Understanding RAG Pipelines: Architecture, Challenges, and Best Practices

Retrieval-Augmented Generation has emerged as a foundational architecture for enterprise AI applications. According to recent surveys, over 60% of organizations are developing AI-powered retrieval tools to improve reliability and reduce hallucinations in their AI systems. For AI engineers and product managers building context-aware applications, understanding RAG pipelines is essential for delivering accurate, trustworthy AI solutions.
What is Retrieval-Augmented Generation?
Retrieval-Augmented Generation is a technique for enhancing the accuracy and reliability of generative AI models with facts fetched from external sources. Rather than relying solely on knowledge from training data, RAG systems retrieve relevant information from external knowledge bases at query time and feed this context to the language model.
RAG provides several benefits, including empowering LLM solutions with real-time data access, preserving data privacy, and mitigating LLM hallucinations by supplying the LLM with factual information. This makes RAG particularly valuable for enterprise applications like customer support chatbots, internal knowledge management systems, and compliance-related queries where accuracy and up-to-date information are critical.
Core Architecture of RAG Pipelines
RAG pipelines consist of two distinct phases that work together to deliver context-aware responses.
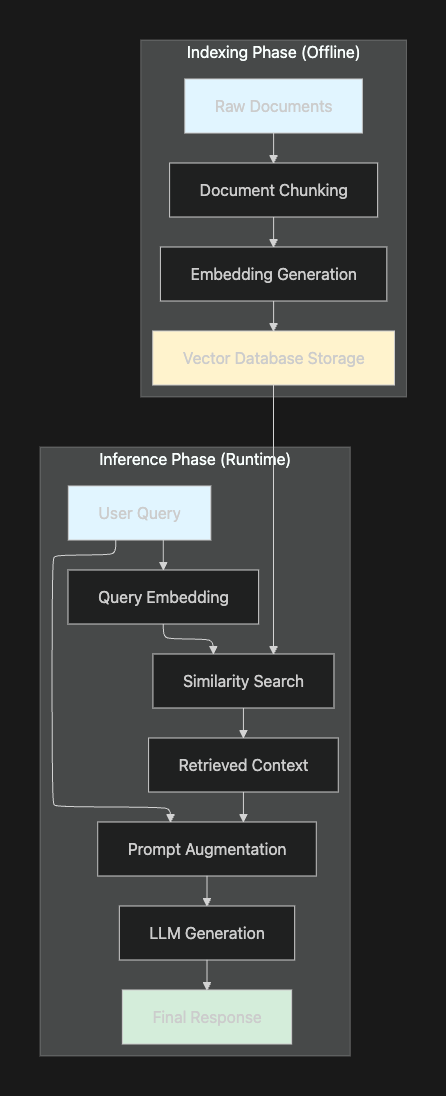
The Indexing Phase
The indexing phase typically involves four steps: document preparation and chunking, vector indexing, retrieval and prompt augmentation. During this phase, data from various sources undergoes several transformations:
Data Loading and Processing: Documents from databases, APIs, or file systems are ingested into the pipeline. Large documents are divided into smaller pieces, for instance, sections of no more than 500 characters each. This chunking strategy ensures that retrieved context fits within model token limits while maintaining semantic coherence.
Embedding Generation: Text chunks are converted into dense vector representations using embedding models. These embeddings capture semantic meaning, enabling similarity-based retrieval that goes beyond simple keyword matching.
Vector Storage: For quick similarity searches, LLM systems use vector databases; these databases are typically used to supply context or domain knowledge for LLM queries. Popular vector database solutions include Pinecone, Milvus, and FAISS, each offering different performance characteristics and scaling capabilities.
The Inference Phase
When a user submits a query, the inference phase executes in real-time:
Query Processing: The user's question is converted into an embedding vector using the same embedding model applied during indexing.
Retrieval: Given a user input, relevant splits are retrieved from storage using a Retriever. The system performs similarity search against the vector database to identify the most semantically relevant document chunks.
Augmentation: Retrieved context is combined with the original query to create an augmented prompt. This enriched prompt provides the language model with specific, relevant information to ground its response.
