Top 5 RAG Evaluation Tools for Production AI Systems (2026)

TL;DR
RAG systems fail silently when retrieval selects irrelevant documents, generation hallucinates despite good context, or quality degrades undetected. Five leading platforms address these challenges:
Maxim AI integrates evaluation with simulation, experimentation, and observability for complete lifecycle management.
DeepEvals comprehensive RAG evaluation metrics
Deepchecks delivers MLOps validation with CI/CD integration.
TruLens specializes in feedback functions for iterative testing.
Langfuse offers open-source observability with comprehensive tracing.
Production RAG evaluation requires measuring retrieval precision, generation faithfulness, and end-to-end accuracy while creating continuous improvement loops from production failures back to testing.
Table of Contents
- Why RAG Evaluation Matters
- RAG Evaluation Workflow
- Top 5 RAG Evaluation Tools
- Platform Comparison
- Choosing Your Stack
- Further Reading
Why RAG Evaluation Matters
Production RAG systems fail differently than traditional software. Retrieval degrades as knowledge bases grow, LLMs hallucinate despite perfect context, and response quality declines while performance metrics stay green. According to enterprise RAG research, teams must prioritize factual grounding, retrieval quality, and compliance risks alongside accuracy.
Silent Quality Degradation occurs when retrieval relevance declines without triggering alerts. Users receive plausible but suboptimal answers. The Retrieval-Generation Disconnect happens when perfect documents are retrieved but LLMs generate responses from training data instead. Production-Testing Gaps emerge when systems perform well on curated tests but struggle with real user queries containing typos or ambiguous intent.
Without systematic evaluation, teams discover problems only when customer satisfaction drops or support tickets escalate. AI reliability demands measuring what actually matters for RAG systems.
Key Evaluation Components
Retrieval metrics include precision@k (percentage of top k documents that are relevant), recall@k (percentage of all relevant documents in top k results), mean reciprocal rank (ranking of first relevant document), and NDCG (ranking quality versus ideal ordering).
Generation metrics assess faithfulness (responses contain only context-supported information), answer relevancy (addressing specific queries), context utilization (using retrieved documents), and hallucination detection (statements without supporting evidence).
As Maxim's RAG evaluation guide explains, retrieval quality directly impacts generation quality, and poor retrieval cannot be compensated by better prompting.
RAG Evaluation Workflow
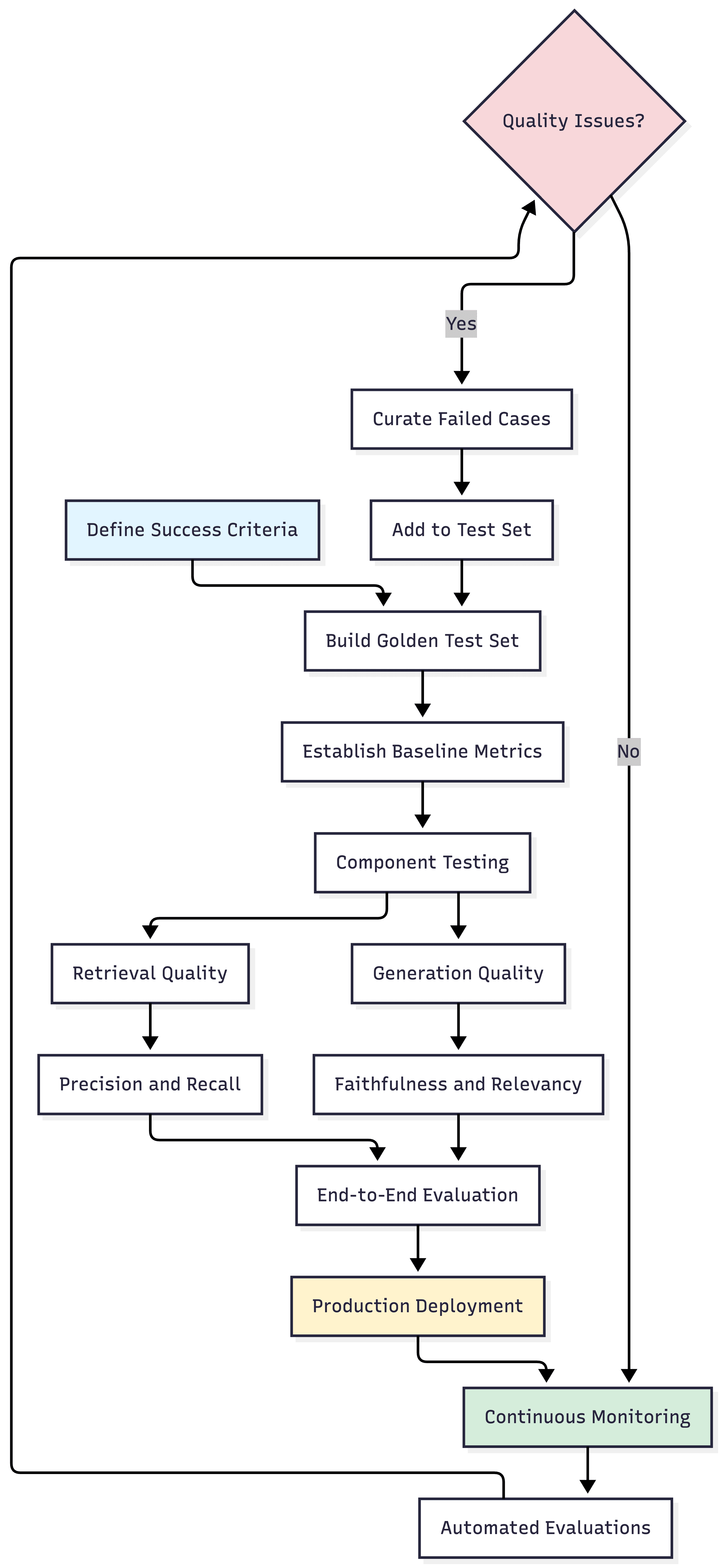
