Top 9 AI Observability Platforms to Track for Agents in 2025

TLDR
As AI agents become more complex and production deployments scale, observability has shifted from optional to essential. In 2025, enterprises require platforms that provide distributed tracing across agent systems, automated quality monitoring, debugging capabilities, and multi-modal support. Maxim AI stands out with its comprehensive full-stack approach combining experimentation, simulation, evaluation, and observability delivering 5x faster AI delivery. Other leading platforms like Arize, Datadog, LangSmith, WhyLabs, Comet, Fiddler, LangFuse, and Helicone each offer distinct strengths, from traditional MLOps focus to lightweight LLM-specific monitoring. Choosing the right platform depends on your team structure, deployment complexity, and whether you need observability alone or integrated lifecycle management.
Introduction
The complexity of managing AI agent systems has fundamentally transformed the operational landscape for engineering teams. As agents become more autonomous, handling multiple tasks across different domains, the traditional metrics used to monitor software systems prove insufficient. Unlike deterministic applications with predictable behavior and clear success criteria, AI agents operate with inherent variability, their decisions depend on model outputs, context, and real-time interactions that shift with each execution.
This variability creates an urgent need for AI observability. When a chatbot fails to resolve a customer issue, an agent provides incorrect information, or a workflow executes unexpected steps, teams need the ability to trace exactly what happened at every stage. They need to understand which model generated a response, what context was provided, which tools were invoked, and why the agent made specific decisions.
The challenge intensifies as enterprises deploy multiple agents across production environments. Without proper observability infrastructure, debugging becomes a maze of logs, incomplete traces, and missing context. Incidents that should take minutes to resolve can consume hours. Quality issues emerge in production but remain invisible until customers are affected.
Why AI Agent Observability Matters in 2025
Non-Deterministic Behavior Creates New Debugging Challenges
AI agents don't behave the same way twice. The same input fed to an agent on different occasions can produce different outputs depending on model temperature, sampling parameters, or the order in which information is retrieved. This non-deterministic nature means traditional debugging approaches fail.
When a software bug occurs, engineers can reproduce it reliably and trace the root cause through deterministic code paths. Agent debugging requires a different mindset. Teams need to observe dozens of interactions, identify patterns in failures, and understand the context surrounding edge cases. Observability platforms capture this context: the prompts used, retrieval results, model parameters, token counts, and latency metrics at each step.
Model Drift and Quality Degradation
Model behavior changes over time. A language model that performed well for a specific task six months ago may produce different quality outputs today due to model updates, deployment drift, or shifts in the data the agent encounters. Detecting and responding to this degradation requires continuous monitoring in production.
AI observability platforms provide real-time evaluation capabilities that automatically assess agent outputs against defined quality metrics. Instead of discovering quality issues through customer complaints, teams receive alerts when performance metrics decline, enabling rapid remediation before users are impacted.
Difficult Debugging and Root Cause Analysis
When an agent fails, finding the root cause isn't straightforward. Did the model generate an incorrect response? Did retrieval return irrelevant context? Did a tool call fail? Was the prompt poorly constructed? Multiple layers of potential failure points exist, and traditional logs often don't capture the information needed to distinguish between them.
Observability platforms designed for agents capture detailed traces that show the complete execution flow. Teams can visualize trace timelines and step through interactions at the span level, examining individual prompts, model responses, tool invocations, and evaluation results to pinpoint exactly where things went wrong.
Multi-Modal Complexity Across Voice, Text, and Vision
Modern agents operate across multiple modalities—text-based chatbots, voice agents, and vision-enabled systems. Each modality introduces unique observability challenges. Voice agents require specialized tracing for audio input, speech-to-text conversion, model inference, and text-to-speech synthesis. Vision agents need to track image processing and multimodal model behavior.
Platforms that natively support multi-modal observability eliminate the need to cobble together separate monitoring solutions for different agent types, streamlining operations and providing unified insights across your agent infrastructure.
