Intuitive UI for Prompt Management: Ship AI Faster Without Code Changes

TL;DR
An intuitive prompt management UI anchored to versioning, deployment variables, and integrated evaluators enables safe, measurable, and reversible changes to AI applications in production. With Maxim AI, teams can organize and version prompts, compare quality, cost, and latency across models, run agent simulations, and apply automated observability with distributed tracing and quality checks. This approach reduces risk, accelerates iteration, and drives reliable AI improvements with no code changes.
Introduction
Prompt management has evolved to a disciplined, UI-driven workflow used by engineering and product teams. The goal is straightforward: enable safe iteration, measurable quality improvements, and rapid rollbacks, without deploying new code. Prompt management must support versioning, controlled deployments, evaluator-backed comparison, and observability across the entire lifecycle.
Maxim AI’s full-stack approach pairs no-code prompt controls with simulation, evaluation, and production monitoring so teams ship changes confidently. Explore the advanced prompt engineering workspace in Playground++ for organizing and versioning prompts, compare outputs across models and parameters, and deploy prompt variants safely, then validate with agent simulations and observability.
Why prompt workflows are critical to accelerate AI delivery timelines?
An centralized prompt workflow reduces coordination overhead, avoids risky production edits, and centralizes decision-making based on quantitative signals.
- Product teams iterate prompts safely with versioning and deployment variables in the UI, avoiding code changes or redeployments. See Maxim’s advanced prompt engineering workspace: Prompt engineering, versioning, and deployment in Playground++.
- Quality, cost, and latency comparisons across prompt versions and models help teams select the best trade-offs for production. Explore side-by-side comparisons and controlled experiments: Experimentation product page.
- Integrated evaluators ensure changes are measurable, reproducible, and defensible across test suites. Learn about unified evaluation workflows for machine and human checks: Agent simulation and evaluation.
- Observability closes the loop by tracing production behavior and running periodic quality checks to catch regressions fast. Monitor real-time logs and distributed tracing: Agent observability.
External research highlights why disciplined prompt operations matter. Latency and cost vary widely across models and configurations, and small context changes can shift behavior significantly; robust evaluation and monitoring are necessary for trustworthy AI. See high-level guidance on AI evaluation and monitoring best practices.
Core capabilities for no-code prompt management
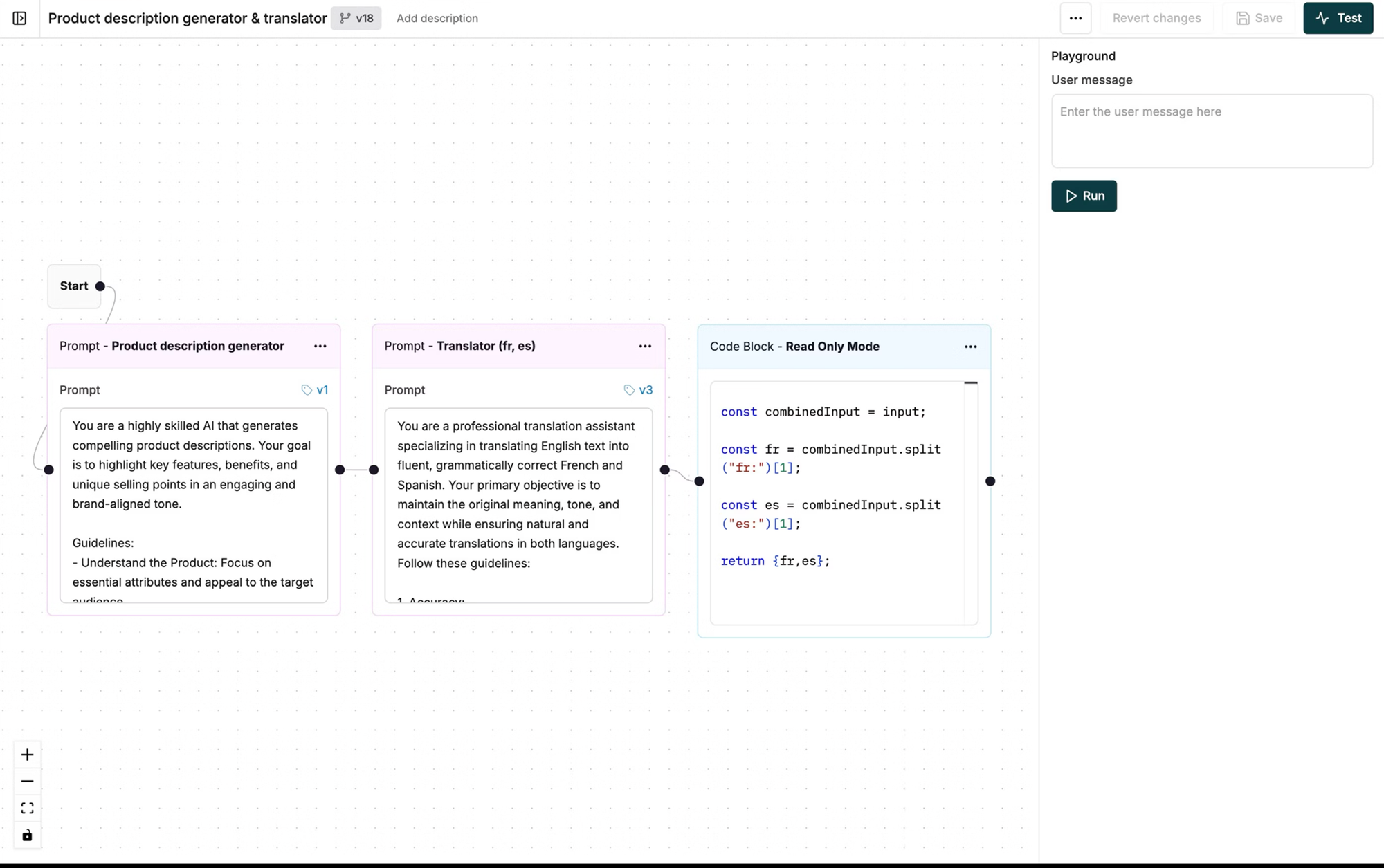
The foundation of an effective prompt UI is a set of capabilities that prioritize safety, speed, and measurable outcomes.
