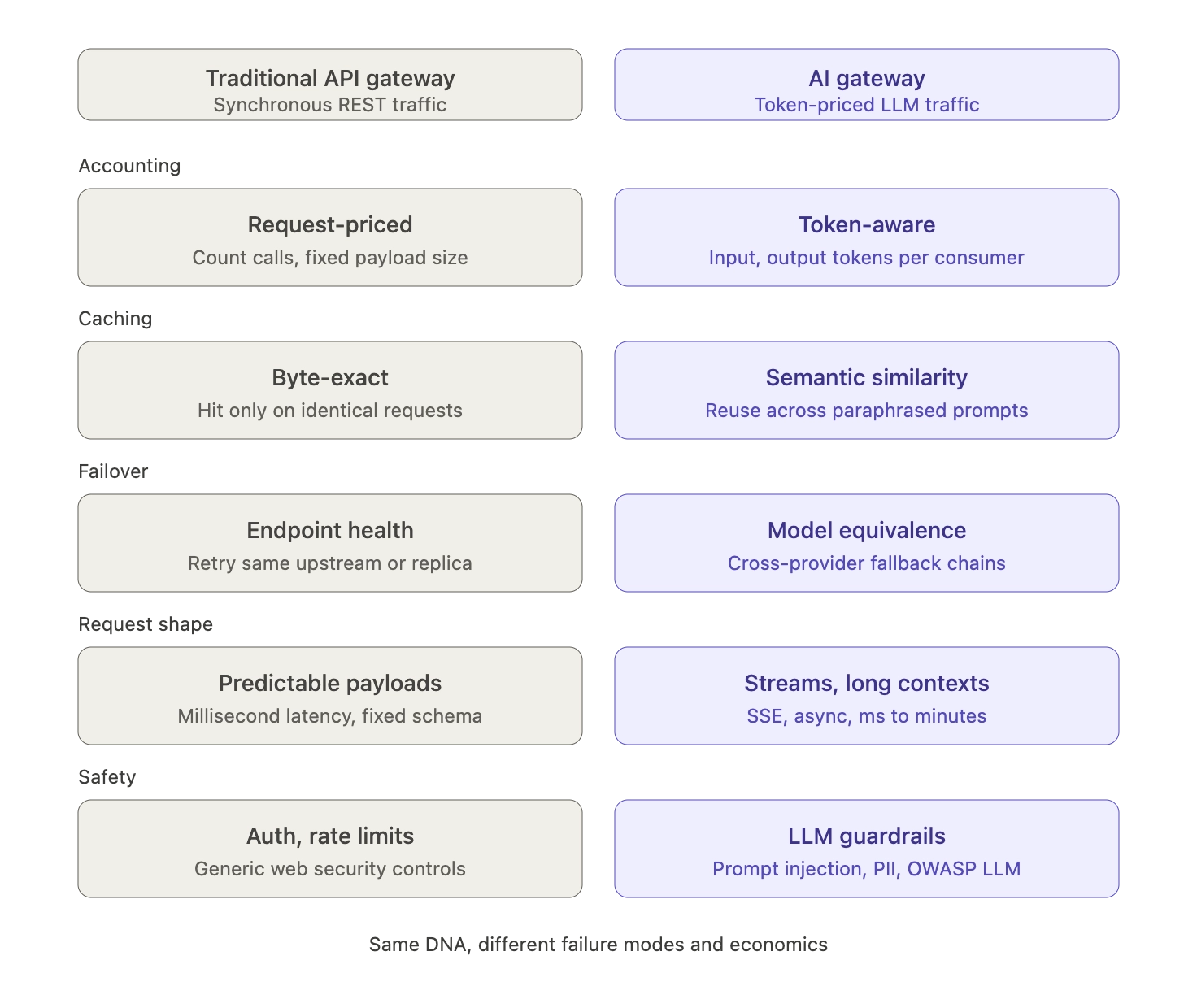
Traditional API gateways such as Kong, NGINX, or Apigee were designed for synchronous, low-latency HTTP traffic with predictable payloads. They handle authentication, routing, rate limiting, and basic observability for RESTful APIs.
An AI gateway shares some of that DNA but solves a different class of problems. LLM traffic is token-priced rather than request-priced, latencies range from milliseconds to minutes, payloads include streaming responses and large context windows, and the failure modes are unique to generative AI (hallucinations, prompt injection, sensitive data leakage, runaway token consumption).
Key differences include:
- Token-aware accounting: AI gateways track input and output tokens per request, per model, per consumer, enabling cost attribution that a traditional gateway cannot provide.
- Semantic caching: Instead of byte-exact response caching, AI gateways cache based on semantic similarity, recognizing that "What is AI?" and "Explain artificial intelligence" can reuse the same response.
- Multi-provider failover: Failover decisions consider model equivalence, not just endpoint health. When OpenAI is degraded, the gateway can fail over to Anthropic Claude or AWS Bedrock for the same logical task.
- Streaming and long-running requests: AI gateways handle SSE streams, partial responses, and asynchronous inference workflows natively.
