The Ultimate Guide to Debugging Multi-Agent Systems

Multi-agent LLM systems represent the next evolution in AI architecture, where multiple specialized agents collaborate to complete complex tasks through distributed reasoning and coordination. These systems promise modular workflows, parallel execution, and emergent intelligence that can tackle problems beyond single-agent capabilities. However, production deployments reveal a sobering reality: debugging multi-agent systems is exponentially more complex than debugging traditional single-agent architectures.
Research from Microsoft and academic institutions identifies core challenges facing AI agent developers, including difficulty reviewing long agent conversations to localize errors, lack of support in current tools for interactive debugging, and the need for specialized tooling to iterate on agent configuration. When one agent makes an incorrect decision in a multi-agent system, errors cascade through the entire network, amplifying initial mistakes into system-wide failures that are notoriously difficult to trace and resolve.
This comprehensive guide explores systematic approaches to debugging multi-agent systems, drawing on recent research including the Multi-Agent System Failure Taxonomy (MAST) developed at UC Berkeley, industry best practices, and practical implementation strategies using Maxim AI's comprehensive observability and evaluation platform. Teams using Maxim's observability suite report 70% reduction in mean time to resolution for multi-agent failures compared to traditional log-based debugging approaches.
Understanding Multi-Agent System Complexity
Multi-agent systems differ fundamentally from single-agent architectures in ways that directly impact debugging complexity and operational reliability. In a single-agent system, execution follows a relatively linear or tree-based path where state management, error handling, and decision-making occur within a unified context. Multi-agent systems introduce distributed coordination, asynchronous communication, and emergent behaviors that create unique debugging challenges requiring specialized approaches.
The Coordination Challenge
The primary complexity in multi-agent systems stems from coordination requirements. Unlike single agents that maintain complete control over their execution context, distributed agents must actively communicate, synchronize state across boundaries, and coordinate actions through explicit protocols. Research from Anthropic on building multi-agent systems reveals that agents are stateful and errors compound over long-running processes, where minor system failures can become catastrophic without effective mitigations.
State distribution creates multiple failure points that simply do not exist in single-agent architectures. Each agent maintains its own internal state, context, and decision-making process. When agents need to coordinate, they must exchange information through message passing, which introduces opportunities for communication failures, message ordering violations, and state synchronization issues. These distributed state management challenges make debugging significantly more complex than traditional software debugging.
Non-Deterministic Behavior Amplification
Multi-agent systems amplify the non-deterministic nature of LLM-based applications. A single agent might produce varying outputs for the same input, but multi-agent systems multiply this variability across all participating agents. The ability of agents to choose multiple valid approaches to solve the same problem makes evaluation and debugging extraordinarily challenging. This challenge multiplies when coordination failures cascade across shared models and interconnected workflows.
Analysis of production multi-agent deployments shows that agents maintaining dynamic, context-dependent relationships result in exponential failure combinations that cannot be comprehensively mapped through traditional testing approaches. The interaction space grows combinatorially with each additional agent, making exhaustive testing impractical and debugging reactive rather than proactive.
The Multi-Agent System Failure Taxonomy
Understanding failure patterns is essential for systematic debugging. The MAST framework provides the first rigorous taxonomy of multi-agent system failures, derived from analyzing over 1,600 annotated execution traces across seven popular multi-agent frameworks including AutoGen, CrewAI, and LangGraph. The taxonomy achieved high inter-annotator agreement (Cohen's kappa = 0.88), validating its reliability for categorizing real-world failures.
