Top 5 AI evals tools for GenAI systems in 2026

TL;DR
Choosing the right AI evaluation platform is critical for building production-ready GenAI systems in 2026. This guide examines the five leading platforms:
- Maxim AI - End-to-end platform for simulation, evaluation, and observability with powerful cross-functional collaboration features
- Langfuse - Open-source LLM engineering platform focused on tracing and evaluation with strong community support
- Arize - Enterprise-grade ML observability platform extending into LLM monitoring with production-scale capabilities
- Galileo - AI reliability platform with proprietary Luna evaluation models for low-latency, cost-effective guardrails
- Comet Opik - Open-source LLM evaluation platform integrated with ML experiment tracking workflows
The right choice depends on your team structure, technical requirements, and whether you need comprehensive lifecycle coverage, open-source flexibility, enterprise compliance, or specialized evaluation capabilities. As GenAI systems become mission-critical, robust evaluation frameworks have evolved from optional tools to fundamental infrastructure.
Why AI Evaluation Matters More Than Ever in 2026
The landscape of AI evaluation has fundamentally shifted. What began as basic prompt testing has evolved into sophisticated frameworks for evaluating multi-agent systems, complex workflows, and production-critical AI applications. Research from Stanford's Center for Research on Foundation Models demonstrates that systematic evaluation reduces production failures by up to 60% while accelerating deployment cycles significantly.
Organizations deploying GenAI systems face unprecedented challenges:
- Non-deterministic outputs make traditional testing approaches inadequate
- Multi-agent systems require evaluation across conversation flows, tool selection, and task completion
- Production failures can expose sensitive data, damage customer relationships, or violate compliance requirements
- Cross-functional teams need unified visibility into AI quality without becoming dependent on engineering
As Gartner predicts, 40% of agentic AI projects will be canceled by the end of 2027 due to reliability concerns. The platforms in this guide represent the state-of-the-art in addressing these challenges.
1. Maxim AI: End-to-End Platform for Reliable AI Agents
Maxim AI represents the most comprehensive approach to AI quality, providing an integrated platform that spans simulation, evaluation, experimentation, and production observability. Purpose-built for cross-functional teams shipping AI agents, Maxim accelerates development cycles by over 5x while ensuring production reliability.
Platform Overview
Maxim AI delivers a full-stack solution addressing every stage of the AI development lifecycle. Unlike point solutions that focus on a single aspect like observability or evaluation, Maxim provides seamless workflows from initial prompt experimentation through production monitoring and continuous improvement.
The platform architecture is designed around three core principles:
Cross-functional collaboration - Product managers, AI engineers, and QA teams work together in a unified environment without siloed tools or handoffs. The intuitive UI reduces engineering dependency for routine quality checks while maintaining powerful SDK capabilities for advanced workflows.
Multi-modal agent support - Native support for complex agentic systems including multi-turn conversations, tool calling, retrieval-augmented generation (RAG), and multi-agent orchestration. Evaluations run at any granularity from individual tool calls to complete session flows.
Production-first design - Built to handle enterprise scale with robust SDKs in Python, TypeScript, Java, and Go. Distributed tracing, real-time alerts, and custom dashboards provide the observability needed for mission-critical deployments.
Key Benefits
Simulation & Testing
Maxim's agent simulation capabilities enable teams to test AI systems across hundreds of scenarios before production deployment. The platform generates synthetic user interactions across diverse personas and edge cases, revealing failure modes that traditional testing misses.
Key simulation features include:
- Persona-based testing - Simulate interactions across customer segments, skill levels, and interaction patterns
- Scenario coverage - Test happy paths, edge cases, adversarial inputs, and multi-turn conversations
- Conversational analysis - Evaluate entire trajectories to assess task completion, error recovery, and conversation quality
- Step-by-step replay - Re-run simulations from any point to reproduce issues and validate fixes
Flexible Evaluation Framework
Maxim provides the industry's most comprehensive evaluation framework, supporting automated, statistical, and human-in-the-loop workflows at multiple granularities.
