Attention Residuals: What If Your Network Could Choose Which Layer to Listen To?

Residual connections are one of those ML ideas that feels obvious in hindsight. Instead of each layer completely overwriting the previous representation, you just add the transformation on top:
h_l = h_{l-1} + f(h_{l-1})
This single + sign is what made training 100-layer networks possible. It gives gradients a direct highway back to early layers, sidestepping the vanishing gradient problem that plagued deep networks before it.
But here's the thing: that + sign is also doing something else, something that has received surprisingly little attention. It's defining how information accumulates across depth. And it does so in the most naive way possible: every layer gets an equal vote. Layer 1 and layer 47 contribute identically to what layer 48 sees. No layer can say "actually, I want more of what layer 12 produced."
The Kimi team's paper, Attention Residuals (AttnRes), argues this is a real limitation and fixes it with an elegant idea borrowed from a familiar source.
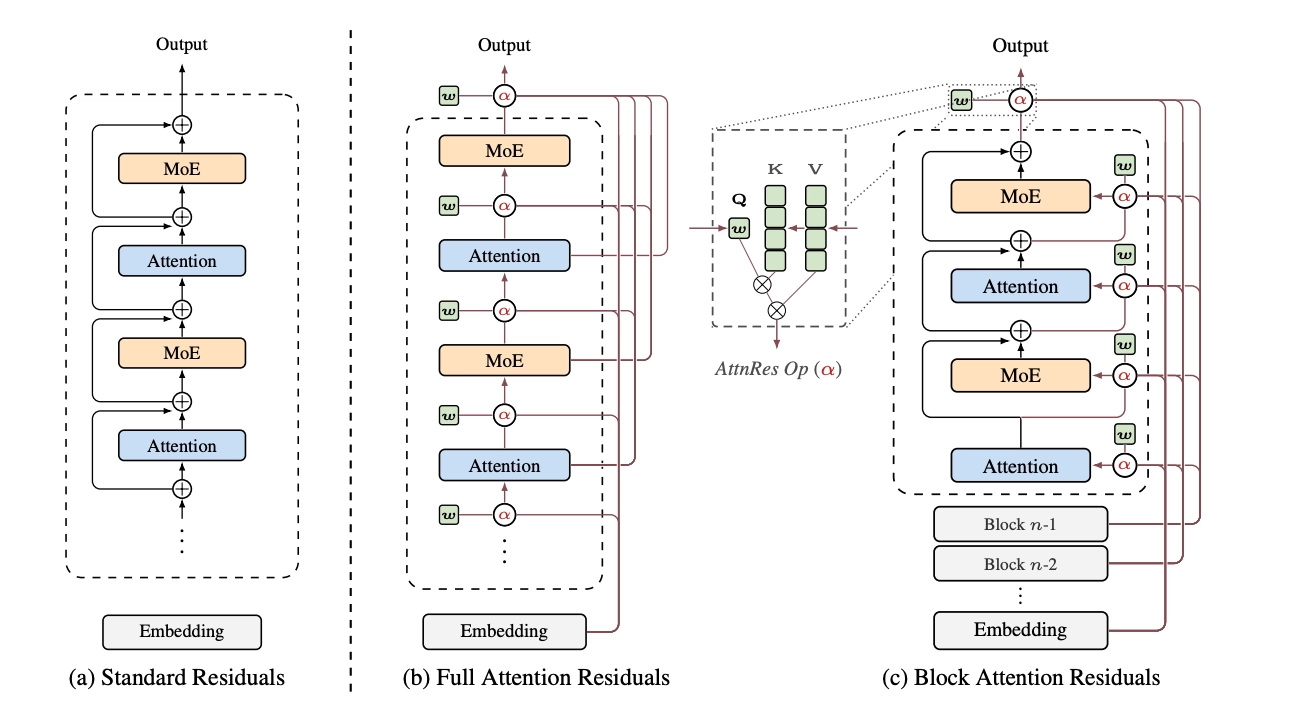
The Problem with Uniform Accumulation
Unroll the residual recurrence and you get:
h_l = h_1 + f_1(h_1) + f_2(h_2) + ... + f_{l-1}(h_{l-1})
The hidden state at any layer is just a running sum of everything before it. Every term has coefficient 1. There's no mechanism for the network to selectively upweight something useful from layer 5 or downweight noise from layer 20.
