5 Essential Techniques for Debugging Multi-Agent Systems Effectively

TLDR: Debugging multi-agent systems requires specialized approaches beyond traditional single-agent methods. This guide covers five essential techniques: implementing comprehensive distributed tracing to capture complete execution flows, applying systematic failure classification using the MAST framework, leveraging span-level root cause analysis for granular debugging, enabling real-time production monitoring with intelligent alerts, and using simulation for controlled reproduction and testing. Teams using these techniques with Maxim's observability platform report 70% reduction in mean time to resolution compared to traditional log-based approaches.
Multi-agent LLM systems represent a significant advancement in AI architecture, enabling distributed reasoning and specialized task execution through collaborative autonomous agents. However, these systems introduce debugging complexity that far exceeds traditional single-agent applications. Research from UC Berkeley analyzing over 1,600 execution traces reveals that failures in multi-agent systems distribute evenly across specification, inter-agent communication, and verification phases, with no single category dominating the failure landscape.
The challenge stems from fundamental architectural differences. While single agents follow relatively linear execution paths, multi-agent systems exhibit emergent behaviors, cascading failure propagation, and state synchronization issues across distributed components. Analysis from Microsoft researchers identifies that developers struggle to review long agent conversations, lack interactive debugging support, and require specialized tooling to iterate on agent configurations effectively.
This guide presents five essential techniques for debugging multi-agent systems, grounded in recent research and production deployment insights. Teams implementing comprehensive debugging strategies using Maxim's observability platform report 70% reduction in mean time to resolution compared to traditional log-based approaches.
1. Implement Comprehensive Distributed Tracing
Distributed tracing forms the foundation of effective multi-agent debugging by capturing complete execution flows across agent hierarchies, tool invocations, and model calls. Unlike traditional logging that captures isolated events, distributed tracing reconstructs the entire request path with hierarchical relationships that preserve execution context.
Structuring Traces for Agent Workflows
Proper trace structure enables rapid root cause identification. Each trace should represent a complete user interaction with nested spans capturing individual operations:
Trace Level: Represents the entire user session or conversation, capturing session metadata and high-level outcomes.
Agent Spans: Each autonomous agent receives its own span, including orchestrator agents, specialized task agents, and supervisory agents in multi-agent architectures.
Generation Spans: Individual LLM calls nested within agent spans, capturing prompts, completions, token usage, and model parameters.
Tool Spans: External tool invocations including database queries, API calls, or file operations, critical for debugging integration failures.
Retrieval Spans: RAG pipeline operations including embedding generation, vector search, and context retrieval.
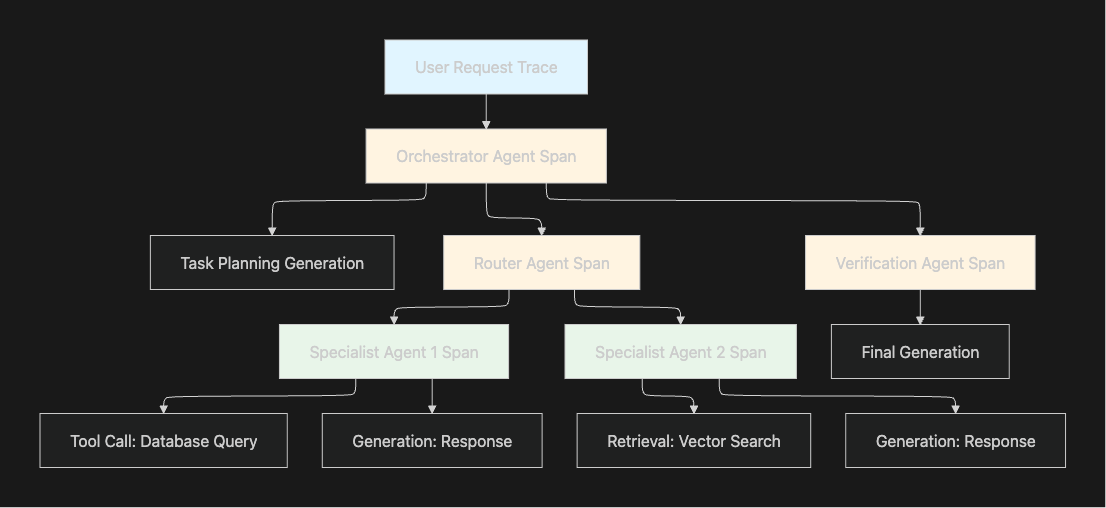
Maxim's tracing SDK automatically captures nested spans while allowing custom metadata attachment for domain-specific debugging context. The platform supports OpenTelemetry-compatible instrumentation with minimal latency overhead, typically adding less than 5% to agent operations.
