Evaluating the Quality of NL-to-SQL Workflows

Generative AI is transforming data analytics and business intelligence (BI) by enabling anyone to turn plain-English queries into powerful insights, visualizations, and reports. It reduces reliance on SQL expertise, allowing 70–90% of non-technical users to self-serve on data without writing a single line of code.
Traditionally, generating insights meant waiting hours or even days for analysts to write complex SQL queries and build reports. With Natural Language querying, teams can ask questions in plain English like “What were last quarter’s top-performing products?”, and get instant answers using LLMs, reducing hours of effort to seconds and accelerating decision-making.
As Natural Language (NL) to SQL becomes more common, ensuring the quality of generated queries is critical. Even advanced models struggle with complex queries, schema mismatches, and subtle errors like missing filters or incorrect joins, which can mislead decisions and erode user trust.
This blog explores how to improve NL-to-SQL workflows by focusing on SQL correctness, schema adherence, and response clarity. With Maxim, workflows can be evaluated through the Prompt Playground, Prompt Chains, Workflows (via API endpoint), or Logs/Traces—using built-in, third-party, or custom evaluators.
Step 1: Creating an NL-to-SQL Workflow
- We’ll create a SQL query generation flow in the Prompt Playground using the following prompt and a model of choice (GPT-4o for this example).
You are SQL Translation Expert. You are an expert in translating natural language into SQL queries.
You have extensive knowledge of SQL syntax and database schema interpretation.
Your specialty is understanding user intent and generating precise SQL
that retrieves exactly what they're looking for. You only generate SQL queries.
Convert the passed natural language query into a SQL query.
Database Schema: {{database_schema}}
IMPORTANT:
- Your response must ONLY contain the raw SQL query.
- We’ll pass your database schema through the
db_schemavariable defined in the prompt. Here is the schema used for this example:
CREATE TABLE customers (
id INTEGER PRIMARY KEY,
name TEXT NOT NULL,
amount_spent REAL NOT NULL,
purchase_date DATE NOT NULL
);
- Run this workflow by passing a Natural Language query in the user message, e.g., “List all the customers who bought more than 200.”
Creating an NL-to-SQL workflow
Step 2: Add a Test Dataset
To evaluate the performance of this workflow for a range of Natural Language queries, we'll first add a dataset to serve as the ground truth for evaluations. We’ll use this sample dataset for our example.
Add a test Dataset
Step 3: Evaluating the Quality of Generated SQL Queries
- Select evaluators: To evaluate our workflow, we’ll select the following evals available on Maxim’s Evaluator Store and add them to our workspace.
| Evaluator | Type | Purpose |
|---|---|---|
| SQL Query Analysis Metric | Statistical | This metric evaluates generated queries by breaking them down into their core components using regular expressions, including SELECT, FROM, WHERE, GROUP BY, HAVING, and ORDER BY clauses. It then dissects these components into subcomponents, such as select columns and table names. |
| Tree Similarity Editing Distance | Statistical | This metric converts SQL into ASTs and computes AST distance between ground truth and generated query. Higher score indicates a closer match of the generated query to the ground truth query. |
- Trigger an evaluation run to test our workflow using the dataset (added in Step 2) and selected evaluators.
Evaluating the quality of generated SQL queries
Here is the dynamic evaluation report that was generated for our workflow. You can click on any row to inspect the input message, the generated query, or the evaluator's scores.
