10 Essential Steps for Evaluating the Reliability of AI Agents

TL;DR
Evaluating AI agent reliability requires a systematic, multi-dimensional approach that extends far beyond simple output checks. This comprehensive guide outlines 10 essential steps for building trustworthy AI agents: defining success metrics, building test datasets, implementing multi-level evaluation, using diverse evaluator types, simulating real-world scenarios, monitoring production behavior, integrating human feedback, measuring cost and latency, version controlling experiments, and enabling continuous iteration. Organizations that implement these practices systematically using platforms like Maxim AI can ship reliable AI agents 5x faster while maintaining enterprise-grade quality and compliance standards.
Introduction
AI agents are rapidly transforming enterprise operations, from customer support and decision-making to data analysis and workflow automation. Their ability to reason, plan, and interact dynamically with users and systems positions them as central components in modern applications. However, as agentic workflows become more complex, the challenge of ensuring reliability, safety, and alignment with business goals intensifies.
Unlike traditional software that produces deterministic outputs, AI agents are probabilistic and context-sensitive systems that can follow unintuitive paths to achieve goals, potentially reaching correct outcomes through suboptimal processes or failing in subtle ways that make debugging difficult. Without rigorous evaluation, agents might perform well in basic scenarios but collapse under edge cases or real-world conditions.
The stakes are particularly high as organizations move from experimental prototypes to production deployments. According to recent industry research, 85 percent of organizations actively use generative AI in at least one business function, yet most agents encounter significant barriers before reaching production. The organizations that succeed are those with robust evaluation and monitoring infrastructure that enables continuous improvement.
This guide presents 10 essential steps for evaluating AI agent reliability, drawing on industry best practices and demonstrating how Maxim AI's comprehensive platform addresses each critical component of the agent evaluation lifecycle.
Step 1: Define Success Metrics and KPIs
The foundation of effective AI agent evaluation begins with clearly defined, objective metrics that reflect your agent's intended purpose and expected outcomes. Evaluation metrics fall into several key categories, including performance metrics (accuracy, task success rate, correctness), interaction metrics (response time, user satisfaction), safety metrics (hallucination rate, bias detection, PII protection), and system efficiency metrics (latency, cost, scalability).
For AI agents, task success rate measures how accurately the agent completes assigned objectives based on predefined success criteria. This metric is fundamental because it directly assesses whether the agent achieves its core purpose. However, agents also require evaluation across multiple dimensions simultaneously. Rather than optimizing for a single KPI, comprehensive evaluation must consider accuracy, latency, cost, customer satisfaction, and safety together.
Maxim's evaluation framework enables teams to define custom success criteria tailored to specific use cases and track multiple metrics in parallel. Through the evaluator store, teams can access off-the-shelf evaluators or create custom evaluators suited to their application needs, measuring quality quantitatively using AI-powered, programmatic, or statistical evaluators.
When defining metrics, consider both technical resilience (latency, throughput, error handling) and user experience quality (relevance, coherence, groundedness). For enterprise deployments, safety and compliance metrics become equally critical, including bias checks, PII protection, and policy adherence.
Step 2: Build Comprehensive Test Datasets
Test datasets serve as the foundation for systematic agent evaluation. Representative evaluation datasets should include diverse inputs that reflect real-world scenarios and test scenarios that simulate real-time conditions. Annotated data provides ground truth that AI models can be tested against.
Effective test suites should span three categories of scenarios. Deterministic scenarios involve known inputs and expected outputs, enabling precise validation of agent behavior. Open-ended prompts assess generative capabilities and the agent's ability to handle ambiguous requests. Edge cases and adversarial inputs validate robustness, testing how agents respond to unusual, complex, or potentially malicious inputs.
For thorough evaluation, develop custom edge case test suites that reflect specific challenges in your domain. This might include rare medical conditions for healthcare applications or unusual financial transactions for banking systems. If you're building an AI agent for customer service, test scenarios should span all supported interactions as well as unsupported requests that the agent must escalate appropriately.
Maxim's data engine streamlines this process by enabling teams to import multi-modal datasets with ease, continuously curate datasets from production data, and enrich data using in-house or Maxim-managed data labeling. The platform supports creating data splits for targeted evaluations and experiments, ensuring test coverage across diverse scenarios.
Synthetic data generation can help expand test coverage. Maxim's AI-powered simulation capabilities allow teams to generate hundreds of realistic customer interactions across different user personas and scenarios, providing comprehensive test coverage without requiring extensive manual data collection.
