Top 5 Tools for Monitoring and Improving AI Agent Reliability (2026)

TL;DR
AI agents often fail in production due to silent quality degradation, unexpected tool usage, and reasoning errors that evade traditional monitoring. Five leading platforms address these challenges: Maxim AI provides end-to-end agent observability with simulation, evaluation, and real-time debugging. Langfuse offers open-source tracing with comprehensive session tracking. Arize AI extends ML observability to agentic systems with drift detection. Galileo specializes in hallucination detection with Luna guard models. AgentOps provides lightweight monitoring for over 400 LLM frameworks.
Agent reliability requires measuring task completion, reasoning quality, tool usage accuracy, and cost efficiency while creating continuous improvement loops from production failures to evaluation datasets.
Table of Contents
- Why Agent Reliability Monitoring Matters
- Agent Reliability Monitoring Workflow
- Top 5 Agent Reliability Tools
- Platform Comparison
- Choosing Your Stack
- Further Reading
Why Agent Reliability Monitoring Matters
AI agents represent a paradigm shift from supervised LLM applications to autonomous systems that plan, reason, use tools, and make decisions across multiple steps. This autonomy introduces failure modes that traditional LLM monitoring cannot detect. According to Microsoft Azure research, agent observability requires tracking not just outputs but reasoning processes, tool selection, and multi-agent collaboration patterns.
Unique Agent Failure Patterns
Silent Reasoning Failures occur when agents produce plausible outputs through flawed reasoning. The final answer may appear correct while the agent selected the wrong tools, ignored available information, or hallucinated intermediate steps. Traditional output-only monitoring misses these issues entirely.
Tool Selection Errors happen when agents choose inappropriate tools for tasks, pass malformed parameters despite having correct context, or create infinite loops through repeated tool calls. These failures rarely trigger error messages but degrade user experience significantly.
Multi-Step Breakdown emerges in complex workflows where early reasoning errors cascade through subsequent steps. An agent might retrieve correct documents but misinterpret them, generate accurate summaries but answer the wrong question, or complete tasks successfully but violate safety constraints.
As Maxim's agent evaluation guide explains, evaluating autonomous agents requires fundamentally different approaches than evaluating supervised LLM applications. Task completion, reasoning quality, and tool usage accuracy become primary metrics alongside traditional output quality measures.
Key Agent Reliability Metrics
Task Completion Rate measures whether agents successfully accomplish assigned objectives, typically targeting 90% or higher for production systems. This metric captures end-to-end effectiveness beyond individual step success.
Reasoning Quality assesses whether agents follow logical paths to conclusions, use available context appropriately, and justify decisions with supporting evidence. Tools like LLM-as-a-judge evaluators score reasoning coherence and soundness.
Tool Usage Accuracy evaluates whether agents select appropriate tools for tasks, provide correct parameters, and handle tool outputs effectively. Monitoring reveals patterns like tool overuse, underuse, or persistent parameter errors.
Cost Efficiency tracks token consumption, API calls, and execution time relative to task complexity. Agents that complete tasks correctly but inefficiently increase operational costs and reduce scalability.
