10 Key Strategies to Improve the Reliability of AI Agents in Production

TL;DR
Building reliable AI agents in production requires a comprehensive approach that extends far beyond initial development. Studies on ML systems show that 91% experience performance degradation over time, making continuous monitoring and proactive intervention essential. This guide covers 10 proven strategies for maintaining AI agent reliability, from implementing robust testing frameworks and multi-level evaluation systems to establishing observability infrastructure and preventing model drift. Success depends on treating reliability as an ongoing discipline rather than a one-time checkpoint, with platforms like Maxim AI providing the end-to-end infrastructure needed to ship reliable agents 5x faster through integrated experimentation, simulation, evaluation, and production monitoring capabilities.
Introduction
The rise of autonomous AI agents represents a fundamental shift in how organizations automate complex workflows and decision-making processes. According to LangChain's State of AI Agents report, for small companies especially, performance quality far outweighs other considerations, with 45.8% citing it as a primary concern when moving agents from development to production. However, as Microsoft Research warns, "autonomous multi-agent systems are like self-driving cars: proof of concepts are simple, but the last 5% of reliability is as hard as the first 95%".
AI agents introduce unique reliability challenges that traditional software development practices cannot address. Unlike deterministic systems, agents can choose completely different approaches to solve the same problem, creating non-deterministic behavior that requires specialized monitoring and evaluation approaches. This guide presents 10 battle-tested strategies for building and maintaining reliable AI agents in production environments.
1. Implement Comprehensive Testing Frameworks
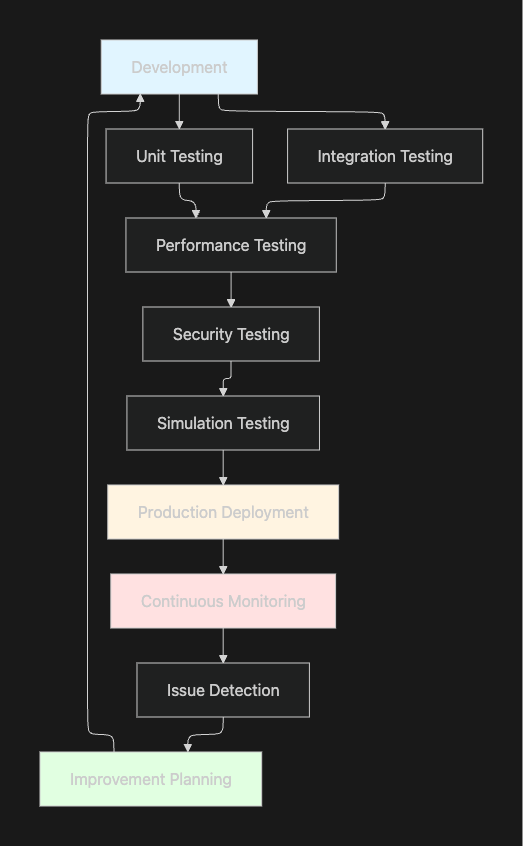
Building reliable AI agents begins with establishing multi-layered testing systems that validate behavior across different dimensions. According to NVIDIA analysis, having the right testing infrastructure can save up to 10 weeks of development time.
Effective testing requires coverage across multiple levels. Unit testing checks individual components using automated tests and LLMs for code analysis, while integration testing evaluates how systems work together in simulation environments with real-world scenarios. Performance testing measures speed and reliability under various conditions, and security testing ensures data protection through auditing and automated scans.
Maxim's Simulation capabilities enable teams to test agents across hundreds of scenarios and user personas before production deployment. By simulating customer interactions and evaluating conversational trajectories, teams can identify failure points and apply learnings to improve agent performance systematically.
2. Deploy Robust Observability and Monitoring
Agent observability extends beyond traditional monitoring to include evaluations and governance. As highlighted in Microsoft Azure's Agent Factory series, traditional observability includes metrics, logs, and traces, while agent observability needs metrics, traces, logs, evaluations, and governance for full visibility.
Critical metrics to monitor include latency (response time impact on user experience), API usage and token consumption (to identify cost spikes from excessive calls), request errors (failed API calls or tool invocations), and user feedback through explicit ratings and textual comments.
Maxim's Observability suite provides distributed tracing for multi-agent systems, real-time alerts for quality issues, and automated evaluations based on custom rules. Teams can track and debug live issues while creating datasets for continuous improvement directly from production data.
3. Establish Multi-Level Evaluation Systems
Comprehensive evaluation requires assessing agents at multiple granularities. According to enterprise AI evaluation frameworks, performance is evaluated using a multi-dimensional framework that tests technical resilience (latency, throughput, error handling), user experience quality (relevance, coherence, groundedness), and safety and compliance (bias checks, PII protection, policy adherence).
Organizations should implement evaluation at three distinct levels:
| Evaluation Level | Focus Areas | Key Metrics |
|---|---|---|
| Span-Level | Individual tool calls, API responses, reasoning steps | Tool selection quality, execution success rate, response accuracy |
| Trace-Level | Complete workflows, multi-step reasoning chains | Workflow completion rate, reasoning coherence, error propagation |
| Session-Level | User interactions, conversational context, task outcomes | Task success rate, user satisfaction (CSAT), resolution time |
Maxim's unified evaluation framework supports evaluations at all three levels, allowing teams to access off-the-shelf evaluators or create custom evaluators suited to specific application needs. Teams can measure quality quantitatively using AI, programmatic, or statistical evaluators while conducting human evaluations for last-mile quality checks.
4. Build Automated CI/CD Pipelines with Quality Gates
According to Microsoft Azure's best practices, automated evaluations should be part of your CI/CD pipeline so every code change is tested for quality and safety before release. This approach helps teams catch regressions early and ensures agents remain reliable as they evolve.