- Content safety and policy enforcement: AI gateways apply guardrails, PII redaction, and prompt-injection defenses that are specific to LLM threat models. The OWASP Top 10 for LLM Applications identifies prompt injection, sensitive information disclosure, and unbounded consumption as top risks, all of which are naturally addressed at the gateway layer.
Why AI Gateways Matter for Enterprise AI Teams
The business case for an AI gateway becomes clear once an organization has more than one AI feature, more than one provider, or more than one team consuming LLMs.
Cost control and visibility
LLM costs are unpredictable because token usage varies per query. A single complex prompt can consume 10x more tokens than expected, and without centralized monitoring, spend can spiral. Gartner forecasts that LLM inference costs will drop by more than 90% by 2030 compared to 2025, but until that happens, every team needs hierarchical budgets, rate limits, and real-time spend dashboards. Bifrost's virtual keys and budget management deliver these controls at the gateway layer, with hierarchical cost caps at the virtual key, team, and customer levels.
Reliability and uptime
Provider outages are not hypothetical. OpenAI, Anthropic, and other vendors have all had multi-hour incidents that knock dependent applications offline. An AI gateway with automatic failover across providers keeps applications running by routing to a backup model whenever the primary degrades, with no application-level changes required.
Governance and compliance
Auditability is non-negotiable in regulated industries. Every LLM request that touches customer data must be logged, attributable, and reviewable. Bifrost's governance layer provides immutable audit logs for SOC 2, GDPR, HIPAA, and ISO 27001 compliance, plus RBAC, SSO via Okta and Entra (Azure AD), and integration with HashiCorp Vault, AWS Secrets Manager, and Azure Key Vault for secrets handling.
Multi-provider flexibility
Hard-coding to a single provider creates lock-in. An AI gateway turns provider choice into a configuration decision instead of a code rewrite. Teams can route reasoning-heavy tasks to one model, high-volume low-complexity tasks to another, and switch models in production without redeploying code.
Core Components of an AI Gateway Architecture
A production-grade AI gateway typically provides the following capabilities:
- Unified API: A single OpenAI-compatible interface that abstracts every supported provider. Bifrost offers a drop-in SDK replacement where switching from a direct OpenAI integration to a gateway-mediated one requires changing only the base URL.
- Provider routing: Rules-based and weighted routing that directs requests to specific models, providers, or API keys based on cost, latency, or capability requirements.
- Failover and load balancing: Automatic detection of provider degradation, with intelligent fallback chains across providers and keys.
- Semantic caching: Cache layer that uses embedding similarity to return previously computed responses for semantically equivalent prompts, reducing both latency and cost.
- Governance primitives: Virtual keys, budgets, rate limits, and access controls scoped to consumers, teams, and projects.
- Observability: Real-time request logging, OpenTelemetry-compatible distributed tracing, and Prometheus metrics for production monitoring. Gartner predicts that by 2028, LLM observability investments will reach 50% of GenAI deployments, up from 15% today.
- Guardrails: Content safety, PII redaction, and policy enforcement applied to every request and response before they reach the application or the provider.
