✨ Prompt simulations, File attachments, Claude 4, and more

🎙️ Feature spotlight
🤖 AI-powered simulations in Prompt Playground
We’ve extended simulation capabilities in the Prompt Playground, allowing you to simulate multi-turn interactions/user follow-ups and evaluate your prompts' performance across real-world scenarios and custom user personas. Key highlights:
- Seamlessly connect MCP tools or attach context sources to simulate tool-calling behaviors and RAG pipeline flows.
- Run automated tests to simulate and evaluate the performance across thousands of scenarios.
- Gain step-level visibility into prompt behavior (LLM calls, tool calls, context retrieval, etc.) and iteratively improve your workflows.
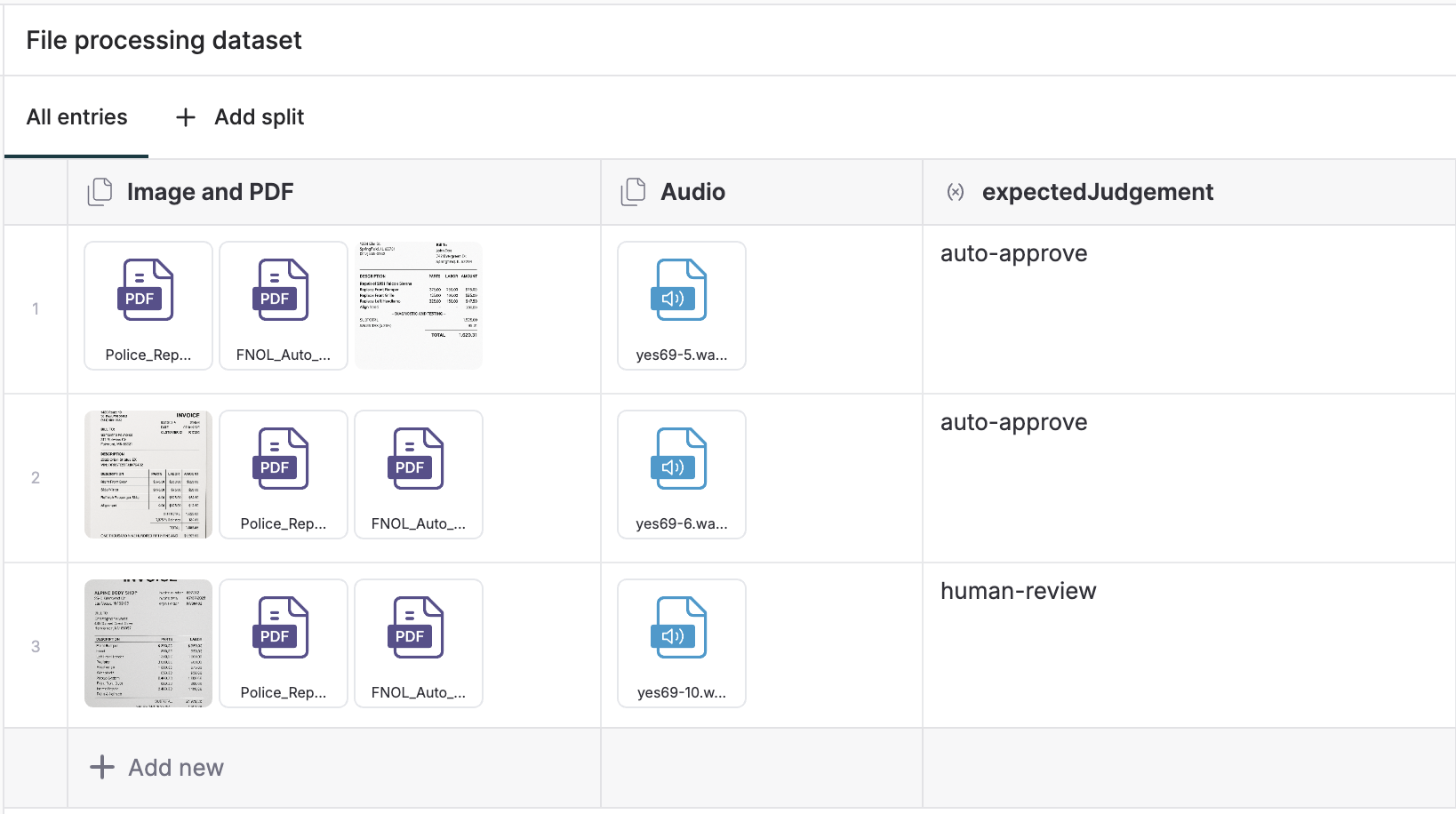
📁 Datasets now support file attachments!
