Top 5 AI Evaluation Platforms in 2025: Why API Endpoint Based Testing Matters for Agent Development

TL;DR
Choosing the right AI evaluation platform significantly impacts development velocity and agent quality. This analysis compares five leading platforms: Maxim AI, Langfuse, Arize, Galileo, and DeepEvals. While most platforms require SDK integration into your codebase, Maxim uniquely offers HTTP API endpoint-based testing, allowing teams to evaluate agents through their APIs without code modifications. This capability proves essential for organizations using no-code platforms, proprietary frameworks, or maintaining multiple agent architectures. Combined with comprehensive simulation, evaluation, and observability features, Maxim enables faster, more flexible agent development across diverse technical environments.
Table of Contents
- The Agent Evaluation Challenge
- Why HTTP API based Endpoint Testing Matters
- Top 5 AI Evaluation Platforms
- Platform Comparison
- Choosing the Right Platform
The Agent Evaluation Challenge
AI agents have moved from experimental projects to production systems handling critical business workflows. According to research on AI deployment, 60% of organizations now run agents in production, yet 39% of AI projects fail to meet quality expectations. This gap stems from the fundamental challenge of evaluating non-deterministic systems that make autonomous decisions.
Traditional evaluation platforms require extensive SDK integration into your application code to capture traces and run evaluations. While this provides visibility, it creates significant overhead. Development teams must instrument code, manage SDK versions, and handle potential performance impacts. For teams building with no-code platforms like AWS Bedrock Agents or Glean, SDK integration becomes impossible since these platforms don't expose internal code for instrumentation.
This architectural limitation has driven demand for alternative approaches that enable evaluation without code modifications. The solution lies in treating agents as black-box systems accessible through their production APIs.
Why HTTP API based Endpoint Testing Matters
HTTP endpoint testing represents a fundamentally different approach to agent evaluation. Instead of instrumenting your application code with SDKs, you evaluate agents by calling their production APIs directly. This architecture delivers critical advantages for modern AI development.
Framework and Platform Neutrality
Your agent might be built with LangGraph, CrewAI, AutoGen, proprietary frameworks, or no-code platforms. HTTP endpoint testing evaluates them all identically through their REST APIs. This neutrality matters as organizations rarely standardize on a single development approach. Different teams might build agents with different tools, yet all can be evaluated through one unified platform.
Enabling No-Code Agent Evaluation
The rise of no-code agent builders creates evaluation challenges for traditional SDK-based approaches. Platforms like AWS Bedrock Agents and Glean don't expose internal code for instrumentation. HTTP endpoint testing solves this completely by evaluating agents through their APIs regardless of how they were built.
Production Parity
HTTP endpoint testing evaluates production-ready systems through their actual APIs. No instrumentation code, no special test modes, no SDK wrappers that might alter behavior. You test exactly what ships to production, ensuring evaluation results accurately predict production performance. According to research on AI reliability, testing production-equivalent systems catches significantly more issues before deployment.