Capturing Essential Debugging Context
Effective debugging requires more than execution traces. Teams must capture sufficient context to understand agent decision-making:
Input State: User messages, conversation history, and system context at execution time, critical for reproducing issues.
Intermediate Reasoning: Chain-of-thought outputs, tool selection rationale, and planning steps revealing where reasoning diverged from expected behavior.
Model Parameters: Temperature, top-p, max tokens, and sampling parameters that significantly impact behavior.
Retrieved Context: For RAG applications, the actual documents retrieved and their relevance scores enable diagnosis of retrieval quality issues.
Tool Execution Results: Both successful outputs and error states from external tools help identify whether failures originated from agents or integrations.
The Maxim observability platform provides structured visualization of this context, allowing teams to navigate complex agent interactions without manually parsing log files.
2. Apply Systematic Failure Classification
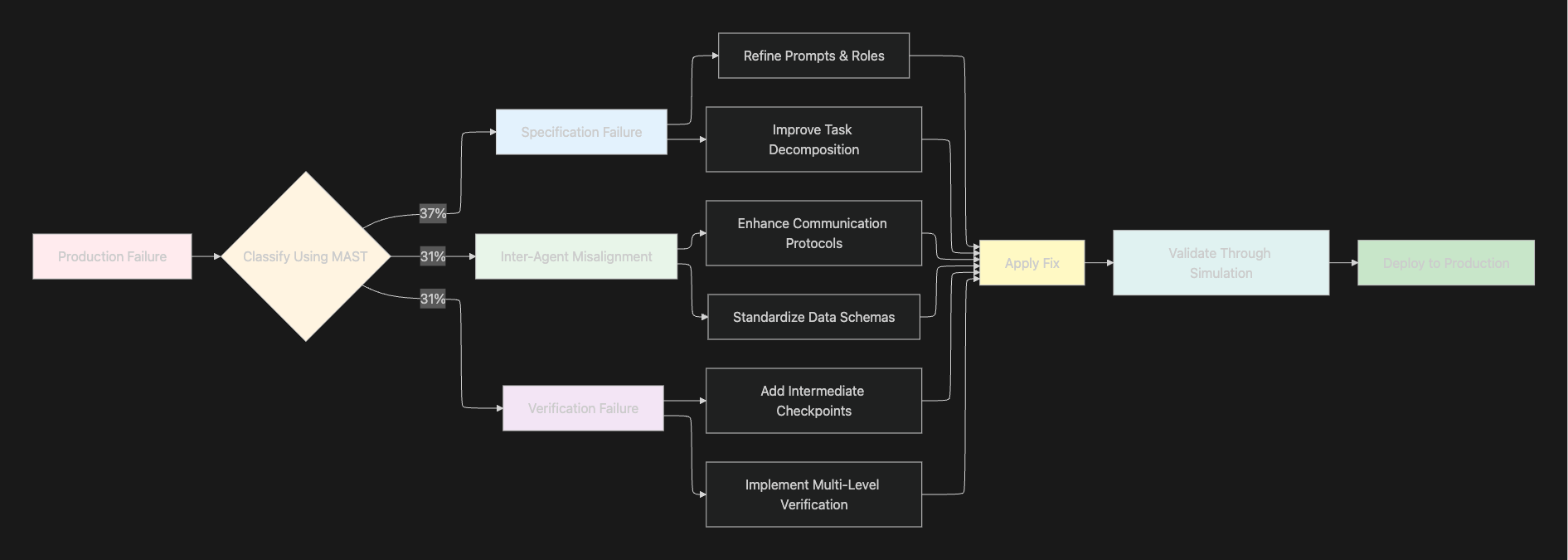
Understanding failure patterns enables targeted remediation rather than trial-and-error debugging. The Multi-Agent System Failure Taxonomy (MAST) provides the first rigorous framework for categorizing multi-agent failures, achieving 94% accuracy in automated classification with Cohen's kappa of 0.77.
MAST Failure Categories
The taxonomy identifies 14 unique failure modes across three major categories:
Specification and System Design: Includes disobeying task specifications, role specification violations, step repetition, loss of conversation history, and unclear task allocation.
Inter-Agent Misalignment: Encompasses information withholding, ignoring agent input, communication format mismatches, and coordination breakdowns.