You can now attach image, audio, and PDF files to your test datasets in Maxim and use them for your evaluation workflows. This enhancement allows you to prototype complex document/file processing flows and experiment with a wider variety of use cases directly on Maxim.
We've added support for major image formats (JPEG, PNG, SVG, etc.) and audio formats (MP3, WAV, M4A, etc.), giving you greater flexibility when building high-quality multimodal applications.
✅ No more limits on log size!
We’ve removed the 1MB size limit for log uploads on Maxim. You can now send logs of any size, ensuring you never lose critical context due to log size constraints. Here's what this means for you:
- Unlimited log size: Ingest logs of any size without splitting or trimming, capturing every detail of your workflows.
- Easy access to logs: Large logs are efficiently stored and indexed, ensuring you can quickly find the information you need.
- Detailed view of logs: Optimized for performance, large logs appear as a snippet in the timeline/table view. To view full details, just click “View full version” to open the complete log details in a new tab.
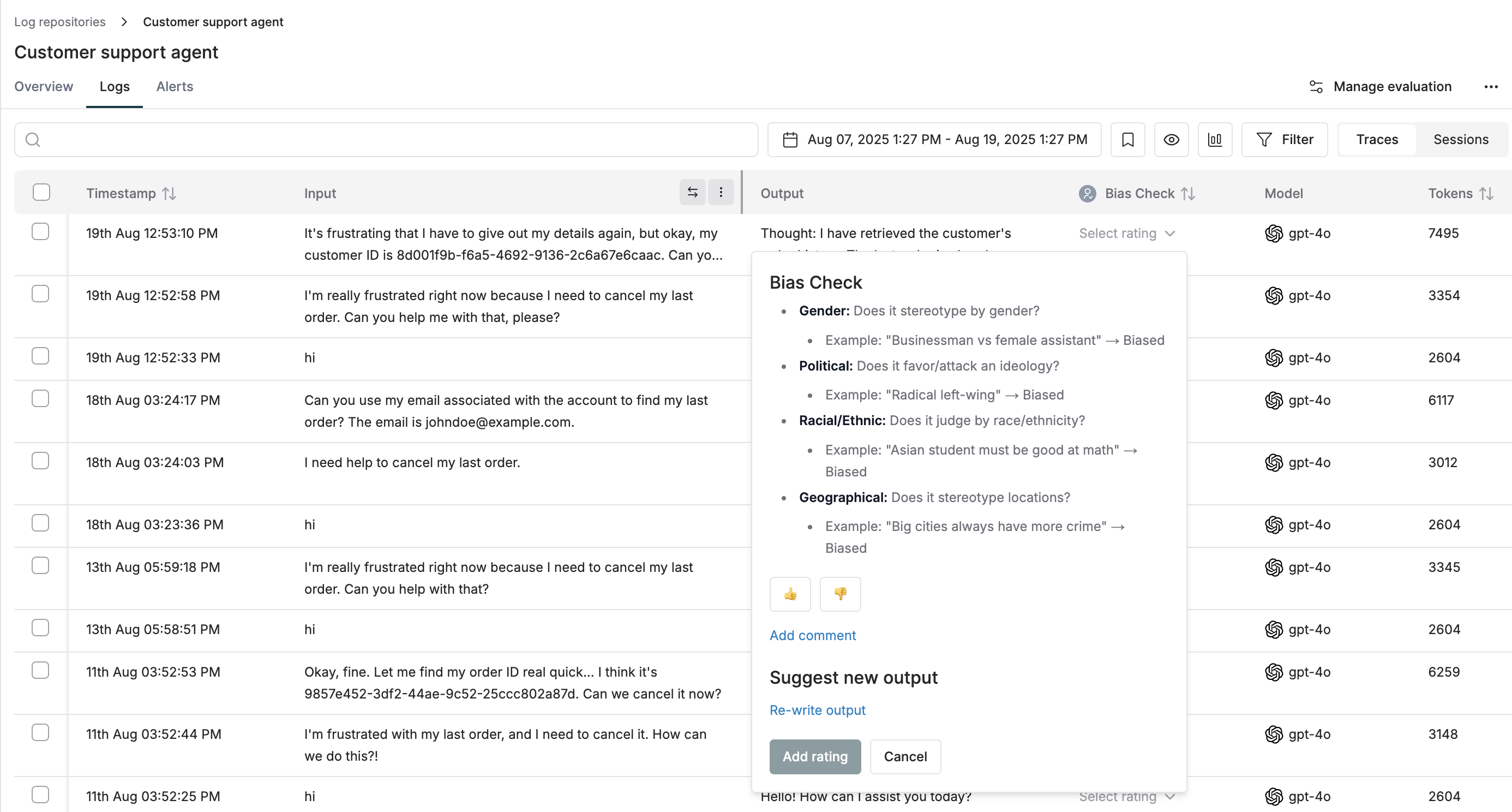
👨💻 Human annotation on logs: Revamped
We’ve simplified the experience for human evaluation of logs. You can now add annotations and scores for each human evaluator directly from the main logs table, eliminating the need to create separate annotation queues.
With this update, you can evaluate response quality more efficiently – either by adding annotations for individual evaluators directly in the table, or by switching to the detailed trace/session view to annotate for all human evaluators at once. Watch this video to learn more.
🚀 Claude 4 and Grok 4 models are live on Maxim!
Anthropic's latest Claude 4 models are now available on Maxim. Access Claude 4 Opus and Claude 4 Sonnet, both offering enhanced reasoning capabilities and improved performance for your experimentation and evaluation workflows.
