5 Tools to Evaluate Prompt Retrieval Quality: The RAG Reliability Stack

TL;DR
- RAG systems require specialized evaluation beyond traditional LLM testing to ensure retrieval accuracy and generation quality
- Five essential platforms provide comprehensive RAG evaluation capabilities: Maxim AI, PromptLayer, LangSmith, Promptfoo, and RAGAS
- Maxim AI offers end-to-end evaluation with agent simulation, multi-modal support, and cross-functional collaboration features
- Component-level testing is critical for isolating retrieval failures from generation issues
Table of Contents
- Why RAG Retrieval Quality Matters
- The RAG Evaluation Challenge
- Tool 1: Maxim AI - Full-Stack RAG Evaluation Platform
- Tool 2: PromptLayer - RAG Pipeline Testing
- Tool 3: LangSmith - LangChain-Native Evaluation
- Tool 4: Promptfoo - Security-First RAG Testing
- Tool 5: RAGAS - Reference-Free Metrics Framework
- Platform Comparison
- Choosing the Right Evaluation Tool
- Further Reading
Why RAG Retrieval Quality Matters
Retrieval-Augmented Generation systems combine LLM capabilities with external knowledge retrieval, enabling applications to provide factually grounded responses. However, research demonstrates that perfect retrieval does not guarantee accurate outputs, introducing evaluation complexities that standard LLM testing cannot address.
Key RAG Quality Challenges
- Retrieval accuracy: Systems must identify and rank relevant documents correctly
- Context utilization: LLMs must effectively use retrieved information without hallucination
- Faithfulness: Generated responses must remain grounded in source material
- Noise interference: Irrelevant information can degrade output quality even with correct retrieval
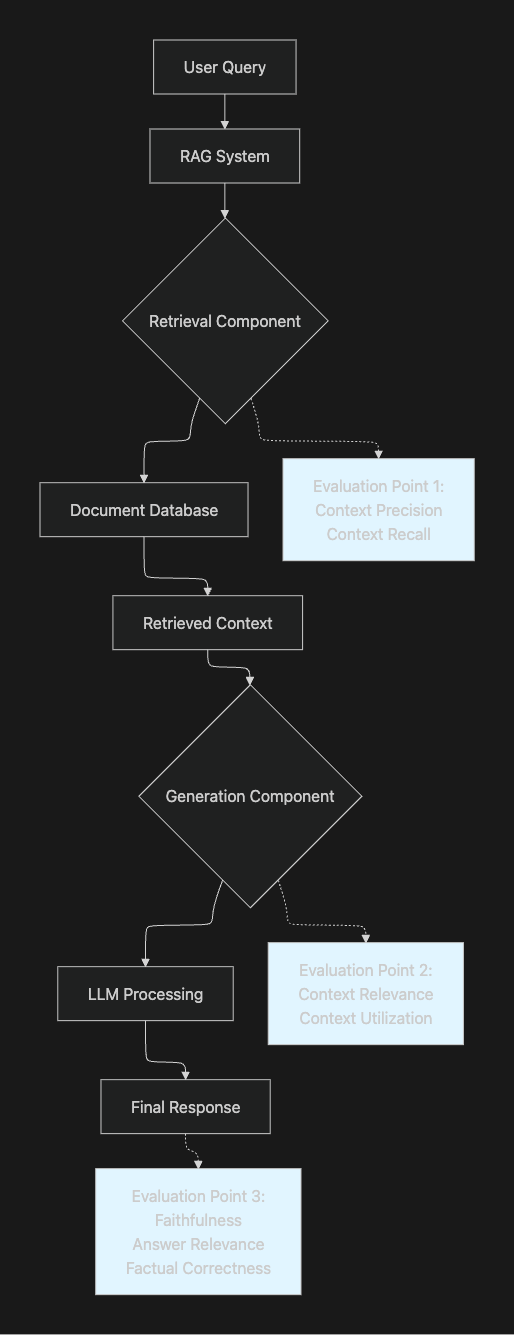
The RAG Evaluation Challenge
Traditional LLM evaluation approaches fail to capture RAG-specific failure modes. Effective RAG evaluation requires:
Component Separation
- Isolate retrieval performance from generation quality
- Test each stage independently before end-to-end evaluation
- Identify whether failures originate from document selection or LLM processing
Multi-Dimensional Metrics
- Context precision and recall for retrieval quality
- Faithfulness and groundedness for generation accuracy
- Answer relevance and completeness for end-to-end performance
Reference-Free Evaluation
- Manual ground truth creation is expensive and time-consuming
- LLM-as-judge approaches enable automated evaluation without human-annotated datasets
- Synthetic test generation scales evaluation across diverse scenarios
Tool 1: Maxim AI - Full-Stack RAG Evaluation Platform
Platform Overview
Maxim AI provides an end-to-end evaluation and observability platform specifically designed for agentic AI applications and RAG systems. The platform integrates experimentation, simulation, evaluation, and production monitoring into a unified workflow, enabling teams to ship reliable AI applications 5x faster.
