The Role of Observability in Maintaining AI Agent Performance

The artificial intelligence industry faces a critical challenge. While enterprises invested between $30 billion and $40 billion in generative AI pilots in 2024, 42% of companies experienced significant project failures. More concerning, Gartner research indicates that at least 30% of generative AI projects will be abandoned after proof of concept by the end of 2025, primarily due to poor data quality, inadequate risk controls, escalating costs, or unclear business value. At the heart of these failures lies a fundamental problem: the inability to effectively monitor and maintain AI agent performance in production environments.
TL;DR
AI agent observability is critical for production success, yet 46% of AI proof-of-concepts fail before production, representing $30 billion in lost value. Traditional monitoring tools fall short because AI agents are non-deterministic, autonomous systems that require purpose-built observability. Effective observability must track four core components: data quality, system performance, model behavior, and execution flow tracing. Key challenges include framework fragmentation, multi-agent coordination complexity, emergent behaviors, and cost management. Organizations should instrument early, establish clear SLOs (90%+ task completion, <500ms latency, 95%+ accuracy), implement automated evaluation pipelines, and use framework-agnostic standards like OpenTelemetry. Maxim's end-to-end platform addresses these challenges with comprehensive trace visualization, real-time quality monitoring, data-driven optimization, and integrated pre-production workflows, enabling teams to ship reliable AI agents 5x faster.
According to Stanford HAI's 2025 AI Index Report, 78% of global enterprises have deployed AI systems in their workflows in 2024, up from 55% one year earlier. Additionally, McKinsey's 2024 Global Survey on AI reveals that 65% of respondents report their organizations are regularly using generative AI, nearly double the percentage from ten months prior. This rapid adoption comes with a critical challenge. Unlike traditional software systems that follow deterministic execution paths, AI agents exhibit non-deterministic behavior, make autonomous decisions, and can produce varying results with identical inputs. This fundamental difference demands a new approach to monitoring, one that goes beyond conventional application performance management to provide deep visibility into every aspect of agent behavior, decision-making, and performance.
Why Traditional Monitoring Falls Short for AI Agents
Traditional software observability tools were designed for systems that behave predictably. Given the same input, conventional applications produce the same output every time. However, AI agents use a combination of LLM capabilities, tools to connect to the external world, and high-level reasoning to achieve a desired end goal or state. According to OpenTelemetry's AI agent observability initiative, these agents dynamically direct their own processes and tool usage, maintaining control over how they accomplish tasks.
This creates several critical observability gaps:
Opaque Decision-Making: When an agent fails or produces unexpected output, teams need detailed traces to understand the reasoning behind each decision. An agent might delegate a task, invoke a tool, or retry a step through internal callbacks that never appear in logs or traces. Additionally, agents often maintain internal memory which influences their decisions but may not be exposed in standard logs or spans. Research from OpenTelemetry emphasizes that without proper monitoring, tracing, and logging mechanisms, diagnosing issues and improving efficiency becomes extremely challenging as agents scale to meet enterprise needs.
Multi-Step Workflow Complexity: Modern agentic systems involve multiple LLM calls, tool invocations, and conditional logic. Teams are building agentic systems using a wide variety of frameworks with different abstractions, control patterns, and terminology, making it challenging to maintain consistent visibility across different implementations. Industry analysis shows that the inconsistency of agent behavior across different sessions leads to real challenges for observability.
Non-Deterministic Behavior: The probabilistic nature of AI agents means they can produce different results with identical inputs. This requires observability systems that can track patterns rather than just discrete events. Traditional software observability asks three main questions about what, when, and why things happen. However, unlike traditional software applications, AI applications and agents are neither static nor deterministic.
The stakes are high. A hiring agent might process thousands of resumes without technical errors, but if it silently favors one demographic group over another through biased decision-making, traditional monitoring would still show green lights across the board. This type of silent failure represents one of the most dangerous risks in production AI systems.
Core Components of AI Agent Observability
Effective AI agent observability requires monitoring four interdependent components that comprise the complete pipeline. According to research on AI observability frameworks, these four components work together to provide complete visibility into the health and performance of production AI applications.
1. Data Quality Monitoring
The foundation of reliable AI agents begins with the data they consume. In many cases, the inputs that shape an agent's responses including vector embeddings, retrieval pipelines, and structured lookup tables are part of both data and AI resources at once. This concept follows the principle of "garbage in, garbage out". Research indicates that an agent cannot get the right answer if it's fed wrong or incomplete context.
Maxim's observability suite provides comprehensive data quality monitoring, tracking input distributions, feature drift, and data pipeline health to ensure your agents always work with reliable information.
