MCP: The Protocol, the Plumbing, and the Gateway
Vrinda Kohli
Jun 01, 2026 · 12 min read

If you've spent any time around AI tooling in the last year, you've probably heard the phrase "Model Context Protocol" thrown around, usually followed by the analogy "it's USB-C for AI." It's a useful starting point, but it's also where most explanations stop. This post starts there too, and then keeps going, all the way down to what's actually moving on the wire when your agent calls a tool.
The problem MCP exists to solve
LLMs, on their own, are isolated. They know what they were trained on, and nothing else. The moment you want one to read your calendar, query your production database, or open a pull request, you have to glue it to the outside world.
For a while, every team did this gluing themselves. Each application invented its own way of describing tools, passing arguments, handling auth, and streaming results back. The result was the M × N problem: if you had M AI applications and N tools, you had M × N bespoke integrations to maintain. Adding a new tool meant updating every app. Adding a new app meant re-integrating every tool.
MCP, introduced by Anthropic in late 2024, collapses that into M + N. Build an MCP server for your tool once, and any MCP-compatible client can use it. Build an MCP client into your AI app once, and it can use the entire MCP ecosystem.
That's the USB-C analogy, and at this altitude it holds up well.
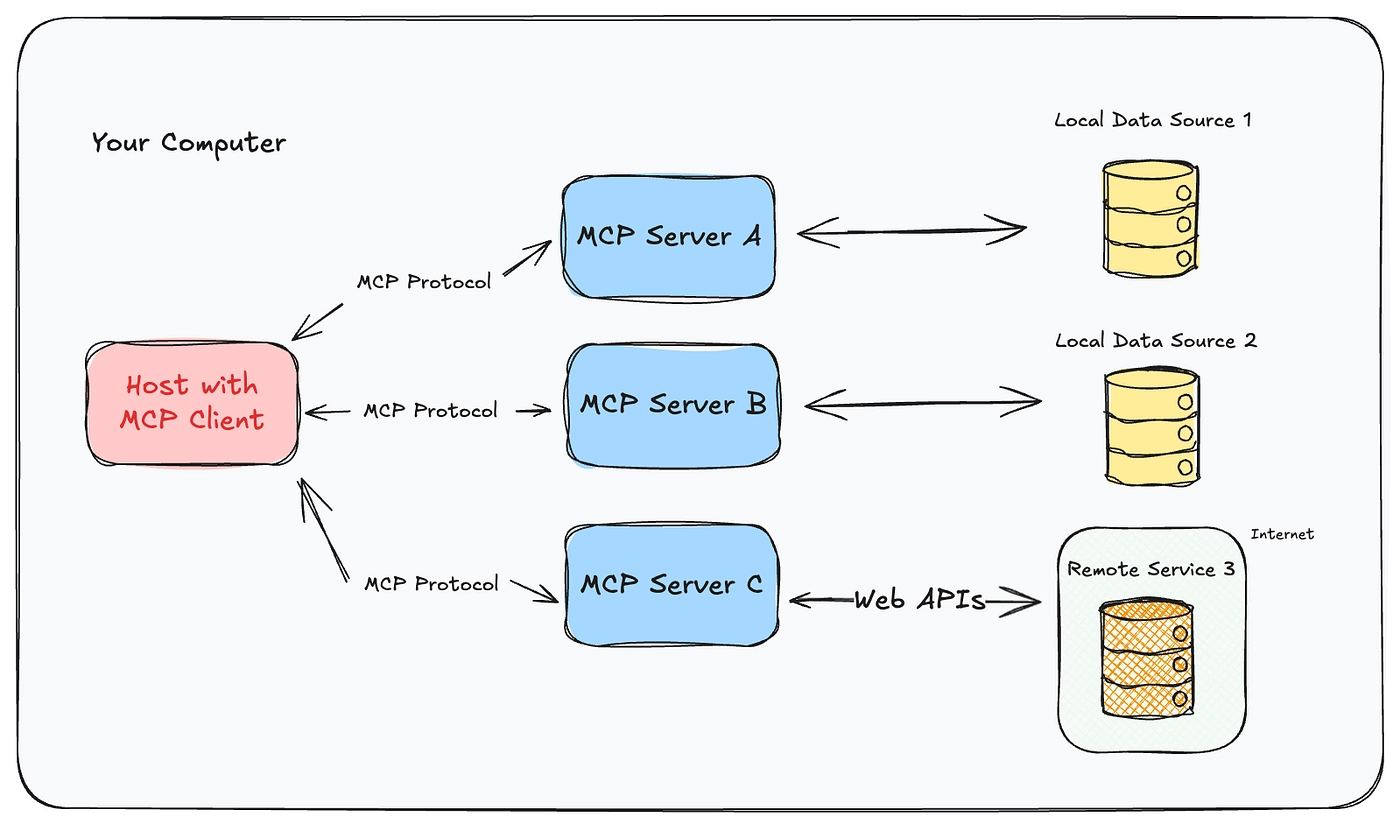
The three roles
MCP defines a client-host-server architecture. The three roles are:
- Host: the AI application the user actually interacts with. Claude Desktop, Cursor, an IDE plugin, your custom agent. The host is where the LLM lives and where the user types.