Generation: The language model processes the augmented input to generate a coherent, informative, and contextually relevant response. The model can now reference specific facts from the retrieved context rather than relying solely on its training data.
Critical Challenges in RAG Implementation
While RAG offers significant advantages, implementing production-grade systems introduces several technical challenges that directly impact system reliability.
Retrieval Quality
Even the most powerful LLMs can generate poor answers if they retrieve irrelevant or low-quality documents. The retrieval component serves as the foundation for answer quality, if relevant context isn't retrieved, the generation model cannot produce accurate responses regardless of its capabilities.
Studies show that improving retrieval recall from 80% to 95% may only improve answer quality by 5-10% if the generation model poorly utilizes retrieved context. This highlights the importance of optimizing both retrieval accuracy and the model's ability to effectively leverage retrieved information.
Context Window Constraints
RAG systems must fit retrieved context within model context windows alongside instructions and conversation history. Teams often evaluate retrieval quality assuming unlimited context availability, failing to account for the truncation or prioritization required in practice. Balancing the number of retrieved documents with context window limitations represents a constant optimization challenge.
Dynamic Data and Evaluation Drift
The frequent interaction of RAG pipelines with evolving knowledge bases means that evaluation results soon become outdated. As knowledge sources change, previously accurate retrieval strategies may degrade. This necessitates continuous monitoring and periodic re-evaluation of system performance.
Hallucination Risks
Research from Stanford's AI Lab indicates that poorly evaluated RAG systems can produce hallucinations in up to 40% of responses despite accessing correct information. Even when relevant context is retrieved, generation models may still produce unfaithful responses that contradict or fail to utilize the provided information.
Essential Evaluation Metrics for RAG Systems
Systematic evaluation requires measuring both retrieval and generation components across multiple dimensions.
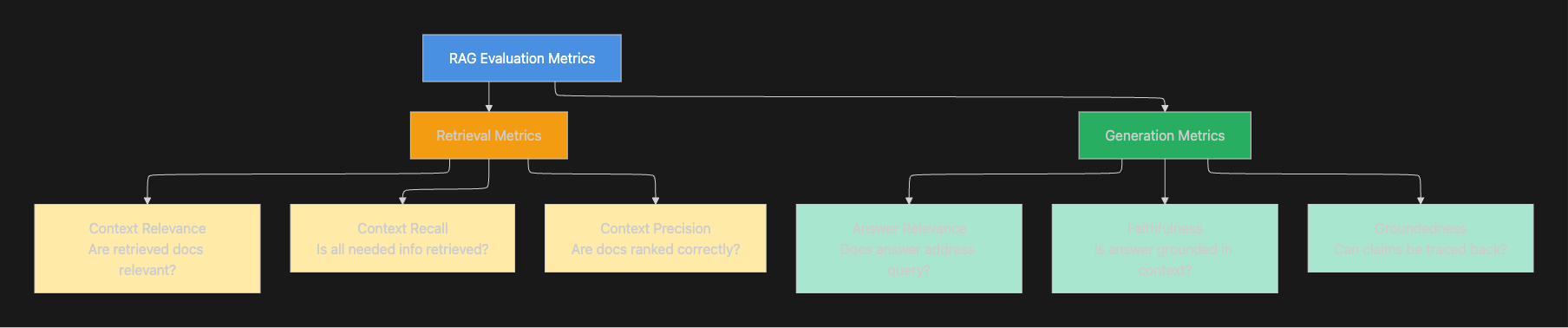
Retrieval Metrics
Context Relevance: This metric measures how relevant the retrieval context is to the input. It assesses whether the retrieval system successfully identified semantically relevant documents for the query.
Context Recall: This metric measures whether the retrieval context contains all the information required to produce the ideal output for a given input. High recall ensures that necessary information is available for answer generation.
Context Precision: This metric evaluates whether the retrieval context is ranked in the correct order, with higher relevancy documents appearing first for a given input. Proper ranking ensures the most relevant information appears within context window constraints.
Generation Metrics
Answer Relevance: This metric measures how relevant the generated response is to the given input. It evaluates whether the model actually addressed the user's question.