This causes a concrete problem known as PreNorm dilution. Because the hidden state magnitude grows as O(L) with depth (you're adding more and more vectors together) deeper layers need to produce increasingly large outputs just to have any influence on the final representation. Early-layer information gets progressively buried under the pile. Empirically, this is why a surprising fraction of layers in large LLMs can be pruned with barely any performance drop: they've become marginally relevant.
There's a second issue: once information is blended into the accumulated state, it can't be selectively retrieved. If an attention layer earlier in the network produced something highly relevant to what you're computing now, you can't reach back and grab it: it's been averaged into everything else.
Depth is Just Sequence, Rotated 90°
Here's the paper's central observation. The way residual connections accumulate information over depth is structurally identical to how RNNs accumulate information over a sequence. In both cases, you have a single compressed state that tries to carry everything forward, with each step blending in new information and permanently overwriting the old.
And we already know the solution to that problem. Transformers replaced RNN recurrence over sequence with attention, letting each position directly query any previous position, with learned, input-dependent weights. The paper simply asks: why haven't we done the same thing over depth?
The answer is Attention Residuals. Instead of:
h_l = h_{l-1} + f_{l-1}(h_{l-1}) ← fixed uniform weights
You get:
h_l = Σ α_{i→l} · v_i ← learned, input-dependent weights
where v_i are the individual outputs of each preceding layer, and α_{i→l} are softmax attention weights so they sum to 1 and compete with each other. Each layer can now look back at every previous layer's output and decide how much of each to use.
How the Attention Weights Are Computed
The weights α_{i→l} are computed using a kernel function:
α_{i→l} = φ(q_l, k_i) / Σ φ(q_l, k_j)
where φ(q, k) = exp(q^T · RMSNorm(k)).
The query q_l = w_l is a single learned vector per layer, a d- dimensional parameter that's fixed after training. Critically, it does not depend on the input token. This is a deliberate design choice: making it input-dependent would improve quality slightly (the ablations confirm this, lowering loss from 1.737 to 1.731) but would require a full d×d projection per layer and break the ability to batch queries across layers, which is essential for the efficiency tricks that make this work at scale.
The keys k_i are the actual layer outputs v_i passed through RMSNorm. The normalization is important: without it, layers with naturally larger output magnitudes would dominate the softmax regardless of their actual relevance. RMSNorm forces all keys to the same scale so the competition is purely about direction, not magnitude.
What the Network Actually Learns
One of the most interesting parts of the paper is the visualization of the learned attention weight matrices: what they call the depth mixing matrix. After training, the pattern reveals these things:
- Locality is still dominant**.** Each layer attends most strongly to its immediate predecessor. The diagonal is the brightest. Standard residual-like behavior is the default: the network learns to rely on the nearby context most of the time.
- But real skip connections emerge**.** There are systematic off-diagonal concentrations. Certain layers reach back several steps to earlier representations, forming learned shortcuts that the fixed residual couldn't express. Layer 4 attending strongly to very early sources, for instance, is something the network discovered entirely on its own.
- The embedding persists. The initial token embedding (source 0) retains non-trivial attention weight all the way through the network, particularly in pre-attention layers. The network has learned that the raw token identity is worth preserving access to, even dozens of layers deep.
- Attention vs. MLP layers specialize**.** Pre-attention layers maintain broader receptive fields across depth, while pre-MLP layers show sharper diagonal reliance on recent representations. This makes intuitive sense: attention already routes information across the sequence, so it benefits from wider depth access; MLPs tend to operate more locally.
The Efficiency Problem and Block AttnRes
Full AttnRes has one obvious problem at scale: you need to store every layer's output for every token, and pass it across pipeline stages during distributed training. Memory grows as O(L·d), which is prohibitive for large models on current hardware.
The solution is Block AttnRes, and it's clean. Instead of attending over all L individual layer outputs, you:
- Divide the L layers into N blocks (empirically, N ≈ 8 works well)
- Within each block, accumulate layer outputs the old-fashioned way — just sum them
- Across blocks, apply softmax attention over the N block-level summaries
Memory drops from O(L·d) to O(N·d). With N=8, you're storing 8 hidden states per token instead of 128 or however many layers you have.
