Failover Routing Strategies for LLMs in Enterprise AI Applications

Failover routing strategies for LLMs keep enterprise AI online during provider outages. Compare patterns, trade-offs, and how Bifrost implements them.
Failover routing strategies for LLMs have become a baseline requirement for any enterprise AI application running in production. LLM provider outages are no longer rare events: IsDown's December 2025 status report tracked 47 incidents across major AI systems in a single month, with Anthropic logging 20 incidents (184.5 hours of total impact) and OpenAI logging 22 incidents (182.7 hours of total impact). When a primary provider fails, enterprise AI applications without a routing fallback go down with it. Bifrost, the open-source AI gateway by Maxim AI, implements failover routing at the infrastructure layer so application code never has to handle provider failures directly.
This blog examines the major failover routing patterns used in production, the architectural trade-offs of each, and how Bifrost's automatic fallback chains deliver them as a configuration concern rather than an application concern.
Why LLM Failover Routing Is a Production Requirement
LLM availability has trended downward as adoption has accelerated. Academic research from the AtLarge Research Group at TU Delft characterized LLM outage patterns across major providers and found significant differences in mean time to repair: the median MTTR for the OpenAI API was 1.23 hours, roughly 1.6 times longer than the Anthropic API's 0.77 hours. Both numbers exceed traditional enterprise tolerance for downtime in customer-facing systems.
The reliability problem compounds because LLM applications usually depend on more than just the model API. They depend on the underlying cloud region, the DNS resolution path, the authentication layer, and any data store the application uses for memory or retrieval. The October 2025 AWS US-EAST-1 outage, analyzed in detail by Cisco ThousandEyes, demonstrated how a DNS race condition in DynamoDB cascaded across 70+ AWS services for over 15 hours, affecting services worldwide that depended on the region for coordination, authentication, or replication.
For enterprise AI teams, the implication is clear: failover routing strategies for LLMs cannot rely on a single provider, a single region, or a single network path. They have to assume failure at every layer and route around it.
What Failures Failover Routing Must Handle
A production failover routing layer must respond to several distinct failure modes:
- Provider outages: full API unavailability lasting minutes to hours.
- Rate limit errors (HTTP 429): the provider is up, but the requesting key has exhausted its quota.
- Server errors (HTTP 5xx): the provider is degraded, returning transient failures.
- Model unavailability: specific models offline for maintenance or deprecated.
- Latency degradation: the provider responds, but slowly enough that the response is unusable.
- Authentication failures: invalid or rotated keys.
- Content safety failures: a model returns a response blocked by a guardrail policy.
Each failure mode benefits from a slightly different routing response, which is why failover routing is rarely a single rule and more often a layered policy.
Core Failover Routing Patterns
Sequential Fallback Chains
The simplest failover routing pattern is a sequential chain: try the primary provider first, and on failure, try the next provider in the configured list. This is the pattern OpenRouter exposes in its API and the pattern most teams adopt first. Research on the LLM API market from Andrey Fradkin's analysis of the LLM inference market shows that aggregator routing layers have become standard precisely because they "allow developers to specify fallback models under defined conditions" without rewriting application code.
Sequential chains work well for total outages but introduce two problems at scale. First, every failed attempt adds latency to the user-facing request. Second, if the primary is degraded rather than fully down, the request may sit waiting for a timeout before the fallback is tried.