Key Features
Agent Simulation & Evaluation
- AI-powered simulations test agents across hundreds of real-world scenarios and user personas
- Conversational-level evaluation analyzes agent trajectory, task completion, and failure points
- Re-run simulations from any step to reproduce issues and identify root causes
Multi-Modal RAG Support
- Native support for text, image, audio, and video retrieval evaluation
- Data Engine enables seamless import and curation of multi-modal datasets
- Continuous dataset evolution using production logs and human-in-the-loop workflows
Flexible Evaluation Framework
- Configure evaluations at session, trace, or span level for multi-agent systems
- Custom evaluators: deterministic, statistical, and LLM-as-judge
- Pre-built evaluators from the evaluator store for common RAG metrics
- Human evaluation workflows for nuanced quality assessment
Experimentation & Iteration
- Playground++ for rapid prompt engineering and deployment
- Version control for prompts with deployment variables
- Compare output quality, cost, and latency across prompt/model combinations
Production Observability
- Real-time monitoring with distributed tracing for live applications
- Automated quality checks on production logs using custom rules
- Alert systems for proactive issue resolution with minimal user impact
- Multiple repositories for organizing production data across applications
Cross-Functional Collaboration
- No-code UI enables product teams to configure evaluations without engineering dependency
- Custom dashboards provide insights across agent behavior and custom dimensions
- Shared evaluation runs and datasets facilitate team alignment
Bifrost AI Gateway Integration
- Unified interface for 12+ LLM providers through single API
- Automatic fallbacks and load balancing for production resilience
- Semantic caching reduces costs and latency
- Model Context Protocol (MCP) support for tool-enabled AI agents
Best For
- Cross-functional AI teams requiring collaboration between engineering and product
- Multi-modal applications beyond text-only RAG systems
- Agentic workflows with complex multi-step reasoning and tool use
- Production-first organizations needing comprehensive lifecycle management from experimentation to monitoring
- Teams requiring custom evaluation logic tailored to specific business metrics
Maxim's Differentiators
1. Full-Stack Lifecycle Approach
- Unlike point solutions focused solely on observability or testing, Maxim provides integrated pre-release experimentation, evaluation, simulation, and production monitoring
- Teams avoid tool-switching overhead and data silos across development stages
2. Product-Engineering Collaboration
- Flexi evals enable non-technical teams to configure complex evaluations through UI
- Custom dashboards democratize insights without requiring SQL or programming knowledge
- Shared workflows reduce engineering bottlenecks in AI quality processes
3. Multi-Modal Agent Support
- Native evaluation capabilities for text, image, audio, and video retrievals
- Specialized metrics for assessing multi-step agent interactions
- Tools for debugging conversational trajectories and task completion
4. Data Curation at Core
- Synthetic data generation for diverse test scenario coverage
- Human review collection and annotation workflows
- Continuous dataset enrichment from production feedback
Tool 2: PromptLayer - RAG Pipeline Testing
Platform Overview
PromptLayer offers prompt management and evaluation capabilities with support for RAG pipeline testing, focusing on systematic evaluation of retrieval quality and model performance across different configurations.
Key Features
- Batch evaluation pipelines for testing prompts across multiple models
- Visual diff tools for comparing outputs between model versions
- Support for different retrieval thresholds and document quantities
- Integration with perplexity-based evaluation metrics
Best For
- Teams migrating between LLM providers
- Organizations needing batch model comparison capabilities
- Use cases requiring systematic prompt iteration tracking
Tool 3: LangSmith - LangChain-Native Evaluation
Platform Overview
LangSmith provides observability and evaluation specifically designed for applications built on the LangChain ecosystem, with deep integration into LangChain's expression language and retrieval abstractions.