Agent Reliability Monitoring Workflow
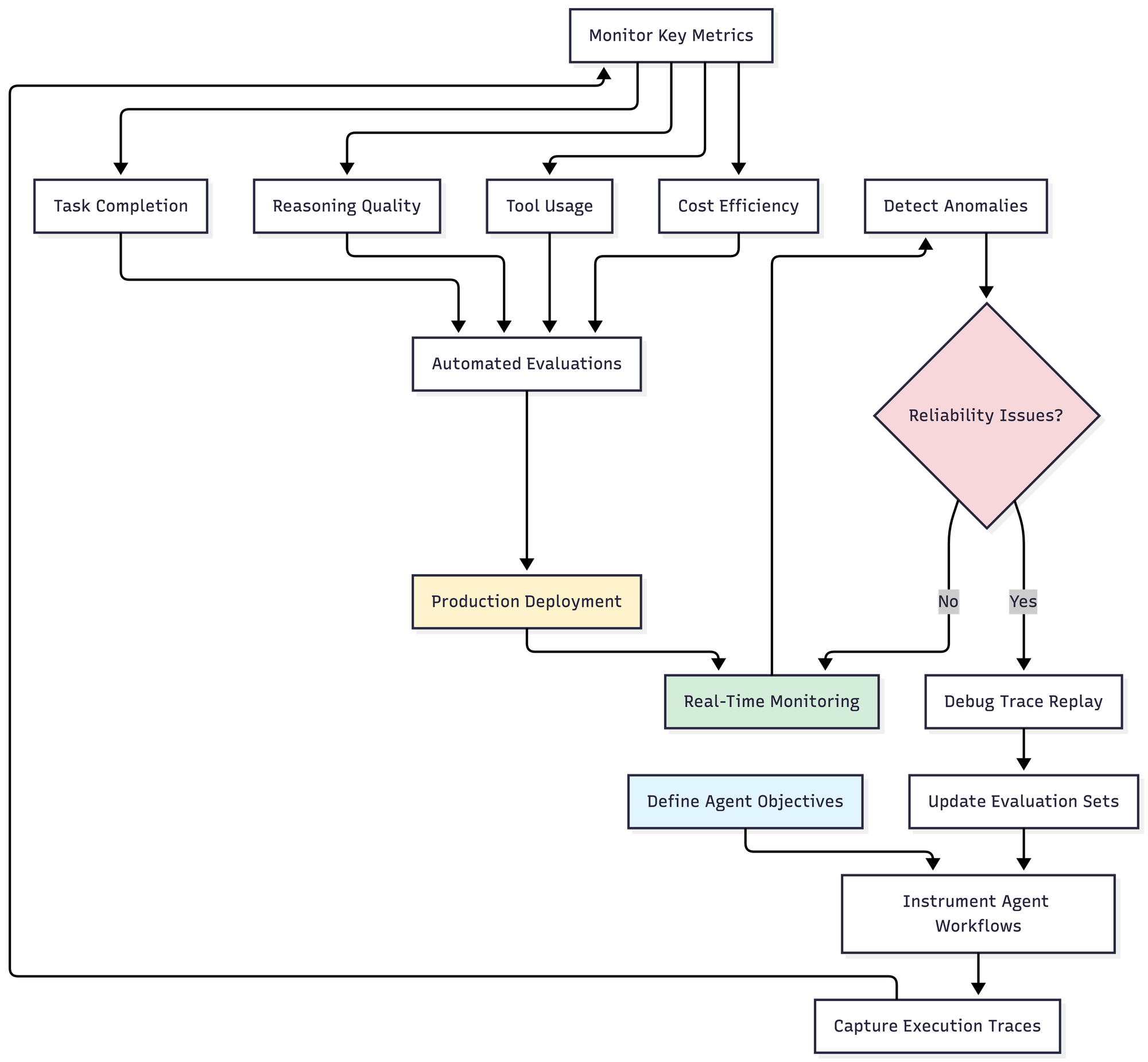
This workflow illustrates continuous agent reliability monitoring from instrumentation through production deployment and improvement. The feedback loop from anomaly detection to evaluation updates ensures monitoring adapts to emerging failure patterns.
Top 5 Agent Reliability Tools
1. Maxim AI: End-to-End Agent Observability Platform
Maxim AI provides the most comprehensive solution for agent reliability, integrating simulation, evaluation, and real-time observability in a unified platform designed specifically for autonomous AI systems.
Agent-Specific Monitoring: Unlike generic LLM observability platforms, Maxim's agent observability tracks multi-step workflows with complete context preservation. Teams monitor individual agent actions, tool calls, reasoning steps, and decision points across distributed systems. The platform provides real-time visibility into agent behavior with automated quality checks and alerting.
Simulation Before Deployment: Agent simulation capabilities enable testing across hundreds of scenarios with diverse user personas before production exposure. Teams can simulate customer interactions, evaluate agent performance at conversational and trajectory levels, and identify failure modes early. This pre-deployment validation significantly reduces production incidents.
Node-Level Debugging: Maxim enables distributed tracing across multi-agent workflows, pinpointing exactly where quality issues originate. Teams can attach evaluation metrics to specific nodes, re-run simulations from failure points, and systematically debug complex agent interactions. This granularity proves essential for multi-agent systems where failures cascade across components.
Production Feedback Loops: Data curation transforms production failures into evaluation test cases automatically. When agents produce poor results, interactions are captured with full context, enriched with correct outcomes, added to evaluation datasets, and used to validate future improvements. This continuous loop ensures monitoring stays aligned with real-world behavior.