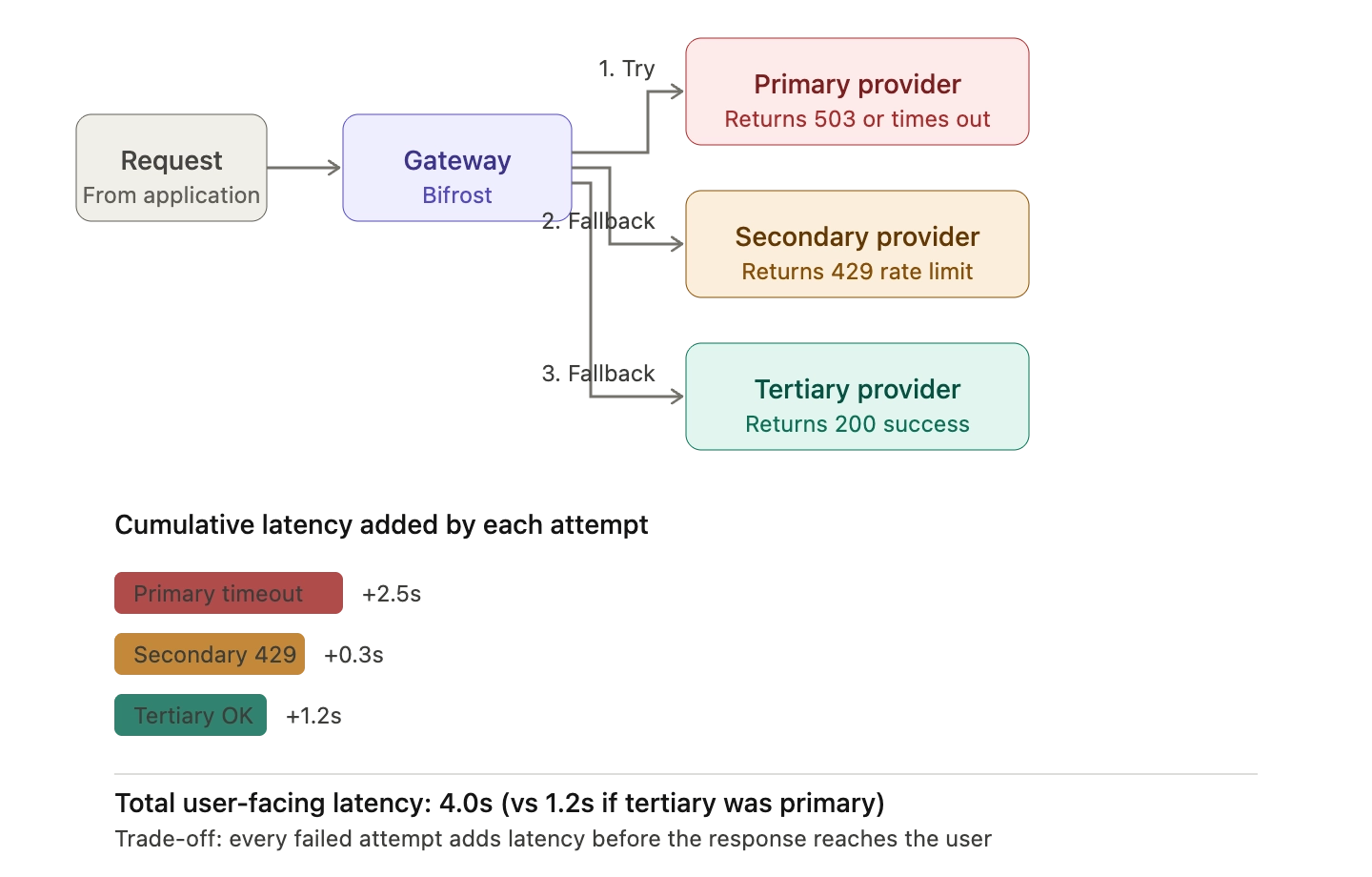
Bifrost's automatic fallback implementation addresses both. When a request includes a fallbacks array, Bifrost tries the primary provider, detects the failure immediately based on retryable error codes, and forwards to the next provider in the chain. Each fallback attempt is treated as a completely new request, so all configured plugins (semantic caching, governance rules, logging) execute fresh for the fallback provider.
