Evaluating LLM Output for Quality, Safety, and Brand Voice with Patronus AI and Bifrost
Kamya Shah
Jun 02, 2026 · 8 min read

LLM features in production fail in ways that classic guardrails are not looking for. A coding assistant returns JSON that looks valid and silently breaks the downstream pipeline that parses it. A customer support reply apologizes three times in five sentences and reads as defensive. A marketing draft names a competitor in a comparison the brand team never approved. An HR assistant writes advice in subtly gendered language. An internal tool answers a perfectly reasonable question with "As an AI assistant I cannot help with that." None of these are attacks, none of them carry sensitive data, and none of them would trip a safety filter. They are quality, format, brand, and tone failures, and they are how LLM features actually break once the obvious safety holes are closed. Bifrost, the open-source AI gateway from Maxim AI, integrates with Patronus AI so that the evaluators a team uses to grade these failures offline can run inline on every LLM call.
The Gateway: One Place to Run Many Evaluators
A single evaluator does not catch much. Real quality control on LLM output looks more like a fleet of checks: one for safety, one for format validity, one for tone, one for bias, one for brand voice, maybe a custom one specific to the workflow. Wiring that into application code, against every model an organization uses, against every provider's SDK, is exactly the kind of fragmentation gateways exist to remove. Every team builds its own evaluation harness. Every harness handles failures differently. The security and quality teams have no single place to see what is passing and what is not.
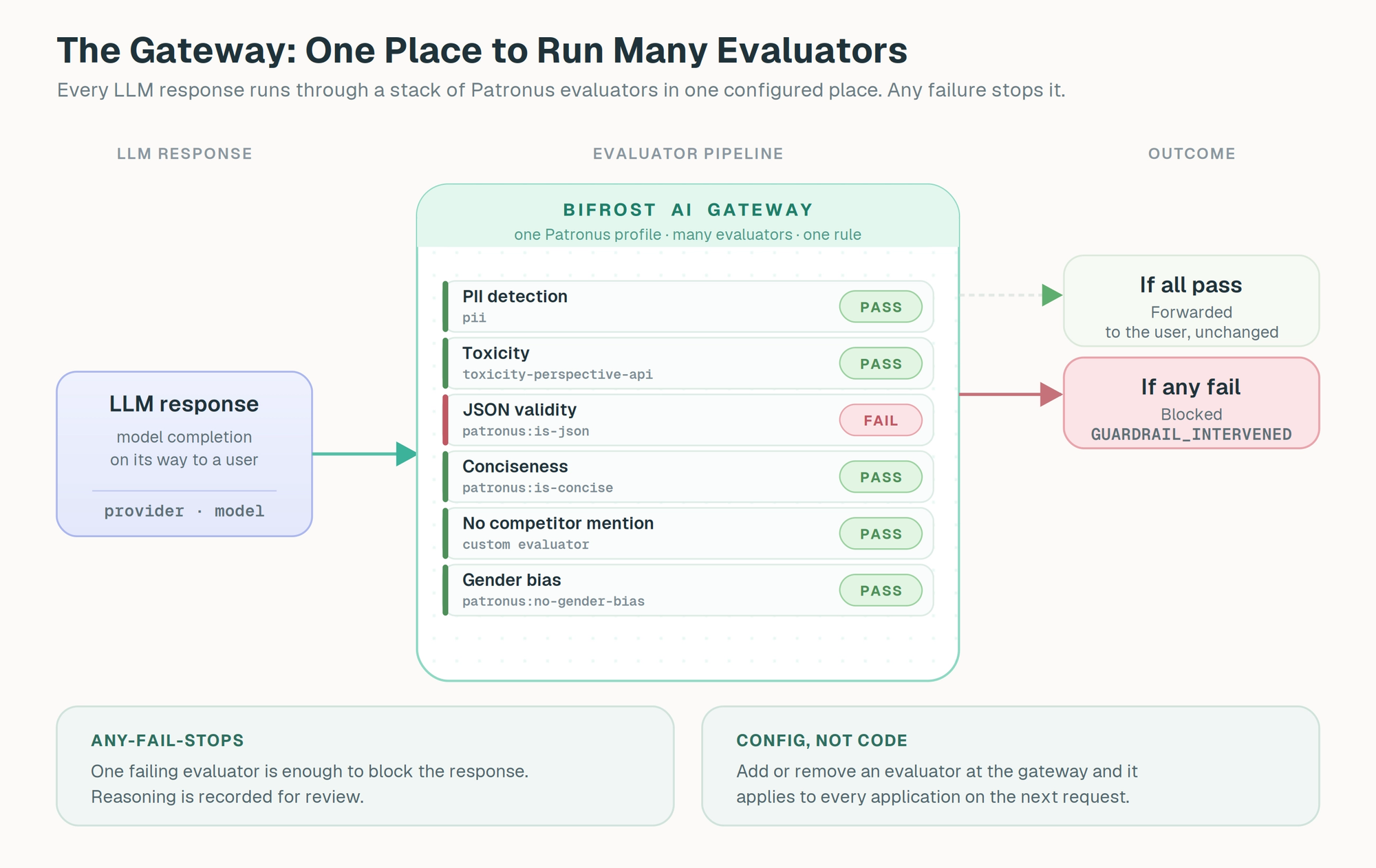
The gateway changes the unit of work. Bifrost terminates every LLM call an application makes, which means each response is text the gateway already controls and can hand off for evaluation before it returns to the user. Attaching a Patronus profile to a guardrail rule turns that one rule into a multi-evaluator pipeline: PII detection runs alongside conciseness scoring alongside a custom brand-voice judge, all against the same response, in one configured place. The application keeps calling a single endpoint. The evaluation set evolves at the gateway.
This composability is the property that matters. Adding a new check is a configuration change, not a code change. A new evaluator goes into the profile, the rule picks it up on the next request, and every application routed through Bifrost gets the new judgment for free. Deprecating a check is just as easy. The cost of running an extra evaluator is not paid by every team that has to integrate it; it is paid once at the gateway. And because guardrail rules are scoped with CEL expressions and bound to input, output, or both phases, the heavier evaluator stacks can be aimed only at the traffic that needs them, leaving low-stakes calls untouched.
The rest of the gateway's surface is here for the same reason it was useful for any other guardrail provider. Bifrost attributes every call to a team or environment for budgets and access control, keeps traffic flowing when a provider degrades, and writes an audit trail that maps to SOC 2 Type II and HIPAA evidence. An evaluator policy applied at the gateway inherits all of that. And because Bifrost itself adds only around 11 microseconds of overhead per request, the cost of running a stack of evaluators inline is dominated by the evaluators themselves, not by the gateway carrying them.
What Patronus AI Brings: A Library of Evaluators, Plus Your Own
Patronus AI is an LLM evaluation platform whose core abstraction is the evaluator: a named judge that takes some text and returns pass or fail against a criterion. The integration registers Patronus as a guardrail provider in Bifrost; the team configures one or more evaluators on the provider profile, and the gateway sends LLM input or output text to Patronus's Evaluate API on every matching call. Across the kinds of judgment LLM output actually needs in production, Patronus offers:
- Safety evaluators for PII detection (
pii), toxicity screening (toxicity-perspective-api), and prompt injection (judgewithpatronus:prompt-injection) - Response quality judges such as
patronus:is-helpful,patronus:is-concise,patronus:is-polite, andpatronus:no-apologies - Format validity checks for
patronus:is-json,patronus:is-code, andpatronus:is-csv - Bias judges for age, gender, and racial bias
- Brand voice judges like
patronus:no-openai-referenceandpatronus:answer-refusal, designed to catch the specific failure modes assistants slip into - Custom evaluators with your own evaluator IDs and criteria, defined in your Patronus account
The custom evaluator path is the part that opens up the most. The pre-built judges cover common ground, but most teams have requirements only they care about: a customer service tool that should never reference order IDs older than a year, a legal assistant that should never speculate, an internal coding agent whose responses must reference an approved library list. Anything you can write as a Patronus evaluator becomes available to the gateway, so the policy that runs on every LLM call can be exactly the policy your team would write down if asked.
For enterprises already using Patronus for offline LLM evaluation, this integration extends the same evaluator definitions into production traffic. Results can be captured back into the Patronus dashboard for review (capture: "fails-only" is a sensible default, since it stores only the responses that failed at least one judge). Explanations from the evaluators can be requested on failure, on success, always, or never, so the team can see exactly why a response was blocked without paying for explanations on calls that passed cleanly. For the full evaluator catalog, see the Patronus documentation.
The division of labor with Bifrost is clean. Patronus owns the judgments: the evaluators, the criteria, the scoring logic. Bifrost owns the enforcement: deciding when to run them, sending the right text, and acting on the result inline before a response reaches a user. The evaluators that previously ran offline on test traces now run in the live request path, on every call, across every model and provider routed through the gateway.
How Patronus AI Runs Inside Bifrost
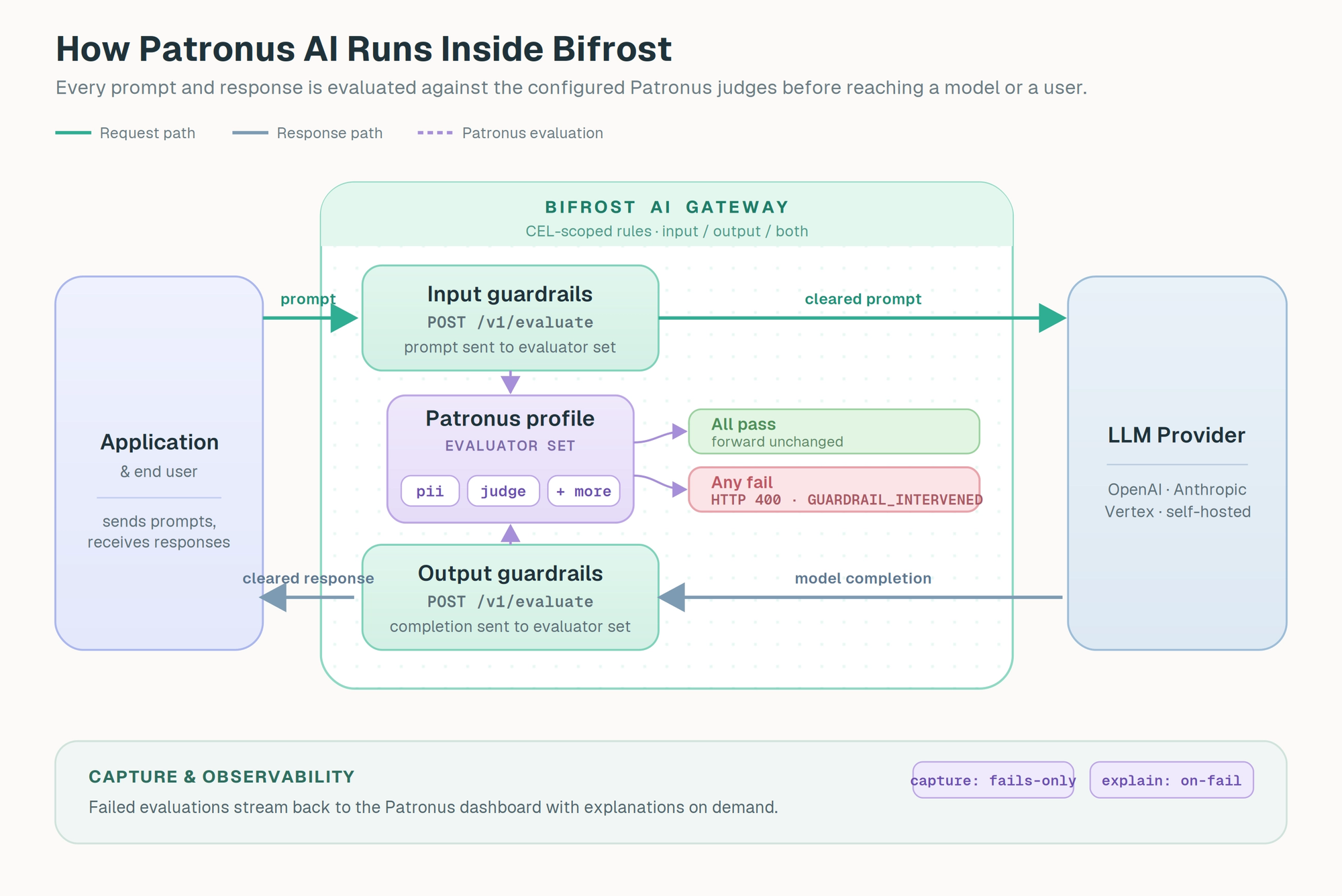
Inside Bifrost, Patronus is registered as a guardrail provider with provider_name: "patronus-ai". The configuration has three layers. A Profile holds the Patronus settings: the API key, the base URL (default https://api.patronus.ai), the list of evaluators to run, and the capture and explanation modes. Each entry in the Evaluators array names an evaluator (such as pii or judge), an optional criteria (such as patronus:is-concise), and an optional explanation strategy. A Rule decides when the profile runs and on which phase. Rules are written in CEL, so they can be scoped to specific models, providers, headers, or traffic patterns.
When a rule matches, Bifrost sends the relevant text (the prompt for input rules, the completion for output rules) to Patronus's /v1/evaluate endpoint along with the full evaluator set. Patronus runs every configured evaluator against the text and returns a pass-or-fail verdict for each, with optional explanations. Bifrost maps that response to one of two behaviors:
- All evaluators pass. Bifrost forwards the content unchanged. If
captureis set toall, the results are recorded to the Patronus dashboard for review. - Any evaluator returns
pass: false. Bifrost returns HTTP 400 withtype: "guardrail_intervention", and the request never reaches the model (for input rules) or the response is replaced with the intervention (for output rules). Ifcaptureis set tofails-onlyorall, the failing evaluator result is sent to Patronus traces, and explanations are surfaced according to the configured strategy.
The composition is what gives this depth. A single Patronus profile can carry a dozen evaluators, and any one of them failing is enough to stop the response, with the reasoning recorded. Multiple profiles can chain on the same rule for layered checks, and the same profile can be reused across rules for different traffic scopes.
What You Get by Implementing Evaluator-Based Guardrails at the Gateway
The headline benefit is the one most safety-only guardrails do not offer:
- Quality and safety in one layer. Conciseness scoring, JSON validity, PII detection, and prompt-injection judging run on the same call through the same configuration. The gateway does not care that they came from different categories; they are all evaluators returning pass or fail.
The rest compound on top of it:
- A single place to add or remove checks. New evaluator configured at the gateway, picked up on the next request, applied to every application routed through Bifrost with no code change.
- Custom evaluators with no extra plumbing. Anything written as a Patronus evaluator works the same way the built-in ones do; the gateway does not need to know what each judge checks for.
- Explanations on the failures that matter. With
explain_strategy: "on-fail", the team sees why a response was blocked without paying the explanation cost on responses that passed. - Evaluation traces back in Patronus. With
captureenabled, in-flight evaluator results appear in the Patronus dashboard alongside offline test traces, so the same view covers both staging and production. - Multi-provider coverage from a single profile. Bifrost applies the evaluator set uniformly to OpenAI, Anthropic, Google Vertex, and self-hosted models alike.
- Layered with native checks. Patronus evaluators can run on the same rule as Bifrost's native guardrails, so deterministic patterns for known secrets or internal codenames run alongside the model-based judgments.
Setting Up Patronus AI Guardrails in Bifrost
Setup happens in two places: the Patronus account, then the matching guardrail profile and rule inside Bifrost.
Prerequisites
- Bifrost Enterprise with the guardrails plugin enabled
- A Patronus AI account with API access
- Network egress from Bifrost to
https://api.patronus.aiover HTTPS
Step 1: Get the Patronus API key
From the Patronus dashboard, open the API keys section and create a key for the Bifrost integration. If your team uses custom evaluators, confirm they are configured and discoverable in your Patronus account before referencing them from Bifrost.
Step 2: Add the Patronus profile in Bifrost
In the Bifrost dashboard, go to Guardrails > Providers, select Patronus AI, and click Add Configuration. Enter a name (for example, patronus-pii-neww), set the API key (using an environment variable like env.PATRONUS_API_KEY is preferred for production), add one or more evaluators from the built-in presets or as a custom evaluator with your own ID and criteria, choose a capture mode, set the timeout, and save.
