Red teaming with auto-generated rewards and multi-step RL
Introduction
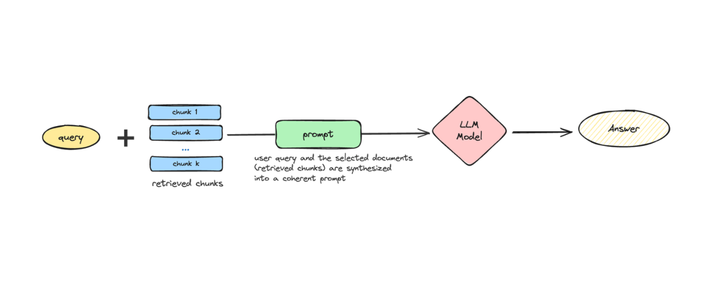
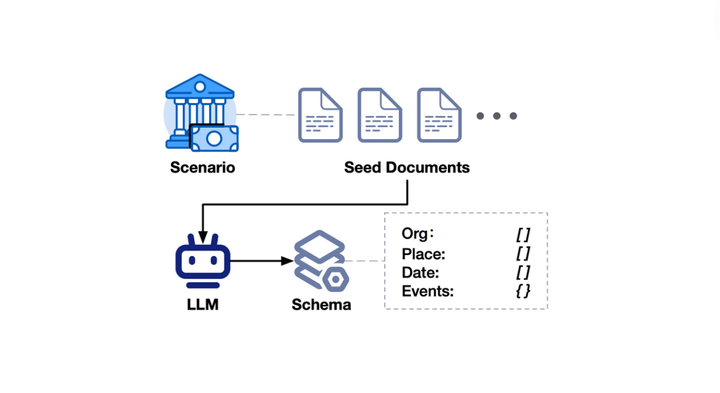
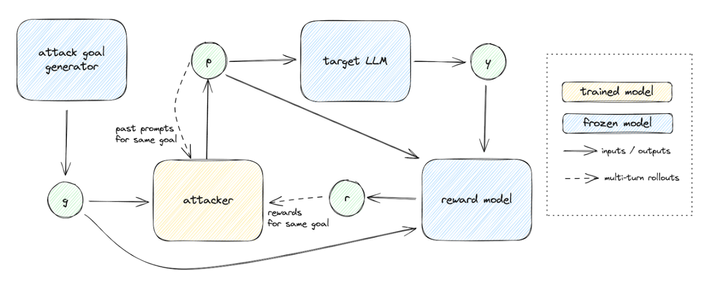
Making AI systems like LLMs robust against adversarial cases is a critical area of research. One approach to identifying vulnerabilities in AI models is red-teaming, where adversarial prompts or attacks are designed to expose weaknesses. However, generating a wide variety of diverse yet effective attacks remains a significant challenge.