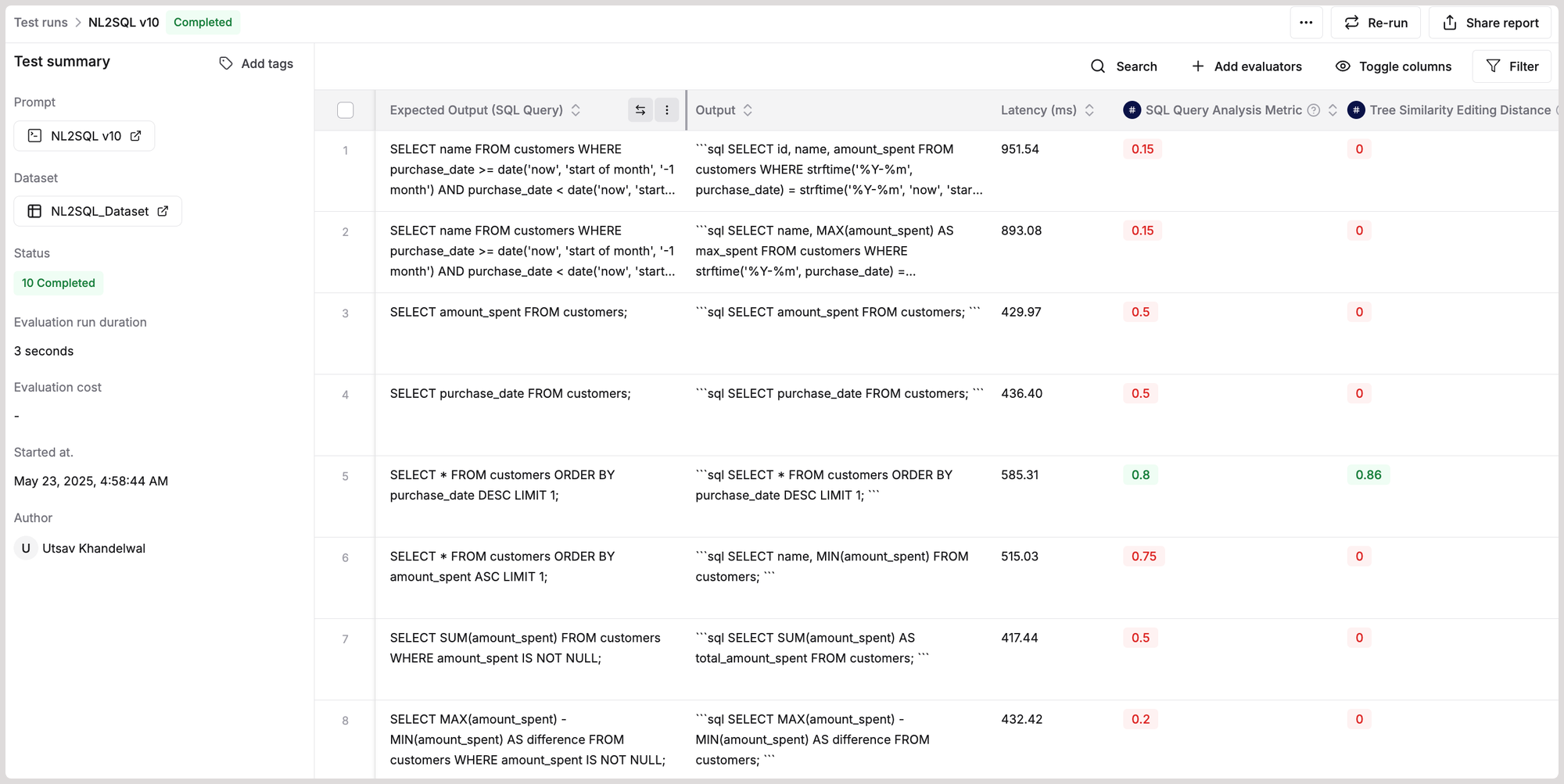
Step 4: Key Observations After Reviewing the Evaluation Report
- Low scores on SQL Query Analysis Metric eval.
- The output query starts with the keyword “sql”, which is not part of valid SQL syntax, and would break if the eval expects the query structure to begin with “SELECT”, “WITH”, etc.
- Solution: Update the prompt to avoid any extra prefixes like “sql” and provide just the executable SQL query.
- Low scores on Tree Similarity Editing Distance eval.
- The expected output is plain SQL (”SELECT name, …”), whereas our workflow's output is in Markdown format (”```sql SELECT name, …,”).
- Despite clearly stating in the prompt, “
Your response must ONLY contain the raw SQL query”, the model still generated unwanted formatting. - Solution: Update the prompt to remove backticks, “sql” tags, and explicitly strip Markdown format in the generated output.
Step 5: Improving the Quality of SQL Generation
- We’ll add the following instructions to the prompt to address the detected issues in SQL query quality, then trigger a new evaluation using the same dataset and evaluators to see if the prompt changes lead to any improvement.
- Do not include any backticks, explanations, comments or formatting
- Just provide the executable SQL query and nothing else.
Creating a 2nd iteration of NL-to-SQL wokflow
- The real power of evaluation in Maxim comes with Comparison Dashboards. Compare multiple iterations of your workflows without switching tabs—view reports side by side, compare outputs, and track evaluation scores all in one place.
