Graph RAG

Introduction
This blog explores Microsoft's Graph-based Retrieval-Augmented Generation (Graph RAG) approach. While traditional RAG excels at retrieving specific information, it struggles with global queries, like identifying key themes in a dataset, which require query-focused summarization (QFS). Graph RAG combines the strengths of RAG and QFS by using entity knowledge graphs and community summaries to handle both broad questions and large datasets.
What are the challenges with RAG?
The primary challenges with RAG are:
- Global question handling: RAG struggles with global questions that require understanding the entire text corpus, such as "What are the main themes in the dataset?". These questions require query-focused summarization (QFS), which differs from RAG's typical focus on retrieving and generating content from specific, localized text regions.
- QFS: Traditional QFS methods, which summarize content based on specific queries, do not scale well to the large volumes of text typically indexed by RAG systems.
- Context window limitations: While modern Large Language Models (LLMs) like GPT, Llama, and Gemini can perform in-context learning to summarize content, they are limited by the size of their context windows. When dealing with large text corpora, crucial information can be "lost in the middle" of these longer contexts, making it challenging to provide comprehensive summaries.
- Inadequacy of direct retrieval: For QFS tasks, directly retrieving text chunks in a naive RAG system is often inadequate. RAG's standard approach is not well-suited for summarizing entire datasets or handling global questions, which requires a more sophisticated indexing and retrieval mechanism tailored to global summarization needs.