Task Verification: Covers incorrect verification, incomplete verification, premature termination, and missing verification mechanisms.
This distribution reveals that failures affect multi-agent systems throughout the entire lifecycle, from initial setup through collaboration to final verification. Each category requires different debugging strategies.
Applying Classification in Practice
Maxim's evaluation framework supports both automated and human-driven classification, enabling teams to balance efficiency with accuracy based on failure severity and frequency. LLM-as-a-Judge pipelines can automate failure classification, enabling scalable analysis of production traces without requiring manual review of every failure.
Classification transforms unstructured failure data into actionable intelligence. Rather than viewing each failure as a unique incident, classification reveals patterns showing that multiple seemingly unrelated failures stem from the same root cause, such as ambiguous role specifications or insufficient verification logic.
3. Leverage Span-Level Root Cause Analysis
After identifying failures through tracing and classification, span-level debugging provides the granularity needed for pinpointing root causes. This technique examines individual operations within the execution hierarchy to isolate failure points.
Analyzing Generation Spans
LLM generation failures manifest in several patterns:
Prompt Structure Issues: Malformed instructions, missing context, or ambiguous phrasing cause agents to misinterpret intent. Examining the actual prompt sent to the model often reveals structural problems not apparent in application code.
Context Window Overflow: When conversation history or retrieved documents exceed model context limits, critical information gets truncated. Maxim's generation spans track token usage, highlighting when limits are approached.
Output Formatting Failures: Agents expecting structured outputs like JSON sometimes receive malformed responses. Comparing expected versus actual output schemas identifies parsing issues.
Debugging Tool Interactions
Tool execution failures often cascade into agent failures. Systematic analysis of tool call spans reveals common patterns:
Parameter Extraction Errors: Agents incorrectly extract parameters from user inputs or context. Examining the reasoning chain shows where parameter identification failed.
Authentication Failures: API rate limits, expired credentials, or permission issues manifest as tool errors. Proper error capture helps distinguish between agent logic issues and infrastructure problems.
Timeout and Latency Issues: External services sometimes respond slowly, causing agents to time out or retry unnecessarily. Span duration metrics identify latency bottlenecks.
The tool call accuracy evaluator quantifies these issues, helping teams prioritize debugging efforts.
Retrieval Pipeline Analysis
For RAG-based agents, retrieval quality directly impacts response quality. Debugging retrieval requires examining multiple components:
Embedding Quality: Poor embeddings cause semantic search to return irrelevant documents. Comparing embedding distances between queries and retrieved documents identifies relevance issues.
Chunking Strategy: Document chunking affects what context gets retrieved. Examining retrieval spans shows whether chunk boundaries split important information.
Ranking and Filtering: Even with good retrieval, poor ranking or insufficient filtering can surface irrelevant context. Context relevance metrics measure this dimension.
4. Enable Real-Time Production Monitoring
Proactive debugging requires real-time awareness of production issues. Monitoring and alerting systems surface problems before they impact significant user populations.
Critical Metrics for Multi-Agent Systems
Production monitoring for multi-agent systems extends beyond traditional application metrics:
Quality Metrics: Task success rate, user satisfaction scores, and evaluation metrics run on production traffic. Declining quality metrics indicate agent degradation requiring investigation.
Performance Metrics: Latency percentiles for agent responses, time spent in each workflow stage, and token consumption rates. Performance regressions often precede quality issues.
Error Rates: Failed tool calls, LLM provider errors, timeout rates, and parsing failures. Spikes in error rates signal infrastructure or integration problems.
Cost Metrics: Token usage, API call volumes, and per-interaction costs. Unexpected cost increases sometimes indicate inefficient agent behavior like retry loops.
Maxim's observability dashboards provide real-time visualization of these metrics with customizable time ranges and filtering.
Configuring Intelligent Alerts
Effective alerting strategies balance sensitivity with noise reduction:
Threshold-Based Alerts: Trigger when metrics cross predefined thresholds, such as task success rate dropping below 85% or average latency exceeding 5 seconds.
Anomaly Detection: Machine learning models identify unusual patterns without manual threshold setting, particularly valuable for gradual degradation.
Trend-Based Alerts: Trigger on sustained metric trends rather than momentary spikes, reducing false positives from transient issues.
Composite Alerts: Combine multiple signals to reduce noise, such as alerting on increased latency only when it coincides with increased error rates.
Teams can configure alerts and notifications to route issues to appropriate channels like Slack, PagerDuty, or email based on severity and team responsibilities.