Top 9 AI Observability Platforms
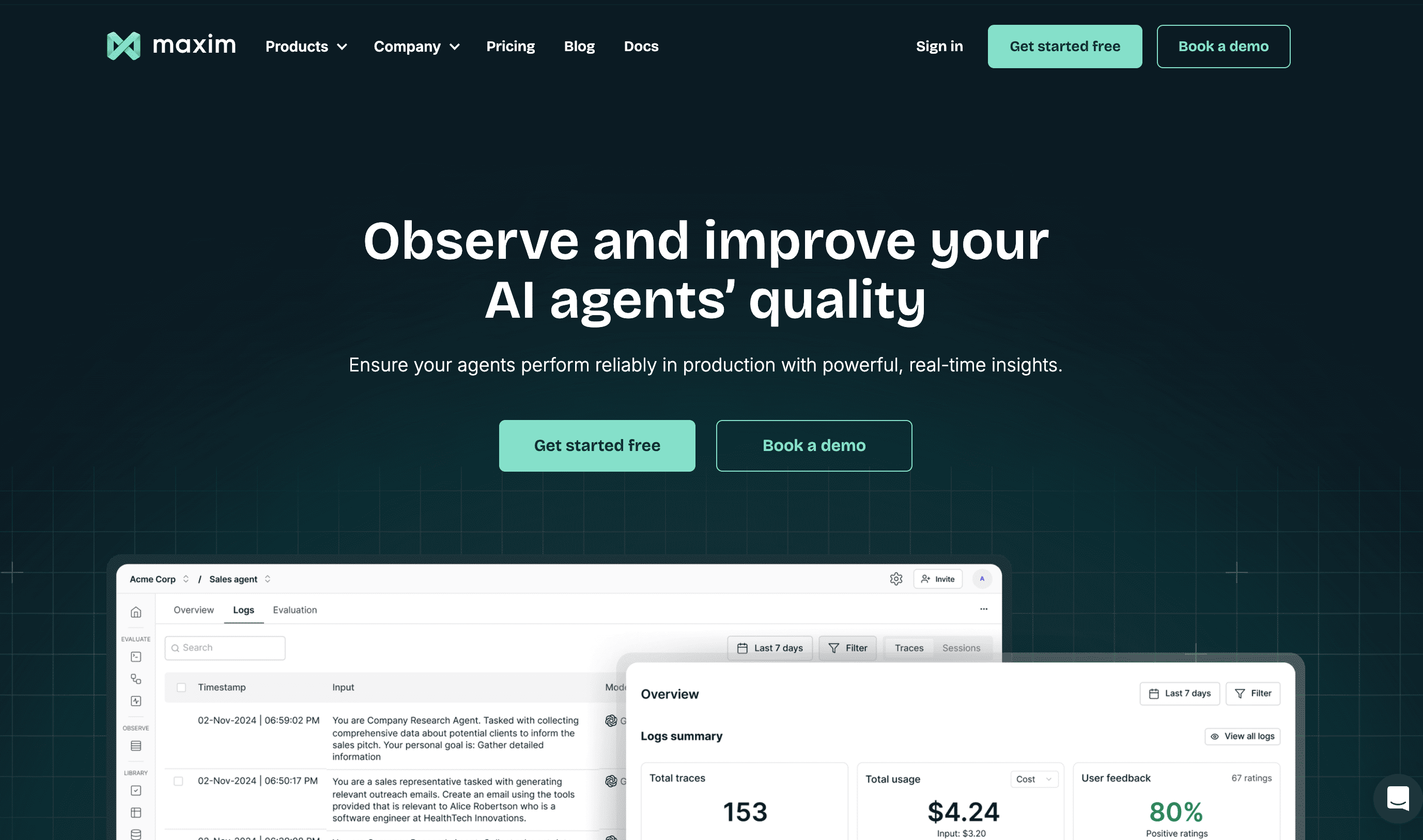
1. Maxim AI
Maxim AI provides an end-to-end platform that extends beyond observability to encompass the entire AI application lifecycle. While observability is a core capability, Maxim differentiates itself through comprehensive support for experimentation, simulation, evaluation, and production monitoring, all designed for cross-functional teams.
