Top 5 Prompt Testing & Optimization Tools in 2026

TL;DR
Systematic prompt testing has become essential as AI applications move to production. This guide examines five leading platforms: Maxim AI delivers comprehensive prompt lifecycle management with experimentation, simulation, evaluation, and production monitoring for cross-functional teams. Mirascope provides evaluation-first development with GitHub Actions integration. PromptLayer offers simplified version control with automatic capture. Promptfoo brings CLI-based testing with batch comparison. LangSmith delivers LangChain-native management with deep tracing. Choose based on workflow: Maxim AI for end-to-end coverage, Mirascope for CI/CD testing, PromptLayer for quick versioning, Promptfoo for CLI workflows, and LangSmith for LangChain apps.
Introduction
As AI applications scale to production, prompt quality directly impacts user experience, costs, and reliability. A poorly optimized prompt wastes tokens and inflates spending. An untested change can degrade accuracy across thousands of interactions. Unlike traditional software where outputs are deterministic, LLM applications require specialized testing approaches that account for probabilistic behavior.
Modern prompt management platforms integrate experimentation, systematic testing, evaluation, deployment, and monitoring into unified workflows. This guide examines five platforms leading the space, helping you select the right infrastructure for shipping reliable AI agents.
Table of Contents
- Quick Comparison
- Maxim AI: Comprehensive Prompt Lifecycle Platform
- Mirascope
- PromptLayer: Simplified Version Control
- Promptfoo: Developer-Friendly CLI Testing
- LangSmith: LangChain-Native Management
- How to Choose the Right Tool
- Further Reading
Quick Comparison
| Platform | Best For | Key Strength | Testing Approach | Deployment |
|---|---|---|---|---|
| Maxim AI | Production AI agents with lifecycle needs | End-to-end platform with simulation and observability | Pre-deployment simulation + A/B testing + monitoring | Cloud or self-hosted |
| Mirascope | Python-first LLM developers | Typed SDK for structured LLM workflows | Testable prompt & tool chains via code | Library-based (runs in your stack) |
| PromptLayer | Teams wanting simple versioning | Automatic capture with minimal setup | Visual editor with basic evaluation | Cloud managed |
| Promptfoo | CLI-comfortable developers | Lightweight testing framework | Batch testing with YAML configs | Open-source CLI |
| LangSmith | LangChain/LangGraph apps | Deep framework integration | Offline datasets + online production evals | Cloud or self-hosted |
Maxim AI: Comprehensive Prompt Lifecycle Platform
Platform Overview
Maxim AI provides end-to-end infrastructure for the complete prompt lifecycle from experimentation through production optimization. Unlike tools focusing on single aspects, Maxim integrates experimentation, simulation, evaluation, and observability into unified workflows designed for teams shipping production-grade AI applications.
The platform addresses a fundamental challenge: while prompts determine AI behavior, most teams lack systematic processes for testing them before deployment. Maxim treats prompts with engineering rigor, providing comprehensive pre-deployment simulation, multi-dimensional evaluation, gradual deployment strategies, and continuous production monitoring.
What distinguishes Maxim is cross-functional accessibility. Many prompt tools cater exclusively to engineers, creating bottlenecks when product managers or domain experts need to test variations. Maxim enables non-technical stakeholders to experiment and optimize through intuitive interfaces while providing engineers the systematic testing capabilities required for production reliability.
Key Features
Advanced Experimentation Playground
The Playground++ transforms prompt development from trial-and-error into systematic optimization:
- Versioned Prompt Management: Create, organize, and version prompts with complete history, enabling easy comparison and quick rollbacks
- Multi-Model Comparison: Test prompts side-by-side across OpenAI, Anthropic, Google, AWS Bedrock, and open-source models
- RAG Integration: Connect with vector databases and retrieval pipelines to test prompts with realistic context
- Deployment Strategies: Deploy using A/B tests, canary releases, or gradual rollouts without code changes
Comprehensive Agent Simulation
The simulation suite validates prompts across hundreds of scenarios before production:
- Multi-Turn Testing: Simulate complex interactions across diverse personas and edge cases
- Trajectory Analysis: Evaluate complete agent decision paths rather than individual responses
- Reproducible Debugging: Re-run simulations from any step to isolate and fix issues
- Scenario Coverage: Build comprehensive test suites covering expected behaviors and failure modes
Flexible Evaluation Framework
The evaluation system combines automated metrics with human judgment:
- Evaluator Store: Access pre-built evaluators for common metrics (hallucination detection, accuracy, relevance) or create custom ones
- Multi-Granularity Evaluation: Run evaluations at response, turn, or session levels
- Human-in-the-Loop: Define structured evaluation processes where automated metrics fall short
- Comparative Analysis: Visualize results across prompt versions to identify improvements and regressions
Production Observability
The observability platform provides real-time performance insights:
- Distributed Tracing: Track requests through multi-agent systems
- Quality Monitoring: Run automated evaluations on production traffic to detect degradations
- Custom Dashboards: Create views surfacing application-specific insights
- Alert Configuration: Set up alerts on quality metrics, latency, or cost anomalies
Data-Driven Optimization
- Dataset Curation: Import, organize, and version datasets for systematic testing
- Production Data Enrichment: Evolve test datasets using production logs and feedback
- A/B Test Analysis: Measure prompt performance with statistical significance
Best For
Maxim AI excels for organizations building production AI agents requiring systematic quality assurance. The platform suits teams when:
- Building Multi-Agent Systems: Applications involve sophisticated interactions requiring comprehensive testing
- Cross-Functional Collaboration: Product managers and domain experts need to optimize prompts without engineering bottlenecks
- Enterprise Reliability: Organizations need robust quality guarantees with systematic testing and monitoring
- Rapid Iteration: Teams want to experiment quickly while maintaining production stability
- Lifecycle Management: Unified tooling provides better ROI than multiple point solutions
Companies like Clinc, Thoughtful, and Comm100 use Maxim to maintain quality and ship faster.