MAST Failure Categories
The taxonomy identifies 14 unique failure modes clustered into three major categories, with failures distributed almost evenly across the agent lifecycle:
| Category | Failure Mode | Frequency | Description |
|---|---|---|---|
| Specification & System Design (37%) | Disobey Task Specification | 15.2% | Failure to adhere to specified constraints or requirements of a given task |
| Disobey Role Specification | 8.7% | Failure to adhere to defined responsibilities and constraints of assigned role | |
| Step Repetition | 6.9% | Unnecessary reiteration of previously completed steps causing delays or errors | |
| Loss of Conversation History | 4.8% | Unexpected context truncation or disregarding recent agent interactions | |
| Unclear Task Allocation | 3.2% | Ambiguous distribution of responsibilities among agents in the system | |
| Inter-Agent Misalignment (31%) | Information Withholding | 9.4% | Agent fails to share critical information with other agents that need it |
| Ignoring Agent Input | 8.1% | Agent disregards instructions or outputs from other participating agents | |
| Communication Format Mismatch | 7.3% | Inconsistent data formats between agents cause parsing errors and failures | |
| Coordination Breakdown | 6.2% | Agents fail to synchronize actions or maintain shared understanding of task state | |
| Task Verification (31%) | Premature Termination | 6.2% | Task ends before completion criteria are met or objectives are achieved |
| Incomplete Verification | 8.2% | Verification checks only validate partial aspects of output, missing critical errors | |
| Incorrect Verification | 13.6% | Verifier incorrectly assesses output quality, approving faulty results | |
| No Verification | 3.8% | Missing quality control mechanisms entirely in the agent workflow |
This distribution reveals that no single area dominates failure modes. Problems plague multi-agent systems throughout the entire lifecycle, from initial setup through agent collaboration to final verification and termination. Each category requires different debugging strategies and tooling approaches.
Key Insights from Failure Analysis
The MAST research provides several critical insights for debugging practitioners. First, the core problem is architectural, not model-level. Analysis shows that in several cases, using the same model in a single-agent setup outperforms the multi-agent version, pointing to systemic breakdowns in communication, coordination, and workflow orchestration rather than fundamental model limitations.
Second, failures require multi-level verification approaches. Current verifier implementations are often insufficient, with sole reliance on final-stage, low-level checks proving inadequate. Systems need intermediate checkpoints, component-level validation, and comprehensive output verification to catch errors before they cascade through the system.
Third, inter-agent communication requires more than natural language. Communication failures like information withholding, format mismatches, and ignored inputs suggest that unstructured natural language exchanges between agents are insufficient. More structured communication protocols, explicit message schemas, and standardized data formats can reduce misalignment failures significantly.
Core Debugging Challenges in Production
Research on multi-agent system development conducted through formative interviews with expert developers identifies several fundamental challenges that make debugging particularly complex in production environments.
Reviewing Long Agent Conversations
As agent conversations grow longer, traditional debugging tools fail to provide adequate visibility. Developers struggle to review extensive message histories spanning dozens or hundreds of interactions to localize where errors originated. The linear log review approaches that work for single-agent systems break down when faced with branching conversation paths, parallel agent execution, and complex interaction patterns.
The challenge intensifies when agents maintain long-running contexts across multiple tool calls and state transitions. Without the ability to pause, rewind, or selectively edit agent behaviors, developers resort to full system restarts, losing valuable execution context and making reproduction of intermittent failures nearly impossible.
Cascading Failure Propagation
In multi-agent workflows, one small mistake rarely stays contained. Research on cascading failures demonstrates that a single misinterpreted message or misrouted output early in the workflow can cascade through subsequent steps, leading to major downstream failures. Agents maintain dynamic dependencies on other agents' specific knowledge or decision-making patterns, making cascade effects propagate unpredictably through the system.
Consider a customer service scenario where a routing agent misclassifies a technical support request as a billing inquiry. The billing agent attempts to process the request using billing tools and context, fails to find relevant information, and passes incomplete results to a resolution agent. The resolution agent, working with faulty context, generates an inappropriate response. By the time the error surfaces to the user, the root cause is buried under multiple layers of cascading failures.
State Synchronization Failures
State synchronization failures occur when agents develop inconsistent views of shared system state. Unlike single agents maintaining a unified context, distributed agents must actively synchronize state across boundaries, creating multiple failure points. Production analysis shows that stale state propagation is one of the most difficult failure modes to debug because symptoms manifest far from the root cause.
An e-commerce system provides a clear example. Agent A processes payment confirmation and updates order status to "paid." Agent B begins fulfillment execution before receiving the update, operating on outdated information showing "pending." The resulting duplicate payment attempts or contradictory order states create difficult-to-diagnose bugs where the timeline of events becomes critical to understanding the failure.
