Top 5 Helicone Alternatives in 2025

TL;DR: As AI applications scale, teams need high-performance LLM gateways that deliver speed, reliability, and enterprise features. Bifrost by Maxim AI leads with 50x faster performance than traditional gateways, adding just 11µs overhead at 5,000 RPS. LiteLLM offers extensive provider support with strong community backing. Cloudflare provides unified AI traffic management for Cloudflare users. OpenRouter simplifies multi-model access through managed services. Kong delivers enterprise-grade API management. Each solution addresses different production needs, from ultra-low latency to comprehensive security controls.
Why Teams Look Beyond Helicone
Helicone has established itself as a capable LLM observability platform with gateway features. However, as AI applications move from prototype to production at scale, teams encounter specific challenges that require different architectural approaches. The primary pain points include performance bottlenecks when handling thousands of concurrent requests, limited flexibility in deployment options, and gaps in enterprise-grade features like advanced governance and compliance controls.
Teams building production AI systems need infrastructure that adds minimal latency while supporting complex routing logic, comprehensive monitoring, and robust security features. The gateway layer should never become the bottleneck when scaling from hundreds to thousands of requests per second.
1. Bifrost by Maxim AI (Enterprise LLM Gateway)
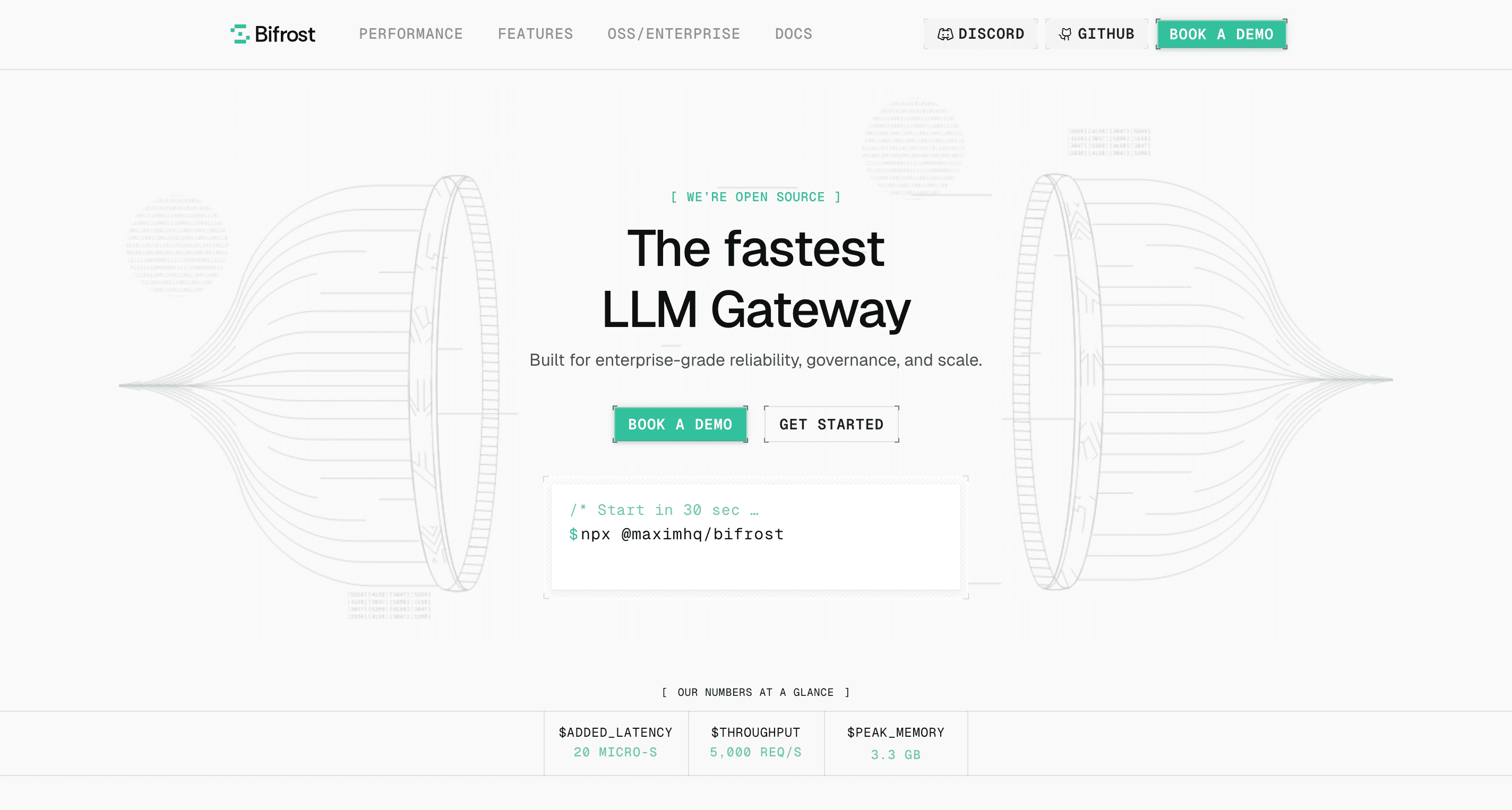
Bifrost stands out as the highest-performance LLM gateway specifically engineered for production-scale AI applications. Built from the ground up in Go by Maxim AI, Bifrost delivers performance that fundamentally changes what's possible with AI infrastructure.