What is Graph RAG?
Graph RAG is an advanced question-answering method that combines RAG with a graph-based text index. It builds an entity knowledge graph from source documents and generates summaries for related entities. For a given question, partial responses from these summaries are combined into a comprehensive final answer. This approach scales well with large datasets and provides more comprehensive answers than traditional RAG methods.
Graph RAG approach & pipeline
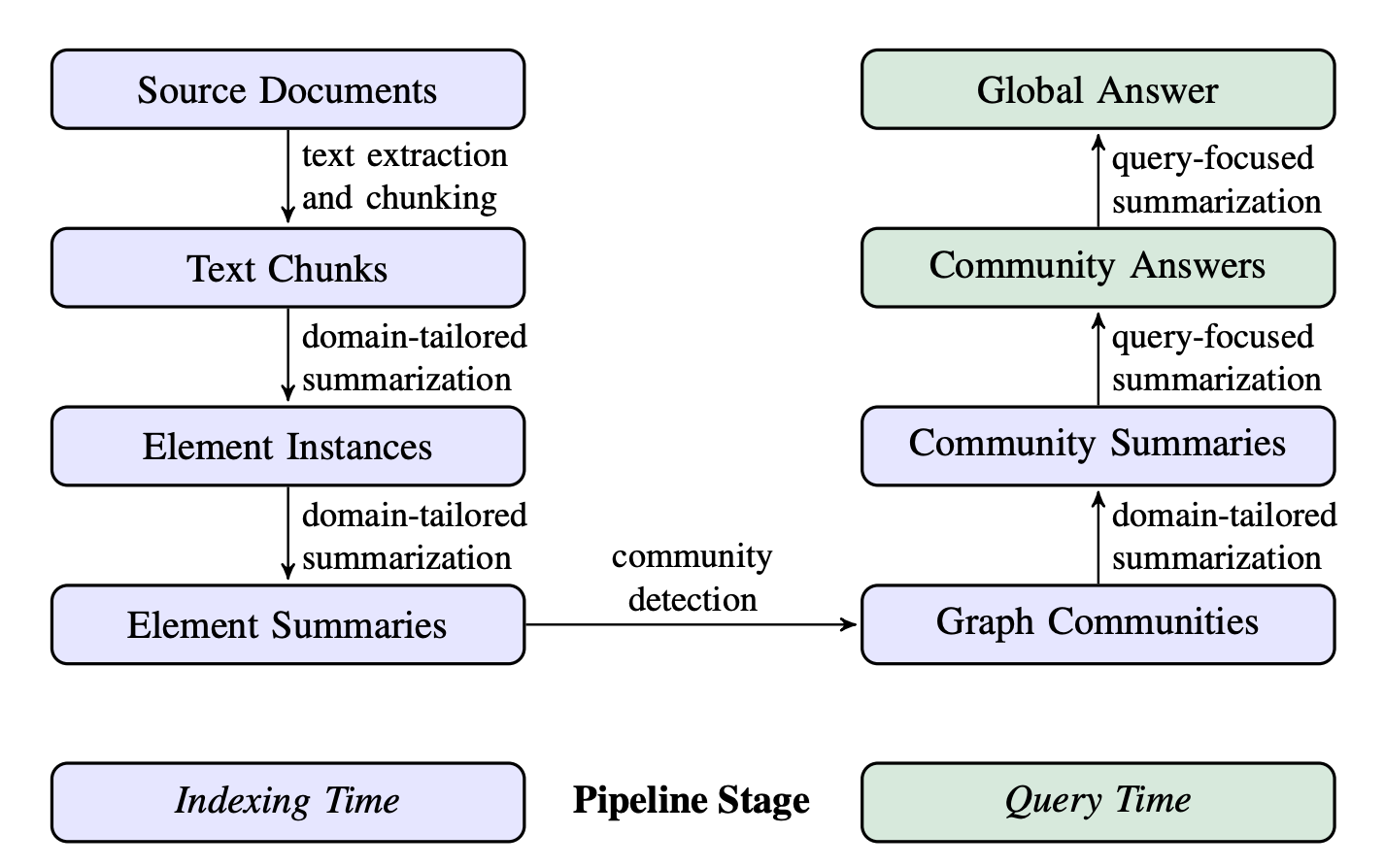
The Graph RAG pipeline uses an LLM-derived graph index to organize source document text into nodes (like entities), edges (relationships), and covariates (claims). These elements are detected, extracted, and summarized using LLM prompts customized for the dataset. The graph index is partitioned into groups of related elements through community detection. Summaries for each group are generated in parallel both during indexing and when a query is made. To answer a query, a final query-focused summarization is performed over all relevant community summaries, producing a comprehensive "global answer."
Step 1: source documents → text chunks
In this stage, texts from source documents are split into chunks for processing. Each chunk is then passed to LLM prompts to extract elements for a graph index.
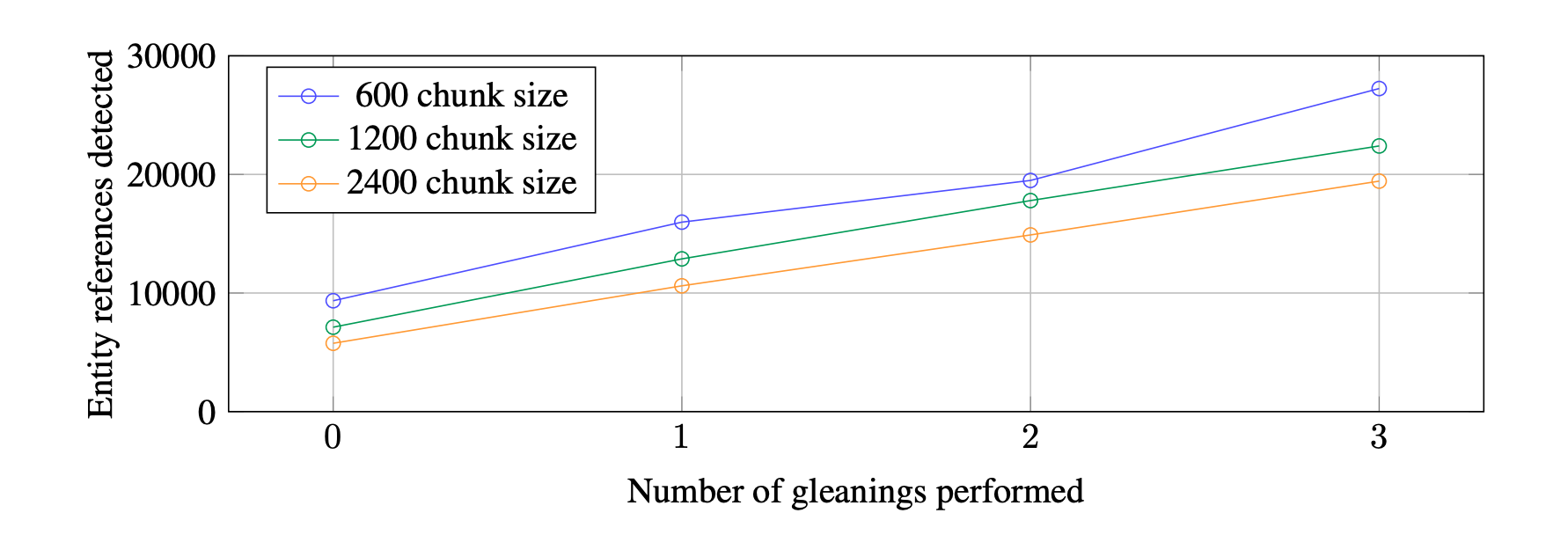
While longer chunks reduce the number of LLM calls needed to process the entire document because more text is handled during each call, they can impair the LLM’s ability to recall details due to an extended context window. For example, in the HotPotQA dataset, a 600-token chunk extracted nearly twice as many entity references as a 2400-token chunk. Thus, balancing recall and precision is crucial.