Lack of Standardized Observability
Traditional monitoring tools are optimized for single-agent reasoning path visibility and lack the semantic depth to capture collaborative workflows across multiple agents. Microsoft's research on OpenTelemetry enhancements highlights that in multi-agent systems, tasks are often decomposed and distributed dynamically, requiring visibility into agent roles, task hierarchies, tool usage, and decision-making processes. Without standardized task spans and unified namespaces, tracing cross-agent coordination becomes nearly impossible.
Multi-Agent System Architecture and Critical Debugging Points
Understanding where failures commonly occur requires mapping the multi-agent architecture and identifying critical debugging points where observability and monitoring must be concentrated.
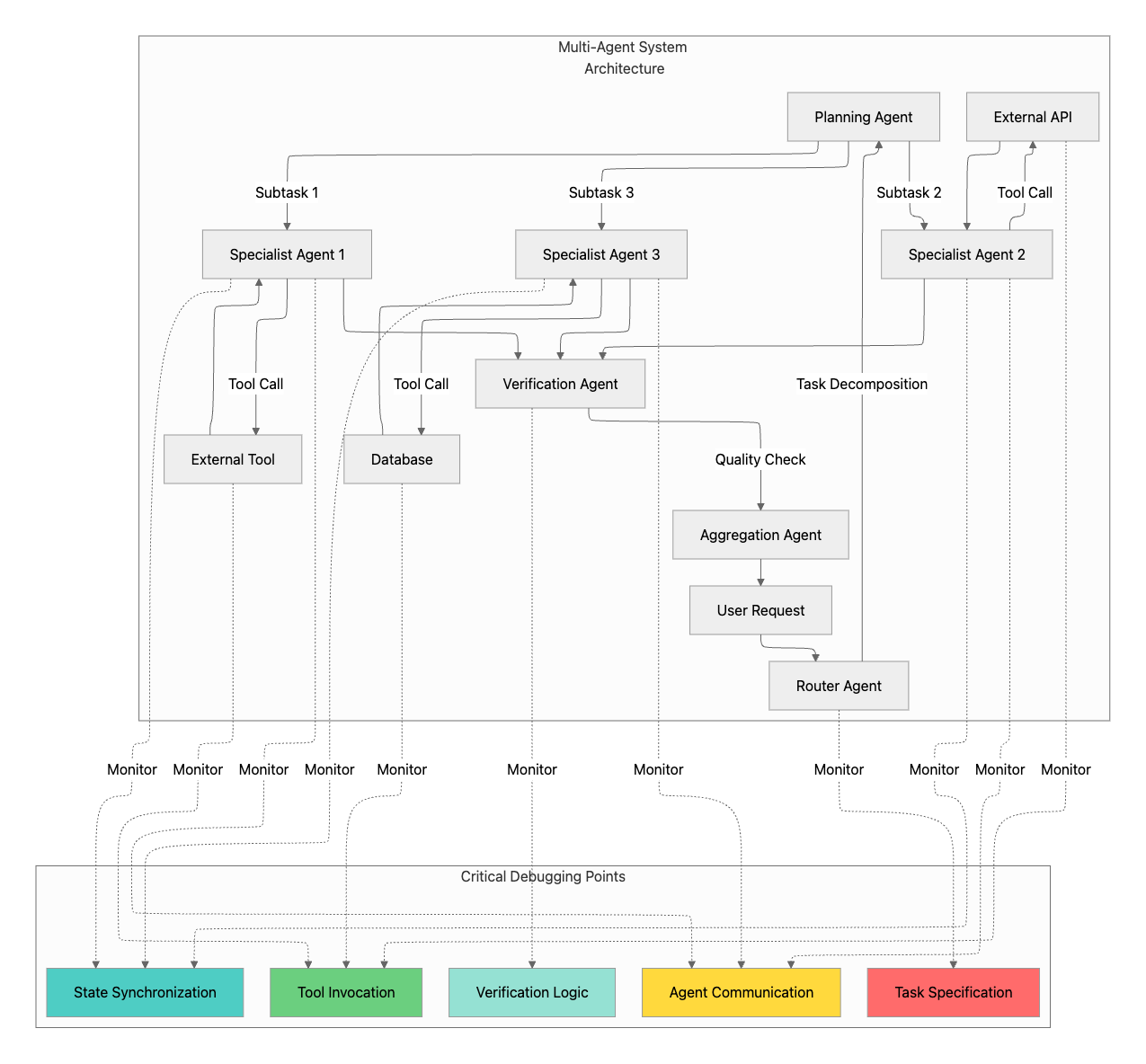
Task Specification Monitoring
The router and planning agents represent the first critical debugging point. These agents decompose user requests into subtasks and allocate them across specialist agents. Monitoring at this layer prevents the most common failure mode in the MAST taxonomy: disobeying task specifications, which accounts for 15.2% of all failures.