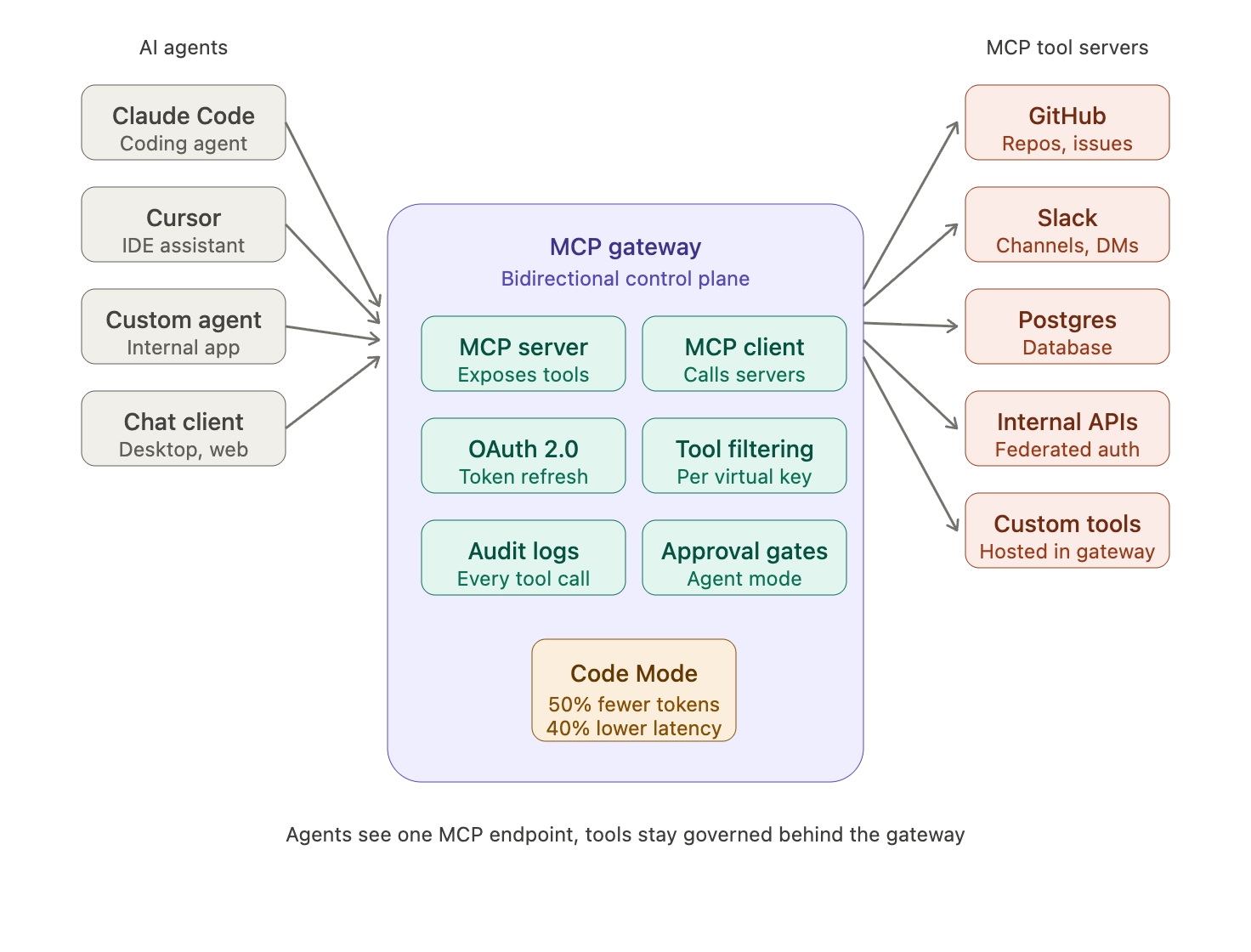
The MCP Gateway: AI Gateways Extended for Agents
The rise of AI agents has expanded the gateway's role beyond LLM routing into tool orchestration. Anthropic introduced the Model Context Protocol (MCP) in November 2024 as an open standard for connecting AI agents to external data sources and tools. MCP has since been adopted as the de facto industry standard for agent-tool integration, with thousands of MCP servers in the ecosystem.
An MCP gateway centralizes all MCP server connections, applies governance and access controls to tool calls, and prevents the security blind spots that emerge when individual applications embed MCP clients directly. Bifrost's MCP gateway acts as both an MCP client and MCP server, with OAuth 2.0 authentication, per-virtual-key tool filtering, and Code Mode (where the AI writes Python to orchestrate multiple tools, reducing token usage by 50% and latency by 40%). This addresses the same problem Anthropic's own engineering team has documented: as agents connect to more tools, loading all tool definitions upfront consumes excessive context and increases costs.
For deep dives on MCP gateway architecture, access control, and cost governance, see the Bifrost MCP Gateway technical guide.
Key Considerations When Choosing an AI Gateway
Evaluating an AI gateway should be a structured exercise, not a vendor pitch comparison. The most important dimensions are:
- Performance overhead: Gateways sit in the hot path of every request. Latency added by the gateway compounds at scale. Bifrost adds only 11µs of overhead at 5,000 RPS, validated in independent performance benchmarks.
- Deployment model: Self-hosted, cloud-managed, or hybrid. Regulated industries often require in-VPC or air-gapped deployments with no external dependencies.
- Provider breadth: How many LLM providers are natively supported, and how quickly are new providers added when they launch.
- Governance depth: Virtual keys, RBAC, SSO, audit logs, secrets management integration, and budget hierarchies.
- MCP and agent readiness: Whether the gateway supports MCP as both client and server, with tool filtering and OAuth authentication.
- Observability integrations: Native support for Prometheus, OpenTelemetry, Datadog, New Relic, and other monitoring stacks.
- Open source vs. proprietary: Open-source gateways such as Bifrost (Apache 2.0) allow transparent inspection, community contribution, and freedom from vendor lock-in.
For a complete capability matrix across deployment, governance, and performance dimensions, the LLM Gateway Buyer's Guide provides a structured framework for evaluation.
Getting Started with an AI Gateway
The fastest way to evaluate an AI gateway is to deploy one and route real traffic through it. Bifrost is open source and requires no configuration to start. Install with a single command:
npx -y @maximhq/bifrost
Or run via Docker:
docker run -p 8080:8080 -v $(pwd)/data:/app/data maximhq/bifrost
The built-in web UI handles provider configuration, virtual key creation, and routing rules visually. Existing applications can migrate by changing only the base URL in the OpenAI, Anthropic, or LiteLLM SDK to point at the Bifrost endpoint.
For production deployments, the Bifrost Kubernetes deployment guide covers clustering, high availability, and scaling patterns. Enterprise teams running mission-critical AI workloads can explore Bifrost's clustering, adaptive load balancing, and in-VPC deployment options through a direct conversation: book a demo with the Bifrost team to see how a production-grade AI gateway can simplify your AI infrastructure.