Integration with development workflows enables teams to auto-evaluate agents on every commit, compare versions using built-in quality, performance, and safety metrics, and leverage confidence intervals and significance tests to support deployment decisions.
Maxim's Experimentation platform enables rapid iteration and deployment by allowing users to version prompts directly from the UI, deploy with different experimentation strategies without code changes, and compare output quality, cost, and latency across various combinations seamlessly.
5. Use Simulation for Pre-Production Validation
Simulation environments allow teams to test agent behavior under controlled conditions before exposing systems to real users. As noted in UiPath's agent builder best practices, teams should use evaluation datasets, trace logs, and regression metrics to validate accuracy, tool use success, and safety.
Pre-production simulation should cover edge cases, adversarial inputs, and scenarios that might not appear during initial development. Teams can progressively expand simulation coverage based on production learnings, creating a feedback loop that continuously strengthens agent robustness.
Maxim's Simulation platform enables AI-powered testing across hundreds of scenarios, allowing teams to simulate customer interactions, evaluate conversational trajectories, and re-run simulations from any step to reproduce issues and identify root causes.
6. Implement Fallback Mechanisms and Error Handling
Reliable agents require graceful degradation when systems fail. According to Microsoft's AI agents course, teams should set up fallbacks or retries to make agents more robust against production issues. For example, if LLM provider A is down, switch to LLM provider B as backup.
Fallback strategies should address multiple failure scenarios including API timeouts, model unavailability, tool execution errors, and context length limitations. Each failure mode requires specific handling logic that maintains user experience while logging incidents for later analysis.
Bifrost, Maxim's AI gateway, provides automatic failover between providers and models with zero downtime, intelligent load balancing across multiple API keys, and semantic caching to reduce costs and latency, ensuring infrastructure-level reliability for production agents.
7. Monitor and Prevent Model Drift
According to analysis of AI agent reliability, drift can occur due to multiple factors including inadequate evaluation datasets that don't reflect production usage patterns, seasonal variations in user behavior, permanent environmental changes in the business landscape, and insufficient validation controls.
Teams should monitor for three types of drift. Concept drift occurs when relationships between input data and target variables change over time. Data drift happens when input data distributions change while underlying relationships remain stable. Prompt drift in agent systems emerges from inconsistent or evolving instruction templates.
Early warning signs include declining success rates on established task types, increasing error frequencies without code changes, response inconsistency for similar inputs, and user feedback indicating off-target outputs. Maxim's observability capabilities enable continuous drift monitoring through automated quality checks on production data.
8. Establish Human-in-the-Loop Processes
According to UiPath's production best practices, teams should maintain a human-in-the-loop by using escalations for human review on high-risk decisions. These interactions inform agent memory, improving future runs. Human oversight becomes particularly critical for decisions involving financial transactions, healthcare recommendations, legal interpretations, or other high-stakes scenarios.
Effective human-in-the-loop systems require clear escalation criteria, streamlined review interfaces that don't create bottlenecks, and feedback mechanisms that inform continuous learning. Maxim's Data Engine facilitates seamless data management by enabling teams to enrich datasets using in-house or Maxim-managed data labeling, creating curated feedback loops for ongoing improvement.
9. Optimize Tool Selection and Integration
Function calling and tool use represent fundamental abilities for building intelligent agents capable of delivering real-time, contextually accurate responses. According to IBM's agent evaluation framework, evaluation should assess whether agents select appropriate tools, call correct functions, pass information in proper context, and produce factually correct responses.
According to UiPath's technical guidance, teams should maintain clarity in tool definitions by using simple, descriptive tool names with lowercase alphanumeric characters and no spaces or special characters. Well-defined tool contracts reduce confusion and improve agent decision-making accuracy.
Organizations should conduct dedicated evaluation of tool usage using rule-based approaches combined with semantic evaluation. Bifrost's Model Context Protocol (MCP) support enables AI models to use external tools including filesystem access, web search, and database connections through a standardized interface, simplifying tool integration for production agents.
10. Maintain Version Control and Documentation
According to UiPath's deployment guidelines, teams should version everything by maintaining clear version control for prompts, tools, datasets, and evaluations. Gate production release by moving agents to production only after evaluations pass and rollout plans are finalized. Attach evaluations to version tags to ensure traceability from design to deployment.
Comprehensive documentation should cover agent capabilities and limitations, tool definitions and usage patterns, evaluation criteria and thresholds, escalation procedures and approval workflows, and incident response protocols. This documentation serves both operational needs and compliance requirements as regulatory frameworks increasingly demand transparency in AI systems.
As noted in the EU AI Act requirements, regulations mandate lifecycle risk management, high accuracy standards, data governance, transparency, and human oversight for critical systems. High-risk AI applications must maintain logs of decisions and allow human intervention.
Conclusion
Building reliable AI agents in production requires treating reliability as an ongoing discipline rather than a one-time milestone. The strategies outlined here, from comprehensive testing and multi-level evaluation to continuous monitoring and drift prevention, form the foundation of sustainable agent operations.
As highlighted in LangChain's industry report, companies who can crack the code on reliable, controllable agents will have a headstart in the next wave of AI innovation and begin setting the standard for the future of intelligent automation. Success depends on implementing the right infrastructure to support evaluation, observability, and continuous improvement throughout the agent lifecycle.
Maxim AI provides the end-to-end platform that AI engineering and product teams need to ship reliable agents faster. From experimentation and simulation to evaluation and production observability, Maxim enables teams to measure and improve AI quality at every stage. Request a demo to see how Maxim can help your team build reliable AI agents that consistently perform in production, or sign up today to start improving your agent reliability.