Key Features
- Detailed trace visualization showing document retrieval, context assembly, and generation steps
- Built-in evaluators for common RAG metrics (context recall, faithfulness, answer relevance)
- Custom LLM-as-judge prompts for defining evaluation criteria in natural language
- Dataset creation from production traces for continuous evaluation
- Integration with RAGAS metrics for comprehensive RAG assessment
Best For
- LangChain-exclusive development teams
- Applications requiring detailed observability into nested execution steps
- Teams prioritizing trace-based debugging over systematic quality improvement
Limitations
- Strong coupling to LangChain framework creates friction for non-LangChain projects
- Observability-first design with limited CI/CD integration for quality gates
- Evaluation infrastructure less comprehensive than full-stack platforms
Tool 4: Promptfoo - Security-First RAG Testing
Platform Overview
Promptfoo is an open-source CLI and library focused on test-driven LLM development, with specialized capabilities for RAG application security testing and red teaming.
Key Features
- Declarative YAML configuration for defining test cases and assertions
- RAG-specific metrics: factuality, context adherence, context recall, answer relevance
- Separate evaluation of retrieval and generation components
- Red teaming capabilities for testing prompt injection, context manipulation, and data poisoning
- Matrix testing across prompts, models, and test cases
- Local execution with privacy-preserving evaluation
Best For
- Security-conscious organizations testing RAG vulnerabilities
- Teams requiring lightweight, code-centric evaluation workflows
- Applications needing systematic regression testing in CI/CD pipelines
- Organizations prioritizing local, privacy-preserving evaluation
Tool 5: RAGAS - Reference-Free Metrics Framework

Platform Overview
RAGAS (Retrieval Augmented Generation Assessment) is an open-source framework providing reference-free evaluation metrics specifically designed for RAG pipelines, eliminating the need for ground-truth human annotations.
Key Features
- Component-Level Metrics
- Context precision: Signal-to-noise ratio of retrieved content
- Context recall: Completeness of relevant information retrieval
- Faithfulness: Factual consistency between generated answers and context
- Answer relevancy: Pertinence of responses to user queries
- Synthetic test data generation for rapid evaluation setup
- LLM-as-judge evaluation leveraging GPT-4 or other models as evaluators
- Integration with LangSmith, Langfuse, and other observability platforms
- Customizable metric definitions for domain-specific requirements
Best For
- Research teams requiring transparent, reproducible metrics
- Organizations without resources for manual ground truth annotation
- Projects needing quick RAG quality baseline establishment
- Teams requiring framework-agnostic evaluation tools
Platform Comparison
| Feature | Maxim AI | PromptLayer | LangSmith | Promptfoo | RAGAS |
|---|---|---|---|---|---|
| Agent Simulation | ✅ Advanced | ❌ | ❌ | ❌ | ❌ |
| Multi-Modal Support | ✅ Native | ⚠️ Limited | ⚠️ Limited | ❌ | ❌ |
| Production Observability | ✅ Full tracing | ⚠️ Basic | ✅ Detailed | ❌ | ❌ |
| Custom Evaluators | ✅ Flexible (deterministic, statistical, LLM) | ⚠️ Limited | ✅ LLM-as-judge | ✅ Custom assertions | ✅ Custom metrics |