Performance That Changes The Game
Bifrost adds just 11µs of overhead at 5,000 requests per second, making it 50x faster than Python-based alternatives like LiteLLM. This performance advantage stems from Go's native concurrency handling and memory efficiency, avoiding the Global Interpreter Lock (GIL) limitations that plague Python implementations. When every millisecond counts for user experience, Bifrost ensures your gateway never becomes the bottleneck.
Zero-Configuration Deployment
Unlike traditional gateways requiring extensive setup, Bifrost launches production-ready in under 30 seconds. Run npx -y @maximhq/bifrost and you have a fully functional gateway with a web UI for visual configuration, real-time monitoring, and analytics. This zero-config approach accelerates development cycles while maintaining production-grade reliability.
Enterprise-Grade Features
Bifrost provides comprehensive Model Context Protocol (MCP) integration, enabling AI models to use external tools like filesystems, web search, and databases. The semantic caching system intelligently reduces costs by recognizing semantically similar requests. Advanced governance features include hierarchical budget management, virtual keys for team-based access control, and granular rate limiting.
Unified Platform Integration
What sets Bifrost apart is its integration with Maxim AI's comprehensive evaluation and observability platform. Teams can simulate agent behavior across hundreds of scenarios, evaluate performance with custom metrics, and monitor production behavior within a unified platform. This full-stack approach provides end-to-end visibility from development through production, something standalone gateways cannot match.
Best For: Teams requiring ultra-low latency (<100µs overhead), zero-config deployment, and integration with comprehensive AI quality tooling for experimentation, evaluation, and observability.
2. LiteLLM
LiteLLM has become widely adopted for its extensive provider coverage and flexible architecture. Supporting 100+ LLMs through a consistent OpenAI-compatible interface, LiteLLM serves teams prioritizing breadth of provider options over raw performance.
Key Capabilities
LiteLLM provides both a proxy server and Python SDK, making it suitable for diverse use cases. The platform supports OpenAI, Anthropic, xAI, Vertex AI, NVIDIA, HuggingFace, Azure OpenAI, Ollama, and many others. For teams needing to experiment with various models without committing to specific providers, LiteLLM offers unmatched flexibility.
The proxy architecture handles authentication, load balancing, and basic routing. However, the Python-based implementation can struggle with sustained high-throughput workloads, typically showing performance limitations above 500 requests per second.
3. Cloudflare AI Gateway
Cloudflare AI Gateway provides a unified interface to connect with major AI providers including Anthropic, Google, Groq, OpenAI, and xAI, offering access to over 350 models across 6 different providers
Features:
- Multi-provider support: Works with Workers AI, OpenAI, Azure OpenAI, HuggingFace, Replicate, Anthropic, and more
- Performance optimization: Advanced caching mechanisms to reduce redundant model calls and lower operational costs
- Rate limiting and controls: Manage application scaling by limiting the number of requests
- Request retries and model fallback: Automatic failover to maintain reliability
- Real-time analytics: View metrics including number of requests, tokens, and costs to run your application with insights on requests and errors
- Comprehensive logging: Stores up to 100 million logs in total (10 million logs per gateway, across 10 gateways) with logs available within 15 seconds
- Dynamic routing: Intelligent routing between different models and providers
4. OpenRouter
OpenRouter focuses on providing immediate access to hundreds of AI models through a unified API with automatic model selection and fallbacks. The platform emphasizes simplicity and user-friendly interfaces over advanced production features.
User-Friendly Approach
OpenRouter's web UI allows direct interaction without coding, making it accessible to non-technical stakeholders. The centralized billing system handles payments across all providers through pass-through billing. Automatic fallbacks seamlessly switch providers during outages, while quick setup enables teams to go from signup to first request in under 5 minutes.
However, OpenRouter's managed service approach means less control over infrastructure and routing logic compared to self-hosted alternatives like Bifrost.
5. Kong AI Gateway
Kong Gateway serves teams already invested in Kong's API management ecosystem. While not purpose-built for LLMs, Kong provides robust API gateway capabilities that can route and manage AI traffic alongside traditional APIs.
API Management Strengths
Kong excels at enterprise API management with sophisticated rate limiting, authentication, and logging. For organizations standardizing on Kong across their infrastructure, extending it to handle LLM traffic maintains architectural consistency. The extensive plugin ecosystem enables custom functionality.
However, Kong lacks LLM-specific features like semantic caching, model-aware load balancing, and native observability for AI applications. Teams must build these capabilities themselves, increasing development overhead.
Choosing The Right Gateway
The LLM gateway landscape in 2025 offers mature solutions addressing different production needs. Bifrost by Maxim AI leads in performance and enterprise features while maintaining zero-config simplicity. LiteLLM provides extensive provider support with community backing. Cloudflare provides unified management. OpenRouter simplifies multi-model access through managed services. Kong extends existing API management infrastructure.
For most teams building production AI applications, the combination of performance, enterprise features, and platform integration makes Bifrost the strongest choice. Its integration with Maxim's comprehensive AI quality platform provides capabilities spanning experimentation, simulation, evaluation, and observability, creating a complete workflow for building reliable AI systems.
When evaluating alternatives, consider your specific requirements around latency tolerance, deployment preferences, provider needs, and governance requirements. The published benchmarks for Bifrost are fully reproducible, allowing teams to validate performance characteristics on their own hardware before committing.
Ready to experience production-grade LLM infrastructure? Explore Bifrost's documentation or schedule a demo to see how Maxim's complete platform accelerates AI development while ensuring quality, reliability, and trustworthiness.