Request a demo to see how Maxim accelerates prompt optimization.
5. Mirascope: Lightweight Python Toolkit
Platform Overview
Mirascope is a minimalist Python toolkit for building LLM applications, paired with Lilypad for prompt management and observability. The project emphasizes using native Python constructs rather than introducing proprietary abstractions.
Key Benefits
Code-first approach: Mirascope relies on Python functions, decorators, and Pydantic models rather than custom DSLs or configuration formats. This makes it intuitive for Python developers and reduces the learning curve.
Automatic versioning: Lilypad's @trace decorator automatically versions every LLM call along with the complete execution context. This includes not just the prompt template but also input data, model settings, and surrounding code.
Framework agnostic: Works alongside other frameworks like LangChain without lock-in. The @trace decorator can be applied to any Python function, making it flexible for diverse workflows.
PromptLayer: Simplified Version Control
Platform Overview
PromptLayer provides prompt management focused on simplicity and minimal integration. Teams can start versioning by wrapping LLM calls with a few lines of code.
Key Features
- Automatic Versioning: Every LLM call creates a version without manual tracking
- Visual Editor: Update prompts from dashboard without code changes
- Cost Tracking: Monitor usage and performance trends
- Basic Evaluation: Compare versions with human and AI graders
Best For
PromptLayer suits small teams and early-stage projects prioritizing quick adoption over comprehensive features.
Promptfoo: Developer-Friendly CLI Testing
Platform Overview
Promptfoo provides open-source CLI testing for systematic prompt evaluation. The platform emphasizes developer workflows through command-line interfaces and YAML configuration.
Key Features
- Batch Testing: Compare prompt variations against scenarios simultaneously
- YAML Configuration: Define tests in version-controlled files
- CI/CD Integration: Run tests in continuous integration pipelines
- Multi-Provider Support: Test across OpenAI, Anthropic, Google, and open-source models
- Local Execution: Run tests locally maintaining data privacy
Best For
Promptfoo fits developers comfortable with CLI workflows wanting lightweight testing without platform overhead.
LangSmith: LangChain-Native Management
Platform Overview
LangSmith delivers observability and evaluation built by LangChain's creators for teams using LangChain or LangGraph frameworks.
Key Features
- Deep Chain Tracing: Capture every step with automatic instrumentation
- Prompt Playground: Iterate with dataset-based testing
- Annotation Queues: Streamline human feedback collection
- Multi-Turn Evaluation: Assess complete conversations
- Insights Agent: Automatically categorize usage patterns
Best For
LangSmith works best for teams fully committed to the LangChain ecosystem, needing deep visibility into chain execution.