Effective debugging requires ensuring that tasks have clear success criteria, appropriate scope, and unambiguous requirements. Specification ambiguities at this stage propagate through the entire system, causing downstream agents to work toward misaligned objectives or violate implicit constraints that were never explicitly communicated.
Inter-Agent Communication Tracking
All message exchanges between agents must be instrumented to detect information withholding, format mismatches, and ignored inputs. Communication failures account for 31% of multi-agent system failures according to MAST research. Maxim's distributed tracing capabilities provide visibility into every agent interaction, enabling teams to identify exactly where communication breakdowns occur in complex workflows.
The challenge extends beyond simply logging messages. Debugging requires understanding the semantic meaning of communications, detecting when agents fail to acknowledge messages, and identifying subtle format incompatibilities that cause parsing errors downstream. Traditional log analysis is insufficient because it treats all messages equally, missing the contextual relationships that determine whether communications are functioning correctly.
Tool Invocation Validation
Tool calling represents a critical failure point where agents interact with external systems. Incorrect parameter passing, mishandled errors, and inappropriate tool selection create failures that are often misattributed to the tools themselves rather than the agent's tool-calling logic. Maxim's evaluation framework enables span-level assessment of tool calls, validating tool selection accuracy, parameter correctness, and response handling.
Production systems must track tool invocation patterns to detect anomalies such as repeated failed calls, inappropriate tool chains, or circular dependencies where agents invoke tools that trigger other agents in infinite loops. These patterns emerge only through systematic monitoring and analysis of tool usage across the entire agent system.
State Synchronization Verification
State consistency across agents requires continuous monitoring with timestamps and version tracking. Implementing eventual consistency checks detects stale state propagation before it causes downstream failures. The challenge is particularly acute in systems where agents cache information locally for performance, as cached data can become stale while the agent continues operating on outdated assumptions.
Debugging state synchronization issues requires the ability to reconstruct the complete state timeline across all agents at any point in execution. This demands more than simple logging; it requires structured state capture, version tracking, and the ability to correlate state changes across distributed agents to identify divergence points.
Verification Completeness
The verification agent represents the final defensive layer, but incorrect verification accounts for 13.6% of failures in the MAST taxonomy. Verification must extend beyond surface-level checks to validate functional correctness, constraint satisfaction, and alignment with user intent. Incomplete verification, where checks cover only partial aspects of output, misses critical errors that subsequently impact users.
Effective verification debugging requires understanding what the verification agent is actually checking versus what it should check. This often reveals gaps between specification and implementation, where developers assumed certain checks were implicit but the verification agent lacks the context to perform them.
Systematic Debugging Workflow for Multi-Agent Systems
Effective multi-agent debugging requires a systematic approach that addresses the unique characteristics of distributed agent systems. The following workflow provides a structured methodology for identifying and resolving failures in production environments.