- Client: a lightweight protocol component that lives inside the host. Each client maintains a 1:1 stateful connection with exactly one server. A host can run many clients in parallel, each isolated from the others.
- Server: an independent process that exposes some capability: filesystem access, a GitHub API wrapper, a Postgres query tool, a vector store, whatever. Servers can run locally (as a subprocess of the host) or remotely (as a hosted service).
The isolation is deliberate. If your GitHub server gets compromised or misbehaves, it can't poke at the session your Postgres server has open. The host is the trust boundary; each client-server pair is its own sandbox.
What servers actually expose
A server doesn't just say "here are my tools." MCP defines three distinct primitives, each with different semantics around who controls invocation:
- Tools: model-controlled. Executable functions the LLM decides to call.
create_issue,run_query,send_email. This is the one people think about first because it's where the action is. - Resources: application-controlled. Read-only data the host can pull in as context. File contents, database rows, API responses. The host decides when to attach these; the model doesn't invoke them.
- Prompts: user-controlled. Reusable templates the user invokes explicitly, usually through a slash command or menu. "Summarize this PR," "draft a standup update."
That control distinction matters more than it looks. It maps cleanly onto the security model: the model can call tools (potentially dangerous, needs guardrails), the app pulls resources (the app is responsible), the user fires prompts (explicit consent). Conflating them, as a lot of pre-MCP tool-use schemes did, leads to muddled trust assumptions.
Every primitive type has the same shape of methods: a list method for discovery (tools/list, resources/list, prompts/list) and a way to retrieve or execute (tools/call, resources/read, prompts/get).
Conceptually, that's MCP. Now let's look at how it actually works
The wire format: JSON-RPC 2.0
Under the hood, every MCP message is a JSON-RPC 2.0 message. This is because Anthropic borrowed heavily from the Language Server Protocol (LSP), which solved an almost identical problem for IDEs and language servers a decade earlier. Why reinvent the wheel when LSP’s is already round, amirite?
A tool call looks like this on the wire:
{
"jsonrpc": "2.0",
"id": 1,
"method": "tools/call",
"params": {
"name": "get_weather",
"arguments": { "city": "London" }
}
}
And the response:
{
"jsonrpc": "2.0",
"id": 1,
"result": {
"content": [
{ "type": "text", "text": "London: 14°C, light rain" }
]
}
}
Errors use the standard JSON-RPC error envelope:
{
"jsonrpc": "2.0",
"id": 1,
"error": {
"code": -32000,
"message": "Tool execution failed",
"data": { "details": "..." }
}
}
Three message kinds exist: requests (have an id, expect a response), responses (correlate by id), and notifications (no id, fire-and-forget, used for things like progress updates and resource-change events).
All messages are UTF-8 encoded. The protocol is stateful: a session is established when the connection opens and maintained for its lifetime.