{
"model": "openai/gpt-4o-mini",
"messages": [{"role": "user", "content": "..."}],
"fallbacks": [
"anthropic/claude-3-5-sonnet-20241022",
"bedrock/anthropic.claude-3-sonnet-20240229-v1:0"
]
}
Parallel Hedged Requests
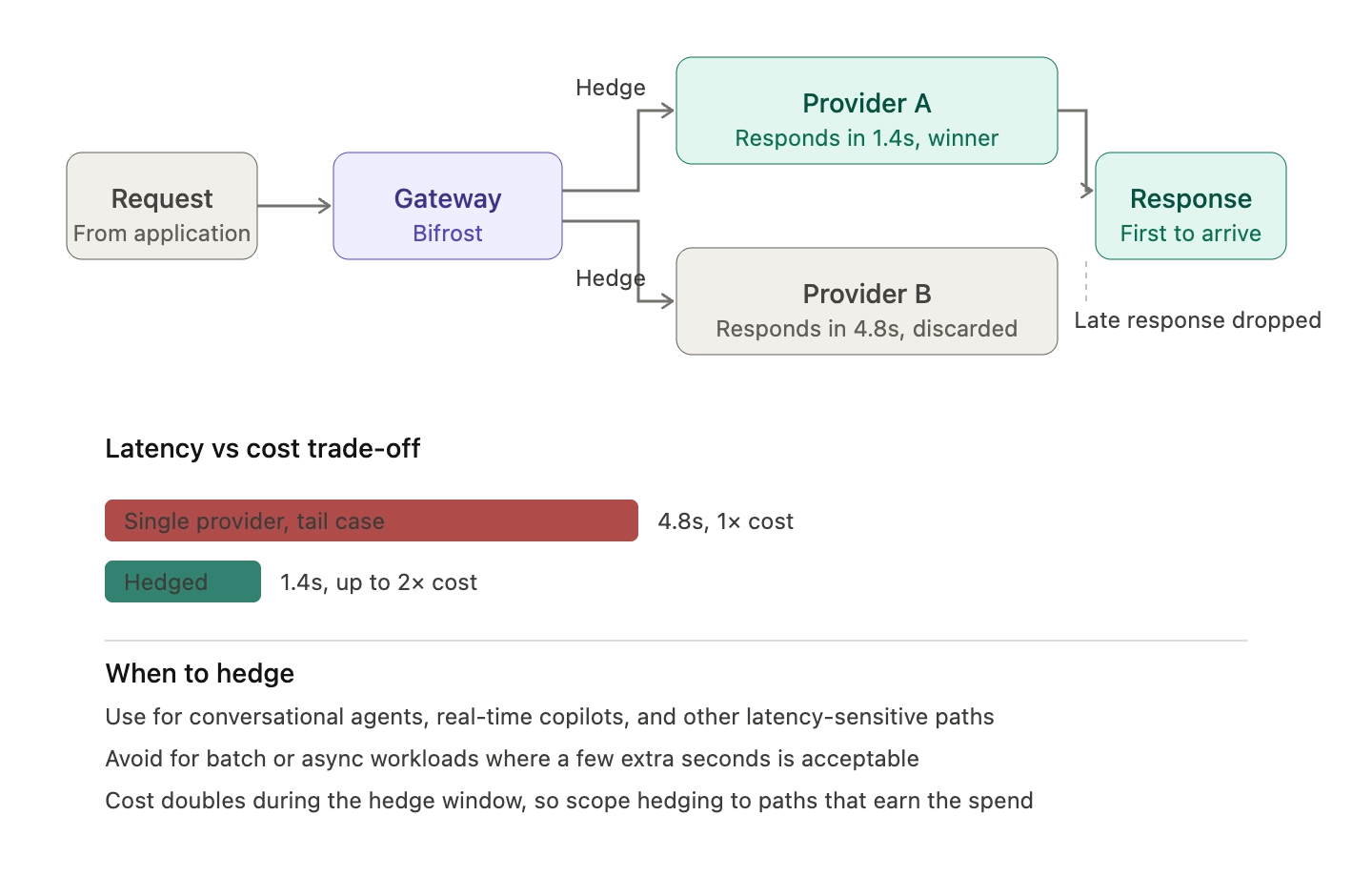
When latency itself is a failure mode, parallel hedging trades cost for response time. The gateway sends the same request to two providers simultaneously and returns whichever response arrives first. This is the pattern Google SRE has documented for tail latency reduction, and it applies cleanly to LLM workloads where a 6-second response is functionally indistinguishable from a failure.
The trade-off is straightforward: hedging doubles the per-request cost during the hedge window. Most production teams hedge only for latency-sensitive paths (conversational agents, real-time copilots) and use sequential fallbacks for batch or async workloads where a few extra seconds is acceptable.