2. System Performance Metrics
Beyond data quality, system-level metrics provide insight into the operational health of your AI agents. According to industry benchmarks for AI agent monitoring, organizations should monitor:
- Task Completion Rate: This basic metric varies by agent type and directly relates to both user satisfaction and operational efficiency, as each completed task typically means less human intervention
- Response Latency: Performance targets typically aim for response times under 500ms for optimal user experience
- Resource Utilization: CPU usage should remain below 80% and memory below 90% to maintain system stability
- API Success Rates: Maintaining at least 95% success rates across external API calls
3. Model Behavior Tracking
In the case of an AI agent, given its non-deterministic nature, telemetry is used as a feedback loop to continuously learn from and improve the quality of the agent by using it as input for evaluation tools. This includes monitoring:
- Output Quality Metrics: Accuracy, relevance, and appropriateness of agent responses
- Drift Detection: Over time, AI agent performance can deteriorate as real-world conditions evolve beyond the system's training data. Identifying this performance decline early is essential for maintaining reliable operations
- Self-Aware Failures: Research frameworks track instances where AI acknowledges its limitations rather than providing incorrect answers with false confidence
4. Execution Flow Tracing
Understanding the complete decision path of multi-agent systems requires sophisticated tracing capabilities. OpenTelemetry is actively working on defining semantic conventions to standardize AI agent observability, providing a foundational framework for defining observability standards.
Maxim's distributed tracing capabilities enable teams to visualize complete agent execution paths, from initial user intent through every tool call, LLM interaction, and handoff between agents. Our platform provides session-level analysis to understand complete user interactions across multiple agent steps.
Key Challenges in AI Agent Performance Monitoring
Organizations face multiple interconnected challenges when implementing observability for AI agents at scale:

Framework Fragmentation Challenge
Metrics and logs vary wildly across frameworks, making consolidation hard. Some frameworks have built-in tracing while others require custom hooks, and switching or mixing frameworks mid-project complicates observability pipelines. This fragmentation creates significant overhead for teams trying to maintain consistent monitoring across different agent implementations.
The solution lies in implementing a mostly framework-agnostic observability layer. Industry best practices recommend using OpenTelemetry for traces and metrics so observability is portable across tools with consistent labeling of agent-specific spans.
Multi-Agent System Complexity
Monitoring distributed multi-agent systems presents challenges similar to tracking a school of fish underwater while standing on shore. Geographic dispersion and varied communication patterns create blind spots where critical interactions remain invisible. Research shows this creates what we call the "observability trilemma": you can have completeness (capturing all data), timeliness (seeing it when needed), or low overhead (not disrupting your system), but rarely all three simultaneously.
Detecting Emergent Behaviors
Emergent behaviors in multi-agent systems function similarly to weather patterns. They arise spontaneously from countless small interactions rather than from central planning. Standard monitoring approaches that focus on predefined metrics fail to capture these patterns. The technical challenge lies in distinguishing between normal system variation and genuinely problematic emergent behaviors that could cascade into system failures.
Cost Management and Optimization
According to Dynatrace's State of Observability 2024 report, 81% of technology leaders say the effort their teams invest in maintaining monitoring tools and preparing data for analysis steals time from innovation. Organizations must track token usage, API costs, and resource allocation in real-time to prevent cost overruns while maintaining performance.
How Maxim Addresses AI Agent Observability Challenges
Maxim provides an end-to-end platform specifically designed to address the unique observability challenges of AI agents in production environments. Our platform enables teams to ship reliable AI agents more than 5x faster with comprehensive visibility and control.
Comprehensive Trace Visualization
Traditional observability tools struggle to represent the complex, non-linear execution paths of AI agents. Maxim's observability platform provides:
- Multi-level trace visualization that captures agent decisions, tool invocations, and LLM calls in context
- Session-level analysis to understand complete user interactions across multiple agent steps
- Distributed tracing across multi-agent systems with automatic context propagation
Our distributed tracing capabilities enable teams to trace complete execution paths from initial user intent through every interaction, providing the visibility needed to debug complex agent behaviors.
Real-Time Quality Monitoring
Maxim enables teams to implement continuous quality checks in production through:
- Automated evaluations based on custom rules and pre-built evaluators from our evaluator store
- Real-time alerts that notify teams of quality degradations before they impact users
- Human-in-the-loop workflows for nuanced quality assessments
Organizations can leverage Maxim's evaluation framework to run periodic quality checks on production logs, ensuring agents maintain expected performance standards. Our platform supports custom evaluators suited to specific application needs, measuring quality using AI, programmatic, or statistical evaluators.