The session lifecycle
MCP connections aren’t simply just opened and used. Every MCP session goes through three phases:
- Initialization. The client sends an
initializerequest advertising its protocol version and capabilities. The server responds with its own version and capabilities. This is capability negotiation. Both sides learn what the other supports before any real work happens. If the client advertises support for sampling and the server doesn't, the server knows not to ask. If the server doesn't listpromptsin its capabilities, the client knows not to callprompts/list. - Operation. The actual work.
tools/list,tools/call,resources/read, notifications flying in both directions. Both sides can initiate requests as it's bidirectional, not strictly client-pull. - Shutdown. Graceful termination. There's no dedicated shutdown message; either side just closes the transport. Implementations are expected to handle cleanup, in-flight request cancellation, and timeouts on their own.
Capability negotiation is the part that makes MCP version-tolerant. The spec evolves (it has revised several times since November 2024), and as long as both sides honestly declare what they implement, mismatches degrade gracefully instead of hard-failing.
Transports: how the bytes actually move
JSON-RPC says nothing about transport. MCP defines two standard ones:
stdio
The client launches the server as a subprocess and talks to it over stdin/stdout. Each message is one line of UTF-8 JSON, newline-delimited, with no embedded newlines. The server can write logs to stderr; it must not write anything to stdout that isn't a valid MCP message.
This is the simplest possible transport. No network stack, no auth, no serialization framing beyond newlines. Latency is essentially the cost of a JSON parse. It's ideal for local tools: filesystem servers, git wrappers, anything that runs alongside your IDE.
The trade-off is operational. Stdio is a process-per-user model. Fifty developers across eight servers means roughly 400 concurrent processes spread across 50 laptops. There's no central point to apply auth, audit, or rate limiting. You'd have to reconstruct identity out-of-band, per host. Fine for individual use, painful at organizational scale.
Streamable HTTP
This is the remote transport, introduced in the 2025-03-26 spec revision, replacing the earlier HTTP+SSE design. The server exposes a single endpoint (e.g., https://example.com/mcp) that accepts both POST and GET.
- POST: the client sends JSON-RPC messages. The server can respond with either a single JSON body (for quick operations) or upgrade the response to a Server-Sent Events stream (
Content-Type: text/event-stream) for long-running calls that need to push progress updates. - GET: the client can open a long-lived SSE connection to receive server-initiated messages (notifications, requests for sampling, etc.).
Sessions are tracked via the Mcp-Session-Id header. This is what makes the transport stateful even though HTTP itself isn't.
A question that comes up: why not WebSockets? They'd seem like the obvious fit for bidirectional streaming. The answer is pragmatic. WebSocket upgrades only work over GET, which complicates POST-based RPC flows. Browsers can't attach Authorization headers to WebSocket handshakes, which makes auth awkward. And for the common case of a quick request-response, the WebSocket upgrade dance is pure overhead. Streamable HTTP keeps the simple cases simple and only pays for streaming when you need it.
Streamable HTTP is also what enables the enterprise deployment story: stick an API gateway in front, terminate auth and TLS, route to horizontally-scaled MCP server instances, audit at the gateway. None of that is possible with stdio.
Auth: OAuth 2.1
For remote servers, MCP mandates OAuth 2.1 (a profile of OAuth 2.0 that bakes in modern security practices: PKCE everywhere, no implicit flow, no password grant). The client obtains a token through a standard OAuth flow and presents it as a bearer token on HTTP requests.
This is one of the spec changes that gets the least fanfare but matters the most. Pre-MCP tool integrations were a wasteland of bespoke auth schemes. We had API keys in environment variables, hardcoded tokens, "just trust the subprocess" chaos. Mandating OAuth 2.1 for remote servers means that every MCP-compatible host gets a sane auth story for free, and every MCP server vendor can plug into existing identity providers without inventing anything.
For stdio servers, there's no transport-layer auth at all. The server inherits the process environment, which is both the strength (simple) and the weakness (no centralized control).
When one server isn't enough: the MCP gateway
Here's what happens once an organization moves past the proof-of-concept stage. Your team has three MCP servers in production. Then it's eight. Then it's twenty, because every team wants their own. Each one has its own URL, its own auth setup, its own deployment story. Each AI client has to be configured with the full list. When a server moves or a new one ships, every client needs updating. Auth is duplicated across servers. There's no consolidated audit trail. No one can answer "which agents called which tools last week" without grepping across twenty log streams.
