How to Evaluate Prompts with Maxim AI

TLDR
Prompt evaluation is essential for ensuring AI application reliability and performance. Maxim AI provides a comprehensive framework for evaluating prompts through automated evaluators, human-in-the-loop workflows, and detailed analytics. This guide covers the fundamentals of prompt evaluation, key metrics to track, and step-by-step instructions for implementing effective evaluation workflows using Maxim's experimentation, evaluation, and observability tools.
Table of Contents
- What is Prompt Evaluation?
- Why Prompt Evaluation Matters
- Key Metrics for Prompt Evaluation
- How to Evaluate Prompts with Maxim AI
- Best Practices for Prompt Evaluation
- Common Challenges and Solutions
- Further Reading
What is Prompt Evaluation?
Prompt evaluation refers to the systematic process of assessing how well a prompt guides a large language model to produce desired outputs. According to research on LLM evaluation frameworks, prompt testing has become critically important for ensuring quality, reliability, and accuracy of AI applications across different use cases.
Unlike traditional software testing, prompt evaluation addresses unique challenges posed by the non-deterministic nature of LLM outputs. A single prompt modification can significantly impact model responses, making systematic evaluation essential for production deployments.

Core Components of Prompt Evaluation
Effective prompt evaluation encompasses three primary components:
- Input Design: Structuring prompts with clear instructions, context, and constraints
- Output Analysis: Measuring response quality against predefined criteria
- Iterative Refinement: Systematically improving prompts based on evaluation results
Why Prompt Evaluation Matters
Prompt evaluation directly impacts the reliability and performance of AI applications in production. Research from Datadog's evaluation framework guide emphasizes that without proper evaluation, organizations risk deploying applications with inconsistent outputs, factual inaccuracies, or responses that fail to meet user expectations.
Business Impact
| Risk Category | Impact Without Evaluation | Mitigation Through Evaluation |
|---|---|---|
| Accuracy | Factual errors and hallucinations | Systematic quality checks |
| Consistency | Variable responses to similar inputs | Performance benchmarking |
| Cost Efficiency | Unnecessary token usage | Optimized prompt design |
| User Experience | Irrelevant or inappropriate outputs | Continuous monitoring |
Production Reliability
For teams building AI agents and applications, prompt evaluation ensures:
- Quality Assurance: Catch issues before they reach end users
- Performance Optimization: Identify opportunities to reduce latency and costs
- Compliance: Verify outputs adhere to brand guidelines and safety policies
- Scalability: Maintain consistent performance as applications grow
Organizations using Maxim's evaluation framework report 5x faster deployment cycles due to systematic prompt testing and validation.
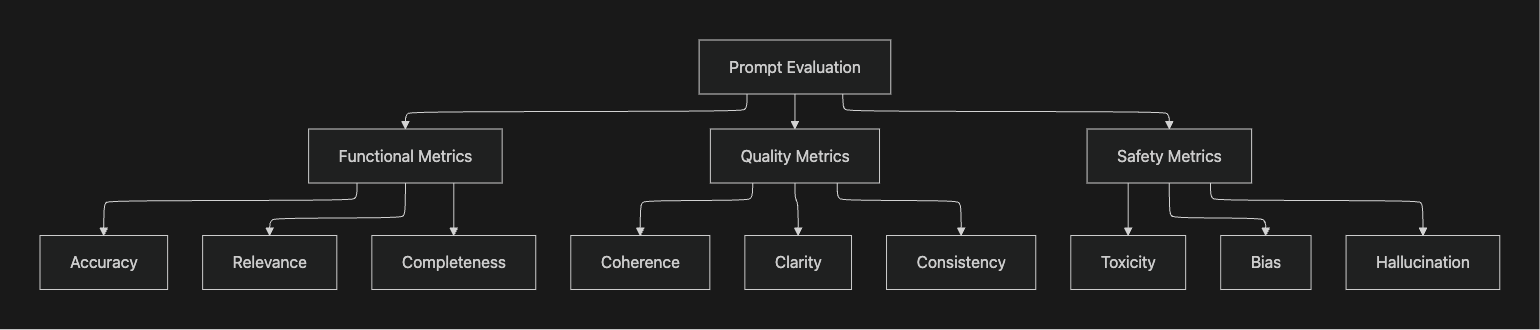
Key Metrics for Prompt Evaluation
Based on industry best practices, prompt evaluation should measure multiple dimensions of output quality:
Functional Metrics
Accuracy: Measures factual correctness of model outputs against ground truth data. This metric is essential for applications where precise information delivery is critical, such as customer support or technical documentation.
Relevance: Evaluates whether responses directly address the user's query without extraneous information. Topic relevancy assessments ensure outputs remain within defined domain boundaries.