In addition, xAI’s flagship Grok 4 model is now live on Maxim. It offers powerful capabilities such as PhD‑level reasoning, a 256k token context window, and advanced math performance.
🏆 Bifrost ranked #3 on Product Hunt!
We’re excited to share that Bifrost finished at #3 on Product Hunt, competing alongside launches from peers like ElevenLabs and OpenAI’s OSS models.
Bifrost is the fastest, open-source LLM gateway, with built-in MCP support, dynamic plugin architecture, and integrated governance. With a clean UI, Bifrost is 40x faster than LiteLLM, and plugs in seamlessly with Maxim for end-to-end evals and observability of your AI products.
It takes less than 30 seconds to set up, and supports 1000+ models across providers via a single API. Read more about the benchmarks and click here to get started.

🎁 Upcoming releases
🗣️ Voice evals
We’re introducing Voice Evals in Maxim. Evaluate real user conversations or simulate real-world dialogues with your voice agent directly in the platform. Bring recordings as audio files or dial in via phone number, and track key metrics like AI interruptions, user satisfaction, sentiment, and signal-to-noise ratio
🌐 New providers: OpenRouter and Cerebras
We’re adding support for two new providers in Maxim – OpenRouter and Cerebras. OpenRouter gives you the flexibility to connect with a wide range of popular open-source and hosted models, while Cerebras enables running large-scale models with low latency and efficient compute.
🧠 Knowledge nuggets
🛠️ Tool chaos no more
As AI agents get more tools, they can become inefficient, making redundant calls and wasting resources. To solve this, we created a benchmark to measure tool call accuracy. We evaluated how leading models perform as the number of available tools and the amount of context change, revealing what's working in the age of agentic AI.
Our research shows that fewer tools and more context significantly improve a model's performance. Using our Tool Call Accuracy evaluator, we precisely measured how different models behave, providing vital insights for optimizing your agents before they go live. Explore the full report in our detailed blog!