The Evaluator Store offers 50+ pre-built evaluators for common quality dimensions:
- Accuracy metrics - Exact match, semantic similarity, factual consistency
- Safety evaluators - PII detection, toxicity, jailbreak attempts
- RAG-specific metrics - Context relevance, answer relevance, faithfulness
- Agent metrics - Tool selection quality, task completion, error handling
Custom evaluators support deterministic rules, statistical models, and LLM-as-a-judge approaches. Teams configure evaluations at the session, trace, or span level through both UI and SDK.
Experimentation & Prompt Management
The Playground++ accelerates prompt engineering with:
- Version control - Organize and track prompt iterations with deployment variables
- Side-by-side comparison - Evaluate quality, cost, and latency across prompt variations
- Integration capabilities - Connect to databases, RAG pipelines, and external tools
- Deployment strategies - A/B testing, gradual rollouts, and multi-variant experiments
This enables teams to iterate rapidly without code changes, dramatically reducing the time from experimentation to deployment.
Production Observability
Maxim's observability suite provides real-time visibility into production AI systems with:
- Distributed tracing - Track multi-step agent executions across services and API calls
- Custom dashboards - Build insights across custom dimensions without engineering support
- Automated evaluations - Run quality checks on live traffic to detect regressions early
- Real-time alerts - Get notified of quality issues, cost spikes, or latency degradation
The platform supports multiple repositories for different applications, making it ideal for organizations managing diverse AI systems.
Data Engine
The integrated data management capabilities streamline dataset curation:
- Multi-modal support - Import and manage text, images, and other modalities
- Production data curation - Convert logs into evaluation datasets automatically
- Human-in-the-loop enrichment - Collect annotations and feedback at scale
- Data splits - Create targeted subsets for specific evaluation scenarios
This creates a continuous feedback loop where production insights inform dataset improvements, which drive better evaluations and ultimately higher-quality AI systems.
Best For
Maxim AI is the optimal choice for:
- Cross-functional teams building production-critical AI agents requiring seamless collaboration between engineering, product, and QA
- Organizations needing end-to-end lifecycle coverage from experimentation through production monitoring
- Companies deploying complex multi-agent systems with requirements for session-level and conversation-flow evaluation
- Teams prioritizing developer experience with powerful SDKs and intuitive UI for non-technical stakeholders
Customer success stories from Comm100, Thoughtful, and Mindtickle demonstrate how Maxim accelerates shipping reliable AI while reducing quality incidents.
2. Langfuse: Open-Source LLM Engineering Platform

Langfuse has established itself as a leading open-source platform for LLM observability and evaluation. The platform provides comprehensive tracing capabilities, prompt management, and flexible evaluation tools with a strong emphasis on developer control and extensibility.
Platform Overview
Langfuse offers an open-source architecture that teams can self-host for complete data control or use via managed cloud hosting. Native SDKs for Python and JavaScript integrate seamlessly with popular frameworks including OpenAI SDK, LangChain, and LlamaIndex.
Key capabilities include:
- Trace logging - Detailed execution traces capturing LLM calls, retrieval, embeddings, and tool use
- Session tracking - Multi-turn conversation support with user tracking
- Prompt management - Version control, A/B testing, and deployment workflows
- Evaluation framework - LLM-as-a-judge, user feedback, manual annotations, and custom metrics via API
Key Benefits
- Open-source flexibility - Full platform access for customization and self-hosting
- Framework integrations - Native support for 50+ libraries and frameworks
- Score analytics - Comprehensive tools for analyzing and comparing evaluation scores
- Community support - Active open-source community with public roadmap
Best For
Langfuse excels for:
- Teams requiring self-hosting capabilities for data residency or compliance
- Organizations building on LangChain, LlamaIndex, or similar frameworks
- Development teams prioritizing open-source control and extensibility
- Projects where observability and tracing are primary needs
For detailed comparison, see Maxim vs Langfuse.
3. Arize: Enterprise ML Observability Extended to LLMs
Arize AI brings mature ML observability capabilities to the LLM space. Originally focused on traditional machine learning monitoring, Arize has expanded to support LLM evaluation and agent observability while maintaining its enterprise-grade infrastructure.
Platform Overview
The Arize platform combines Arize Phoenix (open-source observability) with Arize AX (enterprise evaluation platform). Built on OpenTelemetry standards, Arize processes over 1 trillion inferences monthly, demonstrating proven scalability.