Step 3: Implement Multi-Level Evaluation
AI agents operate at multiple levels of granularity, requiring evaluation strategies that assess both individual components and end-to-end workflows. Evaluation must occur at the span level (individual LLM calls or tool invocations), trace level (complete single-turn interactions), and session level (multi-turn conversations).
At the span level, evaluate each discrete operation: Does each LLM call produce relevant output? Are tool invocations accurate? Do individual reasoning steps align with expected logic? This granular analysis helps identify precisely where failures occur within complex agent workflows.
Trace-level evaluation assesses complete single-turn interactions from user input to final response. Trajectory evaluation examines the sequence of actions and tool calls the agent takes to accomplish tasks. Are the steps logical? Does the agent select appropriate tools? Is the reasoning path efficient?
For multi-turn agents, session-level evaluation becomes critical. This assesses whether agents maintain context across interactions, handle follow-up questions appropriately, and successfully complete complex tasks that require multiple exchanges with users.
Maxim's tracing capabilities provide complete visibility into the agentic hierarchy, enabling teams to track, debug, and analyze agent behaviors at every level. The platform visualizes workflow execution, identifies bottlenecks and failure points, and allows comparison across versions and iterations. This multi-level observability ensures issues are detected and resolved at the appropriate level of granularity.
Step 4: Use Diverse Evaluator Types
Relying on a single evaluation method creates blind spots. Comprehensive agent evaluation requires combining multiple evaluator types: deterministic evaluators, statistical evaluators, LLM-as-a-judge evaluators, and human evaluators.
Deterministic evaluators apply rule-based checks for specific criteria. These include exact match validation, regex pattern matching, JSON schema validation, and programmatic assertions. Deterministic evaluators excel at verifying structured outputs, checking compliance with format requirements, and validating that specific business rules are followed.
Statistical evaluators analyze patterns across multiple outputs, measuring consistency, distribution of response types, and performance trends over time. These evaluators can detect drift, identify outliers, and provide quantitative insights into agent behavior patterns.
LLM-as-a-judge evaluation uses language models to assess other AI systems based on predefined criteria. This automated approach can evaluate nuanced qualities like relevance, coherence, helpfulness, and tone at scale. However, LLM evaluators should be calibrated against human judgment and validated for consistency.
Human evaluators remain essential for assessing subjective qualities that automated systems struggle to measure reliably. Human judgment is invaluable for aspects like tone, creativity, cultural appropriateness, and user experience. Building mechanisms to gather feedback from real users or expert reviewers provides nuanced understanding of agent performance.
Maxim's flexible evaluation framework supports all evaluator types through a unified interface. Teams can configure evaluations with fine-grained flexibility, running automated evaluations while seamlessly integrating human review workflows for last-mile quality checks and nuanced assessments. The platform enables human and LLM-in-the-loop evaluations to ensure agents continuously align with human preferences.
Step 5: Simulate Real-World Scenarios
Before deploying agents to production, systematic simulation testing identifies potential failure modes and validates behavior across diverse conditions. AI agents should be evaluated not just on happy-path interactions but also on edge cases, adversarial prompts, and high-volume scenarios to ensure resilience under pressure.
Effective simulation encompasses several dimensions. Test performance under shifting conditions, including real-time data inputs and varying user behavior. Simulate disruptions or input failures to evaluate robustness and ability to recover gracefully. Include stress tests that intentionally challenge agents with complex, unexpected, or malicious inputs.
Dynamic environments require testing across variable inputs, edge cases, and evolving user interactions. Identifying failure factors early reduces blind spots and strengthens deployment readiness. For example, financial agents should be tested with unusual transaction patterns, healthcare agents with rare diagnostic scenarios, and customer service agents with frustrated or confused user interactions.
Maxim's simulation environment enables teams to test agents across hundreds of realistic scenarios and user personas. Teams can use AI-powered simulations to simulate customer interactions across real-world scenarios and user personas, monitor how agents respond at every step, evaluate conversational trajectories, assess task completion rates, and identify failure points. The simulation overview documentation provides detailed guidance on setting up comprehensive test environments.
Teams can re-run simulations from any step to reproduce issues, identify root causes, and apply learnings to improve performance. This capability is critical for debugging complex agent behaviors and validating that fixes address the underlying problems.
Agent workflow simulation should map out every potential step in the agent's execution path, whether calling an API, passing information to another agent, or making decisions. By breaking down workflows into individual pieces, it becomes easier to evaluate how agents handle each step and assess their overall approach across multi-step problems.