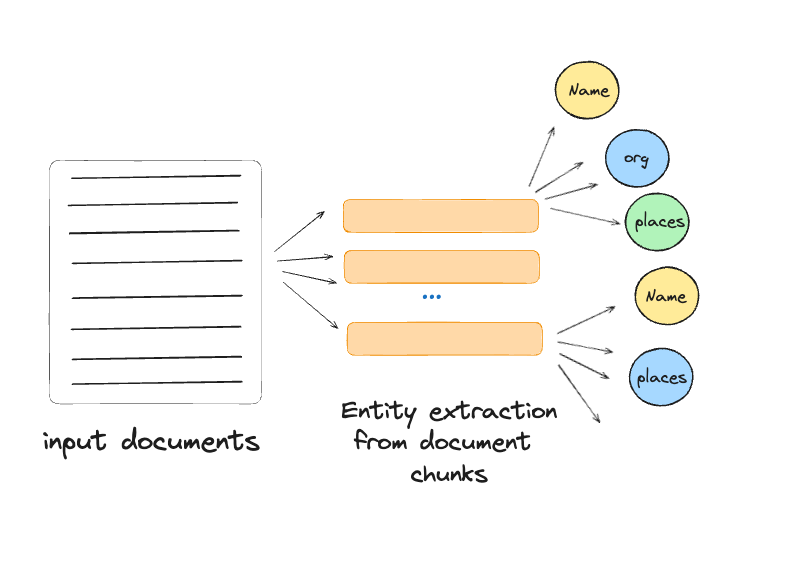
Step 2: text chunks → element instances
In this step, graph nodes and edges are identified and extracted from each chunk of source text using a multipart LLM prompt. The prompt first extracts all entities, including their name, type, and description, and then identifies relationships between these entities, detailing the source, target, and nature of each relationship. Both entities and relationships are output as a list of delimited tuples.
The prompt can be tailored to the document corpus by including domain-specific few-shot examples, improving extraction accuracy for specialized fields like science or medicine. Additionally, a secondary prompt extracts covariates, such as claims related to the entities, including details like subject, object, type, description, source text span, and dates.
Step 3: element instances → element summaries
In this step, an LLM is used to perform abstractive summarization, creating meaningful summaries of entities, relationships, and claims from source texts. The LLM extracts these elements and summarizes them into single blocks of descriptive text for each graph element: entity nodes, relationship edges, and claim covariates.
