How to Streamline Prompt Management and Collaboration for AI Agents Using Observability and Evaluation Tools

TL;DR
Managing prompts for AI agents requires structured workflows that enable version control, systematic evaluation, and cross-functional collaboration. Observability tools track agent behavior in production, while evaluation frameworks measure quality improvements across iterations. By implementing prompt management systems with Maxim’s automated evaluations, distributed tracing, and data curation capabilities, teams can increase shipping velocity by over 5x while maintaining consistent quality standards. This approach combines experimentation platforms, simulation environments, and production monitoring to create a unified lifecycle for prompt optimization.
The Challenge of Prompt Management in Multi-Agent Systems
Building reliable AI agents demands rigorous control over prompts that guide model behavior. As applications scale, engineering teams face three core challenges:
- maintaining consistency across prompt versions,
- measuring quality improvements quantitatively,
- and enabling product managers to contribute without creating engineering dependencies.
Traditional approaches to prompt management create bottlenecks. Engineers store prompts in code repositories, making iterations slow and limiting visibility for non-technical stakeholders. Without systematic evaluation, teams struggle to quantify whether changes improve or degrade performance. Production issues become difficult to trace back to specific prompt modifications.
Maxim AI addresses these challenges through an end-to-end platform that unifies experimentation, evaluation, and observability. The platform enables teams to organize prompts with version control, deploy changes through configuration rather than code updates, and measure quality through automated evaluations at multiple levels of granularity.
Why Prompt Management Requires Specialized Infrastructure
AI applications differ fundamentally from traditional software. Prompts act as the primary interface between human intent and model behavior, but their effects on output quality are probabilistic rather than deterministic. A prompt change that improves performance on one class of inputs may degrade it on another.
This uncertainty demands infrastructure that makes prompt behavior observable and measurable. Teams need to compare outputs across prompt versions, track which prompts are active in production, and quickly roll back changes that cause quality regressions. Without these capabilities, prompt engineering becomes ad-hoc experimentation rather than systematic optimization.
Maxim’s experimentation platform provides a Playground++ environment built for advanced prompt engineering, enabling rapid iteration cycles. Users can organize and version prompts directly from the UI, deploy them with different variables and experimentation strategies without code changes, and connect seamlessly with databases and RAG pipelines.
Establishing Collaborative Workflows Through Centralized Prompt Management

Effective prompt management starts with centralized storage that gives both technical and non-technical team members appropriate access. Maxim's prompt management system allows users to organize and version prompts directly from the UI for iterative improvement, creating a single source of truth that eliminates version conflicts.
Version Control and Deployment Strategies
Prompt versioning extends beyond simple storage. Each version needs metadata capturing the intent behind changes, evaluation results, and deployment status. Teams can deploy prompts with different deployment variables and experimentation strategies without code changes, enabling A/B testing and gradual rollouts that minimize risk.
Deployment variables allow prompts to adapt based on context without creating separate versions. A customer support agent might use different temperature settings for technical queries versus general questions, all controlled through configuration. This flexibility reduces the number of prompt variants teams need to manage while maintaining appropriate behavior across scenarios.
The prompt deployment documentation outlines how teams can implement progressive rollouts, automatically reverting to previous versions if evaluation metrics fall below thresholds. This automated safety mechanism prevents quality regressions from reaching users.
Enabling Cross-Functional Collaboration
Product managers need visibility into how prompt changes affect user experience, but traditional code-based approaches exclude them from the workflow. The entire experience for evaluations is anchored to how product teams can drive AI lifecycle without code, removing core engineering dependencies.
This approach accelerates iteration cycles. Product managers can propose prompt modifications, configure evaluations to test them against historical data, and review results without waiting for engineering resources. Engineers maintain control over production deployments while benefiting from reduced backlog of prompt modification requests.
Prompt partials further enhance collaboration by allowing teams to compose reusable prompt components. Common instructions or formatting requirements become modules that multiple prompts reference, ensuring consistency and simplifying updates.
Implementing Systematic Evaluation Frameworks for Quality Measurement
Observability without evaluation provides visibility but not understanding. Teams need quantitative metrics that indicate whether prompt changes improve agent performance. The unified framework for machine and human evaluations allows teams to quantify improvements or regressions and deploy with confidence.