Flexible Evaluation Framework: Choose from agent-specific evaluators including task completion scoring, reasoning quality assessment, tool usage accuracy validation, LLM-as-a-judge semantic evaluation, and human review workflows for edge cases. The platform supports both automated and manual evaluation approaches.
Best For: Teams building production agents requiring comprehensive lifecycle management, organizations needing cross-functional collaboration between engineering and product, and companies shipping autonomous AI systems 5x faster with systematic quality assurance.
Compare Maxim vs Arize | Compare Maxim vs Langfuse
2. Langfuse: Open-Source Agent Tracing
Langfuse provides comprehensive open-source observability with deep agent tracing capabilities and flexible deployment options.
Session-Level Tracking: Langfuse captures multi-turn agent interactions with user-level attribution, enabling understanding of how individual users experience agent behavior over time. This proves essential for conversational agents and customer support applications.
Detailed Trace Capture: The platform logs LLM calls, tool usage, reasoning steps, and intermediate outputs across agent workflows. Trace architecture provides visibility into nested operations for debugging complex multi-agent systems.
Prompt Management: Version control for agent prompts, A/B testing capabilities, and deployment workflows enable iteration without code changes. Teams track which prompt versions produce the best results across different agent tasks.
Deployment Flexibility: Self-host via Docker or Kubernetes for complete data control, or use a managed cloud service. The open-source nature enables customization for specific monitoring needs.
Best For: Teams requiring self-hosting for data residency, open-source priority organizations, and LangChain/LlamaIndex ecosystem users.
3. Arize AI: Enterprise ML and Agent Monitoring
Arize AI extends mature ML observability capabilities to agentic systems, making it valuable for organizations with existing ML infrastructure.
Unified ML and Agent Monitoring: Organizations running traditional ML models alongside agentic systems benefit from consolidated monitoring. Track regression models, recommendation systems, and autonomous agents in a single interface.
Drift Detection: Advanced drift monitoring catches changes in agent behavior patterns, tool usage distributions, and output characteristics before they impact user experience significantly.
Production-Scale Architecture: Arize's infrastructure handles enterprise-scale deployments with proven reliability. The platform processes billions of predictions and has established credibility through government and enterprise partnerships.
Phoenix Open Source: The Phoenix component provides open-source agent tracing and evaluation for teams wanting to evaluate before committing to managed services.
Best For: Enterprises with existing ML infrastructure, teams requiring sophisticated drift detection, and organizations in regulated industries needing comprehensive audit trails.
4. Galileo: AI-Powered Hallucination Detection
Galileo specializes in agent reliability through hallucination detection, root cause analysis, and actionable improvement recommendations.
Luna Guard Models: Distilled evaluators monitor 100% of agent traffic at 97% lower cost than LLM-as-a-judge approaches. These specialized models detect hallucinations, tool usage errors, and safety violations in real time.
Insights Engine: Analyzes agent behavior to identify failure modes, surface hidden patterns, and prescribe specific fixes. The platform provides actionable recommendations rather than just flagging issues.
Agent-Specific Evaluators: 20+ out-of-box evaluations for RAG, agents, safety, and security, plus custom evaluator support for domain-specific requirements.
End-to-End Visibility: Complete agent workflow tracking from initial input through tool usage and final output, enabling comprehensive debugging.
Best For: Teams prioritizing hallucination detection, organizations requiring real-time guardrails, and enterprises needing actionable improvement insights.
5. AgentOps: Lightweight Framework-Agnostic Monitoring
AgentOps provides developer-friendly observability supporting 400+ LLM frameworks with minimal integration overhead.
Visual Event Tracking: Track LLM calls, tool usage, and multi-agent interactions through intuitive visualizations. Rewind and replay agent runs with point-in-time precision.
Token Management: Monitor every token agent's process, visualize spending patterns, and identify cost optimization opportunities. The platform provides up-to-date price monitoring across providers.
Framework Flexibility: Support for OpenAI, CrewAI, Autogen, and hundreds of other frameworks without vendor lock-in. Integration requires minimal code changes.
Developer Focus: Simple setup with a free tier for getting started. The platform emphasizes developer experience over enterprise features.