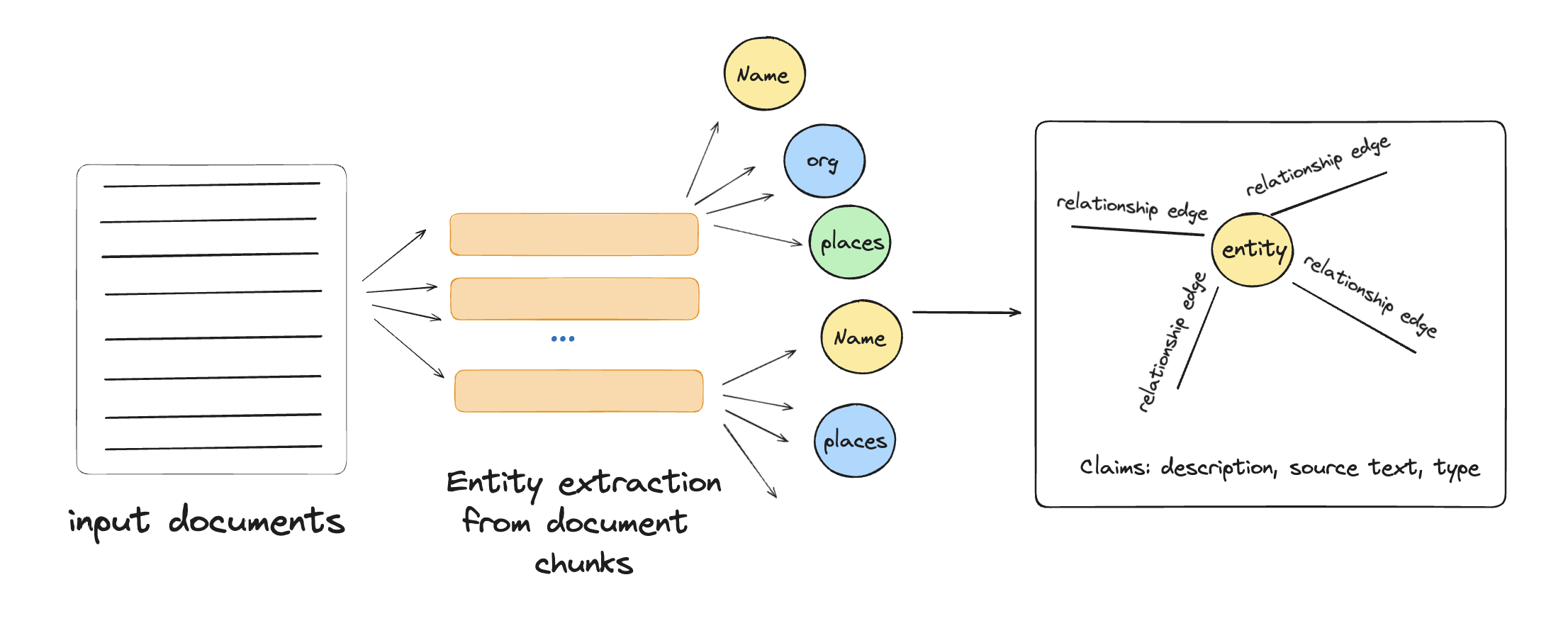
However, a challenge here is that the LLM might extract and describe the same entity in different formats, potentially leading to duplicate nodes in the entity graph. To address this, the process includes a subsequent step where related groups of entities (or "communities") are detected and summarized together. This helps to consolidate variations and ensures that the entity graph remains consistent, as the LLM can recognize and connect different names or descriptions of the same entity. Overall, the approach leverages LLM capabilities to handle variations and produce a comprehensive, coherent graph structure.
Example: Imagine the LLM is tasked with extracting information about a well-known historical figure, "Albert Einstein," from various texts. The LLM might encounter different ways of referring to Einstein, such as:
- "Albert Einstein"
- "Einstein"
- "Dr. Einstein"
- "The physicist Albert Einstein"
During the extraction process, the LLM may generate separate entity nodes for each of these variations, resulting in duplicate entries:
- Node 1: Albert Einstein
- Node 2: Einstein
- Node 3: Dr. Einstein
- Node 4: The physicist Albert Einstein
These variations could lead to multiple nodes for the same person in the entity graph, causing redundancy and inconsistencies.
In the subsequent step, the LLM summarizes and consolidates these related variations into a single node by detecting and linking all references to the same entity. For instance:
- Node: Albert Einstein (consolidates all variations: Einstein, Dr. Einstein, The physicist Albert Einstein)
By summarizing all related variations into a single descriptive block, the process ensures that the entity graph is accurate and does not contain duplicate nodes for the same individual.
Step 4: element instances → element summaries
In this step, the index is modeled as a weighted undirected graph where entity nodes are linked by relationship edges, with edge weights reflecting the frequency of relationships. The graph is then partitioned into communities using the Leiden algorithm, efficiently identifying hierarchical community structures. This allows for a detailed, hierarchical graph division, enabling targeted and comprehensive global summarization.