Key Differentiators:
- Full-stack lifecycle management: Unlike single-purpose observability tools, Maxim helps teams move faster across pre-release experimentation and production monitoring. You can manage prompts and versions, run simulations against hundreds of scenarios, evaluate agents using off-the-shelf or custom metrics, and monitor live production behavior—all from a unified interface.
- Cross-functional collaboration: Maxim's interface is specifically built for how AI engineering and product teams collaborate. Product managers can define evaluation criteria and run quality assessments without code, while engineers maintain deep control through SDKs available in Python, TypeScript, Java, and Go.
- Distributed tracing with multi-modal support: Maxim provides deep, distributed tracing that captures traditional infrastructure events and LLM-specific elements like prompts, responses, tool use, and context injection. The platform supports text, voice, and vision agents natively.
- Custom dashboards and flexible evaluations: Teams can configure custom dashboards to visualize agent behavior across custom dimensions without dashboard templating constraints. Evaluations are configurable at session, trace, or span granularity.
- Model-centric observability: The platform excels at tracking model versions, comparing their behavior, and identifying degradation patterns.
Core Features:
- Distributed tracing across agent systems with visual timeline inspection
- Automated drift and anomaly detection
- Production debugging and root cause analysis
- Cost tracking and optimization
- Online evaluators that continuously assess real-world agent interactions
- Custom alerting for latency, token usage, evaluation scores, and metadata
- OpenTelemetry compatibility for forwarding traces to Datadog, Grafana, or New Relic
- Prompt management and versioning for experimentation workflows
- Agent simulation for testing across hundreds of scenarios and personas
Best For: Organizations needing comprehensive AI lifecycle management, cross-functional collaboration between engineers and product teams, distributed tracing, node-level evaluations, and multi-modal agent deployments.
2. Arize
Arize focuses on production AI monitoring and model performance management, positioning itself as a comprehensive MLOps platform with extended capabilities for LLM and agent systems.
Key Differentiators:
- Model-centric observability: Arize prioritizes model health monitoring, production drift detection, and model performance insights.
- Enterprise scale and governance: Built for large organizations, Arize provides role-based access control, audit trails, and compliance features needed in regulated industries.
- Integration with ML workflows: The platform integrates deeply with ML infrastructure, supporting model registries, feature stores, and retraining pipelines.
Core Features:
- Real-time model performance monitoring
- Automated drift and anomaly detection
- Production debugging and root cause analysis
- Model comparison and performance benchmarking
- Integration with data warehouses and feature platforms
Best For: Large enterprises with existing MLOps infrastructure, teams focused on traditional model monitoring looking to extend into LLM domains, and organizations requiring advanced governance and compliance features.
3. LangSmith
LangSmith, developed by LangChain, offers observability specifically tailored to LLM application development and debugging. It integrates natively with the LangChain ecosystem but supports other frameworks as well.
Key Differentiators:
- LangChain-native integration: Seamless integration with LangChain applications reduces instrumentation overhead. Teams already using LangChain get observability with minimal code changes.
- Focused on application debugging: LangSmith excels at capturing detailed traces of LLM application execution, including prompt inputs, model outputs, and intermediate steps.
- Developer-friendly interface: The platform emphasizes ease of use for developers, with straightforward trace visualization and debugging workflows.
Core Features:
- Detailed LLM application tracing
- Automatic capture of prompts, outputs, and token counts
- Dataset management for evaluation and testing
- Run comparison and analysis
- Integration with LangChain agents and chains
Best For: Development teams already invested in the LangChain ecosystem, small to mid-sized organizations focused on LLM application quality, and teams seeking lightweight observability without extensive MLOps requirements.
4.WhyLabs
WhyLabs is a data-first observability platform that has expanded from traditional ML monitoring into LLM and agent workloads, with a strong focus on data quality, drift, and anomalies.
Key Differentiators:
WhyLabs takes a data-centric approach, continuously monitoring input features, prompts, and outputs for distribution shifts and silent failures. Its privacy-preserving telemetry is well-suited for enterprises that need deep monitoring without exposing sensitive raw data.