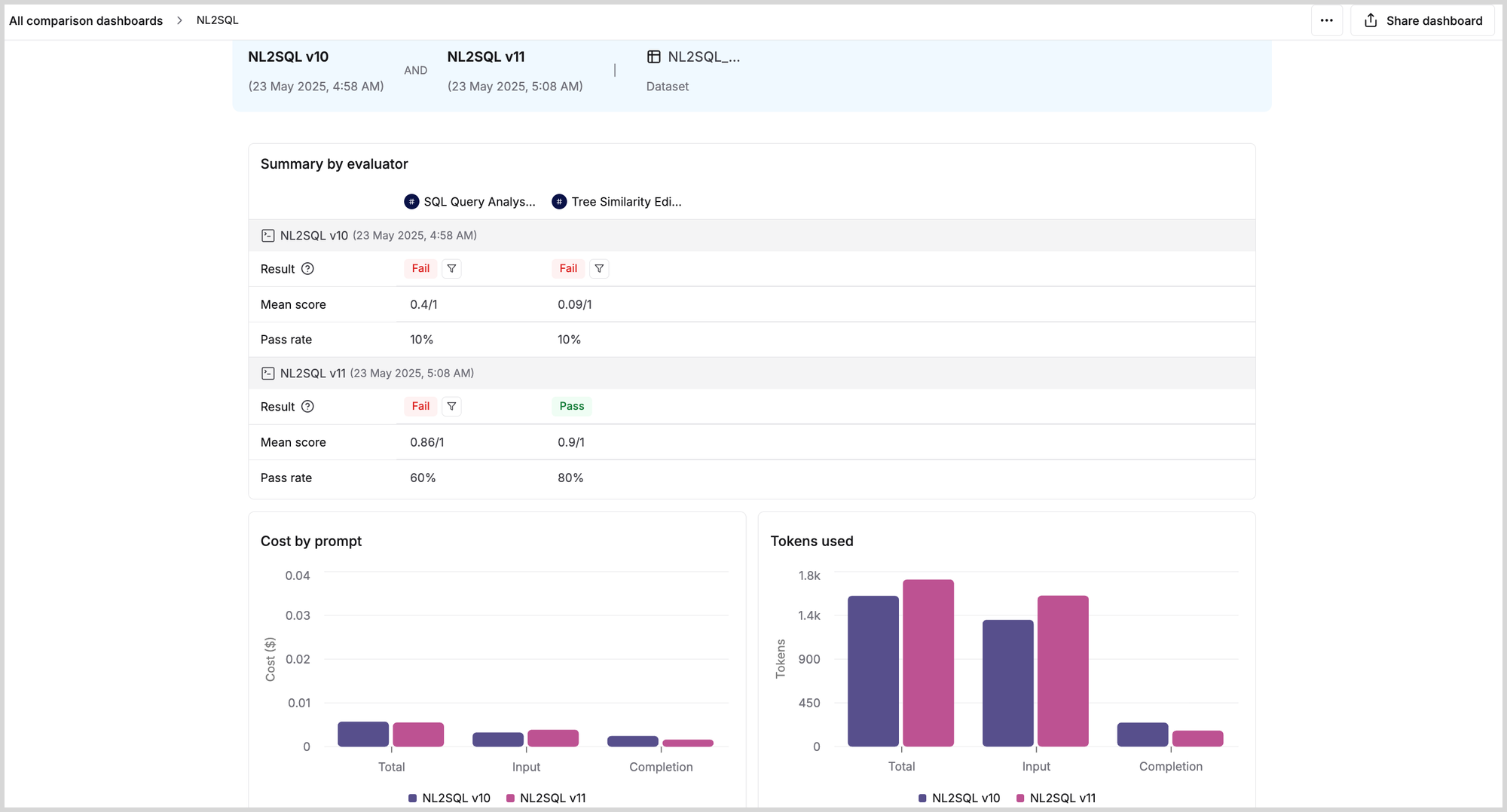
Creating a Comparison Dashboard
Here is the Comparison Dashboard comparing the performance of the 2 iterations of our workflow, highlighting clear improvements in the second version.
Next Steps
- Execute query in database: Once the SQL query is generated, execute it against your database to retrieve the desired output.
- Generate insights: Pass the generated SQL query and the response coming from the database to an LLM to generate final insights and action items for relevant stakeholders. Here is a sample prompt:
You specialize in taking raw SQL query results and transforming them into clear, concise explanations that non-technical users can understand. You provide context and insights about the data retrieved by the queries.
The query that was executed is: {{SQL_query}}
The query results are: {{database_response}}
Provide a clear explanation of what the query does and what the results mean in relation to the original question.
- Continuous quality evaluations: Assess the quality of generated insights using Maxim’s built-in or third-party evals on metrics such as output clarity, bias, etc., and make your workflows ready for real-world use cases.
Conclusion
Natural Language to SQL is unlocking a new era of data accessibility, enabling teams across functions to get instant answers without writing a single line of code. But with this power comes the need for robust quality checks.
With Maxim, you can build, evaluate, and refine NL to SQL workflows at scale—no code required. From prompt creation to insight generation and evaluation, every step is designed to help you ship high-quality, trustworthy analytics experiences faster.