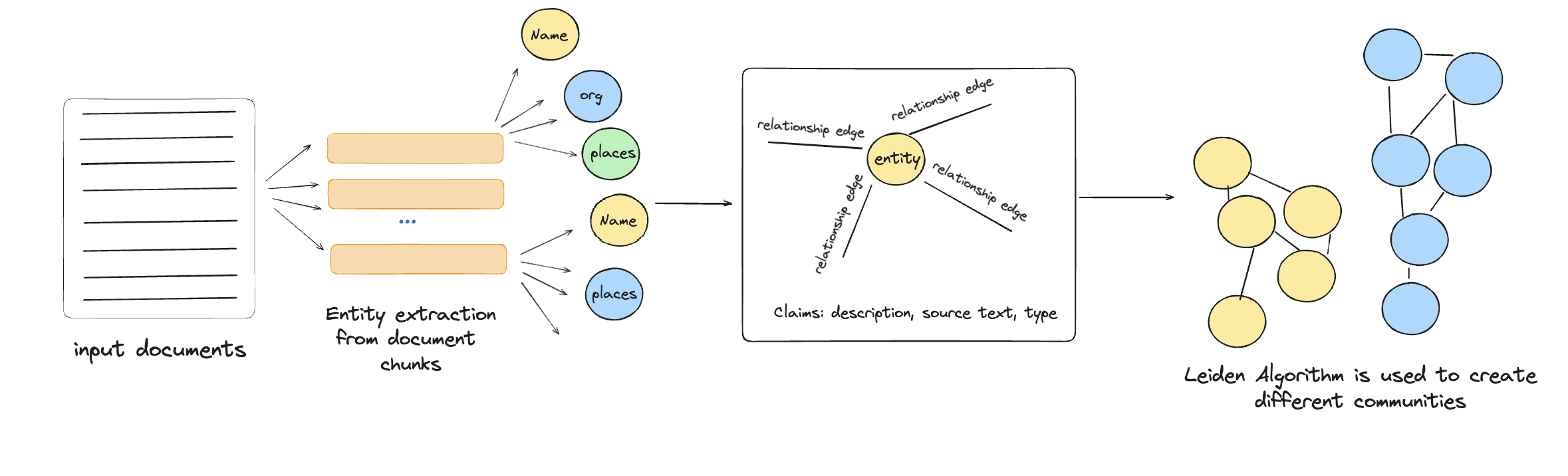
Step 5: graph communities → community summaries
In this step, report-like summaries are created for each community detected in the graph. These summaries help understand the global structure and details of the dataset and are useful for answering global queries. Here's how it's done:
Leaf-level communities: Summarize the details of the smallest communities first, prioritizing descriptions of nodes, edges, and related information. These summaries are added to the LLM context window until the token limit is reached.
Higher-level communities: If there’s room in the context window, summarize all elements of these larger communities. If not, prioritize summaries of sub-communities over detailed element descriptions, fitting them into the context window by substituting longer descriptions with shorter summaries.
This approach ensures that both detailed and high-level summaries are generated efficiently, fitting within the LLM's token limits while maintaining comprehensive coverage of the dataset.