Weighted Load Balancing with Failover
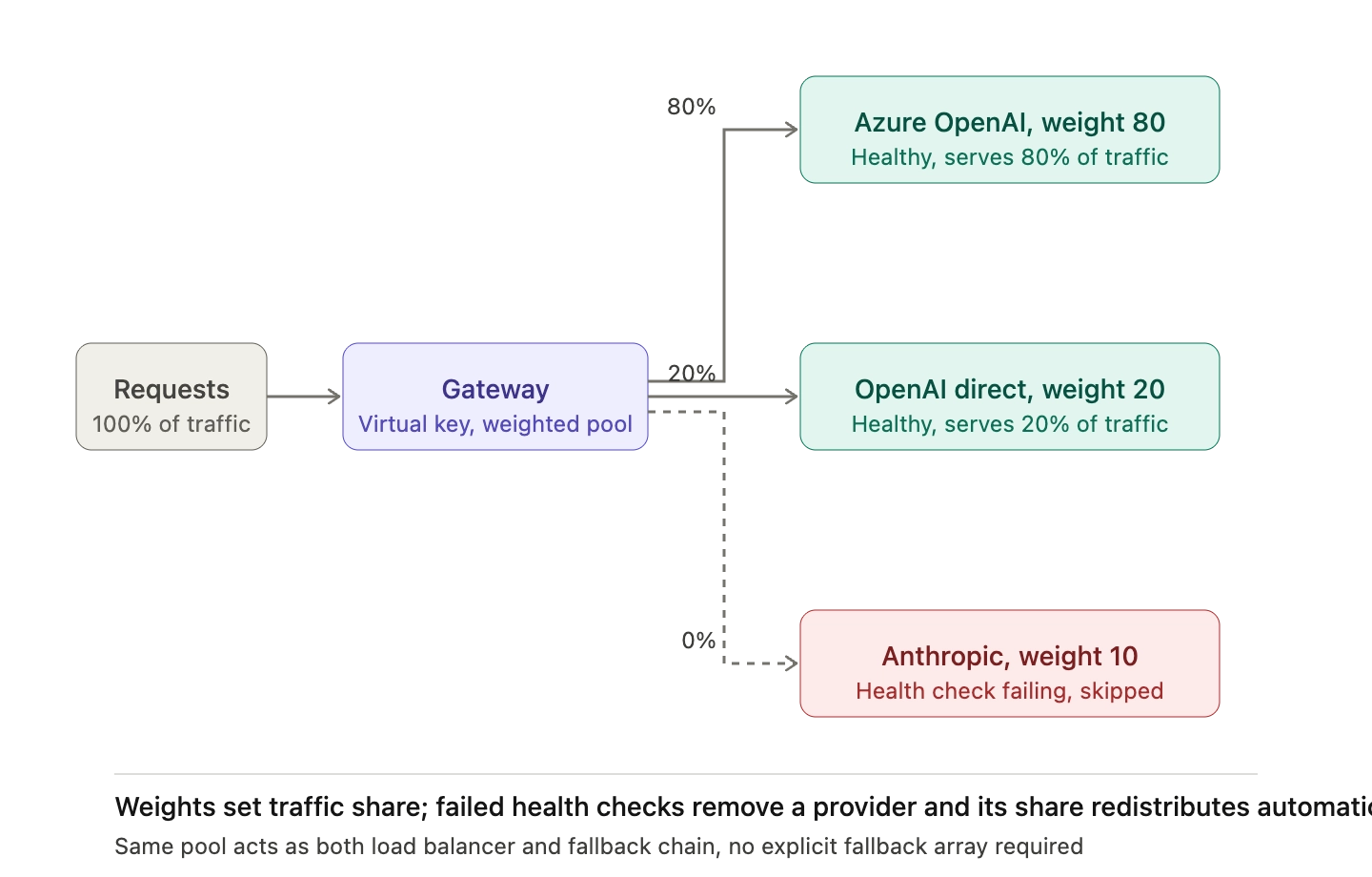
Weighted distribution sits between pure failover and pure load balancing. Traffic is split across multiple providers in fixed proportions (for example, 80% Azure OpenAI, 20% direct OpenAI), and each provider in the pool is itself a fallback target if another fails. This pattern is especially common in multi-region AWS architectures, where Route 53 latency-based routing distributes traffic by region but fails over when health checks mark a region unhealthy.
Bifrost supports weighted distribution at the virtual key level. When multiple providers are configured on a virtual key, Bifrost sorts them by weight and builds the fallback list automatically, so requests without explicit fallback arrays still get failover routing.