This is the operational chaos that MCP, on its own, doesn't solve. The protocol standardizes communication; it does not standardize governance. That gap is what an MCP gateway fills.
What a gateway actually is
An MCP gateway is a reverse proxy that speaks MCP. From the client's perspective, the gateway is an MCP server: it exposes the standard tools/list, tools/call, resources/read methods. From the backend servers' perspective, the gateway is a client. It sits in the middle, terminates connections from clients, and routes them to the appropriate downstream server.
This collapses an N-to-N mesh into a 1-to-N hub-and-spoke. Clients are configured with one URL. The gateway maintains the server registry internally. Adding a server is an admin action, not a fleet-wide config change.
If you've worked with API gateways, the mental model is similar, but the differences matter. An API gateway brokers stateless HTTP calls. An MCP gateway brokers stateful, session-aware, often bidirectional JSON-RPC sessions. It needs to understand the tools/list → tools/call cycle, propagate user identity across multi-step agent workflows, and maintain session continuity for long-running tasks. It enforces policies at the semantic layer (which tool can this user call) rather than just the HTTP layer (can this user hit this URL).
What the gateway is doing
A production-grade gateway typically handles five concerns:
- Auth termination and identity propagation. The OAuth 2.1 dance happens at the gateway, against your existing IdP (Okta, Azure AD, whatever). Downstream servers don't reimplement auth. Instead, they trust the gateway and receive a propagated identity. This is also where SSO and federated identity slot in.
- Authorization and RBAC. Authentication answers "who are you;" authorization answers "what can you do." The gateway enforces tool-level access policies: this team can call
create_issue; that agent cannot touchdelete_user. Without this layer, every server reimplements auth, badly. - Audit and observability. Every request and response flows through one chokepoint, so every action gets logged with full context (which user, which agent, which tool, which arguments, what came back). This is what makes "show me everything the procurement agent did last Tuesday" answerable instead of aspirational.
- Rate limiting, quota, and cost control. Agents loop. An agent stuck in a retry loop can hammer a downstream API into oblivion or run up an unexpected bill. The gateway is where you put per-user, per-tool, per-tenant limits.
- Tool aggregation and discovery. When a client calls
tools/list, the gateway can merge tools from many backend servers into a single response, or filter that list per-user, so users only see the tools they're permitted to call. This is where the gateway stops being just a proxy and starts being a registry.
Some gateways layer on additional things: prompt-injection filtering, response sanitization to strip secrets before they reach the model, context trimming to cut token waste, semantic caching of tool results. The boundary between "gateway" and "AI control plane" gets fuzzy at the high end.
Where it fits in the architecture
The flow with a gateway looks like this:
[Host + Client] ──HTTPS──> [MCP Gateway] ──┬──> [GitHub MCP Server]
▲ ├──> [Postgres MCP Server]
│ ├──> [Slack MCP Server]
│ └──> [Internal Tools MCP Server]
▼
[IdP, Audit Log, Policy Engine]
The client opens one Streamable HTTP session to the gateway. The gateway handles auth against the IdP, applies policy, and routes the JSON-RPC messages to the right downstream server which may itself be remote (another Streamable HTTP target) or local to the gateway (stdio subprocess managed by the gateway). The downstream servers don't know or care that there's a gateway in front of them; they speak plain MCP.
This is also why the spec's decision to mandate OAuth 2.1 over Streamable HTTP matters so much. Because the transport is just HTTP with a session header, gateways can be built with conventional tooling (reverse proxies, service meshes, API gateway platforms) extended to understand JSON-RPC semantics. If MCP had picked WebSockets or a custom binary protocol, the gateway ecosystem would have been much harder to bootstrap.
When you actually need one
For an individual developer running Claude Desktop with three stdio servers, a gateway is overkill: you don't have an N-to-N problem yet. The point at which it starts to pay off is roughly when any of these become true: you have more than a handful of servers, more than one team using them, compliance or audit requirements, multi-tenant deployments, or any agent that runs unattended in production. Below that line, stdio and direct connections are fine. Above it, the gateway is what makes the system operable.