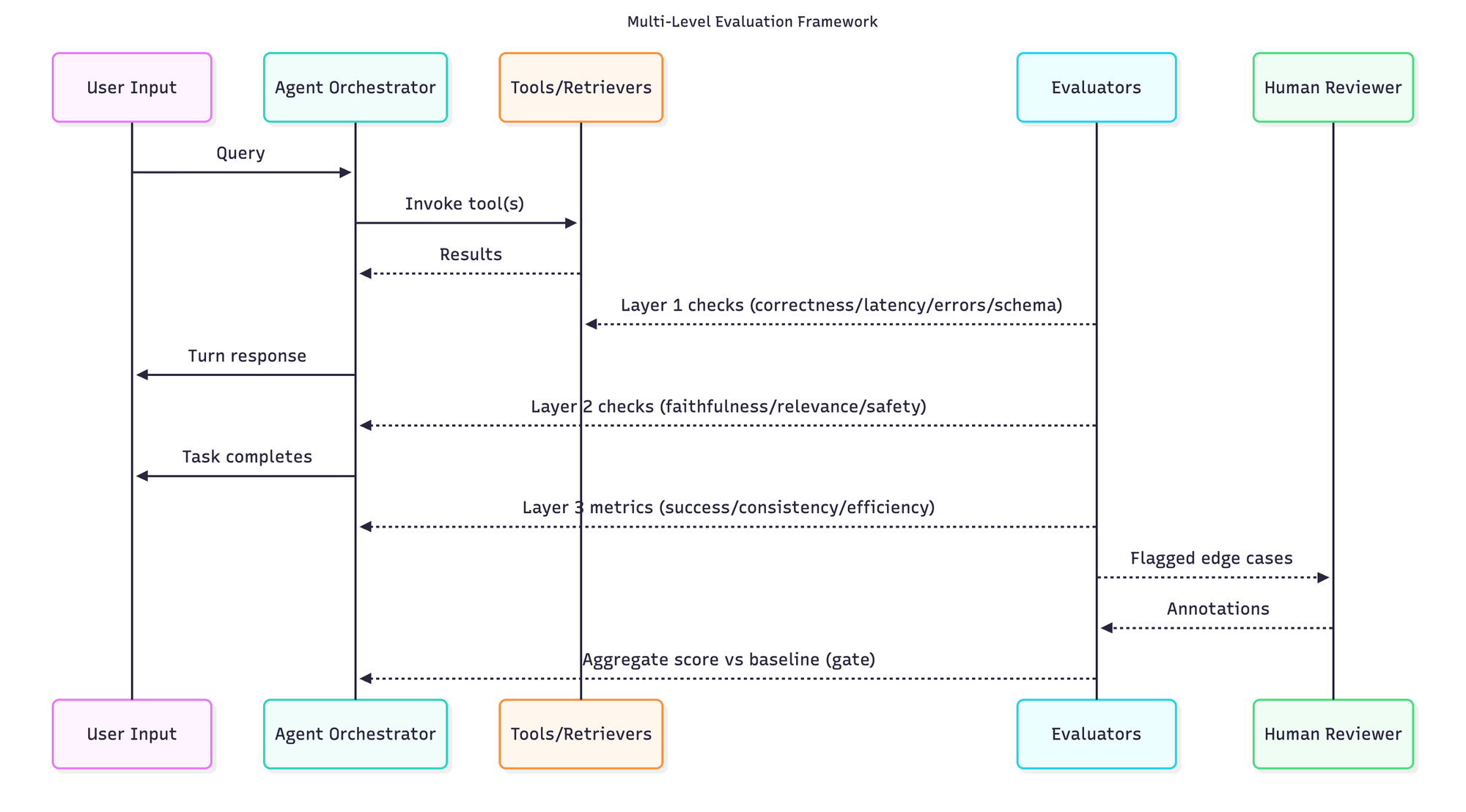
Configuring Multi-Level Evaluations
AI agents operate at multiple levels of granularity. A single user query might trigger multiple LLM calls, tool invocations, and retrieval operations. Evaluation frameworks must measure quality at each level to identify specific failure points.
Flexi evals allow teams to configure evaluations with fine-grained flexibility, running evaluations at any level of granularity for multi-agent systems. This capability enables evaluation of individual tool calls, complete conversation turns, and overall task success within a single framework.
The evaluator library provides pre-built metrics for common quality dimensions. Faithfulness evaluators measure whether responses remain grounded in retrieved context. Context relevance metrics assess whether retrieval systems surface appropriate information. Task success evaluators determine whether agents complete user objectives.
Combining Automated and Human Evaluation
Automated metrics provide scalability but miss nuanced quality dimensions that humans readily perceive. Custom evaluators allow teams to encode domain-specific quality criteria, while human annotation captures subjective judgments about appropriateness, tone, and helpfulness.
The platform supports hybrid evaluation strategies. Automated evaluators screen large volumes of outputs, flagging edge cases for human review. This approach balances comprehensive coverage with deep quality assessment. Human plus LLM-in-the-loop evaluations ensure teams continue to align agents to human preferences.
Statistical evaluators complement AI-based assessment. F1 scores and precision metrics measure information extraction accuracy. BLEU scores quantify translation quality. Semantic similarity measures compare outputs against golden references.
Leveraging Observability for Production Monitoring and Debugging
Evaluation on test datasets reveals how prompts perform on known scenarios, but production behavior often differs. The observability suite empowers teams to monitor real-time production logs and run periodic quality checks to ensure reliability.
Distributed Tracing for Multi-Step Agent Workflows
Modern AI applications rarely consist of single LLM calls. Agents orchestrate multiple operations across retrievers, tools, and model invocations. Distributed tracing captures the complete execution path, showing how each component contributes to the final output.