This workflow illustrates continuous RAG evaluation from initial setup through production monitoring. The feedback loop from production failures to test set expansion ensures evaluation stays aligned with real-world usage.
Top 5 RAG Evaluation Tools
1. Maxim AI: Integrated Lifecycle Platform
Maxim AI treats RAG evaluation as part of a complete AI quality lifecycle, enabling teams to ship applications reliably and 5x faster.
Unified Framework: Teams test retrieval strategies in Playground++, run systems through hundreds of scenarios with diverse personas, apply comprehensive metrics, and monitor production with automated evaluations.
Node-Level Granularity: Maxim enables node-level evaluation where teams attach metrics to specific retrieval nodes, measure generation independently, identify which component causes failures, and re-run simulations from failure points.
Production Feedback Loop: Data curation transforms production failures into test cases automatically. When queries produce poor results, interactions are captured with full context, enriched with correct answers, added to evaluation datasets, and used to validate future changes. Comm100's case study notes, "Maxim AI has significantly accelerated our testing cycles for evaluating RAG pipelines."
Flexible Evaluators: Choose from RAG-specific metrics, LLM-as-a-judge semantic evaluation, statistical evaluators, programmatic evaluators, and human review workflows. Bifrost, Maxim's LLM gateway, adds ultra-low latency routing with semantic caching reducing costs by 30%.
Best For: Cross-functional teams, RAG simulation at scale, production-to-evaluation feedback loops, and shipping AI 5x faster.
DeepEval
Platform Overview
DeepEval is a Python-first LLM evaluation framework similar to Pytest but specialized for testing LLM outputs. DeepEval provides comprehensive RAG evaluation metrics alongside tools for unit testing, CI/CD integration, and component-level debugging.
Key Features
Comprehensive RAG Metrics: Includes answer relevancy, faithfulness, contextual precision, contextual recall, and contextual relevancy. Each metric outputs scores between 0-1 with configurable thresholds.
Component-Level Evaluation: Use the @observe decorator to trace and evaluate individual RAG components (retriever, reranker, generator) separately. This enables precise debugging when specific pipeline stages underperform.
CI/CD Integration: Built for testing workflows. Run evaluations automatically on pull requests, track performance across commits, and prevent quality regressions before deployment.
G-Eval Custom Metrics: Define custom evaluation criteria using natural language. G-Eval uses LLMs to assess outputs against your specific quality requirements with human-like accuracy.
Confident AI Platform: Automatic integration with Confident AI for web-based result visualization, experiment tracking, and team collaboration.
3. Deepchecks: MLOps Validation
Deepchecks brings enterprise validation with CI/CD strength.