Where Bifrost comes in
This is the problem we built Bifrost's MCP Gateway to solve. Bifrost started as an LLM gateway, a unified plane for managing providers, keys, routing, and costs across the AI stack. As teams moved from single-model calls to full agent workflows, they started wiring MCP servers through it: one for files, one for search, one for internal tools, then ten more. The gateway handled it. But as MCP adoption scaled into production, two problems kept surfacing: no clear control over which tools agents could call, and token costs that exploded in ways nobody noticed until the bill arrived.
Bifrost MCP Gateway addresses both. It exposes every connected MCP server through a single /mcp endpoint that any MCP-compatible client (Claude Code, Cursor, Claude Desktop, custom agents) can point at unmodified, and adds the governance and cost-control layer the protocol itself doesn't provide:
- Virtual Keys: scoped credentials issued per consumer, with per-tool (not just per-server) allowlists. The model never sees definitions for tools outside its scope.
- MCP Tool Groups: named collections of tools you attach to keys, teams, customers, or providers, resolved at request time in memory.
- Audit logging: every tool call as a first-class log entry: tool name, source server, arguments, result, latency, virtual key, and parent LLM request.
- Per-tool cost tracking: pricing config per MCP client, so tool costs sit alongside LLM token costs in one view.
- Code Mode: the headliner. Instead of injecting every tool definition into context on every request, Bifrost exposes tools as a virtual filesystem of Python stub files. The model reads only what it needs, writes a short orchestration script, and Bifrost executes it in a sandboxed Starlark interpreter. Intermediate results stay inside the sandbox; only the final output returns to the model.
- Full transport coverage: STDIO, HTTP, SSE, and in-process via Go SDK, with OAuth 2.0 (PKCE, dynamic client registration, auto token refresh) and header-based auth.
- Health monitoring and tool sync: per-client health checks with automatic reconnects and periodic refresh to pick up new tools from upstream servers.
- Configurable autonomy: manual approval by default, with per-tool auto-execute allowlists for agent loops that need to run unattended.
Code Mode is the part worth dwelling on for a moment because it changes the economics of running MCP at scale. The default execution model loads every tool definition into context on every request, five servers with 30 tools each is 150 definitions before the model reads a single word of your prompt. The standard advice is "trim your tool list," which is just trading capability for cost. Code Mode trades neither. Across three rounds of controlled benchmarks scaling from 96 to 508 tools, input tokens dropped by 58.2%, 84.5%, and 92.8% respectively, with task pass rate holding at 100% throughout. The savings compound with scale, because classic MCP's cost grows with catalog size while Code Mode's cost is bounded by what the model actually reads.
The broader point: sitting in the middle of every tool call gives the gateway a perch from which to reshape how the protocol is used without changing what it speaks. Clients still speak plain MCP. Servers still speak plain MCP. The gateway is where governance, cost control, and execution-pattern improvements all land, and that's the kind of leverage the M+N standardization story enables almost by accident. Once everyone agrees on the wire format, you can do interesting things in the middle.
What this enables that wasn't there before
Pull the layers back together and the design choices start to look coherent rather than arbitrary.
JSON-RPC because it's boring, proven, and LSP showed it works for exactly this shape of problem. Stateful sessions because tool use is inherently multi-turn and you want capability negotiation to happen once, not on every call. Two transports because local and remote have genuinely different operational requirements and one-size-fits-all would have been worse for both. Three primitives because conflating model-controlled, app-controlled, and user-controlled invocation is where trust models go to die. OAuth 2.1 because every other answer to "how does auth work" has been tried and found wanting.
None of these pieces are individually novel. What's novel is that they're now standard. An agent built against MCP today can use any of the thousands of community servers that have shipped in the year since launch, without anyone writing glue code. The M + N math is no longer aspirational.
The interesting question now isn't whether MCP wins; it has reached the point where the ecosystem effects are self-sustaining. The interesting question is what gets built on top, once "connect this model to that system" stops being the hard part.