Faithfulness: This metric determines whether the generated response contains hallucinations relative to the retrieval context. Faithfulness checks ensure that answers are grounded in the provided context rather than the model's parametric knowledge.
Groundedness: This metric measures the extent to which the generated text aligns with the factual information retrieved from the source documents. It verifies that claims in the response can be traced back to retrieved content.
Best Practices for RAG Pipeline Development
Implement Comprehensive Evaluation Frameworks
Measuring against a gold standard with an LLM-as-a-judge approach is the best method for evaluating LLMs. Modern evaluation frameworks like DeepEval, TruLens, and RAGAS provide automated evaluation capabilities that streamline the testing process.
However, aggregate metrics like average accuracy or precision obscure systematic failure patterns. Teams should implement detailed failure analysis that segments performance by query characteristics, topics, or user types to identify specific areas requiring improvement.
Adopt Iterative Testing Strategies
Teams should only change one variable at a time between test runs. By systematically modifying individual components (whether retrieval strategy, chunk size, embedding model, or generation prompt) and measuring the impact on evaluation metrics, teams can identify which changes actually improve system performance.
Teams should track longitudinal performance over a staggered time period to identify model drift and measure whether improvements stick. Continuous evaluation prevents performance degradation as knowledge bases and user patterns evolve.
Balance Multiple Objectives
Optimizing for single metrics often degrades other dimensions. For example, increasing the number of retrieved documents may improve completeness but hurt conciseness and latency. Production RAG systems require balancing retrieval precision, answer quality, response latency, and computational cost.
Configure Retrieval Components Strategically
Teams need to choose the right similarity metric to get the best retrieval quality. Metrics used in dense vector retrieval include Cosine Similarity, Dot Product, Euclidean Distance, and Manhattan Distance. The choice of similarity metric should align with the embedding model's training approach and the semantic relationships in your domain.
For many applications, hybrid search strategies combining dense vector retrieval with traditional keyword-based methods provide superior results compared to either approach alone.
How Maxim Accelerates RAG Development and Optimization
Building reliable RAG systems requires extensive experimentation, evaluation, and monitoring across the development lifecycle. Maxim's platform provides specialized capabilities for each stage of RAG development:
Experimentation and Prompt Optimization
Maxim's Playground++ enables rapid iteration on RAG prompts and retrieval strategies. Teams can connect directly to vector databases and RAG pipelines, then compare output quality, latency, and cost across various combinations of retrievers and generators without code changes.
Comprehensive RAG Evaluation
Through Maxim's evaluation framework, teams can assess RAG systems using both automated and human evaluation methods. The platform includes pre-built evaluators specifically designed for RAG metrics including retrieval relevance scoring, context utilization assessment through faithfulness checks, and hallucination detection.
Custom evaluators can be configured at the session, trace, or span level to address domain-specific quality requirements. This flexibility ensures evaluation aligns with your specific application needs and quality standards.
Production Observability
Maxim's observability suite enables real-time monitoring of RAG system performance in production. Track retrieval quality, generation accuracy, and user satisfaction metrics to identify issues before they impact users. Automated evaluations based on custom rules can continuously assess in-production quality.
Data Curation for Continuous Improvement
Effective RAG evaluation requires high-quality test datasets. Maxim's data engine enables teams to curate and enrich multi-modal datasets from production logs, evaluation results, and human feedback. This continuous data curation loop ensures test suites remain representative of real-world usage patterns.
Conclusion
RAG pipelines represent a powerful approach for building AI applications that require accurate, up-to-date, and domain-specific knowledge. However, achieving production-grade reliability requires careful attention to retrieval quality, systematic evaluation, and continuous monitoring.
The challenges inherent in RAG development (from optimizing retrieval strategies to preventing hallucinations) demand specialized tooling that supports the complete development lifecycle. By implementing comprehensive evaluation frameworks, adopting iterative testing strategies, and leveraging platforms designed specifically for RAG workflows, teams can build trustworthy AI systems that consistently deliver accurate, grounded responses.
Ready to accelerate your RAG development with comprehensive evaluation and observability? Schedule a demo to see how Maxim helps teams ship reliable RAG systems faster.