Step 6: Monitor Production Behavior
Evaluation is not a one-time task but an ongoing process supporting continuous learning and adaptation. Once agents are deployed, continuous monitoring ensures they maintain quality, safety, and alignment with business objectives in real-world conditions.
Production monitoring should track several key dimensions. Operational metrics include latency, error rates, throughput, and resource utilization. Quality metrics assess output accuracy, relevance, and consistency in live interactions. Safety metrics detect hallucinations, bias, PII exposure, and policy violations. Business metrics measure task completion rates, user satisfaction, cost efficiency, and return on investment.
Over time, AI agent performance can deteriorate as real-world conditions evolve beyond the system's training data. Identifying performance decline early is essential for maintaining reliable operations. Effective drift detection tracks changing patterns in input distributions, output quality, user behavior, and environmental conditions.
Control charts help monitor performance stability over time, establishing baseline performance ranges and alerting teams when metrics drift beyond acceptable thresholds. By implementing automated monitoring that tracks key performance indicators, organizations can detect subtle degradation before it significantly affects users.
Maxim's observability suite empowers teams to monitor real-time production logs and run periodic quality checks. The platform provides distributed tracing to track every interaction, real-time dashboards showing latency, cost, token usage, and error rates at granular levels, and automated alerts via Slack, PagerDuty, and other integrations. Teams can create multiple repositories for different applications, with production data logged and analyzed through comprehensive tracing capabilities.
The platform enables automated evaluations in production based on custom rules, allowing continuous quality assessment of live traffic. This ensures reliability while enabling teams to act on production issues with minimal user impact.
Step 7: Integrate Human Feedback
Even with the best automated metrics, human feedback remains essential, especially for evaluating tone, empathy, and cultural context. Human evaluators can detect subtle biases or unfair assumptions that automated tools often miss, assess user experience dimensions like friendliness and appropriateness, and understand context related to business norms or local customs that cannot be captured through rules alone.
Implementing direct user evaluation provides valuable insights. Explicit feedback mechanisms include thumbs up/down ratings, star ratings, or textual comments. Implicit feedback can be derived from user behavior patterns, task completion rates, and conversation flow analysis.
For aspects like creativity, appropriateness, and nuanced quality judgments, human review is invaluable. Build mechanisms to gather feedback from real users or expert reviewers to gain nuanced understanding of agent performance that complements quantitative metrics.
Maxim's human evaluation workflows make it easy to collect and incorporate human feedback into the evaluation process. Teams can define custom evaluation criteria, distribute review tasks to internal teams or external reviewers, and aggregate human ratings alongside automated metrics. The platform's data curation capabilities enable enrichment using in-house or Maxim-managed data labeling services.
Human feedback loops should be closed systematically. Collect feedback, analyze patterns and common issues, prioritize improvements based on frequency and severity, implement changes, and validate improvements through follow-up evaluation. This continuous cycle ensures agents evolve in alignment with user needs and expectations.
Step 8: Measure Cost and Latency Alongside Quality
AI agents rely on LLM calls billed per token and external APIs, where frequent tool usage or multiple prompts can rapidly increase costs. Response time directly impacts user experience and system efficiency. Comprehensive evaluation must balance quality improvements against cost and latency implications.
Cost metrics should track tokens consumed per interaction, API call expenses, infrastructure costs, and total cost per completed task. For instance, if an agent calls an LLM five times for marginal quality improvement, teams must assess whether the cost is justified or if the number of calls can be reduced or a more efficient model used.
Latency metrics measure time to first token, complete response time, tool invocation overhead, and end-to-end task completion time. Users expect rapid responses, and delays can significantly degrade experience even if final output quality is high.
Maxim's unified dashboards show quality metrics, cost, and latency side-by-side, enabling teams to evaluate tradeoffs effectively. The platform tracks these metrics at granular levels (session, node, span), providing visibility into where costs accumulate and where latency bottlenecks occur.
Teams can identify optimization opportunities by analyzing cost-benefit tradeoffs. Consider implementing caching for common requests, selecting more efficient models for appropriate tasks, optimizing prompt design to reduce tokens, and implementing fallback strategies to balance cost and reliability.
Strategies for cost optimization include identifying common requests and providing cached responses, using basic AI models to determine similarity to cached requests, implementing tiered model selection based on query complexity, and monitoring for unexpected spikes that may indicate bugs or inefficient implementations.