Cross-Functional Collaboration
When evaluation requires no code changes, product teams can independently configure tests, run evaluations, and analyze results. This accessibility accelerates iteration cycles by eliminating engineering bottlenecks for quality assessment.
Top 5 AI Evaluation Platforms
1. Maxim AI: Full-Stack Platform with HTTP Endpoint Testing
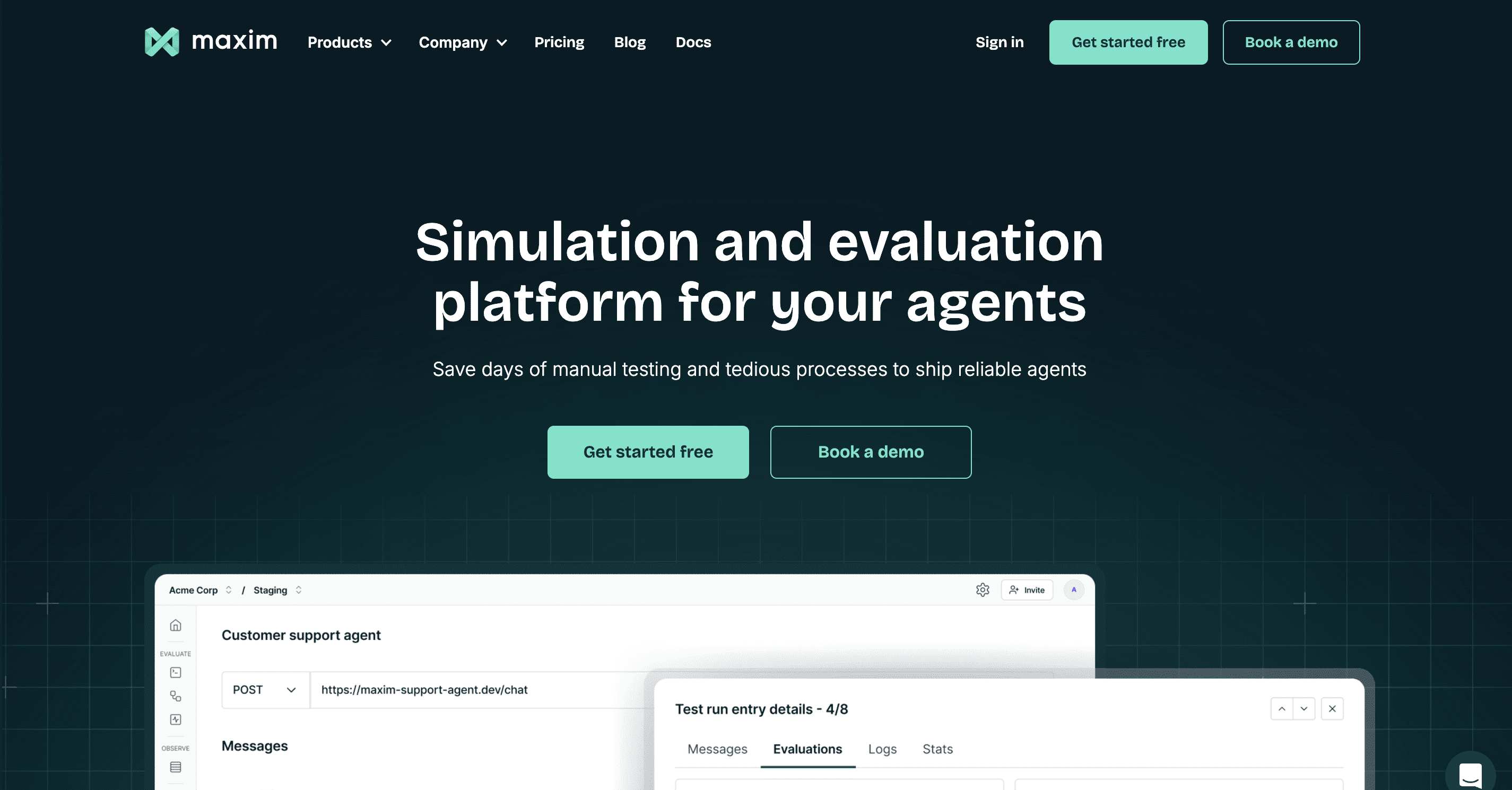
Maxim AI stands alone as the only platform offering HTTP endpoint-based testing, enabling teams to evaluate any agent through its API without code modifications. This unique capability combines with comprehensive simulation, evaluation, experimentation, and observability features.
Key HTTP Endpoint Capabilities:
- UI-driven endpoint configuration requiring no code
- SDK-based programmatic testing for CI/CD integration
- Dynamic variable substitution using
{{column_name}}syntax - Pre and post-request scripts for complex workflows
- Environment management for testing across deployments
- Multi-turn conversation testing with node level and session level evals
Beyond Endpoint Testing: Maxim provides the complete agent development toolkit including agent simulation across hundreds of scenarios, unified evaluation framework with pre-built and custom evaluators, real-time observability with distributed tracing, Playground++ for prompt experimentation, and comprehensive data management.
Enterprise Features: SOC2, GDPR, HIPAA compliance, self-hosted deployment options, advanced RBAC, and multi-repository support for managing multiple applications.
Best For: Teams building with no-code platforms, diverse frameworks, or requiring cross-functional evaluation access without engineering bottlenecks.
Start free trial | Book demo | Compare with other platforms
2. Langfuse: Open-Source Observability

Langfuse provides open-source LLM observability and evaluation with strong tracing capabilities and LangChain/LangGraph integration. The platform requires SDK integration for capturing agent behavior, making it suitable for teams building with these frameworks who can instrument application code.
Key Capabilities: Comprehensive tracing with tool call visualization, dataset experiments with offline/online evaluation, human annotation workflows, and Model Context Protocol support.
Best For: Teams prioritizing open-source transparency, using LangChain/LangGraph frameworks, and comfortable with SDK integration requirements.
3. Arize: ML Observability for LLMs
Arize extends proven ML observability practices to LLM agents with focus on production monitoring and drift detection. The platform provides granular tracing and enterprise compliance features but requires SDK integration and emphasizes monitoring over pre-release experimentation.
Key Capabilities: Multi-level tracing, automated drift detection, real-time alerting with Slack/PagerDuty integration, specialized RAG evaluators, and enterprise compliance (SOC2, GDPR, HIPAA).
Best For: Organizations with mature ML infrastructure seeking to extend observability to LLM applications, primarily focused on production monitoring.
4. Galileo: Safety-Focused Reliability
Galileo emphasizes agent reliability through built-in guardrails and safety-focused evaluation. The platform provides solid evaluation capabilities with partnerships with CrewAI and NVIDIA, though requiring SDK integration and offering narrower scope compared to comprehensive platforms.