Automated Quality Evaluation
Running evaluations continuously on production traffic provides quality assurance without manual review overhead. Automated evaluation on logs enables:
Quality Regression Detection: Automatically identify when deployed changes degrade specific quality dimensions, providing immediate feedback.
Drift Monitoring: Track whether agent behavior changes over time due to model updates, data distribution shifts, or environmental changes.
Targeted Dataset Curation: Failed evaluations automatically populate datasets for further analysis, creating a continuous improvement loop.
5. Use Simulation for Reproduction and Testing
Reproduction in controlled environments is critical for validating fixes without risking production systems. Maxim's Agent Simulation enables testing agents across hundreds of scenarios to reproduce failure conditions systematically.
Simulation Capabilities
The simulation platform supports comprehensive testing approaches:
User Persona Modeling: Create distinct user profiles with varying communication styles, domain knowledge levels, and behavioral patterns. Agents face realistic variability during testing.
Scenario Coverage Generation: Systematically test agents across hundreds of conversation flows, identifying failure modes that manual testing would miss.
Production Issue Reproduction: When bugs emerge in production, teams can recreate the exact scenario in simulation for debugging without impacting live users.
Regression Testing: After fixing issues, re-run simulations to verify the fix worked without introducing new problems. Critical for maintaining agent quality during rapid iteration.
Advanced Debugging Strategies
Beyond basic simulation, several advanced strategies enhance debugging effectiveness:
Circuit Breaker Implementation: Circuit breakers prevent cascading failures by isolating problematic agents before errors propagate system-wide. Analysis of production failures shows that implementing circuit breaker patterns can reduce cascade failure impact by 70%.
Replay Debugging: Maxim's data curation capabilities support replay debugging by preserving complete execution context including agent states, message sequences, and external tool responses. Developers can rerun simulations from any step to reproduce issues and validate fixes.
Failure Injection: Controlled experimentation enables systematic validation by intentionally triggering specific conditions such as delayed state propagation, tool failures, or message loss.
Cost Management During Debugging
Debugging multi-agent systems can become expensive quickly when reproducing failures requires executing multiple agents across numerous scenarios. Bifrost, Maxim's AI gateway, provides several cost optimization features:
Semantic Caching: Intelligent caching based on semantic similarity dramatically reduces costs when debugging involves repeated execution of similar scenarios, potentially reducing API costs by 50-80%.
Automatic Fallbacks: Load balancing and fallbacks ensure debugging workflows continue even when specific providers experience issues, preventing wasted time and resources.
Budget Management: Hierarchical cost control prevents debugging activities from exceeding allocated budgets through project, team, or individual level limits.
Building a Systematic Debugging Culture
Technical tools form only part of effective debugging. Organizations must cultivate practices that emphasize systematic approaches and continuous improvement:
Documentation and Knowledge Sharing: Documenting debugging sessions, failure patterns, and resolution strategies builds institutional knowledge that accelerates future debugging efforts. Maxim's platform supports this through structured failure classification and reusable evaluation suites.
Cross-Functional Collaboration: Multi-agent debugging often requires collaboration between AI engineers, product managers, and domain experts. Maxim's user experience enables seamless cross-functional teamwork with interfaces tailored to different personas.
Proactive Failure Prevention: The ultimate goal is preventing failures rather than reacting to them. Organizations should invest in comprehensive simulation before deployment, gradual rollouts with monitoring, and continuous evaluation of production behavior.
Conclusion
Debugging multi-agent systems demands specialized approaches that address distributed coordination, cascading failures, and emergent behaviors. The five essential techniques presented here provide a framework for building reliable multi-agent applications: comprehensive distributed tracing, systematic failure classification, span-level root cause analysis, real-time production monitoring, and simulation-based testing.
Research demonstrates that failures distribute evenly across specification, inter-agent communication, and verification phases, requiring multi-faceted debugging strategies. Success depends on comprehensive observability infrastructure, systematic classification frameworks like MAST, and robust evaluation capabilities.
Maxim AI provides the complete platform teams need to debug multi-agent systems effectively, from distributed tracing and automated evaluations to simulation capabilities and human-in-the-loop workflows. Organizations using the platform report 70% reduction in mean time to resolution, enabling faster iteration and more reliable production deployments.
Ready to transform how your team debugs multi-agent systems? Schedule a demo to explore how Maxim AI accelerates debugging and improves agent reliability, or sign up today to start building more reliable multi-agent applications.