Tiered Quality Fallback
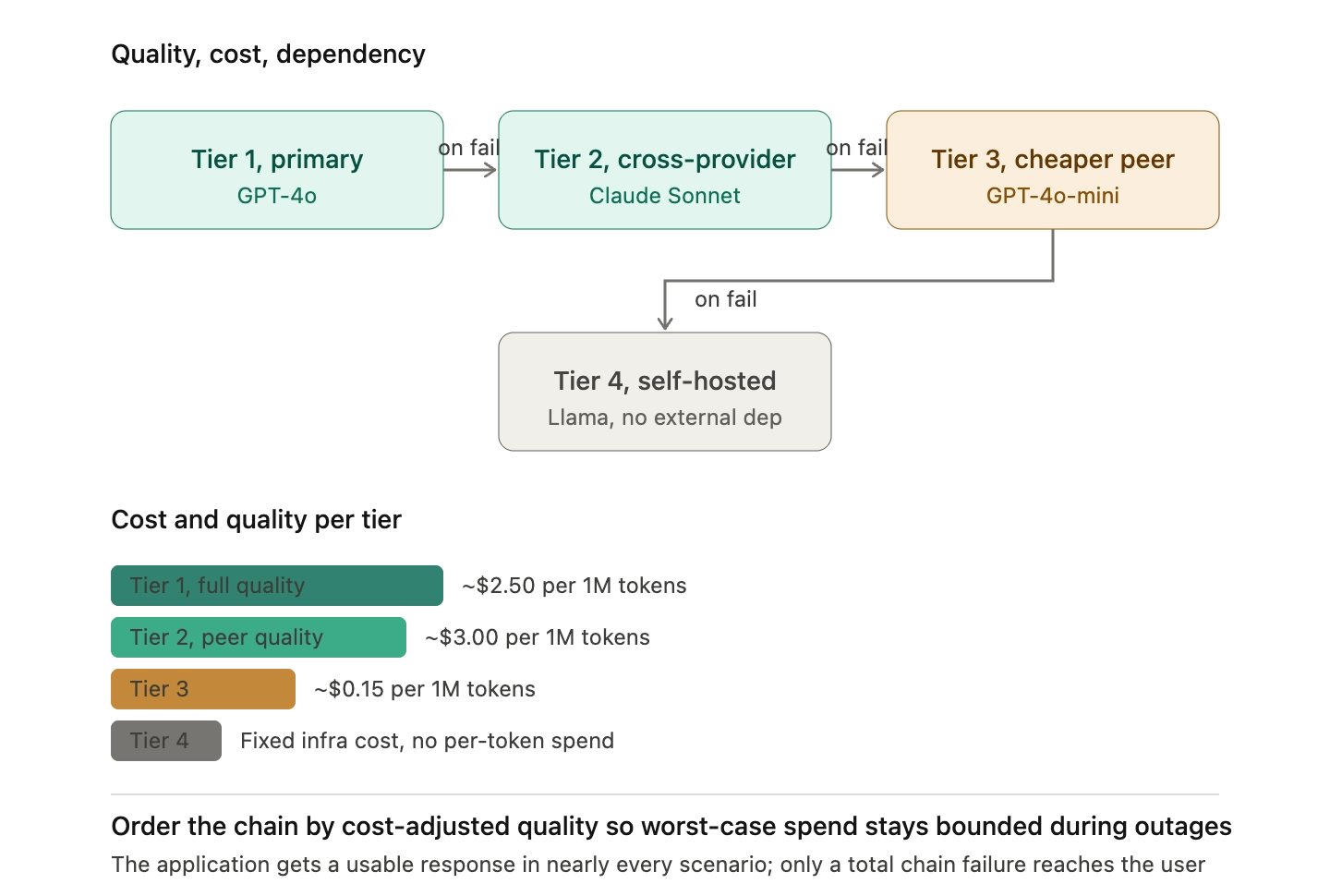
Not every fallback needs to match the primary model's capability. A tiered chain degrades quality gracefully rather than failing the request: GPT-4o (primary) to Claude Sonnet (cross-provider peer) to GPT-4o-mini (cheaper, same provider) to a self-hosted Llama model (no external dependency). The application receives a response in nearly every failure scenario, and only the most catastrophic provider-wide event reaches the user as an error.
This pattern matters for cost as well as reliability. A naive fallback chain that goes from a primary model to a more expensive backup will increase costs during outages, exactly when the business is already absorbing the impact. Ordering the chain by cost-adjusted quality keeps the worst-case spend bounded.
Resilience Patterns That Make Failover Routing Work
Failover routing alone is not enough. Without supporting resilience patterns, an aggressive failover chain can amplify the very outage it is trying to mitigate.