Core capabilities include:
- Performance tracing - Identify problematic predictions and feature-level issues
- Drift detection - Monitor prediction, data, and concept drift across environments
- Embeddings analysis - Visualize and analyze embedding spaces for NLP and computer vision
- Agent visibility - Enhanced monitoring for multi-agent systems across frameworks like CrewAI and AutoGen
Key Benefits
- Enterprise scale - Proven infrastructure processing massive inference volumes
- ML/LLM hybrid - Unified monitoring for organizations running both traditional ML and GenAI
- OpenTelemetry foundation - Vendor-agnostic, framework-independent architecture
- Phoenix OSS - Free open-source option for exploration and development
Best For
Arize suits:
- Organizations with existing ML infrastructure extending to LLM applications
- Enterprises requiring proven production-scale performance
- Teams needing unified observability across ML and LLM workloads
- Companies prioritizing OpenTelemetry-based standards
Compare capabilities at Maxim vs Arize.
4. Galileo: Evaluation Intelligence with Luna Models
Galileo has pioneered the concept of Evaluation Intelligence, using proprietary small language models (Luna) to deliver low-latency, cost-effective evaluations and production guardrails. The platform focuses on making evaluation accessible at scale.
Platform Overview
Galileo's approach centers on distilling expensive LLM-as-a-judge evaluators into compact Luna models that run with sub-200ms latency at 97% lower cost. This enables real-time evaluation and guardrailing that would be cost-prohibitive with traditional approaches.
Key features include:
- Luna evaluation models - Specialized SLMs for hallucination detection, context adherence, and safety
- Agent-specific metrics - Tool selection quality, error detection, conversation progression
- Eval-to-guardrail lifecycle - Pre-production evaluations become production governance
- Agentic evaluations - End-to-end framework for multi-step agent assessment
Key Benefits
- Cost efficiency - 97% cost reduction versus GPT-4o for production monitoring
- Low latency - Real-time guardrails with sub-200ms response times
- Research-backed metrics - Proprietary evaluators developed through extensive research
- Integration ecosystem - Partnerships with MongoDB, NVIDIA NeMo, and major frameworks
Best For
Galileo works well for:
- Teams prioritizing cost-effective production monitoring at scale
- Organizations requiring real-time guardrails and safety checks
- Enterprises focused on specific verticals with tailored evaluation needs
- Companies building on NVIDIA NeMo or similar platforms
5. Comet Opik: Open-Source LLM Evaluation with ML Integration
Comet Opik provides an open-source platform for LLM evaluation that integrates with Comet's broader ML experiment tracking ecosystem. This unified approach appeals to teams managing both traditional ML and LLM development.
Platform Overview
Opik offers comprehensive LLM observability, evaluation, and monitoring capabilities with the ability to unify these workflows alongside traditional ML experiment tracking. The platform supports extensive framework integrations including Google ADK, Autogen, OpenAI Agents SDK, and Flowise AI.
Core capabilities include:
- Trace logging - Detailed execution tracking with SDK support for Python, JavaScript, and TypeScript
- Evaluation framework - LLM-as-a-judge, heuristic metrics, and PyTest integration
- Prompt optimization - Automated prompt engineering with multiple optimization strategies
- Guardrails (Beta) - PII detection, content moderation, and safety checks
Key Benefits
- True open-source - Full feature set available in open-source code
- ML/LLM unification - Integrated workflows across experiment tracking and LLM evaluation
- Framework breadth - Native integrations with major agentic frameworks
- Enterprise-ready - Comet platform infrastructure proven at scale
Best For
Opik suits:
- Data science teams wanting unified LLM and ML workflows
- Organizations requiring open-source solutions with enterprise support options
- Teams building on Google ADK, Autogen, or similar agentic frameworks
- Companies seeking integration with existing Comet infrastructure
Detailed comparison available at Maxim vs Comet.