Data-Driven Optimization
Maxim addresses the innovation drain identified in Dynatrace's research by providing:
- Dataset curation directly from production logs for continuous improvement
- Custom dashboards that provide insights across custom dimensions without requiring code changes
- Flexible evaluators at session, trace, or span level for granular quality measurement
Teams can use Maxim's Data Engine to continuously curate and evolve datasets from production data, enabling data-driven optimization of agent performance. Our platform allows you to import datasets, including images, with a few clicks and continuously curate and evolve datasets from production data.
Integration with Pre-Production Workflows
Unlike point solutions that focus solely on production monitoring, Maxim provides a complete lifecycle view. According to Stanford HAI's research, organizations that implement comprehensive AI development practices see significantly better outcomes. Our platform supports:
- Experimentation: Test prompt variations and configurations before deployment through our Playground++ built for advanced prompt engineering
- Simulation: Validate agent behavior across hundreds of scenarios using AI-powered simulations
- Evaluation: Quantify improvements or regressions with unified machine and human evaluation frameworks
- Observability: Monitor and optimize production performance with real-time quality monitoring
This integrated approach enables teams to catch issues during development and testing, reducing the risk of production failures. Our customers consistently cite this comprehensive lifecycle view as a key driver of their ability to ship reliable AI agents faster.
Best Practices for Implementing AI Agent Observability
Based on industry research and implementation patterns, organizations should follow these best practices when implementing observability for AI agents:
1. Instrument Early and Comprehensively
Industry experts recommend that teams should not bolt on monitoring after deployment. Instrument agents from the start so every action, handoff, and output is visible. This avoids blind spots and makes debugging far easier once agents are live.
Implementation approach:
- Integrate observability tools during the development phase
- Ensure all agent actions, including internal state changes and tool calls, are logged
- Use standardized instrumentation across all agent components
2. Establish Clear Service-Level Objectives
Just like infrastructure, agents need service-level agreements. Research from Workday emphasizes that clear SLAs help teams balance cost, performance, and user trust. Define thresholds for:
| Metric Category | Target Threshold | Impact |
|---|---|---|
| Task Completion Rate | ≥90% | User satisfaction |
| Response Latency | <500ms | User experience |
| Output Accuracy | ≥95% | Trust and reliability |
| Error Rate | <5% | System stability |
| API Success Rate | ≥95% | Operational continuity |
These benchmarks align with industry standards for AI agent monitoring and provide clear targets for teams to measure against.
3. Implement Automated Evaluation Pipelines
AI agents change behavior with every model update or prompt tweak. Best practices recommend adding automated evaluation tests to your CI/CD pipeline: run fixed prompts, compare outputs to baselines, and halt deployments if too many responses drift.
Maxim's evaluation framework enables teams to:
- Define custom evaluators suited to specific application needs
- Run automated evaluations on large test suites
- Compare performance across multiple versions of prompts or workflows
4. Use Framework-Agnostic Standards
Relying on proprietary formats locks you into a single stack. OpenTelemetry recommendations emphasize using standardized semantic conventions for traces and metrics so observability is portable across tools. This approach ensures:
- Flexibility to switch or combine monitoring tools