How to Choose the Right Tool
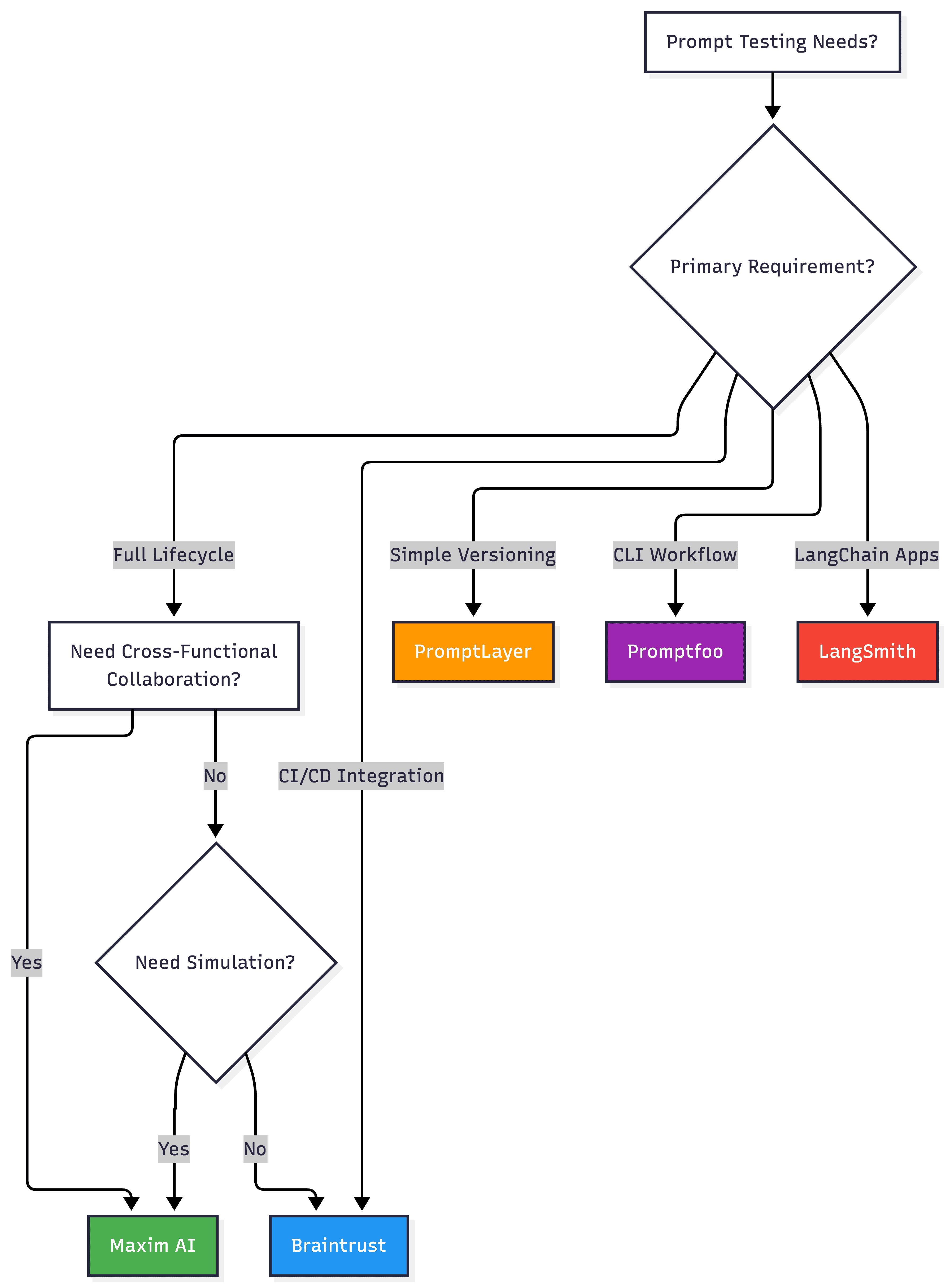
Choose Maxim AI when:
- Building production AI agents requiring systematic quality assurance across full lifecycle
- Cross-functional teams need to test prompts without engineering dependencies
- Agent simulation for testing complex scenarios is essential
- Unified tooling provides better ROI than multiple point solutions
Choose Mirascope when:
- Engineering teams prioritize evaluation in CI/CD workflows
- Python toolkit for building LLM applications
Choose PromptLayer when:
- Small teams prioritize quick adoption with minimal setup
- Simple version control meets current needs
- Cost-effectiveness is primary consideration for early-stage projects
Choose Promptfoo when:
- Developers prefer CLI-first workflows over UIs
- Local execution for data privacy is required
- Lightweight open-source tools preferred over platforms
Choose LangSmith when:
- Applications built on LangChain or LangGraph frameworks
- Deep visibility into chain execution is critical
- LangChain ecosystem alignment outweighs vendor-neutral needs
For production AI applications involving multi-agent systems or enterprise reliability requirements, comprehensive platforms like Maxim AI deliver the strongest ROI through integrated simulation, evaluation, and observability.
Further Reading
Resources
- What Are AI Evals? A Comprehensive Guide
- How to Detect and Prevent Hallucinations in LLM Applications
- Agent Tracing for Debugging Multi-Agent AI Systems
Platform Comparisons
Conclusion
Prompt testing and optimization have evolved from optional practices into essential infrastructure for production AI. The five platforms examined offer distinct approaches: Maxim AI delivers comprehensive lifecycle management, Mirascope emphasizes using native Python constructs rather than introducing proprietary abstractions, PromptLayer offers simplified versioning, Promptfoo brings CLI testing, and LangSmith enables LangChain-native management.
The right testing infrastructure accelerates shipping reliable AI by validating changes before production, enabling rapid iteration with confidence, and maintaining quality visibility over time.
Ready to elevate your prompt testing? Explore Maxim AI to see how end-to-end lifecycle management transforms building and optimizing AI applications at scale.