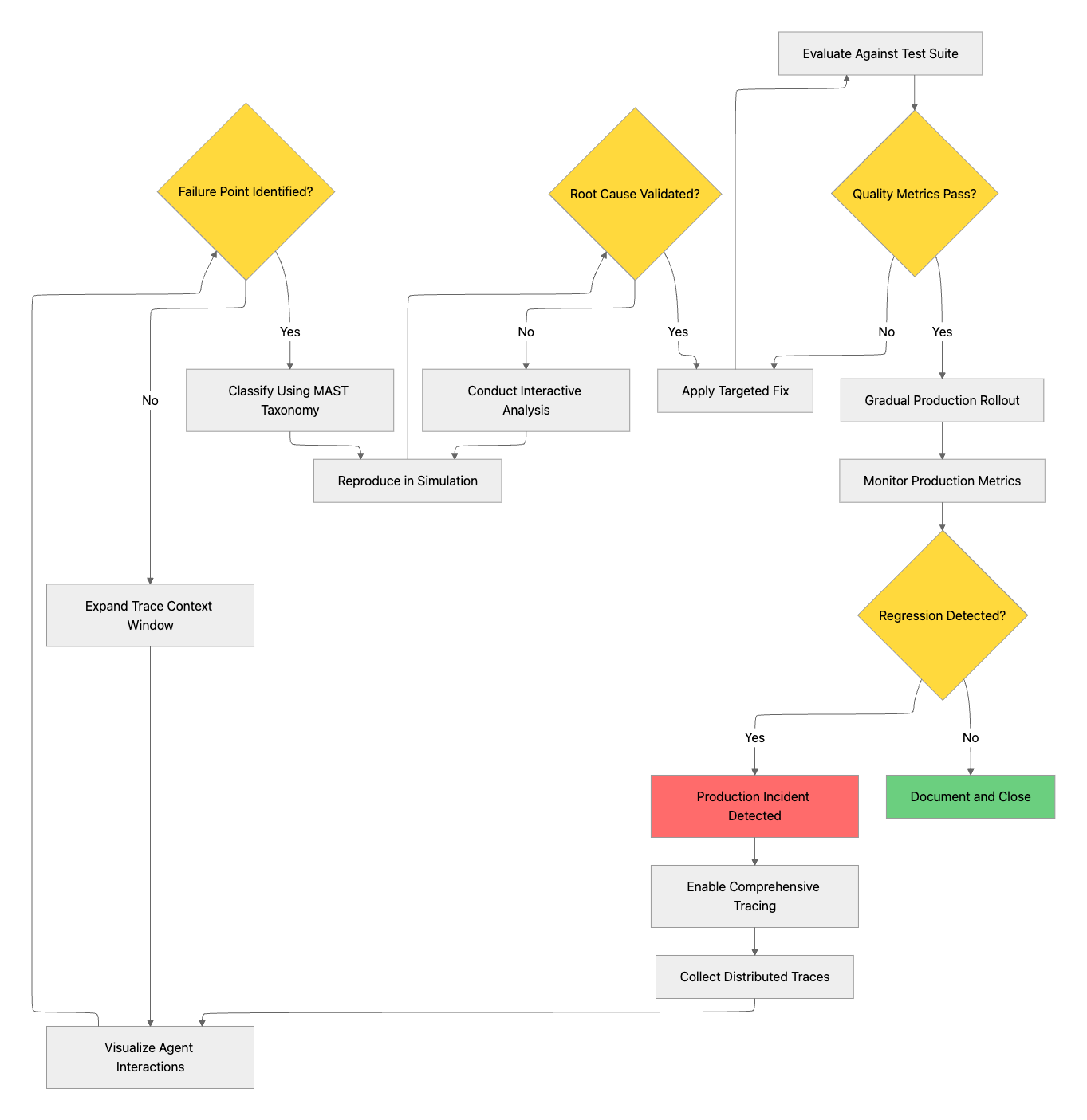
Enable Comprehensive Observability
The foundation of effective debugging is comprehensive observability through distributed tracing. Maxim's observability platform provides OpenTelemetry-compatible instrumentation that captures the complete execution context across all agents, including message flows, state transitions, tool invocations, and decision points. The platform supports distributed tracing across multiple repositories, enabling teams to monitor complex multi-agent applications with centralized visibility.
Unlike traditional logging that captures isolated events, distributed tracing reconstructs the complete request path across all participating agents. Each trace contains structured spans representing individual operations, with parent-child relationships that preserve the execution hierarchy. This hierarchical structure enables developers to navigate from high-level task execution down to specific agent decisions or tool calls, dramatically reducing time to identify failure points.