Completeness: Assesses whether responses provide comprehensive answers to complex queries, including all necessary details and context.
Quality Metrics
Coherence: Measures logical flow and consistency within generated text. Incoherent outputs can confuse users and degrade application quality.
Clarity: Evaluates how easily users can understand the response, considering factors like sentence structure, terminology, and organization.
Consistency: Tracks whether similar inputs produce appropriately similar outputs across multiple evaluation runs.
Safety Metrics
Toxicity: Identifies harmful, offensive, or inappropriate content in model outputs using specialized detection models.
Bias: Measures potential biases in responses across demographic dimensions to ensure fair and equitable treatment.
Hallucination Detection: Identifies instances where models generate plausible but factually incorrect information.
How to Evaluate Prompts with Maxim AI
Maxim AI provides an end-to-end platform for prompt evaluation spanning experimentation, simulation, and production monitoring. Here's how to implement effective prompt evaluation workflows:
Step 1: Prompt Experimentation
Start with Maxim's Playground++ to iterate on prompt design:
- Version Control: Organize and version prompts directly from the UI for systematic iteration
- Parameter Testing: Compare output quality across different models, temperatures, and parameters
- Deployment Variables: Test prompts with various deployment configurations without code changes
- Cost Analysis: Evaluate trade-offs between quality, latency, and cost for different configurations
Step 2: Dataset Curation
Build high-quality evaluation datasets using Maxim's Data Engine:
- Import multi-modal datasets including text and images
- Curate test cases from production logs and edge cases
- Enrich datasets through human-in-the-loop labeling
- Create data splits for targeted evaluations
According to prompt testing best practices, domain-specific datasets provide the most accurate evaluation results for production applications.
Step 3: Configure Evaluators
Maxim offers flexible evaluator configurations at session, trace, or span levels:
Automated Evaluators
| Evaluator Type | Use Case | Implementation |
|---|---|---|
| LLM-as-a-Judge | Complex quality assessments | Custom criteria with GPT-4 or Claude |
| Deterministic | Rule-based checks | Keyword matching, format validation |
| Statistical | Similarity metrics | ROUGE, BLEU, semantic similarity |
Access pre-built evaluators through the evaluator store or create custom evaluators suited to specific application needs.
Human Evaluations
For nuanced assessments requiring domain expertise:
- Define custom evaluation rubrics
- Distribute evaluation tasks across team members
- Collect structured feedback on output quality
- Aggregate results for comprehensive analysis
Step 4: Run Evaluations
Execute systematic evaluations across test suites:
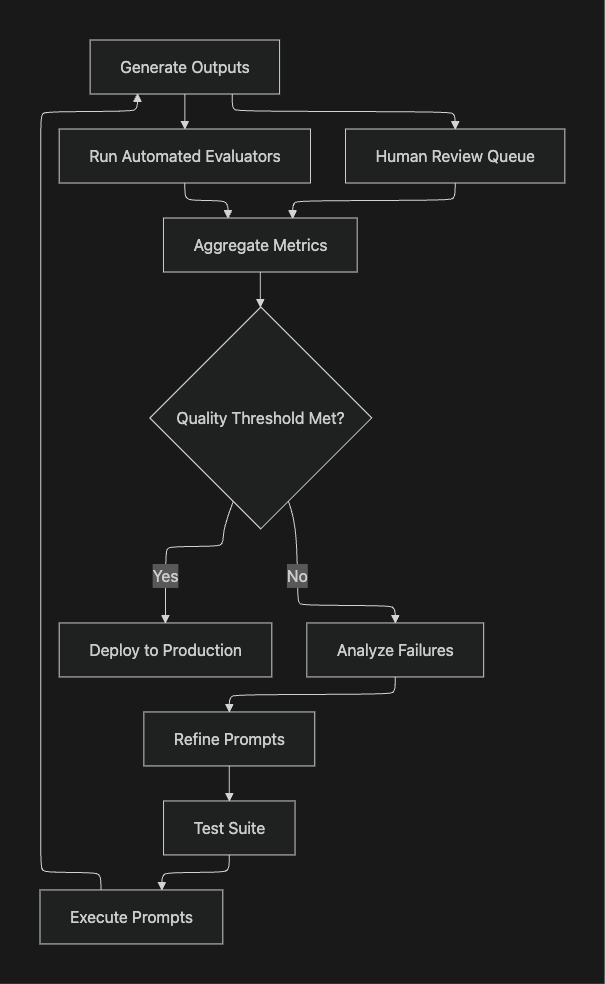
Maxim's evaluation framework enables:
- Batch evaluation across hundreds of test cases
- Parallel execution for faster feedback cycles
- Detailed failure analysis with root cause identification
- Comparative analysis across prompt versions
Step 5: Simulation Testing
Use AI-powered simulations to test prompts across realistic scenarios:
- Generate synthetic conversations with diverse user personas
- Evaluate multi-turn interactions and agent trajectories
- Identify failure points in complex workflows
- Re-run simulations from specific steps for debugging
Step 6: Production Monitoring
Deploy prompts with confidence using Maxim's observability suite:
- Track real-time quality metrics in production
- Set up automated alerts for quality degradation
- Run periodic evaluations on production logs
- Create feedback loops for continuous improvement
Key Observability Features:
- Distributed tracing for multi-step agent workflows
- Custom dashboards for cross-functional insights
- Automated evaluation pipelines
- Integration with incident management systems
Best Practices for Prompt Evaluation
1. Start with Clear Objectives
Define specific goals before evaluating prompts. Vague evaluation criteria lead to inconsistent results and wasted effort. Research on prompt engineering shows that well-defined objectives improve evaluation consistency by 70%.