Exponential Backoff with Jitter
When a provider returns transient errors, immediate retries from every client at the same time create a thundering herd. The Google SRE book's chapter on cascading failures is explicit on this point: every client making an RPC must implement exponential backoff with jitter to dampen error amplification. Retries that arrive in synchronized waves can keep a recovering provider from ever stabilizing.
For LLM routing, this means each provider in the fallback chain should be reached with a randomized delay relative to its retry attempt, not on a fixed schedule.
Circuit Breakers
A circuit breaker monitors failure rates per provider and trips open when the rate exceeds a threshold. While the circuit is open, new requests skip the failing provider entirely and go straight to the next in the chain. After a cool-down window, the breaker half-opens to test recovery before resuming normal traffic. AWS documents circuit breaker implementations using Lambda extensions and DynamoDB as the canonical reference, and the pattern is essentially identical for LLM gateways.
Without a circuit breaker, every request to a failing provider waits for its timeout before failing over. With a circuit breaker, the gateway short-circuits known-bad providers and routes to healthy backups in milliseconds.
Health Checks and Adaptive Load Balancing
Synthetic health checks ping each provider on a fixed interval and mark it unhealthy when it fails. Adaptive load balancing goes further: it monitors real request metrics (latency, error rate, success ratio) and shifts traffic proactively before a full outage triggers fallback routing. Bifrost's enterprise tier includes adaptive load balancing that combines real-time health monitoring with predictive scaling, so degraded providers see traffic drop off before requests start to fail.
Governance-Aware Routing
In an enterprise setting, failover routing must respect organizational policy. A fallback from a HIPAA-compliant provider to a non-compliant one is worse than the outage it is supposed to fix. Bifrost's virtual keys act as the governance entity for routing: each virtual key carries its own list of approved providers, budget limits, rate limits, and MCP tool permissions, and fallback chains are constrained to providers the requesting key is authorized to use.
This is the structural difference between a fallback chain configured in application code and one configured at the gateway: the gateway enforces policy on every request, including the fallback path, while application code typically does not.
Implementing Failover Routing with an LLM Gateway
The argument for centralizing failover routing in an AI gateway is operational, not just architectural. Teams that build failover routing in application code end up maintaining custom wrappers for every provider's error format, normalizing rate limit responses across SDKs, and writing glue code that becomes brittle as the provider list grows.