The block count N interpolates between two extremes: N=1 gives you standard residual connections (with the embedding isolated), and N=L gives you Full AttnRes. The ablations show that N≈8 recovers most of the gain of full attention, with graceful degradation as you increase block size.
There are two additional infrastructure tricks that make this practical at scale:
- Cross-stage caching: In pipeline-parallel training, each stage normally retransmits all accumulated block representations when it hands off to the next stage, leading to O(C²) communication where C is the number of pipeline chunks. By caching previously received blocks on each physical stage, you only need to transmit the incremental new blocks at each transition. Communication drops from O(C²) to roughly O(P²·V) where P is physical stages and V is virtual stages, a V× improvement.
- Two-phase inference: During inference, since the pseudo-query vectors
w_lare fixed parameters (not computed from the input), you can batch all S queries within a block into a single matrix multiplication against the cached block representations. This amortizes memory access across the whole block, bringing per-layer I/O from O(L·d) down to O((S+N)·d). The result: less than 2% latency overhead on typical inference workloads.
Does It Actually Help?
The scaling law experiments are convincing. Across five model sizes, both Full and Block AttnRes consistently outperform the baseline, with the improvement holding across the full compute range rather than being a narrow regime effect. Block AttnRes reaches the same validation loss as the baseline trained with 1.25× more compute.
For the flagship 48B parameter model (3B activated, MoE architecture) pre-trained on 1.4T tokens, the downstream results show improvements across all evaluated benchmarks. The gains are most pronounced on multi-step reasoning tasks: GPQA-Diamond improves by 7.5 points, Math by 3.6 points, HumanEval by 3.1 points. Knowledge-retrieval benchmarks like MMLU and TriviaQA also improve, but more modestly. This pattern is consistent with the hypothesis: better depth-wise information flow helps most when later layers need to build on specific intermediate computations, which is exactly what reasoning tasks require.
The training dynamics tell a clear mechanistic story. The baseline shows the classic PreNorm dilution pattern: output magnitudes growing monotonically with depth, gradients distributing unevenly across layers (disproportionately large in early layers). Block AttnRes shows bounded, periodic output magnitudes. Each block boundary "resets" the accumulation via selective aggregation and substantially more uniform gradient flow across all depths.
The Broader Picture: A Unified View of Residuals
One of the paper's more theoretical contributions is showing that all the residual variants you've heard of, standard residuals, Highway networks, ReZero, LayerScale, Hyper-Connections, DenseFormer, can be written as instances of a depth mixing matrix M, where M[i→l] is the weight layer l assigns to the output of layer i.
- Standard residuals: M is all-ones lower-triangular. Fixed, uniform, no selectivity.
- Highway networks: M is 1-semiseparable. Input-dependent gates, but still conditioned only on the immediately preceding state.
- (m)HC: M is m-semiseparable. Multiple streams with learned mixing, closer to linear attention over depth.
- AttnRes: M is dense and rank-L. Full softmax attention over depth, input-dependent via the kernel.
Through this lens, the paper makes the neat observation that most prior residual variants are doing linear attention over depth (the kernel decomposes as a dot product of feature maps, which collapses to a recurrence), while AttnRes is doing softmax attention over depth. This is the same transition that proved transformative when applied to sequences and the paper is betting it will do the same for depth.
What to Take Away
AttnRes is not a radical departure from the transformer architecture. It's a targeted intervention on one specific component, the residual connection, that has remained essentially unchanged since 2015. The implementation is simple enough to fit in a few dozen lines of PyTorch. The overhead at inference is under 2%. And it fixes a real, theoretically motivated problem: uniform accumulation causing dilution, information loss, and uneven gradient flow.
The depth-sequence duality framing is the paper's most intellectually satisfying contribution. The history of deep learning is full of insights migrating from one dimension to another and this one has a clean story: RNNs over time became transformers, and now uniform residuals over depth are becoming depth-wise attention. Whether this becomes as consequential as the original attention mechanism is a question future work will answer, but the scaling evidence so far suggests the direction is real.
Check out the paper here: Attention Residuals