- Consistent labeling of agent-specific spans
- Long-term maintainability of observability infrastructure
5. Monitor Across Multiple Dimensions
Effective observability requires tracking multiple aspects simultaneously. According to comprehensive AI observability research, organizations need to monitor data, system, code, and model response components together:
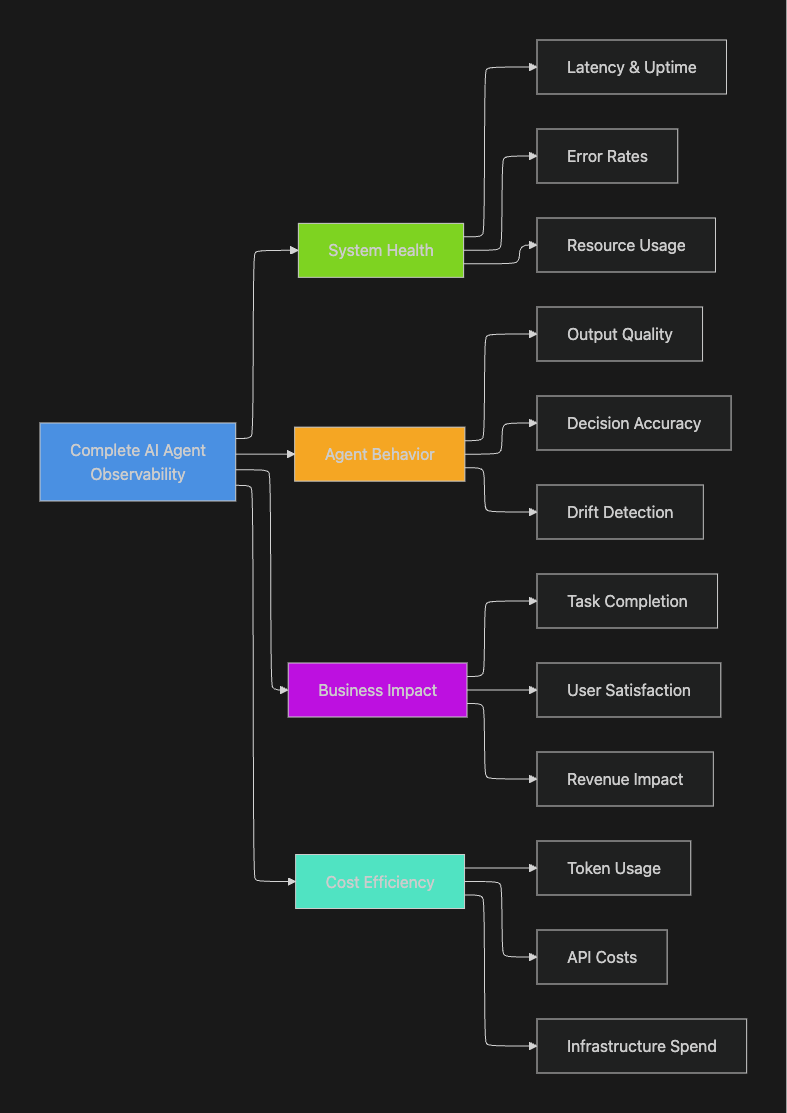
The Business Case for AI Agent Observability
The evidence is clear: effective observability is not optional for production AI systems. According to research cited in industry analysis, the average organization scraps 46% of AI proof-of-concepts before they reach production, representing roughly $30 billion in destroyed shareholder value in a single year. Proper observability addresses the core challenges that lead to these failures including cost overruns, data quality issues, and security risks.
Stanford HAI's 2025 AI Index reports that while 78% of global enterprises have deployed AI systems, many still struggle with production reliability. McKinsey's research shows that 23% of respondents report their organizations are scaling an agentic AI system somewhere in their enterprises, and an additional 39% say they have begun experimenting with AI agents. However, most are still in early stages of scaling AI and capturing enterprise-level value.
As organizations embrace multicloud environments and face increasing complexity, the need for comprehensive, purpose-built observability solutions becomes even more critical. According to Dynatrace's State of Observability 2024 report, the average multicloud environment spans 12 different platforms and services, with organizations using 10 different observability or monitoring tools to manage applications, infrastructure, and user experience across these environments.
Organizations that implement robust observability frameworks gain several competitive advantages:
- Faster Time to Resolution: Identify and fix issues before they impact users
- Cost Optimization: Track token usage, API costs, and resource allocation in real-time
- Quality Assurance: Maintain consistent agent performance through continuous monitoring
- Regulatory Compliance: The European Union's AI Act, which began taking effect in 2024, mandates continuous monitoring of high-risk AI applications
- Continuous Improvement: Use production data to refine and enhance agent behavior
Conclusion
AI agent observability represents a fundamental shift from traditional application monitoring. The non-deterministic nature of AI agents, combined with their multi-step workflows and autonomous decision-making capabilities, demands purpose-built observability solutions that provide deep visibility into every aspect of agent behavior and performance.
OpenTelemetry's research emphasizes that without proper monitoring, tracing, and logging mechanisms, diagnosing issues, improving efficiency, and ensuring reliability in AI agent-driven applications becomes extremely challenging, especially when scaling these agents to meet enterprise needs. As Stanford HAI reports show increasing AI adoption across enterprises, the organizations that invest in comprehensive observability platforms will have a significant competitive advantage.
Organizations that invest in comprehensive observability platforms like Maxim gain the ability to ship AI agents reliably and more than 5x faster, with the confidence that comes from understanding exactly how their agents perform in production environments. Our platform provides end-to-end visibility from experimentation through production, enabling teams to build, test, and deploy AI agents with unprecedented speed and reliability.
Ready to build reliable AI agents with world-class observability? Schedule a demo to see how Maxim's end-to-end platform can help your team ship AI applications with confidence, or sign up today to start monitoring your agents in production.


