The AI Safety Stack: Guardrails, Evaluation, and Observability Defined

The AI safety stack has three layers: guardrails, evaluation, and observability. Learn how Bifrost enforces production-grade AI safety at the gateway.
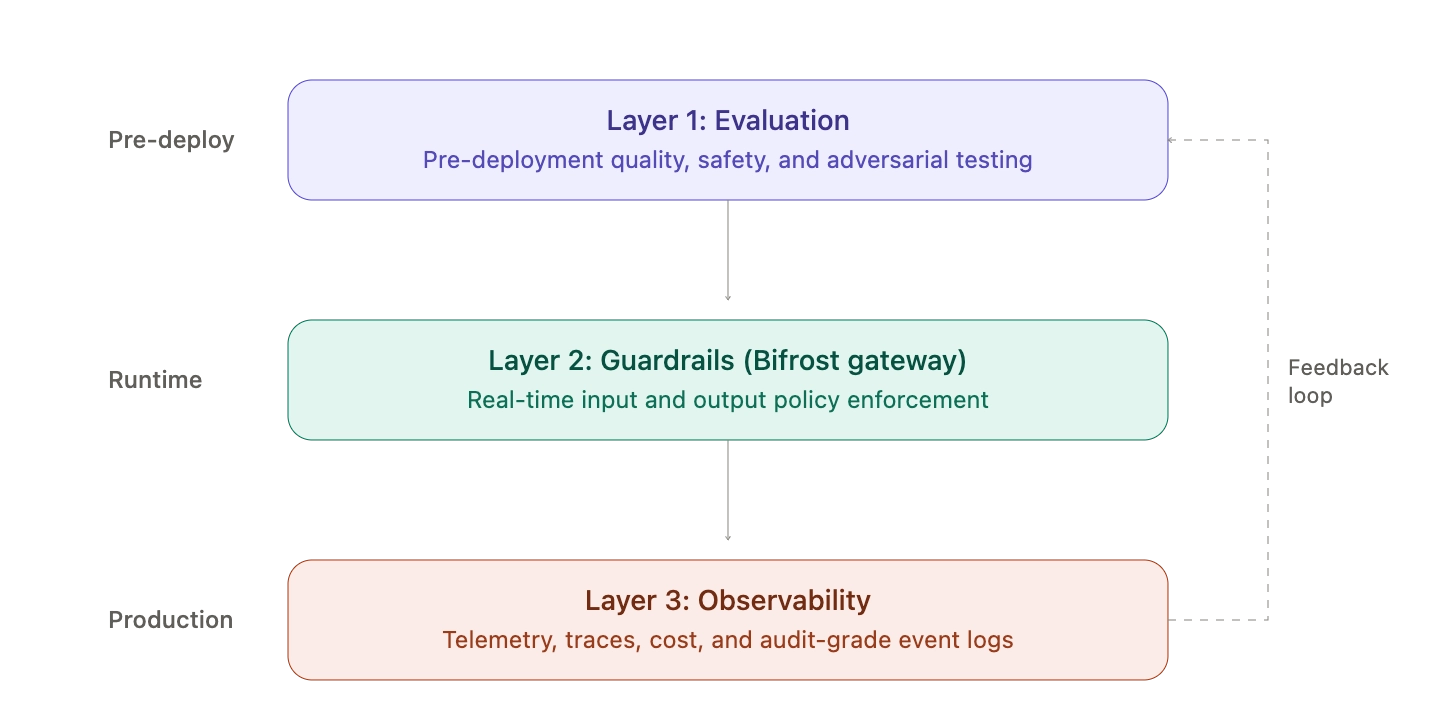
The AI safety stack is the set of controls, tests, and monitoring layers that together prevent an LLM application from producing unsafe outputs, leaking data, or behaving unpredictably in production. It is not a single tool. It is a layered architecture: guardrails block bad inputs and outputs at runtime, evaluation measures quality before and after deployment, and observability tells you what is actually happening in production. Bifrost, the open-source AI gateway by Maxim AI, sits at the runtime layer of this stack, enforcing guardrails inline at 11 microseconds of overhead per request and feeding observability data into the layers above.