Core Features:
Real-time data quality and drift monitoring, LLM and agent metrics, automated alerting, privacy-aware logging, and integrations with common data and ML stacks.
Best For:
Data-heavy teams that prioritize input and feature reliability, mature ML organizations extending into LLM/agent use cases, and enterprises needing strict data governance and privacy-aware observability.
5. LangFuse
LangFuse is an open-source observability platform designed specifically for LLM applications, offering transparency and flexibility through self-hosted deployment options alongside cloud hosting.

Key Differentiators:
- Open-source foundation: The open-source nature provides flexibility for organizations needing custom modifications or self-hosted deployments.
- LLM-specific tracing: Built from the ground up for LLM applications, with native support for tracking prompts, completions, and token usage.
- Cost transparency: Open-source deployment allows organizations to understand and control their observability infrastructure costs.
Core Features:
- Comprehensive LLM application tracing
- Cost tracking and optimization
- Prompt management and versioning
- Evaluation capabilities
- Self-hosted and cloud deployment options
Best For: Organizations valuing transparency through open-source software, teams with self-hosted infrastructure requirements, and development teams seeking cost-effective LLM observability.
6. Helicone
Helicone positions itself as a lightweight observability layer for LLM applications, focusing on ease of deployment and minimal integration overhead.

Key Differentiators:
- Drop-in integration: Helicone acts as a reverse proxy to OpenAI and other LLM APIs, requiring minimal code changes. Teams can add observability by routing API calls through Helicone.
- Minimal latency impact: Designed as a thin observability layer, Helicone adds minimal overhead to API calls.
- Cost and usage analytics: Strong capabilities for tracking API costs and identifying optimization opportunities.
Core Features:
- Reverse proxy-based API monitoring
- Request and response logging
- Cost and usage analytics
- Performance metrics and latency tracking
- Cache management for cost reduction
Best For: Teams seeking lightweight observability without extensive code refactoring, organizations focused on LLM API cost optimization, and development teams prioritizing minimal integration complexity.
7. Comet
Comet provides machine learning operations platform with extended capabilities for LLM application monitoring and evaluation.
Key Differentiators:
- Experiment tracking and MLOps: Comet's foundation in experiment tracking makes it valuable for teams managing multiple model versions and configurations.
- Broad AI application support: Beyond LLMs, Comet supports traditional ML models, computer vision, and other AI applications, making it suitable for organizations with diverse AI workloads.
- Collaborative workflows: Built-in collaboration features help teams share insights and coordinate on experiments.
Core Features:
- Experiment tracking and versioning
- Model performance monitoring
- Dataset management
- Collaborative notebooks and analysis
- Integration with training pipelines
Best For: Organizations managing diverse AI workloads across traditional ML and LLM applications, teams conducting extensive experimentation and model iteration, and enterprises requiring collaborative ML infrastructure.
8. Fiddler
Fiddler specializes in model monitoring and explainability, with a strong focus on regulatory compliance and model governance for enterprise organizations.
Key Differentiators:
- Model explainability: Fiddler provides detailed explanations for model predictions, helping teams understand and justify model decisions.
- Regulatory compliance: Built for regulated industries with features for model governance, audit trails, and fairness monitoring.
- Production model focus: Emphasizes monitoring deployed production models rather than development-phase debugging.
Core Features:
- Model performance monitoring and drift detection
- Feature importance and explainability analysis
- Fairness and bias monitoring
- Model governance and audit trails
- Integration with model deployment platforms
Best For: Regulated industries requiring model explainability and governance, enterprise organizations with strict compliance requirements, and teams focused on traditional ML model monitoring looking to extend into LLM spaces.
9. Datadog
Datadog represents the traditional observability and monitoring platform extended to include AI-specific capabilities. It provides unified monitoring across infrastructure, applications, and increasingly, AI systems.
Key Differentiators:
- Unified monitoring infrastructure: Datadog integrates AI observability with traditional application and infrastructure monitoring, providing a single pane of glass for complete system visibility.
- Enterprise scale and reliability: Built for enterprise deployments with proven scalability, reliability, and 24/7 support.