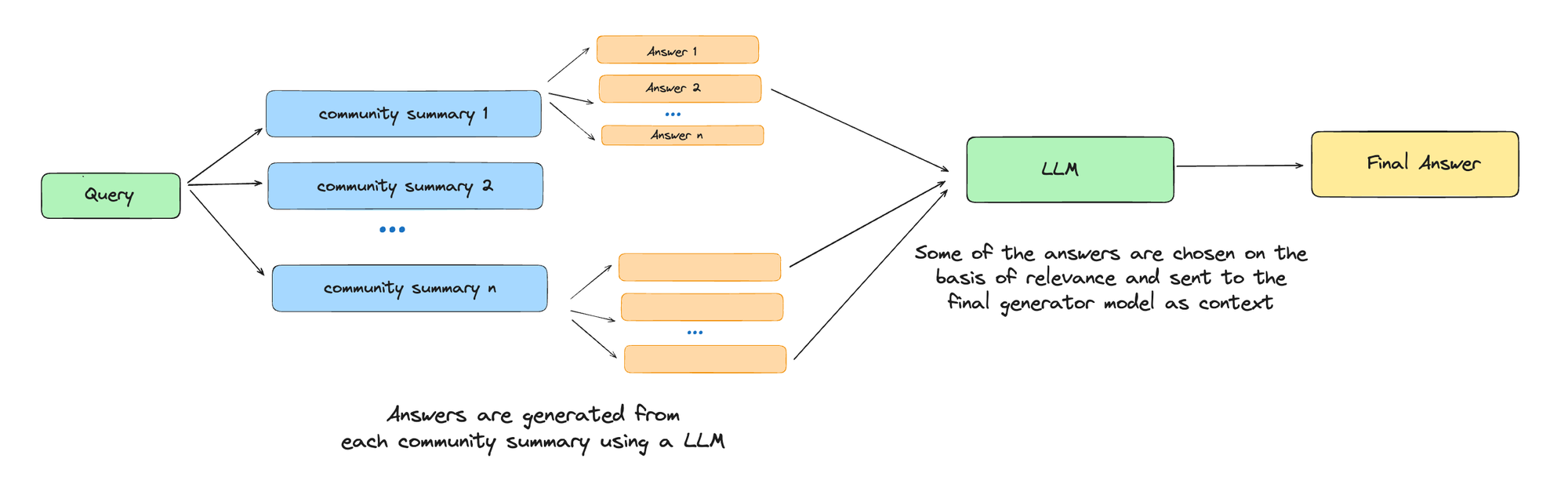
Step 6: community summaries → community answers → global answer
Given a user query, the community summaries created in the previous step are used to produce a final answer through a multi-stage process. The hierarchical structure of the communities allows the system to select the most appropriate level of detail for answering different types of questions. The process for generating a global answer at a specific community level is as follows:
- Prepare community summaries: The community summaries are shuffled and split into chunks of a predefined token size. This approach helps ensure that relevant information is spread across multiple chunks, reducing the risk of losing important details in a single context window.
- Generate intermediate answers: For each chunk, the LLM generates intermediate answers in parallel. Along with the answer, the LLM assigns a helpfulness score between 0-100, indicating how well the answer addresses the user’s query. Any answers scoring 0 are discarded.
- Compile the global answer: The remaining intermediate answers are sorted in descending order based on their helpfulness scores. These answers are then added to a new context window, one by one, until the token limit is reached. This final compilation is used to generate the global answer provided to the user.
Performance evaluation
The authors evaluated the performance of both Graph-based Retrieval-Augmented Generation (Graph RAG) and standard RAG approaches using two datasets, each containing approximately one million tokens, equivalent to around 10 novels of text. The evaluation was conducted across four different metrics.
Datasets
The datasets were chosen to reflect the types of text corpora users might typically encounter in real-world applications:
- Podcast transcripts: This dataset includes transcripts from the "Behind the Tech" podcast, where Kevin Scott, Microsoft's CTO, converses with other technology leaders. The dataset comprises 1,669 text chunks, each containing 600 tokens, with a 100-token overlap between chunks, resulting in approximately 1 million tokens overall.
- News articles: The second dataset is a benchmark collection of news articles published between September 2013 and December 2023. It covers a range of categories, including entertainment, business, sports, technology, health, and science. This dataset consists of 3,197 text chunks, each containing 600 tokens with a 100-token overlap, totaling around 1.7 million tokens.
Conditions
The authors compared six different evaluation conditions to assess the performance of the Graph-based RAG system. These conditions included four levels of graph communities (C0, C1, C2, C3), a text summarization method (TS), and a naive "semantic search" RAG approach (SS). Each condition represented a distinct method for creating the context window used to answer queries:
- C0: Utilized summaries from root-level communities, which were the fewest in number.
- C1: Employed high-level summaries derived from sub-communities of C0.
- C2: Applied intermediate-level summaries from sub-communities of C1.
- C3: Low-level summaries from sub-communities of C2 were used, which were the most numerous.
- TS: Implemented a map-reduce summarization method directly on the source texts, shuffling and chunking them.
- SS: Employed a naive RAG approach where text chunks were retrieved and added to the context window until the token limit was reached.
All conditions used the same context window size and prompts, with differences only in how the context was constructed. The graph index supporting the C0-C3 conditions was generated using prompts designed for entity and relationship extraction, with modifications made to align with the specific domain of the data. The indexing process used a 600-token context window, with varying numbers of "gleanings" (passes over the text) depending on the dataset.