This post defines each layer, explains where the boundaries sit, and shows how Bifrost handles the runtime enforcement piece for teams running LLMs in production.
What Is the AI Safety Stack
The AI safety stack is a defense-in-depth architecture for LLM applications, organized around three complementary layers:
- Guardrails: real-time enforcement of input and output policies (PII redaction, prompt injection blocking, content moderation, jailbreak detection)
- Evaluation: pre-deployment and continuous testing of model and agent quality against defined criteria
- Observability: production-time visibility into requests, responses, latencies, costs, and policy enforcement events
These layers map cleanly to the four functions of the NIST AI Risk Management Framework (Govern, Map, Measure, Manage). Guardrails operationalize the Manage function. Evaluation covers Measure. Observability provides the data substrate for both Govern and Map. Skipping any layer leaves a measurable gap that audits, security teams, and customers will eventually find.
Why a Layered AI Safety Stack Matters
LLM applications fail in ways that traditional software does not. The OWASP Top 10 for LLM Applications places prompt injection at number one for the second consecutive edition, with sensitive information disclosure, supply chain risk, and improper output handling close behind. The NIST Generative AI Profile catalogs twelve distinct GAI risk categories, including confabulation, data privacy, information integrity, and harmful bias.
No single control covers all of these. A guardrail can block a leaked SSN at the output stage but cannot tell you whether the underlying agent is hallucinating policy citations. An evaluation suite can score an agent on accuracy in a test environment but cannot stop a live prompt-injection attack at 3am. An observability dashboard can surface a latency spike but cannot decide what to do about it.
The AI safety stack works because each layer compensates for the others' blind spots:
- Guardrails stop known-bad behavior at runtime before it reaches users or upstream systems
- Evaluation catches quality regressions and unsafe behaviors before they ship
- Observability tells you when controls are firing, when they are not, and when something new is happening
Layer 1: AI Guardrails
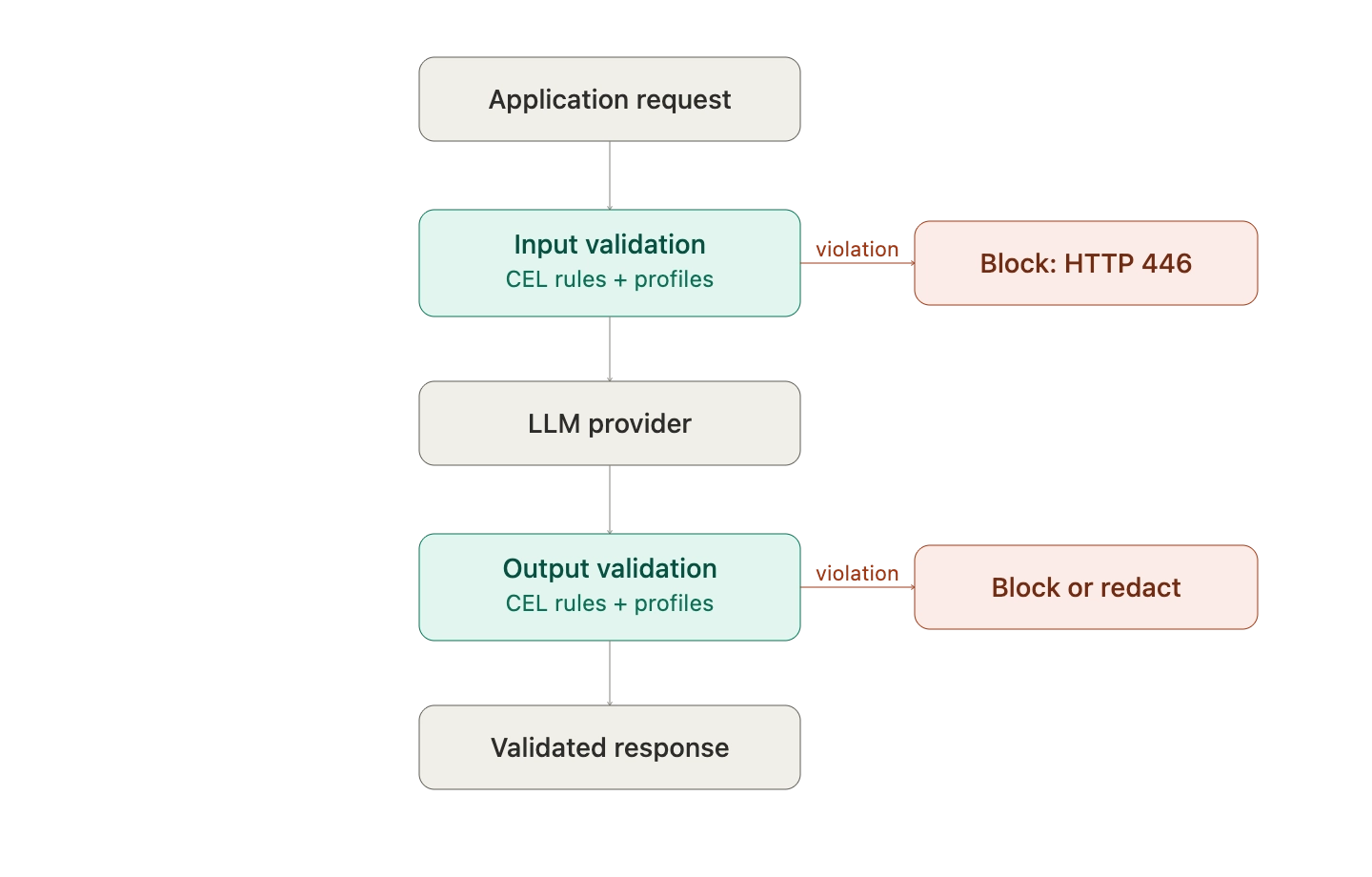