Step 9: Version Control and Experiment Tracking
AI agent development involves continuous experimentation with prompts, models, architectures, and evaluation criteria. Without systematic version control and experiment tracking, teams lose the ability to understand what changes drove improvements or regressions, reproduce results consistently, or rollback when deployments cause issues.
Comprehensive versioning should track prompt versions and changes, model selections and parameters, evaluation configurations, test datasets, and agent logic modifications. Every change should be documented with clear descriptions, timestamps, and author information.
Experiment tracking enables teams to compare versions systematically, measuring differences in quality metrics, cost and latency, error rates, and user satisfaction. Track not just agent versions but also evaluation setups, test cases, and criteria to maintain accountability and consistency across iterations.
Maxim's experimentation platform provides Playground++ for advanced prompt engineering, enabling rapid iteration, deployment, and experimentation. The prompt playground allows teams to organize and version prompts directly from the UI, deploy prompts with different deployment variables and experimentation strategies without code changes, and simplify decision-making by comparing output quality, cost, and latency across various combinations of prompts, models, and parameters.
The platform's comprehensive experiment tracking capabilities allow teams to visualize evaluation runs on large test suites across multiple versions, compare performance across iterations with statistical significance testing, and maintain complete audit trails for compliance and governance requirements.
Version control becomes particularly critical in regulated industries where organizations must demonstrate that deployed agents meet safety and compliance standards, prove that changes were properly tested and validated, and maintain records for audit and regulatory review.
Step 10: Enable Continuous Iteration and Improvement
The most successful AI agent deployments treat evaluation as a continuous lifecycle discipline embedded across build, test, release, and production stages. By combining technical testing, observability, human feedback loops, and business KPI tracking, enterprises ensure agents remain reliable, transparent, and enterprise-ready.
Continuous improvement requires establishing feedback loops between all evaluation stages. Monitor production performance to identify issues and opportunities, collect and analyze user feedback systematically, run regular evaluation cycles on updated test sets, prioritize improvements based on impact and feasibility, implement changes with proper versioning and testing, and validate improvements before rolling out to production.
Teams should monitor agents regularly in production settings, reassess after software updates or retraining, and use feedback loops to refine models and logic. By tracking performance and evaluation results over time, organizations can track progress, ensure alignment with objectives, and maintain reliable operation as systems scale.
The ultimate vision for AI agents is for them to become self-improving systems. By analyzing structured traces and identifying failure points or inefficient paths, future agents could automatically correct behavior and refine internal plans. This feedback loop, powered by sophisticated observability and evaluation, promises agents that continuously improve performance.
Maxim's comprehensive platform supports this continuous improvement cycle by unifying experimentation, simulation, evaluation, and observability in a single environment. Teams can move seamlessly from identifying issues in production through Maxim's observability suite, reproducing problems using simulation capabilities, experimenting with fixes in the playground, validating improvements through systematic evaluation, and deploying updated agents with confidence.