Best For: Development teams wanting lightweight monitoring, projects using diverse agent frameworks, and startups prioritizing quick setup over advanced features.
Platform Comparison
| Feature | Maxim AI | Langfuse | Arize AI | Galileo | AgentOps |
|---|---|---|---|---|---|
| Primary Focus | Full lifecycle | Open tracing | Enterprise ML/AI | Hallucination detection | Framework-agnostic |
| Deployment | Cloud, Self-hosted | Cloud, Self-hosted | Cloud | Cloud | Cloud |
| Agent Simulation | Built-in | No | No | No | No |
| Real-Time Monitoring | Native | Standard | Advanced | Luna guards | Basic |
| Tool Usage Tracking | Comprehensive | Standard | Standard | Detailed | Visual |
| Multi-Agent Support | Node-level | Session-level | Standard | Workflow-level | Event-level |
| Production Feedback | Automated curation | Manual | Limited | Insights engine | Manual |
| Best For | Full-stack teams | Open-source priority | Enterprise ML teams | Hallucination focus | Quick setup |
Choosing Your Stack
Selection depends on agent complexity, organizational structure, and reliability requirements.
Agent Architecture Considerations: Simple task-completion agents work with lightweight tools like AgentOps. Multi-agent systems with complex workflows benefit from Maxim's node-level tracing. Agentic RAG applications requiring hallucination detection suit Galileo's Luna guards.
Team Structure: Cross-functional teams benefit from Maxim enabling product managers to configure monitoring without engineering dependency. Engineering-focused teams may prefer open-source flexibility from Langfuse. Enterprises with existing ML infrastructure leverage Arize's unified monitoring.
The Critical Question: Does the platform create continuous improvement loops from production failures to evaluation datasets? Agent reliability improves through iteration. Tools enabling feedback cycles from production monitoring to pre-deployment testing drive systematic quality gains.
Maxim's architecture exemplifies this by capturing production interactions, enabling human enrichment, converting failures into test cases, and validating improvements against expanded evaluation suites. Teams using Maxim ship autonomous agents reliably and 5x faster.
Implementation Steps: Define agent objectives and success criteria. Instrument workflows with comprehensive tracing. Establish baseline metrics for task completion, reasoning quality, and cost efficiency. Deploy automated evaluations in testing environments. Enable production monitoring with real-time alerting. Create feedback loops, adding failures to evaluation datasets.
Reference Maxim's AI reliability guide for systematic reliability frameworks.
Further Reading
Agent Evaluation and Monitoring
- Top 5 Tools for Agent Evaluation in 2026
- AI Agent Quality Evaluation: Best Practices
- Agent Tracing for Debugging Multi-Agent Systems
- Agent Evaluation vs Model Evaluation,
Platform Comparisons
- Maxim vs Arize: Agent Observability
- Maxim vs Langfuse: Monitoring Platforms
- Maxim vs LangSmith: Agent Evaluation
Conclusion
Agent reliability monitoring has evolved from optional observability to essential infrastructure for autonomous AI systems. The five platforms represent fundamentally different approaches: Maxim provides comprehensive lifecycle integration with simulation and real time debugging, Langfuse offers open-source flexibility with deep tracing, Arize extends enterprise ML monitoring to agentic systems, Galileo specializes in hallucination detection with Luna guards, and AgentOps delivers lightweight framework-agnostic monitoring.
The critical selection factor: can the platform create continuous improvement loops from production failures to pre-deployment evaluation? Agents are inherently non-deterministic and improve through iteration. Tools enabling feedback cycles from production monitoring to systematic testing drive reliability gains.
Maxim's comprehensive solution integrates agent simulation, evaluation, and observability, enabling teams to test thoroughly before deployment, monitor continuously in production, and systematically improve through automated data curation. Cross-functional collaboration features democratize agent quality across product, engineering, and QA teams.
Unlike traditional LLM monitoring, focused on output quality, agent reliability requires tracking reasoning processes, tool selection patterns, and multi-step workflow execution. Maxim's node-level tracing and simulation capabilities address these requirements specifically, helping teams ship autonomous agents reliably and 5x faster.
Ready to implement systematic agent reliability monitoring? Book a demo with Maxim to see how integrated simulation, evaluation, and observability improve agent reliability, accelerate development velocity, and enable your team to deploy autonomous AI systems with confidence.