Key Capabilities: Galileo Protect for real-time safety checks, hallucination detection, bias monitoring, Luna-2 models for in-production evaluation, and NVIDIA NIM guardrails integration.
Best For: Organizations prioritizing safety and reliability, requiring built-in guardrails for sensitive domains, or using CrewAI/NVIDIA tools.
DeepEval
Platform Overview
DeepEval is a Python-first LLM evaluation framework similar to Pytest but specialized for testing LLM outputs. DeepEval provides comprehensive RAG evaluation metrics alongside tools for unit testing, CI/CD integration, and component-level debugging.
Best For
DeepEval suits engineering teams that want production-grade testing infrastructure for RAG applications in CI/CD pipelines, need granular component-level evaluation for debugging, or prefer code-first workflows with strong Python integration. The framework works particularly well for teams familiar with Pytest patterns.
Platform Comparison
Evaluation Approach
| Platform | Evaluation Method | No-Code Agent Support | Cross-Functional Access | CI/CD Integration |
|---|---|---|---|---|
| Maxim AI | HTTP Endpoint Testing | ✅ Full Support | ✅ Excellent | ✅ Native |
| Langfuse | SDK Integration | ❌ Not Supported | ⚠ Limited | ✅ Available |
| Arize | SDK Integration | ❌ Not Supported | ⚠️ Limited | ✅ Available |
| Galileo | SDK Integration | ❌ Not Supported | ⚠️ Limited | ⚠️ Limited |
| DeepEval | SDK / Python Integration | ❌ Not Supported | ❌ Engineering Only | ⚠️ Limited |
Feature Coverage
| Platform | Simulation | Experimentation | Observability | Multi-Turn Testing | Data Management |
|---|---|---|---|---|---|
| Maxim AI | ✅ Advanced | ✅ Playground++ | ✅ Real-time | ✅ Native | ✅ Data Engine |
| Langfuse | ❌ None | ⚠ Basic | ✅ Strong | ✅ Good | ⚠️ Basic |
| Arize | ❌ None | ❌ Limited | ✅ Excellent | ✅ Good | ❌ Limited |
| Galileo | ❌ None | ⚠ Limited | ✅ Good | ⚠️ Limited | ❌ Limited |
| DeepEval | ❌ None | ⚠️ Playground | ❌ Limited | ⚠️ Limited | ❌ Limited |
Choosing the Right Platform
Choose Maxim AI if you:
- Build agents with no-code platforms like AWS Bedrock Agents or Glean
- Use diverse frameworks and need unified, framework-agnostic evaluation
- Need product teams to run evaluations independently without engineering support
- Want to evaluate production-ready systems without code instrumentation
- Require comprehensive lifecycle coverage from experimentation through production monitoring
Choose Langfuse if you:
- Build exclusively with LangChain or LangGraph frameworks
- Prioritize open-source transparency and self-hosting
- Have strong engineering resources for SDK integration and maintenance
- Primarily need tracing and debugging capabilities
Choose Arize if you:
- Have mature MLOps infrastructure to extend to LLM applications
- Focus primarily on production monitoring versus pre-release evaluation
- Require enterprise compliance with established governance workflows
Choose Galileo if you:
- Prioritize safety and reliability above other considerations
- Require built-in guardrails for sensitive domains
- Use CrewAI or NVIDIA tools extensively
Choose DeepEvals if you:
- Operate engineering-only workflows without cross-functional needs
- Accept closed-source platforms with limited transparency
According to research on agent evaluation, teams with cross-functional evaluation access deploy features 40-60% faster. Organizations building with diverse frameworks benefit significantly from platform-agnostic evaluation approaches.
Conclusion
The right AI evaluation platform significantly impacts development velocity and quality outcomes. While all five platforms provide valuable capabilities, they differ fundamentally in evaluation architecture and feature breadth.
Maxim AI stands alone in offering HTTP endpoint-based testing, enabling universal agent evaluation regardless of framework, platform, or architecture. This unique capability proves essential for teams building with no-code platforms, maintaining diverse agent architectures, or requiring cross-functional evaluation access. Combined with comprehensive simulation, evaluation, experimentation, and observability features, Maxim provides the complete toolkit for production-grade agent development.
For teams building mission-critical AI agents, HTTP endpoint testing eliminates SDK integration overhead, enables framework-neutral evaluation, ensures production parity, and accelerates cross-functional collaboration. These advantages translate directly to faster deployment cycles and higher-quality production systems.
Ready to evaluate your agents without code changes? Start your free trial or book a demo to see HTTP endpoint testing in action.
Additional Resources
HTTP Endpoint Testing:
Agent Evaluation Best Practices:
No-Code Agent Evaluation:
Platform Comparisons:


