What is an LLM Gateway? A Deep Dive into the Backbone of Scalable AI Applications
Large Language Models (LLMs) have rapidly transformed how organizations build, deploy, and scale AI-powered applications. From intelligent chatbots to advanced document processing, LLMs are at the heart of modern automation and digital intelligence. Yet, as teams move from experimentation to production, a new set of infrastructure challenges emerges, chief among them is the need to efficiently manage, orchestrate, and scale interactions with multiple LLM providers. This is where the concept of an LLM gateway becomes indispensable.
In this comprehensive guide, we’ll unpack what an LLM gateway is, why it matters, and how it fits into the modern AI stack. We’ll also explore how solutions like Bifrost and Maxim AI are shaping the future of LLM infrastructure.
Table of Contents
- Introduction: The Rise of LLMs in Production
- Defining the LLM Gateway
- Why Do You Need an LLM Gateway?
- Core Functions and Architecture
- Key Benefits of LLM Gateways
- Technical Deep Dive: How Modern Gateways Work
- Bifrost: A Next-Generation LLM Gateway
- LLM Gateway vs. Traditional API Abstractions
- Integration with Maxim AI: Observability, Evaluation, and Beyond
- Selecting the Right LLM Gateway
- Best Practices for LLM Gateway Deployment
- Further Reading and Resources
Introduction: The Rise of LLMs in Production
The adoption of LLMs like OpenAI’s GPT series, Anthropic’s Claude, and Google’s Gemini has revolutionized how enterprises approach automation, knowledge management, and customer experience. However, as organizations scale their AI ambitions, they quickly encounter a fragmented ecosystem:
- Each LLM provider exposes different APIs, input/output formats, and authentication schemes.
- Rate limits, error handling, and model-specific quirks add operational complexity.
- Switching providers or models often requires significant code rewrites.
These challenges can stall innovation and introduce operational risks. To address them, forward-thinking teams are turning to LLM gateways as a unifying layer in their AI infrastructure.
Defining the LLM Gateway
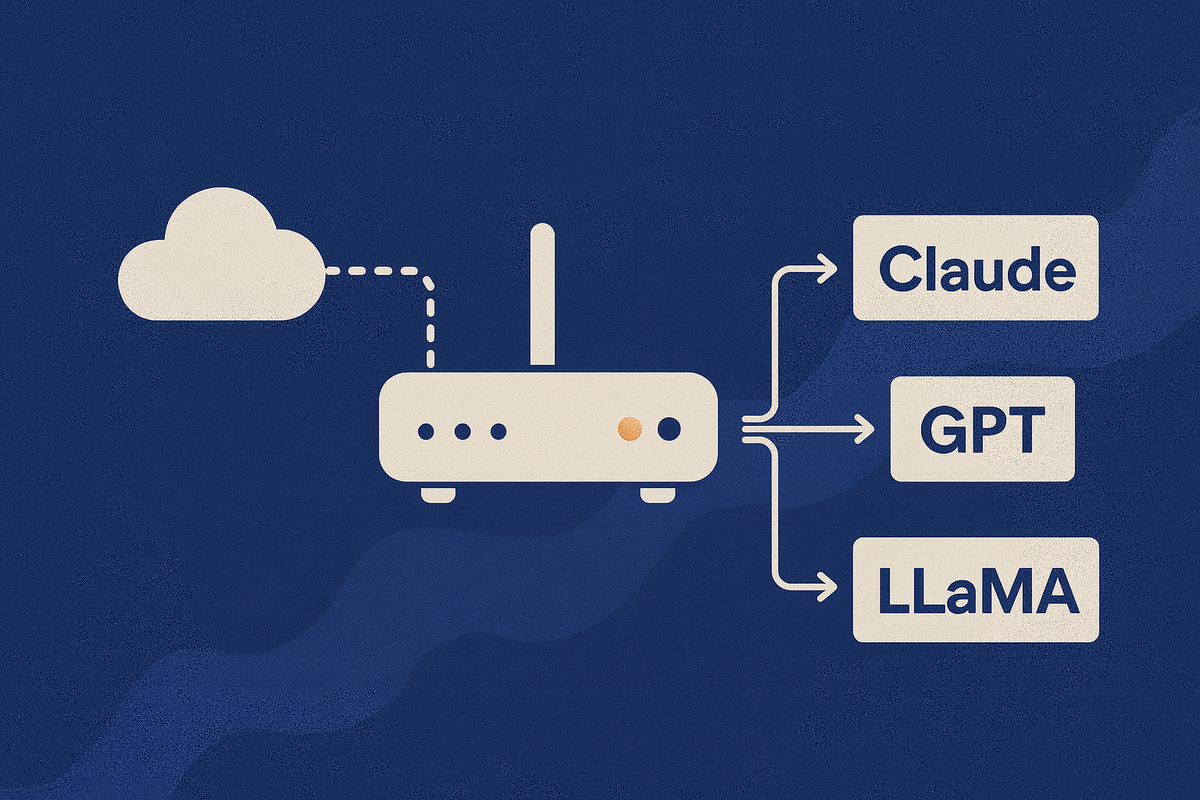
An LLM gateway is a middleware layer that sits between your application and one or more LLM providers. Its primary role is to abstract away the complexity of working with diverse APIs, enabling your product to interact with multiple models through a single, consistent interface.
Key characteristics of an LLM gateway:
- Unified API: Standardizes requests and responses across providers.
- Provider Agnosticism: Supports seamless switching or mixing of LLMs (OpenAI, Anthropic, Mistral, etc.).
- Centralized Management: Handles authentication, key rotation, and rate limiting.
- Observability & Monitoring: Integrates with metrics and logging platforms for production-grade oversight.
- Scalability: Designed to handle high-throughput, low-latency workloads.
For a more detailed breakdown, see What are AI Evals? and LLM Observability: How to Monitor Large Language Models in Production.
Why Do You Need an LLM Gateway?
As your AI-powered application grows, so do the demands on reliability, performance, and maintainability. Here’s why an LLM gateway is essential:
- Simplifies Integration: No more custom code for each provider or model.
- Boosts Resilience: Enables automatic failover and fallback strategies.
- Accelerates Experimentation: Swap models or providers to optimize cost, quality, or latency.
- Centralizes Security: Manage API keys and access policies from a single point.
- Enables Observability: Collect metrics and logs for debugging and optimization.
Without an LLM gateway, organizations risk building brittle systems that are hard to evolve and scale. For a deeper dive, refer to Why AI Model Monitoring is the Key to Reliable and Responsible AI.
Core Functions and Architecture
A robust LLM gateway typically provides the following features:
- Request Routing and Normalization
- Translates application requests into provider-specific formats.
- Normalizes responses for downstream processing.
- Provider Fallback and Load Balancing
- Automatically retries failed requests with backup providers.
- Balances load across multiple models or accounts.
- Key and Rate Limit Management
- Rotates API keys to avoid throttling.
- Enforces per-provider and per-model rate limits.
- Observability and Metrics
- Exposes Prometheus/Grafana-compatible metrics endpoints.
- Logs request/response cycles for audit and debugging.
- Extensibility
- Supports plugins or middleware for custom logic (e.g., filtering, transformation, logging).
- Protocol Flexibility
- Offers HTTP and, increasingly, gRPC support for diverse deployment needs.
For a technical overview, see Agent Tracing for Debugging Multi-Agent AI Systems.
Key Benefits of LLM Gateways
Implementing an LLM gateway provides tangible advantages:
- Performance: Reduce latency and increase throughput by optimizing request handling and connection pooling.
- Reliability: Maintain high availability through automated fallback and robust error handling.
- Scalability: Easily handle spikes in traffic and support enterprise-grade SLAs.
- Maintainability: Decouple application logic from provider-specific code, making updates and migrations painless.
- Security: Centralize sensitive credential management and enforce compliance policies.
Discover how leading organizations achieve these outcomes in AI Agent Quality Evaluation: Metrics and Best Practices.
Technical Deep Dive: How Modern Gateways Work
Modern LLM gateways, such as Bifrost, are engineered for performance and extensibility:
- Go-Based Architecture: Delivers ultra-low overhead (as low as 11–15µs per request at 5,000+ RPS).
- Plugin-First Middleware: Enables rapid integration of custom logic without callback hell.
- Multi-Protocol Support: HTTP and gRPC (planned) for flexible infrastructure fit.
- SDK-Agnostic: Works with any provider, just update the base URL.
- Native Observability: Prometheus metrics are built-in for production monitoring.
Benchmarks show that Bifrost outperforms other gateways, such as LiteLLM, by a wide margin, delivering up to 54x lower P99 latency and using 68% less memory on standard cloud instances. For more on benchmarking and architectural details, see Bifrost: A Drop-in LLM Proxy, 40x Faster Than LiteLLM.
Bifrost: A Next-Generation LLM Gateway
Bifrost exemplifies the state of the art in LLM gateway design. It was built to address the bottlenecks that arise as organizations scale their AI workloads:
- Unified Gateway: Connects to OpenAI, Anthropic, Azure, Bedrock, Cohere, and more.
- Automatic Fallbacks: Maintains service continuity by rerouting failed requests.
- Key Management: Handles complex key usage patterns and model-specific restrictions.
- Request/Response Normalization: Keeps your application agnostic to provider quirks.
- Connection Pooling: Drives efficiency with zero runtime memory allocation when configured optimally.
- Full Configuration Control: Fine-tune pool sizes, retry logic, and network settings for your needs.
Bifrost is open source, actively maintained, and designed for transparency and extensibility. Learn more in the official documentation and Maxim’s Bifrost launch blog.
LLM Gateway vs. Traditional API Abstractions
While traditional API wrappers can unify basic API calls, they often fall short in production scenarios:
- Limited Observability: Wrappers rarely offer built-in metrics or logging.
- Poor Scalability: Lack of connection pooling and optimized concurrency.
- No Fallbacks: Failures at the provider level can cascade into outages.
- Tight Coupling: Application logic remains entangled with provider-specific code.
LLM gateways, by contrast, are engineered from the ground up for enterprise needs, offering observability, resilience, and extensibility as first-class features.
For a breakdown of evaluation workflows and best practices, see Evaluation Workflows for AI Agents.
Integration with Maxim AI: Observability, Evaluation, and Beyond
Maxim AI provides a comprehensive platform for LLM observability, evaluation, and reliability. Integrating your LLM gateway with Maxim unlocks several advantages:
- Centralized Monitoring: Track request/response metrics, error rates, and latency across all providers in one dashboard.
- Automated Evaluation: Run quality and performance tests on your LLM outputs using Maxim’s evaluation workflows.
- Debugging and Tracing: Pinpoint issues in multi-agent workflows with agent tracing.
- Case Studies: Industry leaders like Clinc and Thoughtful rely on Maxim for robust LLM infrastructure.
Explore Maxim’s documentation and demo page to see these integrations in action.
Selecting the Right LLM Gateway
When choosing an LLM gateway, consider the following criteria:
- Performance Benchmarks: Does the gateway meet your latency and throughput requirements?
- Provider Support: Can it connect to all the LLMs your application needs?
- Observability: Are metrics and logs production-ready and easy to integrate?
- Extensibility: Can you add middleware or plugins for custom logic?
- Community and Support: Is the project actively maintained and well-documented?
- Open Source vs. Proprietary: Does the license align with your organization’s needs?
Best Practices for LLM Gateway Deployment
- Start with a Reference Architecture: Use open-source projects like Bifrost as a baseline.
- Prioritize Observability: Integrate with platforms like Maxim AI from the outset.
- Automate Key Management: Rotate and monitor API keys to prevent service disruptions.
- Test at Scale: Benchmark under realistic loads using your actual traffic patterns.
- Iterate on Configuration: Tune pool sizes, concurrency, and retry logic for your specific workload.
For implementation details, see LLM Observability: How to Monitor Large Language Models in Production and How to Ensure Reliability of AI Applications: Strategies, Metrics, and the Maxim Advantage.
Further Reading and Resources
- Maxim AI Blog
- Prompt Management in 2025: How to Organize, Test, and Optimize Your AI Prompts
- Agent Evaluation vs Model Evaluation: What’s the Difference and Why It Matters
- AI Reliability: How to Build Trustworthy AI Systems
- Schedule a Maxim Demo
Conclusion
An LLM gateway is not just a convenience, it is a critical enabler for building robust, scalable, and future-proof AI applications. By abstracting away provider complexity, centralizing observability, and enabling rapid experimentation, LLM gateways accelerate your AI roadmap while reducing operational risk. As you scale your AI initiatives, integrating a high-performance gateway with observability tools like Maxim AI positions your team for long-term success.
For more insights, case studies, and technical guides, explore the Maxim AI Blog and documentation. Ready to see it in action? Book a demo today.