An LLM gateway moves these concerns out of application code:
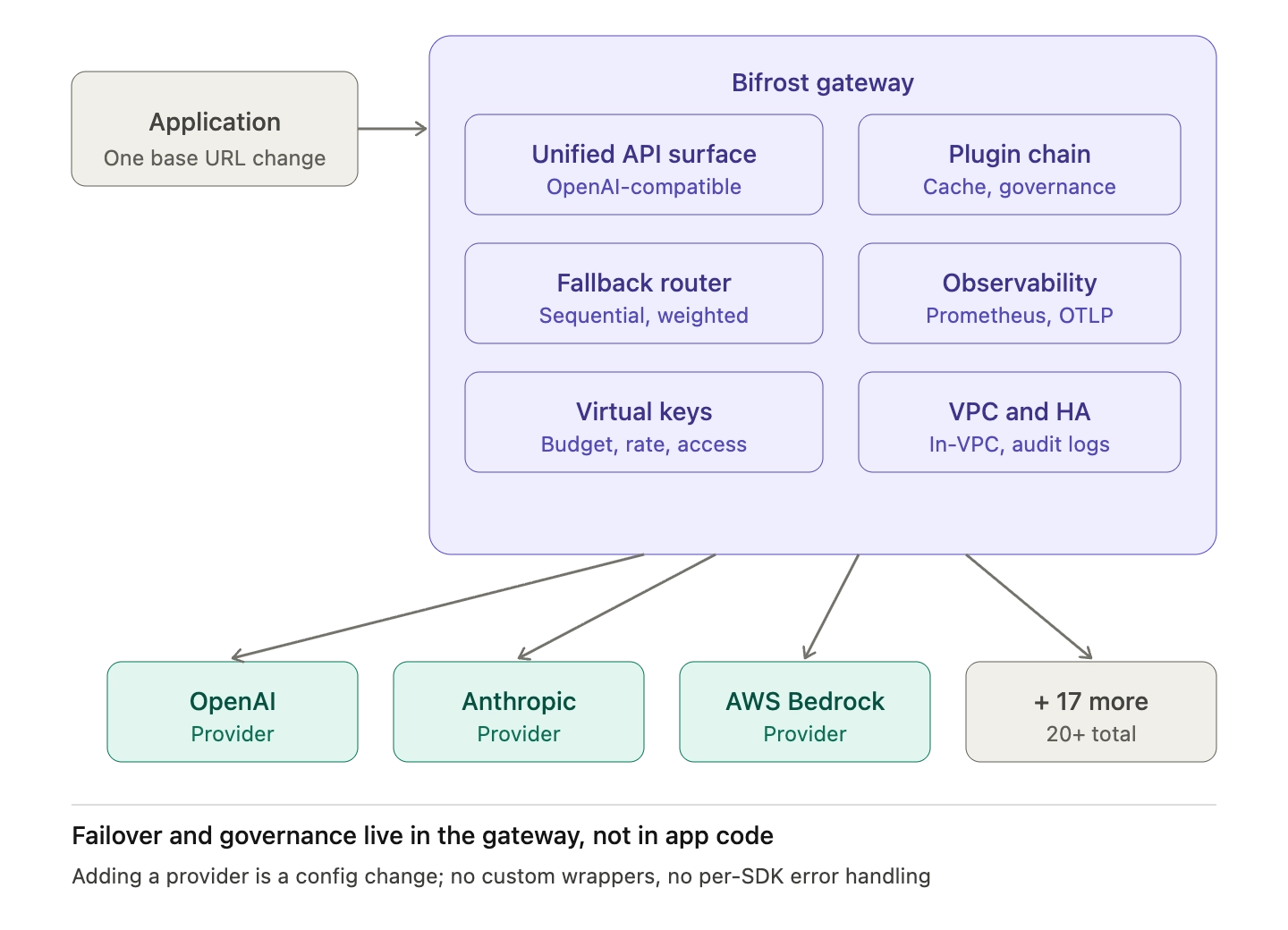
- Unified API surface: Bifrost exposes a single OpenAI-compatible interface for 20+ providers, so fallback configurations work across the full provider matrix without translation.
- Drop-in integration: Bifrost works as a drop-in replacement for existing SDKs by changing only the base URL, so existing application code gains failover routing without modification.
- Centralized observability: Every fallback attempt is captured in Prometheus metrics and OpenTelemetry traces, so teams can monitor fallback trigger rate, per-position success rate, and per-provider latency from a single dashboard.
- Plugin-aware fallbacks: Each fallback attempt re-executes the full plugin chain, so semantic cache hits, governance enforcement, and audit logging remain consistent regardless of which provider ultimately handles the request.
For enterprise deployments, Bifrost runs inside the customer VPC, supports clustering with automatic service discovery for high availability, and produces immutable audit logs that capture every fallback decision for SOC 2 and HIPAA compliance. Teams comparing approaches can review the LLM Gateway Buyer's Guide for a feature-by-feature breakdown of what a production failover routing layer should include.
Operational Practices for Failover Routing
Failover routing is configured once and observed continuously. The metrics that matter:
- Fallback trigger rate: percentage of requests that required at least one fallback. A baseline under 5% is normal; sustained spikes indicate a primary provider problem.
- Success rate by chain position: how often the primary, first fallback, and second fallback succeed. Consistently high first-fallback success means the primary is the wrong choice.
- Latency per provider: measured at the gateway, not the application, so latency-based reordering of the chain reflects what the gateway actually sees.
- Cost per provider: fallback paths to more expensive providers should be flagged and reviewed.
Routine failover drills matter as much as the metrics. The Cisco ThousandEyes post-mortem on the AWS October 2025 outage observed that many "multi-region" architectures failed because the backup region had not been validated under production load. The same applies to LLM fallback chains: a backup provider that has not received real traffic in months is not a backup, it is a guess.
Start Building Resilient LLM Routing with Bifrost
Failover routing strategies for LLMs determine whether an enterprise AI application stays online when its primary provider degrades. Bifrost ships the full set of patterns described above, sequential chains, weighted distribution, plugin-aware fallbacks, circuit-breaker behavior, governance-constrained routing, and adaptive load balancing, as configuration concerns rather than application concerns. To see how Bifrost can replace custom failover logic in your AI stack, book a demo with the Bifrost team.