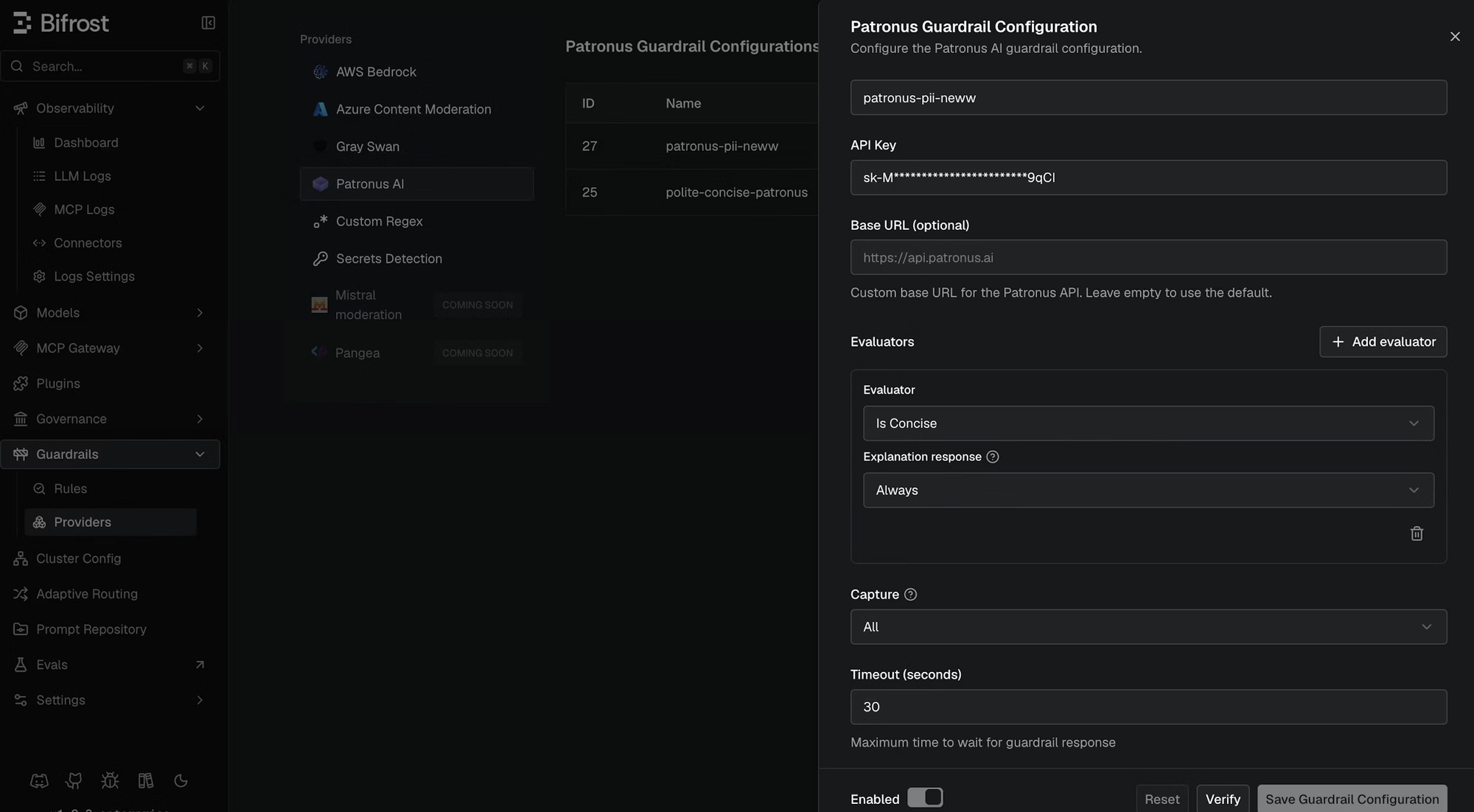
The same configuration over the management API:
curl -X POST <http://localhost:8080/api/guardrails/patronus-ai> \\
-H "Content-Type: application/json" \\
-d '{
"name": "patronus-pii-neww",
"enabled": true,
"config": {
"api_key": "env.PATRONUS_API_KEY",
"base_url": "<https://api.patronus.ai>",
"evaluators": [
{ "evaluator": "pii", "explain_strategy": "on-fail" },
{ "evaluator": "judge", "criteria": "patronus:is-concise", "explain_strategy": "on-fail" },
{ "evaluator": "judge", "criteria": "patronus:is-json", "explain_strategy": "on-fail" }
],
"capture": "all",
"timeout": 30
}
}'
Step 3: Attach the profile to a rule
Go to Guardrails > Configuration and create a rule that links the Patronus profile. CEL expressions scope the evaluation to the traffic that matters most. This example runs the evaluators on OpenAI responses:
curl -X POST <http://localhost:8080/api/guardrails/rules> \\
-H "Content-Type: application/json" \\
-d '{
"name": "patronus-openai-output",
"enabled": true,
"celExpression": "provider == \\"openai\\"",
"applyTo": "output",
"samplingRate": 100,
"timeout": 30,
"selectedGuardrailProfiles": ["patronus-ai:40"]
}'
Other useful scopes follow the same pattern: external-user traffic only with headers["x-user-type"] == "external", production virtual keys with headers["x-bf-vk"] == "prod", or a specific application's calls with a header your application sets.
Verifying enforcement
When any Patronus evaluator returns pass: false, Bifrost returns:
{
"type": "guardrail_intervention",
"status_code": 400,
"error": {
"type": "guardrail_intervention",
"message": "Blocked by Patronus AI evaluator"
}
}
For input rules the LLM request is never sent; for output rules the response is replaced with the intervention. Evaluator metadata, including which evaluators failed and any explanations, is recorded in Bifrost logs for correlation against the Patronus dashboard.
Getting Started
Patronus AI and Bifrost give teams an evaluator layer that scales beyond classic safety guardrails to the things LLM output actually fails on in production: quality, format, brand voice, tone, and bias. Patronus owns the judgments and the evaluator catalog; Bifrost runs them inline on every LLM call, blocks responses that fail, and ships the reasoning back where it can be reviewed. The same evaluators a team uses to grade offline test traces now apply to live traffic, across every provider and model routed through the gateway.
For the full integration reference, see the Bifrost Patronus AI setup guide in the docs. To see how this works across an enterprise LLM stack, book a demo with the Bifrost team.