AI guardrails are the runtime enforcement layer. They sit inline with every request and response, applying policy decisions in milliseconds based on content classification, rule matching, or model-based detection.
What Guardrails Do
A production guardrail layer typically handles:
- PII detection and redaction: blocking or masking SSNs, credit card numbers, phone numbers, addresses, and custom regex patterns in both inputs and outputs
- Prompt injection defense: detecting jailbreak attempts, indirect prompt injection through retrieved documents, and known attack patterns
- Content moderation: filtering hate speech, violence, sexual content, and self-harm material across configurable severity thresholds
- Topic restrictions: blocking model responses on prohibited subjects defined in natural language
- Output groundedness checks: verifying that responses are supported by retrieved context in RAG architectures
- Custom policy rules: enforcing organization-specific constraints (no competitor mentions, no medical advice, no financial recommendations)
How Bifrost Enforces Guardrails
Bifrost's guardrails system is gateway-native: every request and response that flows through Bifrost can be validated against one or more configured guardrail providers. There is no application-side SDK to integrate, no per-team policy drift, and no missed enforcement when a new service is deployed. The control is at the gateway, so every model call inherits it.
Bifrost integrates with the major guardrail providers:
- AWS Bedrock Guardrails: content filters, denied topics, PII redaction, and contextual grounding checks via Bedrock Guardrail ARNs
- Azure AI Content Safety: severity-based moderation, Prompt Shield for jailbreak detection, indirect attack shield, and groundedness checks
- Patronus AI: hallucination detection, toxicity screening, and prompt injection defense with customizable policies
- GraySwan: custom safety rules expressed in natural language with configurable violation thresholds and reasoning modes
Multiple providers can be layered for defense in depth. Validation runs at two stages: input rules apply before the request reaches the model, and output rules apply before the response returns to the caller. Each can be configured synchronously (block on violation) or asynchronously (log and continue), depending on latency and policy requirements.