Maxim's implementation ensures that tracing overhead remains minimal, typically adding less than 5% latency to agent operations. The platform's intelligent sampling allows teams to capture complete traces for failed requests while sampling successful requests to manage data volumes without losing critical debugging context.
Analyze Execution Patterns
Once traces are collected, analyzing execution patterns reveals anomalies that indicate specific failure modes. Maxim's automated quality evaluations based on custom rules enable continuous monitoring of agent behavior, flagging deviations from expected patterns before they cascade into user-visible failures.
Analysis techniques include message flow analysis to identify communication breakdowns, state transition tracking to detect synchronization failures, and resource utilization pattern analysis to identify retry storms where cascading failures trigger exponential retry attempts. The platform's visualization capabilities present complex agent interactions in intuitive formats, enabling developers to quickly grasp system behavior and identify problem areas.
Critical to effective analysis is the ability to correlate events across agents and time. When Agent A sends a message to Agent B, but Agent B's response comes after an unexpected delay, was the delay due to Agent B's processing time, message queue latency, or a third agent's interference? Maxim's correlated tracing provides the temporal and causal context needed to answer such questions definitively.
Classify Failures Systematically
Using the MAST taxonomy, failures can be classified into specific categories that guide remediation strategies. Specification failures require prompt engineering and role definition improvements, while inter-agent misalignment failures demand communication protocol enhancements. Task verification failures point to gaps in quality control mechanisms.
Research demonstrates that LLM-as-a-Judge pipelines can automate failure classification, achieving 94% accuracy against human expert annotations with Cohen's kappa of 0.77. This enables scalable analysis of production traces without requiring manual review of every failure. Maxim's evaluation framework supports both automated and human-driven classification, enabling teams to balance efficiency with accuracy based on failure severity and frequency.
The classification step transforms unstructured failure data into actionable intelligence. Rather than viewing each failure as a unique incident, classification reveals patterns showing that multiple seemingly unrelated failures stem from the same root cause, such as ambiguous role specifications or insufficient verification logic.
Reproduce Through Simulation
Reproduction in controlled environments is critical for validating fixes without risking production systems. Maxim's Agent Simulation enables testing agents across hundreds of scenarios to reproduce failure conditions systematically. Teams can simulate customer interactions across real-world scenarios and user personas, monitoring how agents respond at every step.
The simulation platform supports failure injection, allowing developers to intentionally trigger specific conditions such as delayed state propagation, tool failures, or message loss. This controlled experimentation enables systematic validation of fixes and verification that solutions address root causes rather than symptoms.
Simulation also enables regression testing across the entire agent system. When fixing one failure mode, teams must verify that the fix does not introduce new failures in different scenarios. Maxim's simulation framework runs comprehensive test suites evaluating agent behavior across diverse conditions, catching regressions before they reach production.
Apply Targeted Remediation
Based on failure classification and root cause analysis, teams can apply targeted fixes. Specification failures often require prompt refinement, clearer role definitions, or enhanced task decomposition logic. Inter-agent misalignment failures may require communication protocol changes, explicit data schemas, or coordination mechanisms.
Research on intervention strategies distinguishes between tactical tweaks like prompt refinement and structural changes that address fundamental system design issues. While tactical fixes provide modest gains of around 9-15% accuracy improvements, truly reliable multi-agent systems often require structural redesigns including robust verification mechanisms, standardized communication protocols, and explicit coordination logic.
The remediation phase benefits from Maxim's experimentation capabilities. Playground++ enables rapid iteration on prompts, deployment with different variables, and comparison of output quality across various configurations. Teams can test fixes in isolated environments before rolling them out to production.
Validate Through Comprehensive Evaluation
Before deploying fixes, comprehensive evaluation ensures that changes improve system behavior without introducing regressions. Maxim's unified evaluation framework combines machine and human evaluations to quantify improvements across multiple dimensions including task completion rate, response quality, tool selection accuracy, and constraint adherence.
The platform provides off-the-shelf evaluators through an evaluator store, covering common quality metrics like relevance, coherence, and factual accuracy. For domain-specific requirements, teams can create custom evaluators using deterministic rules, statistical methods, or LLM-as-a-judge approaches. Evaluation can be configured at any granularity, from individual tool calls to complete conversational trajectories.