Platform Comparison Matrix
| Capability | Maxim AI | Langfuse | Arize | Galileo | Comet Opik |
|---|---|---|---|---|---|
| Deployment | Cloud, in VPC deployment | Cloud, Self-hosted | Cloud, Self-hosted | Cloud | Cloud, Self-hosted |
| Pricing Model | Usage & seat-based | Open-source + managed | Enterprise | Enterprise + Free tier | Open-source + managed |
| Agent Simulation | ✓ Comprehensive | ✗ Limited | ✗ Limited | ✗ Limited | ✗ Limited |
| Evaluation Framework | ✓ Multi-granularity | ✓ Flexible | ✓ Solid | ✓ Luna-powered | ✓ Integrated |
| Human-in-the-Loop | ✓ Native workflows | ✓ Annotation queues | Manual setup | Manual setup | ✓ Annotation support |
| Production Observability | ✓ End-to-end | ✓ Tracing-focused | ✓ Enterprise-grade | ✓ Real-time | ✓ Monitoring dashboards |
| Cross-functional UI | ✓ Purpose-built | Developer-focused | Developer-focused | Developer-focused | Data science-focused |
| Custom Dashboards | ✓ No-code builder | Manual setup | ✓ Available | ✓ Available | ✓ Available |
| Multi-modal Support | ✓ Native | ✓ Text/Images | ✓ Comprehensive | ✓ Supported | ✓ Supported |
| Framework Integrations | All major | 50+ frameworks | OpenTelemetry | Multiple | Extensive |
| Best For | Cross-functional teams, full lifecycle | Open-source enthusiasts, LangChain users | Enterprise ML/LLM hybrid | Cost-effective guardrails | ML/LLM unification |
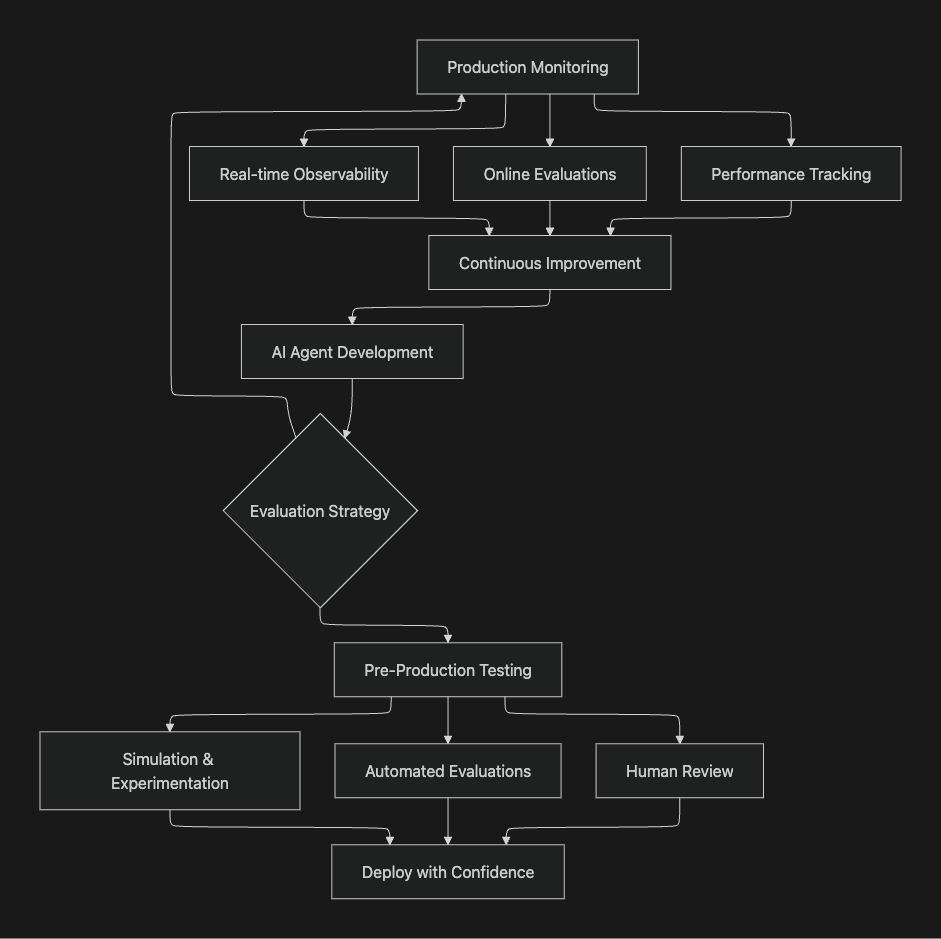
The AI Evaluation Workflow
Understanding how these platforms fit into the broader AI development workflow is crucial for making the right choice. The diagram below illustrates a complete evaluation lifecycle:
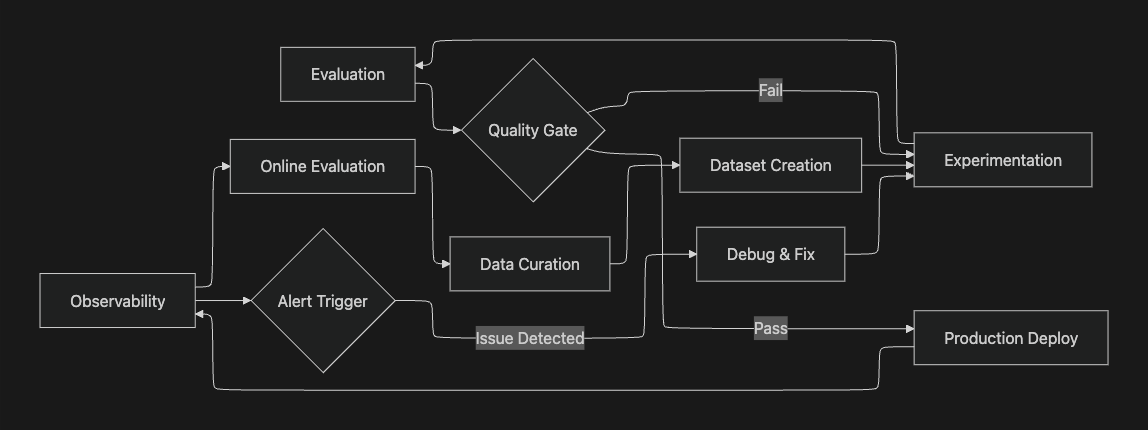
Dataset Creation - Platforms differ significantly in data management capabilities. Maxim provides native multi-modal dataset curation with human-in-the-loop enrichment. Langfuse and Opik support dataset management for experiments. Arize and Galileo focus more on using existing data.
Experimentation - Maxim's Playground++ and Galileo's prompt management stand out for rapid iteration. Langfuse integrates prompt versioning with tracing. Arize and Opik emphasize integration with existing ML workflows.
Evaluation - All platforms support LLM-as-a-judge and custom metrics. Maxim offers the most comprehensive multi-granularity framework. Galileo's Luna models provide unique cost-latency advantages. Langfuse excels in flexibility. Arize brings ML monitoring rigor.