The Comprehensive AI Agent Evaluation Workflow
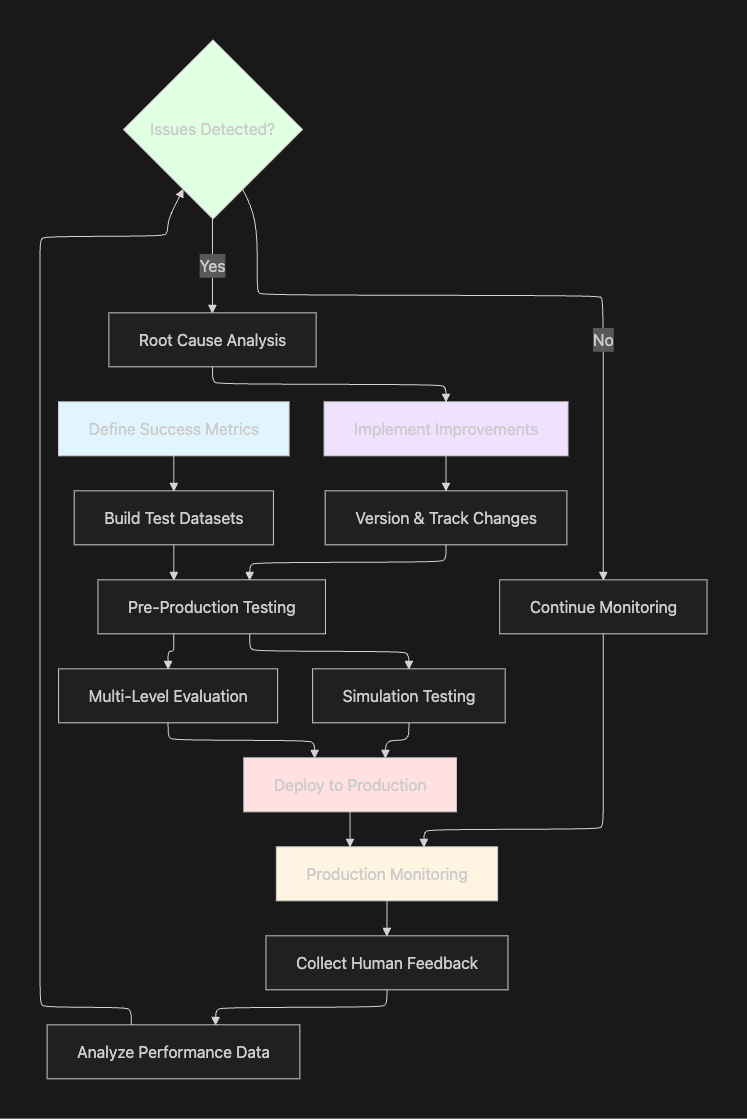
This workflow diagram illustrates how the 10 essential steps interconnect in a continuous improvement cycle. The process begins with defining metrics and building test datasets, progresses through comprehensive pre-production testing, deploys to production with robust monitoring, and feeds insights back into iterative improvements.
Summary of Essential Steps
| Step | Focus Area | Key Activities | Maxim Platform Support |
|---|---|---|---|
| 1. Define Success Metrics | Goal Setting | Define KPIs across performance, safety, cost, and user experience | Custom evaluators and multi-dimensional metrics tracking |
| 2. Build Test Datasets | Data Foundation | Create diverse test scenarios including edge cases and adversarial inputs | Data engine for import, curation, and enrichment |
| 3. Multi-Level Evaluation | Granular Analysis | Evaluate at span, trace, and session levels | Distributed tracing with hierarchical observability |
| 4. Diverse Evaluator Types | Comprehensive Coverage | Combine deterministic, statistical, LLM-based, and human evaluators | Evaluator store with flexible configuration options |
| 5. Simulate Real-World Scenarios | Pre-Production Testing | Test across hundreds of user personas and scenarios | AI-powered simulation environment |
| 6. Monitor Production | Continuous Oversight | Track quality, cost, latency, and safety in live environments | Real-time dashboards and automated alerting |
| 7. Integrate Human Feedback | Qualitative Insights | Collect explicit and implicit user feedback | Human evaluation workflows and feedback collection |
| 8. Measure Cost and Latency | Efficiency Optimization | Balance quality with operational efficiency | Side-by-side metrics visualization and cost tracking |
| 9. Version Control | Experiment Tracking | Track all changes and compare performance across versions | Playground++ for versioning and experiment comparison |
| 10. Continuous Iteration | Ongoing Improvement | Close feedback loops and systematically improve agents | End-to-end lifecycle platform integration |
Conclusion
Evaluating AI agent reliability is a complex, multi-faceted discipline that requires systematic approaches, diverse methodologies, and comprehensive tooling. The 10 essential steps outlined in this guide provide a framework for building agents that are not just functional but truly reliable, safe, and aligned with business objectives.
Success in AI agent deployment depends on treating evaluation as a continuous lifecycle practice rather than a one-time validation step. Organizations must combine automated testing with human oversight, balance multiple metrics simultaneously, and maintain visibility across all stages from experimentation through production.
Maxim AI provides the comprehensive platform that organizations need to implement these best practices effectively. By unifying experimentation, simulation, evaluation, and observability in a single environment, Maxim enables teams to ship reliable AI agents 5x faster while maintaining enterprise-grade quality standards.
The platform's integrated approach means that insights from production monitoring inform simulation testing, evaluation results guide experimentation, and improvements are tracked and validated systematically. This closed-loop system ensures that agents continuously evolve and improve while maintaining reliability and compliance.
As AI agents become increasingly central to enterprise operations, the organizations that succeed will be those with robust evaluation and monitoring infrastructure. Maxim's platform provides the foundation for building AI systems that users can trust and that deliver consistent business value.
Ready to build reliable AI agents with confidence? Schedule a demo to see how Maxim's comprehensive evaluation and observability platform can accelerate your AI development while ensuring enterprise-grade reliability, or sign up to start evaluating your agents today.