Multi-Dimensional Testing: Evaluates retrieval quality, generation quality, safety checks (toxicity, bias, PII), and performance metrics (latency, cost).
CI/CD Native: Run evaluation suites in GitHub Actions, block pull requests below quality thresholds, track trends, and compare versions.
Enterprise Security: On-premises deployment, SOC 2 compliance, and comprehensive audit logging.
Best For: MLOps-mature organizations and enterprise security requirements.
4. TruLens: Feedback-Driven Improvement
TruLens specializes in feedback functions for programmatic evaluation.
Feedback Architecture: Define evaluators checking groundedness, context relevance, answer relevance, and custom criteria.
Model Versioning: Track RAG versions to compare strategies, evaluate prompt variations, and identify best configurations.
Framework Integration: Native support for LangChain, LlamaIndex, and Nvidia NeMo Guardrails.
Best For: Iterative improvement workflows and framework-native integration.
5. Langfuse: Open-Source Observability
Langfuse provides open-source observability with comprehensive tracing.
Detailed Tracing: Capture LLM calls, retrieval operations, embeddings, and tool usage. Trace architecture provides visibility into nested operations.
Prompt Management: Version control for prompts, A/B testing, and deployment workflows.
Deployment Flexibility: Self-host via Docker or Kubernetes, or use managed cloud service.
Best For: Self-hosting requirements and open-source priority.
Platform Comparison
| Feature | Maxim AI | DeepEval | Deepchecks | TruLens | Langfuse |
|---|---|---|---|---|---|
| Primary Focus | Full lifecycle | Test-centric eval | MLOps validation | Feedback loops | Open observability |
| Deployment | Cloud, Self-hosted | Python library | Cloud, On-prem | Cloud | Cloud, Self-hosted |
| Production Integration | Native observability | Code-level | CI/CD focused | Dashboard | Manual |
| Simulation | Built-in | Limited | No | No | No |
| Component Testing | Node-level | Pytest-style | Standard | Intermediate | Standard |
| Best For | Full-stack teams | Python dev teams | MLOps orgs | Rapid iteration | Open-source |
Choosing Your Stack
Selection depends on organizational needs and technical requirements.
Team Structure: Cross-functional teams benefit from Maxim enabling non-technical stakeholders to configure evaluations. Engineering-heavy teams may prefer code-first tools. MLOps organizations leverage Deepchecks' CI/CD integration.
Development Stage: Early prototypes need rapid iteration (TruLens). Pre-production systems require comprehensive testing at scale (Maxim simulation). Production applications demand continuous monitoring with observability integration.
The Critical Question: Does the platform turn production failures into evaluation improvements? RAG systems improve through iteration. Platforms creating continuous loops from production monitoring to pre-deployment testing enable systematic quality gains.
Maxim's architecture captures production interactions, enables human enrichment, converts failures into test cases, and validates future changes against expanded suites.
Implementation Steps: Define success criteria for retrieval precision, generation faithfulness, and latency budgets. Build 50-100 representative queries with reference answers. Establish baseline metrics. Implement continuous evaluation in CI/CD. Enable production monitoring with 10-20% sampling. Create feedback loops adding failures to test sets.
Reference Maxim's AI reliability guide for quality criteria frameworks.
Further Reading
RAG Evaluation Fundamentals
AI Quality and Evaluation
- What Are AI Evals? Complete Guide
- AI Agent Quality Evaluation
- Agent Tracing for Debugging
- AI Reliability: Building Trustworthy Systems
Platform Comparisons
Conclusion
RAG evaluation evolved from optional testing to essential infrastructure. The five platforms represent different approaches: Maxim provides complete lifecycle integration, DeepEvals comprehensive RAG evaluation metrics, Deepchecks excels at CI/CD validation, TruLens specializes in iterative improvement, and Langfuse offers open-source flexibility.
The critical selection factor: can the platform create continuous improvement loops from production failures to pre-deployment testing? Tools enabling this feedback cycle drive systematic quality gains.
Maxim's comprehensive solution integrates evaluation with simulation, experimentation, and observability, enabling cross-functional teams to test thoroughly before deployment, monitor continuously in production, and create systematic improvement loops. Teams using Maxim ship AI applications reliably and 5x faster while maintaining quality standards.
Ready to implement systematic RAG evaluation? Book a demo with Maxim to see how integrated evaluation, simulation, and observability improve RAG quality and development velocity.