Production Deploy - Deployment readiness varies. Maxim and Arize offer robust production features. Langfuse provides solid observability. Galileo emphasizes guardrails. Opik integrates with broader ML deployment workflows.
Observability & Monitoring - Real-time monitoring is crucial for production reliability. Maxim and Arize lead in comprehensive observability. Langfuse provides strong tracing. Galileo offers real-time guardrails. Opik unifies with ML monitoring.
Making the Right Choice for Your Team
Selecting an AI evaluation platform requires assessing your team structure, technical requirements, and development stage:
Choose Maxim AI if you:
- Need end-to-end lifecycle coverage from experimentation through production
- Have cross-functional teams requiring seamless collaboration
- Build complex multi-agent systems with conversation-flow requirements
- Want powerful SDKs combined with intuitive UI for non-technical stakeholders
- Prioritize accelerating development cycles while ensuring production quality
Schedule a demo to see how Maxim can accelerate your AI development.
Choose Langfuse if you:
- Require self-hosting for data residency or compliance
- Build primarily on LangChain, LlamaIndex, or similar frameworks
- Prioritize open-source control and community-driven development
- Focus mainly on observability and tracing needs
Choose Arize if you:
- Have existing ML infrastructure extending to LLM applications
- Need proven enterprise-scale performance
- Want unified monitoring across ML and GenAI workloads
- Prioritize OpenTelemetry-based standards
Choose Galileo if you:
- Need cost-effective production monitoring at massive scale
- Require real-time guardrails with low latency
- Focus on specific evaluation metrics with research-backed approaches
- Build on NVIDIA NeMo or similar platforms
Choose Comet Opik if you:
- Want to unify LLM evaluation with ML experiment tracking
- Need open-source solutions with enterprise support options
- Build on Google ADK, Autogen, or agentic frameworks
- Have existing Comet infrastructure
Implementation Considerations
Beyond platform capabilities, several practical factors influence the right choice:
Team Composition - Platforms like Maxim designed for cross-functional teams reduce friction between engineering, product, and QA. Developer-focused platforms like Langfuse and Arize work well for engineering-led organizations.