Metrics
The evaluation employs an LLM to conduct a head-to-head comparison of generated answers based on specific metrics. Given the multi-stage nature of the Graph RAG mechanism, the multiple conditions the authors wanted to compare, and the lack of gold standard answers for activity-based sensemaking questions, the authors decided to adopt a head-to-head comparison approach using an LLM evaluator, this approach helps in assessing system performance through:
- Comprehensiveness: This metric measures the extent to which the answer provides detailed coverage of all aspects of the question.
- Diversity: This evaluates the richness and variety of perspectives and insights presented in the answer.
- Empowerment: This assesses how effectively the answer aids the reader in understanding the topic and making informed judgments.
- Directness: This measures the specificity and clarity with which the answer addresses the question.
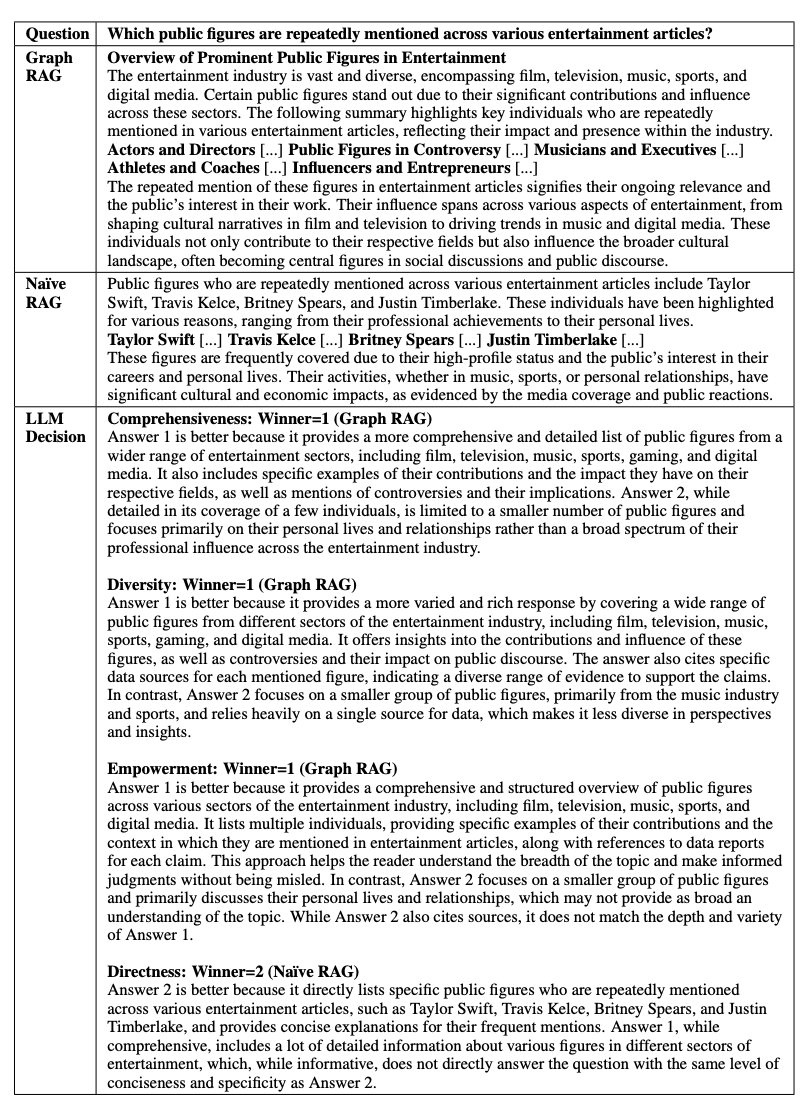
Since directness often conflicts with comprehensiveness and diversity, it is unlikely for any method to excel across all metrics. The LLM evaluator compares pairs of answers based on these metrics, determining a winner or a tie if differences are negligible. Each comparison is repeated five times to account for the stochastic nature of LLMs, with mean scores used for final assessments.