| No-Code UI | ✅ Product-friendly | ⚠️ Basic | ⚠️ Trace viewer | ❌ CLI-focused | ❌ Code-based |
| Framework Dependency | ❌ Framework-agnostic | ❌ Framework-agnostic | ⚠️ LangChain-coupled | ❌ Framework-agnostic | ❌ Framework-agnostic |
| Red Team Testing | ✅ Security evaluation | ❌ | ❌ | ✅ Specialized | ❌ |
| Deployment | ☁️ Managed + Self-hosted | ☁️ Cloud | ☁️ Cloud | 🏠 Local | 🏠 Local |
| Best For | Full-stack AI lifecycle | Prompt iteration | LangChain apps | Security testing | Metrics research |
Choosing the Right Evaluation Tool
Selection Criteria
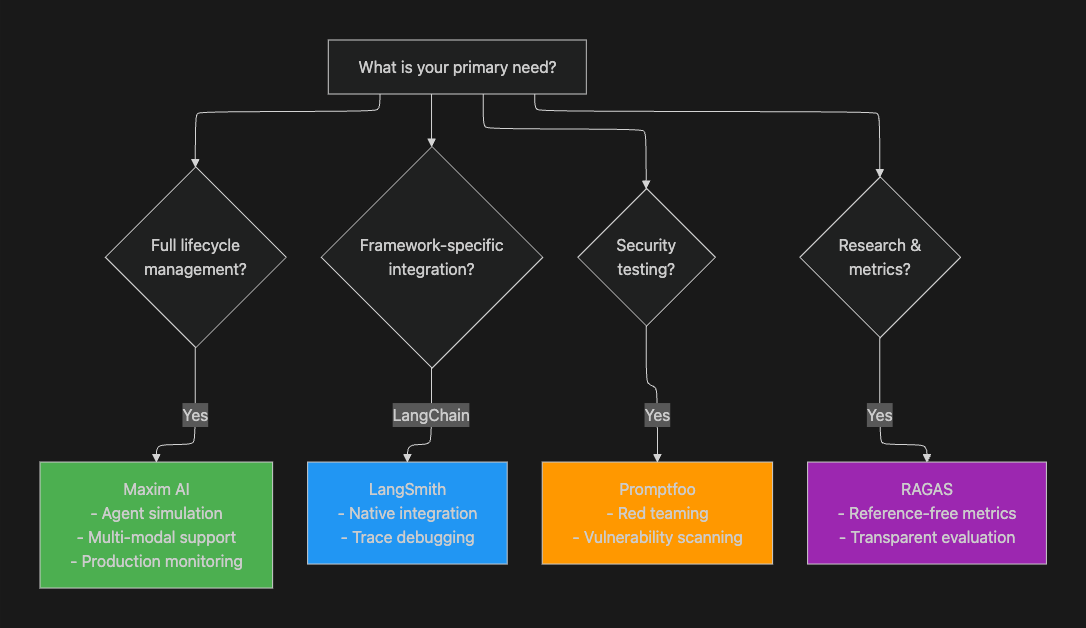
Use Case Recommendations
Choose Maxim AI if you need:
- End-to-end AI application lifecycle management from experimentation to production
- Cross-functional collaboration between engineering and product teams
- Multi-modal agent evaluation (text, image, audio, video)
- Agent simulation across diverse scenarios and personas
- Custom evaluation logic tailored to business-specific metrics
- Comprehensive observability with real-time alerting
Choose PromptLayer if you need:
- Systematic prompt versioning and iteration tracking
- Batch evaluation across multiple models for migration decisions
- Visual comparison tools for model output analysis
Choose LangSmith if you:
- Build exclusively with LangChain framework
- Require detailed trace debugging for complex chains
- Prioritize observability over systematic evaluation infrastructure
Choose Promptfoo if you need:
- Security-first evaluation with red teaming capabilities
- Lightweight, code-centric evaluation in CI/CD pipelines
- Local execution for privacy-sensitive applications
- Declarative test configuration without extensive coding
Choose RAGAS if you need:
- Transparent, reproducible RAG metrics for research
- Reference-free evaluation without manual annotation
- Framework-agnostic metrics library
- Quick baseline establishment for RAG quality
Further Reading
Academic Research
- RAGAS: Automated Evaluation of Retrieval Augmented Generation - Academic paper introducing reference-free RAG evaluation framework
Technical Guides
- Maxim AI Documentation - Complete guides for agent simulation, evaluation, and observability
Industry Resources
- RAG Evaluation Best Practices - Comprehensive guide to building automated evaluation frameworks
- Red Teaming RAG Applications - Security testing methodologies for RAG systems
- Bifrost Documentation - AI gateway features supporting production RAG deployments
Get Started with Maxim AI
Building reliable RAG applications requires comprehensive evaluation across the entire AI lifecycle. Maxim AI provides the full-stack platform teams need to ship production-ready agents with confidence.
Key advantages:
- Agent simulation across hundreds of real-world scenarios
- Multi-modal evaluation for text, image, audio, and video retrievals
- Production monitoring with real-time alerting and distributed tracing
- Cross-functional workflows enabling engineering and product collaboration
- Custom evaluation logic tailored to your business metrics
Schedule a demo to see how Maxim AI can accelerate your RAG development, or sign up for free to start evaluating your agents today.
About Maxim AI: Maxim AI is an end-to-end AI simulation, evaluation, and observability platform helping teams ship AI agents reliably and 5x faster. Teams around the world use Maxim to measure and improve the quality of their AI applications across the full development lifecycle.