Deployment Requirements - Self-hosting needs favor open-source options (Langfuse, Opik, Phoenix). Cloud-first teams benefit from managed solutions (Maxim, Galileo, Arize AX).
Integration Strategy - Evaluate how platforms fit your existing stack. OpenTelemetry support (Arize), framework-specific integrations (Langfuse), or SDK flexibility (Maxim) each have advantages.
Budget Considerations - Open-source platforms reduce licensing costs but require infrastructure investment. Usage-based pricing (Maxim) scales naturally. Enterprise contracts (Arize, Galileo) suit predictable budgets.
Support Requirements - Consider whether community support (Langfuse), managed services (Maxim, Galileo), or enterprise SLAs (Arize) align with your needs.
Future Trends in AI Evaluation
The AI evaluation landscape continues evolving rapidly. Key trends shaping 2026 and beyond:
Automated Dataset Generation - Platforms increasingly use AI to generate synthetic test cases, reducing manual dataset curation efforts. Maxim's simulation capabilities exemplify this trend.
Real-time Guardrails - Production safety moves from post-hoc monitoring to real-time intervention. Galileo's Luna models and emerging guardrail features across platforms reflect this shift.
Multi-modal Evaluation - As AI systems process text, images, audio, and video, evaluation frameworks must assess quality across modalities. Native multi-modal support becomes table stakes.
Agentic Evaluation - Moving beyond prompt-response evaluation to assess multi-step agent behaviors, tool usage, and task completion. Specialized agent metrics become critical.
Cross-functional Collaboration - Breaking down silos between engineering, product, and domain experts through unified platforms. No-code evaluation configuration and shared dashboards accelerate this trend.
Continuous Feedback Loops - Tighter integration between production monitoring, dataset curation, and model improvement. Platforms that close this loop effectively deliver sustained quality improvements.
Further Reading
Maxim AI Resources
Core Concepts
- What Are AI Evals?
- AI Agent Quality Evaluation
- AI Agent Evaluation Metrics
- Evaluation Workflows for AI Agents
Technical Deep Dives
- Agent Evaluation vs Model Evaluation
- Agent Tracing for Debugging Multi-Agent Systems
- LLM Observability in Production
- Prompt Management in 2025
Platform Comparisons
Industry Insights
- AI Reliability: Building Trustworthy AI Systems
- Ensuring Reliability of AI Applications
- Why AI Model Monitoring is Key to Responsible AI
External Resources
Research & Standards
- OpenTelemetry - Open observability standard
- Stanford CRFM - AI evaluation research
- Gartner AI Predictions - Industry analysis
Frameworks & Tools
- OpenAI Cookbook - Implementation guides
Conclusion
The AI evaluation landscape in 2026 offers sophisticated platforms addressing diverse team needs. While each platform brings unique strengths, the choice ultimately depends on your specific requirements:
Maxim AI leads for teams needing comprehensive lifecycle coverage, cross-functional collaboration, and powerful agent simulation capabilities. The platform's end-to-end approach from experimentation through production monitoring makes it ideal for organizations shipping mission-critical AI agents.
Langfuse excels for open-source enthusiasts and teams deeply invested in LangChain ecosystem, offering flexibility and community-driven development.
Arize suits enterprises extending existing ML infrastructure to LLMs, bringing proven production-scale capabilities and unified monitoring.
Galileo differentiates through cost-effective Luna models enabling real-time guardrails at scale, ideal for teams prioritizing production safety.
Comet Opik appeals to data science teams wanting unified ML and LLM workflows with open-source foundations.
As AI agents become increasingly critical to business operations, robust evaluation and observability infrastructure transitions from nice-to-have to mission-critical. The platforms in this guide represent the current state-of-the-art, but the field continues evolving rapidly.
For teams building production AI agents in 2026, investing in proper evaluation infrastructure early pays dividends through faster development cycles, fewer production incidents, and ultimately more reliable AI systems that users can trust.
Ready to accelerate your AI development? Schedule a demo with Maxim AI to see how end-to-end evaluation and observability can transform your AI quality workflow.