Human evaluation remains critical for nuanced assessments that automated metrics cannot capture. Maxim's human evaluation workflows enable teams to define evaluation criteria, collect feedback from domain experts, and continuously align agents to human preferences through iterative refinement cycles.
Advanced Debugging Strategies
Beyond the systematic workflow, several advanced strategies address specific failure patterns and enhance overall debugging effectiveness.
Circuit Breaker Implementation
Circuit breakers prevent cascading failures by isolating problematic agents before errors propagate system-wide. Analysis of production failures shows that implementing circuit breaker patterns adapted for multi-agent systems can reduce cascade failure impact by 70% by containing problems within limited system boundaries.
The circuit breaker pattern tracks failure rates for each agent and opens the circuit when failures exceed configured thresholds, routing requests to backup agents or escalating to human review. After a timeout period, the circuit enters a half-open state allowing limited traffic to test if the agent has recovered. This prevents retry storms where failing agents receive repeated requests that exacerbate system instability.
Maxim's observability platform enables configuration of circuit breakers based on real-time monitoring metrics. Teams can define failure thresholds, timeout periods, and escalation paths tailored to each agent's role and criticality. The platform tracks circuit breaker state changes as part of distributed traces, providing visibility into how circuit breakers prevent cascade failures.
Replay Debugging Capabilities
Replay debugging allows developers to reproduce failures by capturing and replaying agent execution sequences. This technique is particularly valuable for investigating race conditions, state synchronization issues, and intermittent failures that are difficult to reproduce through traditional debugging approaches.
Maxim's data curation capabilities support replay debugging by preserving complete execution context including agent states, message sequences, and external tool responses. Developers can rerun simulations from any step to reproduce issues, identify root causes, and validate fixes against the exact conditions that triggered the original failure.
Anomaly Detection for Agent Behavior
Statistical monitoring detects abnormal agent behavior patterns that may indicate emerging failures before they impact users. By establishing baseline behavior profiles for each agent, anomaly detection identifies deviations such as unusual tool calling frequencies, abnormal response times, or unexpected message patterns.
Maxim's custom dashboards enable teams to create insights across custom dimensions, monitoring agent behavior trends over time. Automated alerts notify teams when anomalies cross configured thresholds, enabling proactive intervention before patterns escalate into user-visible failures.
Human-in-the-Loop Debugging
Despite advances in automated debugging tools, human expertise remains critical for diagnosing complex failure modes. Research on interactive debugging shows that developers frequently need to specify more detailed instructions, simplify agent tasks, or alter agent plans based on observed failures.
Maxim's human evaluation framework enables expert review of agent behaviors, providing structured workflows for collecting feedback, identifying patterns in human assessments, and incorporating human insights into agent improvements. This human-in-the-loop approach ensures that debugging addresses not just technical correctness but also alignment with user expectations and business requirements.
Cost Management During Debugging
Debugging multi-agent systems can become expensive quickly, particularly when reproducing failures requires executing multiple agents across numerous scenarios. Cost management strategies ensure debugging remains economically viable while maintaining comprehensive coverage.
Bifrost, Maxim's AI gateway, provides several cost optimization features that benefit debugging workflows. Semantic caching intelligently caches responses based on semantic similarity, dramatically reducing costs when debugging involves repeated execution of similar scenarios. During debugging sessions, many agent interactions follow similar patterns, and semantic caching can reduce API costs by 50-80%.
Automatic fallbacks and load balancing ensure that debugging workflows continue even when specific providers experience issues, preventing wasted time and resources. The gateway's unified interface enables seamless switching between models and providers, allowing teams to use cost-effective models for initial debugging phases and upgrade to more capable models only when necessary.
Budget management through hierarchical cost control prevents debugging activities from exceeding allocated budgets. Teams can set limits at project, team, or individual levels, ensuring that debugging costs remain controlled even during intensive troubleshooting sessions.
Production Monitoring and Continuous Improvement
Effective debugging extends beyond resolving individual incidents to establishing continuous monitoring and improvement processes that prevent recurrence and identify emerging issues proactively.