Teams can create multiple repositories for multiple apps, logging and analyzing production data using distributed tracing. This structure supports organizations running multiple agent applications, each with distinct logging requirements and access controls.
Continuous Quality Monitoring and Alerting
Production monitoring requires automated quality assessment. In-production quality can be measured using automated evaluations based on custom rules, applying the same evaluation framework used during development to live traffic.
Automated evaluation on logs runs evaluators on production data, detecting quality regressions as they occur. Teams configure evaluation schedules, sampling rates, and alert thresholds. When metrics fall below acceptable levels, alerts and notifications trigger immediate investigation.
The observability dashboard provides real-time visibility into agent behavior. Teams can track, debug, and resolve live quality issues with real-time alerts to minimize user impact. Custom dashboards give teams control to create insights across custom dimensions with minimal configuration.
Integrating Simulation Environments for Pre-Deployment Testing
Testing AI agents against static datasets reveals limited failure modes. Real-world usage introduces edge cases that synthetic test data rarely captures. AI-powered simulations test and improve agents across hundreds of scenarios and user personas, measuring quality using various metrics.
Scenario-Based Testing and Persona Simulation
Traditional software testing uses deterministic inputs and expected outputs. AI agent testing requires simulating dynamic conversations where user behavior adapts based on agent responses. Teams can simulate customer interactions across real-world scenarios and user personas, monitoring how agents respond at every step.
The simulation framework generates synthetic users with defined characteristics and goals. A customer support simulation might include frustrated users seeking refunds, technical users requiring detailed troubleshooting, and casual users exploring product features. Each persona challenges the agent differently, revealing failure modes specific to user types.
Simulation runs execute these scenarios at scale, creating hundreds of conversation trajectories. Teams evaluate agents at conversational level, analyzing trajectory choices, assessing task completion success, and identifying failure points.
Iterative Debugging Through Simulation Replay
Production debugging in AI systems poses challenges. Users rarely report complete conversation context, and reproducing issues requires understanding the exact sequence of agent decisions. Teams can re-run simulations from any step to reproduce issues, identify root causes, and apply learnings to debug and improve performance.
This replay capability accelerates root cause analysis. Engineers identify where agent behavior diverged from optimal trajectories, test prompt modifications against the specific failure case, and verify fixes before production deployment. The voice simulation capabilities extend this approach to voice-based interactions, where prosody and speech patterns introduce additional complexity.
Building Sustainable Data Management Practices for Continuous Improvement
Prompt optimization requires high-quality datasets that evolve with application requirements. Synthetic data generation and data curation workflows help teams curate high-quality, multi-modal datasets and continuously evolve them using logs, evaluation data, and human-in-the-loop workflows.
Curating Datasets from Production Logs
Production data provides realistic test cases that synthetic generation struggles to replicate. Datasets can be curated with ease for evaluation and fine-tuning needs, extracting valuable examples from logged interactions.
The dataset curation documentation outlines workflows for filtering logs based on evaluation scores, user feedback, and conversation patterns. Teams identify high-performing interactions to establish quality benchmarks and problematic cases requiring targeted improvements.
Dataset import capabilities support multiple formats and sources. Teams can import existing test suites, combine datasets from different applications, and create stratified samples ensuring broad scenario coverage. Dataset management features include versioning, access controls, and organization by project or use case.
Enriching Data Through Human Feedback
Automated evaluation provides scalability, but human judgment remains essential for nuanced quality assessment. Teams can enrich data using in-house or Maxim-managed data labeling and feedback, capturing expert annotations that improve both evaluation accuracy and model behavior.
Human annotation workflows integrate directly with production monitoring. Reviewers assess outputs based on custom rubrics, flagging issues for engineering investigation. These annotations feed back into evaluation datasets, creating a continuous improvement loop where production learnings enhance pre-deployment testing.
Conclusion
Streamlining prompt management and collaboration requires integrated infrastructure spanning experimentation, evaluation, simulation, and production monitoring. Teams that implement systematic workflows for prompt versioning, automated quality measurement, and cross-functional collaboration reduce deployment cycles significantly while maintaining consistent quality standards.
The combination of centralized prompt management, multi-level evaluation frameworks, distributed tracing for production monitoring, and simulation environments for pre-deployment testing creates a comprehensive approach to AI agent development. Organizations adopting these practices report faster iteration cycles, fewer production incidents, and improved collaboration between engineering and product teams.
Success in AI agent development depends on treating prompts requiring rigorous engineering practices. Version control, systematic evaluation, and production observability transform prompt engineering from ad-hoc experimentation into disciplined optimization. As AI applications grow in complexity, these practices become essential for maintaining reliability at scale.
Ready to implement systematic prompt management for your AI agents? Schedule a demo to see how Maxim's unified platform accelerates development cycles while ensuring production quality, or sign up to start optimizing your agent workflows today.