- Extensive integrations: Datadog integrates with hundreds of tools and services, making it suitable for complex environments with diverse technology stacks.
Core Features:
- Infrastructure and application performance monitoring
- LLM application tracing through integrations
- Log aggregation and analysis
- Custom dashboards and alerting
- Distributed tracing capabilities
Best For: Large enterprises already using Datadog for infrastructure monitoring, organizations seeking unified visibility across infrastructure and AI systems, and teams requiring enterprise-grade support and SLAs.
Conclusion
AI observability in 2025 is no longer optional, it's foundational to reliable AI agent deployment. The landscape includes platforms ranging from specialized LLM-focused solutions to comprehensive lifecycle platforms to traditional observability tools extending into AI.
Maxim AI stands out by providing not just observability but a complete platform for AI application development, evaluation, and production monitoring. Its focus on cross-functional collaboration, multi-modal support, and 5x faster delivery makes it particularly valuable for organizations building sophisticated agent systems at scale.
However, the right platform depends on your specific context. Organizations already invested in LangChain benefit from LangSmith's native integration. Enterprise teams with existing MLOps infrastructure may prefer Arize or Fiddler. Those seeking lightweight LLM monitoring might choose Helicone or LangFuse.
The key is recognizing that as AI agents become more critical to business operations, visibility into their behavior becomes equally critical. Investing in proper observability infrastructure today prevents costly incidents and enables continuous improvement of AI application quality tomorrow.
To get started with comprehensive AI agent observability and lifecycle management, explore Maxim AI's full platform capabilities or sign up for a free account to experience how teams are shipping AI agents 5x faster.
Additional Reading and Resources
- The Definitive Guide to Enterprise AI Observability
- Observability and Evaluation Strategies for Tool-Calling AI Agents: A Complete Guide
- Context Engineering for AI Agents: Token Economics and Production Optimization Strategies
Frequently Asked Questions
What is AI observability? AI observability refers to the ability to monitor, trace, and evaluate AI system behavior across real-world interactions. For agents, it means gaining visibility into decision-making, model outputs, and performance at every step—from initial input through tool invocation to final output generation.
Why is observability critical for AI agents? AI agents operate with inherent variability. Without observability, debugging failures becomes impossible when the same input produces different outputs. Observability platforms capture the context surrounding each interaction, enabling teams to identify patterns in failures, understand model behavior, and respond to quality degradation.
How does AI observability differ from traditional application monitoring? Traditional monitoring tracks infrastructure metrics and application logs. AI observability extends this to capture LLM-specific elements including prompts, model parameters, context retrieval, tool invocations, token usage, and evaluation scores. This additional context is essential for debugging AI agents since failures often stem from these AI-specific layers rather than infrastructure issues.
What should I look for in an AI observability platform? Key considerations include: distributed tracing capabilities, support for your agent framework, automated evaluation and alerting, multi-modal support if needed, integration with existing infrastructure, and whether you need lifecycle management beyond observability.
Can I use traditional observability platforms for AI agents? Traditional platforms like Datadog can monitor infrastructure underlying AI applications, but they lack AI-specific observability capabilities like prompt tracking, token-level analysis, and automated LLM-based evaluation. Specialized AI observability platforms provide deeper insights into agent behavior.
How does Maxim AI differ from other observability platforms?Maxim provides a comprehensive platform that combines experimentation, simulation, evaluation, and observability—enabling teams to move faster across both pre-release development and production monitoring. The platform's focus on cross-functional collaboration allows product and engineering teams to work seamlessly without hand-offs.
What is OpenTelemetry and how does it relate to AI observability? OpenTelemetry is an open standard for collecting observability data. AI observability platforms that support OpenTelemetry compatibility can forward traces to third-party platforms like Datadog, Grafana, or New Relic, enabling unified visibility across traditional and AI observability.
How can I get started with AI observability? Start by assessing your current monitoring infrastructure and team needs. Evaluate platforms based on framework compatibility, ease of integration, and specific features relevant to your use case. Most platforms offer free trials or starter tiers, allowing you to test capabilities before committing to a full deployment.