Real-Time Alerting
Maxim's observability platform provides real-time alerts for production issues, enabling teams to act on problems with minimal user impact. Alerts can be configured based on error rates, quality metric degradation, latency increases, or custom rules specific to business requirements.
The platform's intelligent alerting reduces noise by correlating related failures and surfacing root causes rather than overwhelming teams with individual error notifications. When multiple agents experience correlated failures, Maxim identifies the common cause and generates a single high-priority alert rather than separate alerts for each affected agent.
Automated Quality Evaluations
In-production quality measurement through automated evaluations based on custom rules ensures that agent behavior remains consistent with requirements. Maxim's evaluation capabilities continuously assess production outputs against defined quality criteria, flagging degradations before they accumulate into major issues.
Automated evaluations run on sampled production traffic, balancing comprehensive coverage with computational efficiency. Teams can configure evaluation frequency, sampling rates, and alert thresholds based on application criticality and available resources.
Dataset Curation for Continuous Learning
Maxim's Data Engine enables seamless data management, allowing teams to continuously curate datasets from production logs for evaluation and improvement. Production data represents real-world usage patterns and edge cases that synthetic data often misses, making it invaluable for improving agent robustness.
Teams can import datasets with a few clicks, continuously evolve them from production data, and enrich data through in-house or Maxim-managed labeling. This creates a virtuous cycle where production monitoring identifies failure patterns, curated datasets capture those patterns, evaluations validate improvements, and refined agents deploy back to production with enhanced reliability.
Building a Debugging Culture
Technical tools and processes form only part of effective debugging. Organizations must cultivate a debugging culture that emphasizes systematic approaches, knowledge sharing, and continuous improvement.
Documentation and Knowledge Sharing
Documenting debugging sessions, failure patterns, and resolution strategies builds institutional knowledge that accelerates future debugging efforts. When teams encounter similar failures, documented approaches provide starting points rather than requiring complete rediscovery of solutions.
Maxim's platform supports this knowledge building through structured failure classification, reusable evaluation suites, and sharable simulation scenarios. Teams can create libraries of test cases covering known failure modes, ensuring that fixes address root causes comprehensively.
Cross-Functional Collaboration
Multi-agent debugging often requires collaboration between AI engineers, product managers, and domain experts. Maxim's user experience enables cross-functional teams to collaborate seamlessly, with interfaces tailored to different personas. Engineers work with detailed traces and evaluation metrics, while product managers focus on user impact and quality trends.
This collaborative approach ensures that debugging addresses both technical correctness and business alignment. Product managers contribute insights on user expectations and business requirements that inform evaluation criteria and priority of fixes.
Proactive Failure Prevention
The ultimate goal of debugging is preventing failures rather than merely reacting to them. Organizations should invest in proactive strategies including comprehensive simulation before deployment, gradual rollouts with monitoring, and continuous evaluation of production behavior.
Maxim's end-to-end platform supports this proactive approach by integrating experimentation, simulation, evaluation, and observability in a unified workflow. Teams can test changes thoroughly in simulation, evaluate against comprehensive test suites, deploy gradually with monitoring, and quickly detect regressions through continuous evaluation.
Conclusion
Debugging multi-agent systems presents unique challenges that traditional debugging approaches cannot adequately address. The distributed nature of multi-agent architectures, cascading failure propagation, state synchronization complexity, and lack of standardized tooling demand systematic approaches grounded in understanding common failure patterns and equipped with specialized observability and evaluation capabilities.
Research demonstrates that the core problem is architectural, not model-level, with failures distributed across specification, inter-agent alignment, and verification phases. Successful debugging requires comprehensive distributed tracing, systematic failure classification using frameworks like MAST, reproduction through simulation, and validation through multi-dimensional evaluation.
Maxim AI provides the complete infrastructure teams need to debug multi-agent systems effectively, from distributed tracing and automated evaluations to simulation capabilities and human-in-the-loop workflows. Organizations using Maxim's platform report 70% reduction in mean time to resolution, enabling faster iteration and more reliable production deployments.
Ready to transform how your team debugs multi-agent systems? Schedule a demo to see how Maxim AI accelerates debugging and improves agent reliability, or sign up today to start building more reliable multi-agent applications.