- Prompt organization and versioning: Maintain clear lineage across prompt edits, variants, and deployment states in the UI. Use controlled rollouts and revert on signal. See advanced prompt engineering, versioning, and deployment: Playground++ prompt engineering.
- Deployment variables and strategies: Adjust prompt variables and experiment configurations without code changes. Connect to RAG pipelines and prompt tools seamlessly. Explore deployment flexibility and data connections: Experimentation product page.
- Evaluator-backed comparisons: Quantitatively compare prompts on output quality, cost, and latency across models and parameters. Use statistical and LLM-as-judge evaluators and visualize runs across large test suites. Learn more: Agent simulation and evaluation.
- Integrated simulation: Reproduce issues across conversational trajectories, re-run from any step, assess task completion, and identify failure points. Validate changes before shipping. Details: Agent simulation and evaluation.
- Production observability: Trace live traffic with distributed tracing, run automated quality checks, and curate datasets from logs for future evaluation and fine-tuning. See: Agent observability.
Collaborative workflows for product and engineering teams
Prompt changes require coordination, governance, and shared visibility. The UI should reflect how product and engineering collaborate:
- Shared workspaces and roles: Product teams configure prompt variants and evaluators; engineering integrates SDKs and tracing once, then iterates via UI. See cross-functional workflows across experimentation, simulation, and observability: Experimentation, Agent simulation and evaluation, Observability.
- Custom dashboards: Build insights across agent behavior, quality, and cost using configurable dashboards with a few clicks, enabling PMs to drive lifecycle decisions without blocking on code changes. Explore lifecycle views across products above.
- Human-in-the-loop reviews: Collect human feedback for last-mile quality checks and nuanced assessments when automated evaluators are insufficient. Learn more: Agent simulation and evaluation.
- Data curation: Use production logs to curate multi-modal datasets for evaluation and fine-tuning. See capabilities in Maxim’s Data Engine within observability workflows: Agent observability.
These workflows increase iteration speed while maintaining accountability and auditability. Structured, evaluator-backed decisions outperform ad hoc edits.
Measuring impact: quality, cost, latency, reliability
Data-driven iteration requires consistent metrics and comparative visualization.
- Quality scoring: Use off-the-shelf evaluators or custom ones (deterministic, statistical, LLM-as-a-judge) to quantify changes across test suites. Configure at session, trace, or span levels. Learn more: Agent simulation and evaluation.
- Cost analysis: Compare cost across models, parameters, and prompt variants; apply budget constraints and guardrails via gateway-level policies. See Maxim’s LLM gateway (Bifrost) for governance and usage tracking: Gateway governance and usage tracking.
- Latency tracking: Visualize latency distributions from experiments and production traces; leverage semantic caching and load balancing to reduce tail latency. Explore: Semantic caching and Load balancing & fallbacks.
- Reliability safeguards: Apply automatic fallbacks across providers and models to reduce downtime during prompt or model changes. See: Automatic fallbacks.
Empirical studies show that operational controls like caching and fallbacks can materially reduce latency variance and error rates, improving user experience. Governance and observability further ensure changes do not degrade service quality.
Applying simulation and evaluation before production
Pre-release validation reduces production risk. Teams run scenario-based simulations, test agent trajectories, and apply evaluators before pushing changes.
- Scenario coverage: Simulate customer interactions across real-world personas; assess task completion and identify failure points. See: Agent simulation and evaluation.
- Reproducibility: Re-run simulations from any step to isolate root causes and verify fixes before deployment. Same link as above.
- Evaluator suites: Combine statistical, programmatic, and LLM-as-judge evaluators to capture both objective metrics and qualitative alignment. Same link as above.
- Visualization: Review evaluation runs across large test suites to quantify improvements and regressions; use dashboards for cross-version comparison. See: Experimentation.
This pre-release discipline mirrors best practices in software quality and reliability engineering, adapted to AI systems.
Observability and continuous improvement in production
Post-deployment, production observability validates hypotheses and finds edge cases.
- Real-time alerts: Track and resolve live quality issues with minimal user impact by setting automated rules and alerts. See: Agent observability.
- Distributed tracing: Analyze multi-agent workflows with span-level insights and correlate prompt versions with downstream behavior. Same link as above.
- Periodic quality checks: Run automated evaluations on production logs to catch drift or regressions; store results for audits and continuous improvement. Same link as above.
- Dataset curation: Convert production logs into curated datasets for future evaluation and fine-tuning, closing the loop between ops and experimentation. Same link as above.
Continuous monitoring is a pillar of trustworthy AI. External guidance emphasizes the need for ongoing checks and traceability to maintain performance and compliance.
Conclusion
Intuitive prompt UI empowers product teams to drive measurable AI improvements without code changes. Versioning, deployment variables, evaluator-backed comparisons, simulation, and robust observability form a cohesive lifecycle that reduces risk and accelerates iteration. With Maxim AI’s Playground++ for prompt engineering, agent simulation and evaluation, and production observability, plus the Bifrost gateway for governance and reliability, organizations ship AI changes faster while maintaining quality, cost, latency, and trust. Explore the stack to enable safe, data-driven prompt operations across teams: Experimentation, Agent simulation and evaluation, and Agent observability.