Results
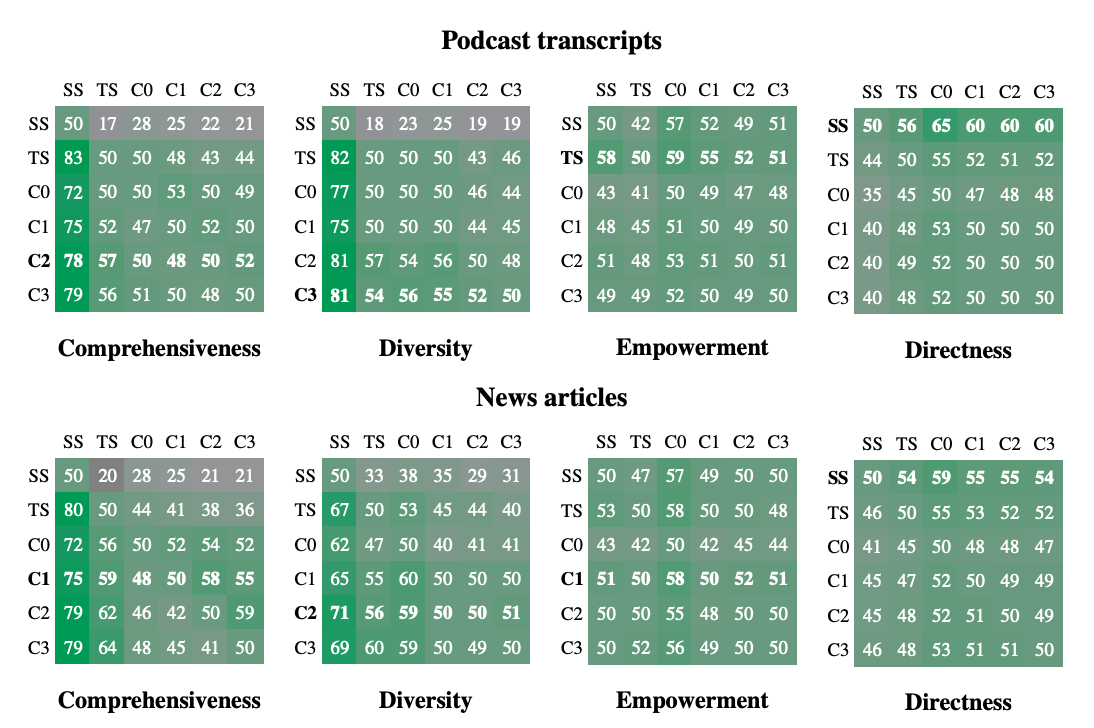
The indexing process created graphs with 8,564 nodes and 20,691 edges for the Podcast dataset and 15,754 nodes and 19,520 edges for the News dataset. Graph RAG approaches consistently outperformed the naïve RAG (SS) method in both comprehensiveness and diversity across datasets, with win rates of 72-83% for Podcasts and 72-80% for News in comprehensiveness, and 75-82% and 62-71% for diversity, respectively. Community summaries provided modest improvements in comprehensiveness and diversity compared to source texts, with root-level summaries in Graph RAG being highly efficient. Root-level Graph RAG offers a highly efficient method for iterative question answering that characterizes sensemaking activity while retaining advantages in comprehensiveness (72% win rate) and diversity (62% win rate) over naive RAG. Empowerment results were mixed, with naive RAG outperforming in directness.
Conclusion
Graph RAG advances traditional RAG by effectively addressing complex global queries that require comprehensive summarization of large datasets. By combining knowledge graph generation with query-focused summarization, Graph RAG provides detailed and nuanced answers, outperforming naive RAG in both comprehensiveness and diversity.
This global approach integrates RAG, QFS, and entity-based graph indexing to support sensemaking across entire text corpora. Initial evaluations show significant improvements over naive RAG and competitive performance against other global methods like map-reduce summarization.GraphRAG improves upon naive RAG in scenarios requiring complex reasoning, high factual accuracy, and deep data understanding—such as financial analysis, legal review, and life sciences. However, naive RAG may be more efficient for straightforward queries or when speed is key. In short, GraphRAG is best for complex tasks, but naive RAG suffices for simpler ones.
Maxim is an evaluation platform for testing and evaluating LLM applications. Test your RAG performance with Maxim.