2. Build Representative Test Sets
Create evaluation datasets that reflect real-world usage patterns:
- Include edge cases and challenging scenarios
- Balance common queries with uncommon requests
- Incorporate diverse user personas and contexts
- Regularly update test sets based on production insights
3. Combine Evaluation Methods
Use multiple evaluation approaches for comprehensive assessment:
- Automated evaluators for scale and consistency
- Human review for nuanced judgment
- Rule-based checks for deterministic requirements
- Statistical metrics for quantitative benchmarking
According to LLM-as-a-judge best practices, combining methods provides more reliable evaluation than any single approach.
4. Implement Version Control
Track prompt changes systematically:
- Version every prompt modification
- Document rationale for changes
- Maintain evaluation history across versions
- Enable rollback to previous versions if needed
5. Establish Quality Thresholds
Define clear success criteria for production deployment:
- Set minimum acceptable scores for each metric
- Require consistency across multiple evaluation runs
- Implement staged rollout for new prompt versions
- Monitor quality trends over time
6. Iterate Based on Data
Use evaluation results to drive systematic improvement:
- Analyze failure patterns to identify root causes
- A/B test prompt variations in production
- Incorporate user feedback into evaluation criteria
- Continuously refine evaluation methodologies
Common Challenges and Solutions
Challenge 1: Non-Deterministic Outputs
Problem: LLMs produce variable outputs for identical inputs, making evaluation difficult.
Solution: Run multiple evaluations with different temperature settings and aggregate results. Maxim's evaluation framework supports batch testing with configurable parameters to account for output variance.
Challenge 2: Subjective Quality Criteria
Problem: Metrics like "helpfulness" or "tone" lack objective measurement standards.
Solution: Implement LLM-as-a-judge evaluators with detailed rubrics. Maxim enables teams to define custom evaluation criteria with example responses for consistent assessment.
Challenge 3: Scale and Speed
Problem: Manual evaluation doesn't scale for large test suites or high-velocity development.
Solution: Leverage automated evaluators for systematic testing while reserving human review for edge cases. Maxim's parallel execution capabilities enable evaluation of thousands of test cases in minutes.
Challenge 4: Production-Development Gap
Problem: Prompts perform well in testing but fail in production due to distribution shift.
Solution: Use Maxim's simulation capabilities to test against diverse user personas and scenarios. Continuously monitor production performance and feed real-world data back into evaluation datasets.
Challenge 5: Cross-Functional Collaboration
Problem: Engineering and product teams struggle to align on evaluation criteria and quality standards.
Solution: Maxim's platform enables seamless collaboration through shared dashboards, accessible evaluation interfaces, and unified metrics. Product managers can configure evaluations without code, while engineers maintain full SDK control.
Further Reading
Internal Resources
- Maxim AI Experimentation Product Page
- Agent Simulation and Evaluation Guide
- Observability Best Practices
- Maxim AI Documentation
- Prompt Management for AI Applications: Versioning, Testing, and Deployment with Maxim AI
- Prompt Evaluation Frameworks: Measuring Quality, Consistency, and Cost at Scale
External Resources
- Building an LLM Evaluation Framework - Production evaluation strategies
- Prompt Engineering Best Practices - Systematic prompt optimization
Start Evaluating Your Prompts Today
Effective prompt evaluation is essential for building reliable AI applications. Maxim AI provides the complete infrastructure teams need to experiment, evaluate, and monitor prompts from development through production.
Ready to improve your prompt quality and deploy with confidence? Book a demo to see how Maxim AI can accelerate your AI development workflow, or sign up to start evaluating prompts today.