A typical config attaches guardrails per request via header:
curl -X POST <http://localhost:8080/v1/chat/completions> \\
-H "Content-Type: application/json" \\
-H "x-bf-guardrail-ids: bedrock-prod-guardrail,azure-content-safety-001" \\
-d '{
"model": "gpt-4o-mini",
"messages": [{"role": "user", "content": "Help me with this task"}]
}'
When a guardrail fires, Bifrost returns a structured violation response with the offending category, severity, action taken, and processing time, so applications and audit pipelines can react cleanly.
For teams evaluating gateway-level safety, the Bifrost guardrails resource page covers the full enforcement model, including how it composes with virtual keys and governance for per-team policy assignment.
Layer 2: AI Evaluation
Evaluation is the pre-deployment and continuous testing layer. Where guardrails enforce at runtime, evaluation measures quality, safety, and reliability against defined criteria, ideally before a model or agent ever sees production traffic.
What Evaluation Covers
A complete evaluation layer includes:
- Model-level evals: accuracy, factuality, refusal behavior, and bias across benchmark datasets
- Agent-level evals: end-to-end task completion, tool selection correctness, multi-turn coherence, and policy adherence
- RAG evals: retrieval quality, context relevance, answer groundedness, and citation accuracy
- Adversarial evals: red-team prompts, jailbreak suites, and known prompt-injection corpora to probe safety regressions
- Regression evals: automated runs against a frozen test set whenever prompts, models, or upstream tools change
- Human-in-the-loop reviews: structured annotation workflows for cases where automated scoring is insufficient
Evaluation is the layer that catches issues before they ship. The NIST GAI Profile explicitly identifies pre-deployment testing as one of four primary considerations for managing generative AI risk. OWASP's mitigation guidance for prompt injection includes "conduct adversarial testing and attack simulations" as a core control, which is a pure evaluation activity.
The evaluation layer typically lives in a dedicated platform that supports agent simulation and evaluation at session, trace, and span level, multi-scenario testing across user personas, and continuous evaluation against production traffic. From the perspective of the safety stack, evaluation is upstream of the gateway: it decides what is safe to deploy. Bifrost is downstream: it enforces decisions on what is safe to serve.
Layer 3: AI Observability
AI observability is the production visibility layer. It captures every request, response, tool call, latency measurement, token count, cost, and guardrail event, then makes that data queryable for debugging, auditing, and continuous improvement.
What Observability Captures
A production-grade observability layer surfaces:
- Request and response payloads (with PII redacted before storage)
- Latency and token-usage breakdowns per provider, model, and route
- Cost attribution per virtual key, team, customer, or workflow
- Guardrail invocation metrics: which rules fired, how often, on which models
- Tool-call traces for agentic workflows, including arguments and results
- Distributed traces that correlate gateway events with upstream and downstream services
- Audit logs of policy changes, key rotations, and access events
How Bifrost Powers the Observability Layer
Bifrost emits the data the observability layer needs. Built-in observability covers real-time request monitoring with a native dashboard, while native telemetry supports Prometheus metrics (both scrape and Push Gateway modes) and OpenTelemetry distributed tracing. The OTLP output is compatible with Grafana, New Relic, Honeycomb, and Datadog, so existing observability investments continue to work.
For compliance contexts, Bifrost's audit logs provide immutable trails suitable for SOC 2, GDPR, HIPAA, and ISO 27001 reviews, capturing every guardrail invocation, policy change, and credential rotation alongside the underlying request data.
The observability layer is also where evaluation and guardrails close the loop. Production traces feed back into the evaluation suite to flag drift. Guardrail events become part of the audit story. Cost and latency data inform routing decisions. Without this layer, the other two operate blind.
How the Three Layers Compose in Production
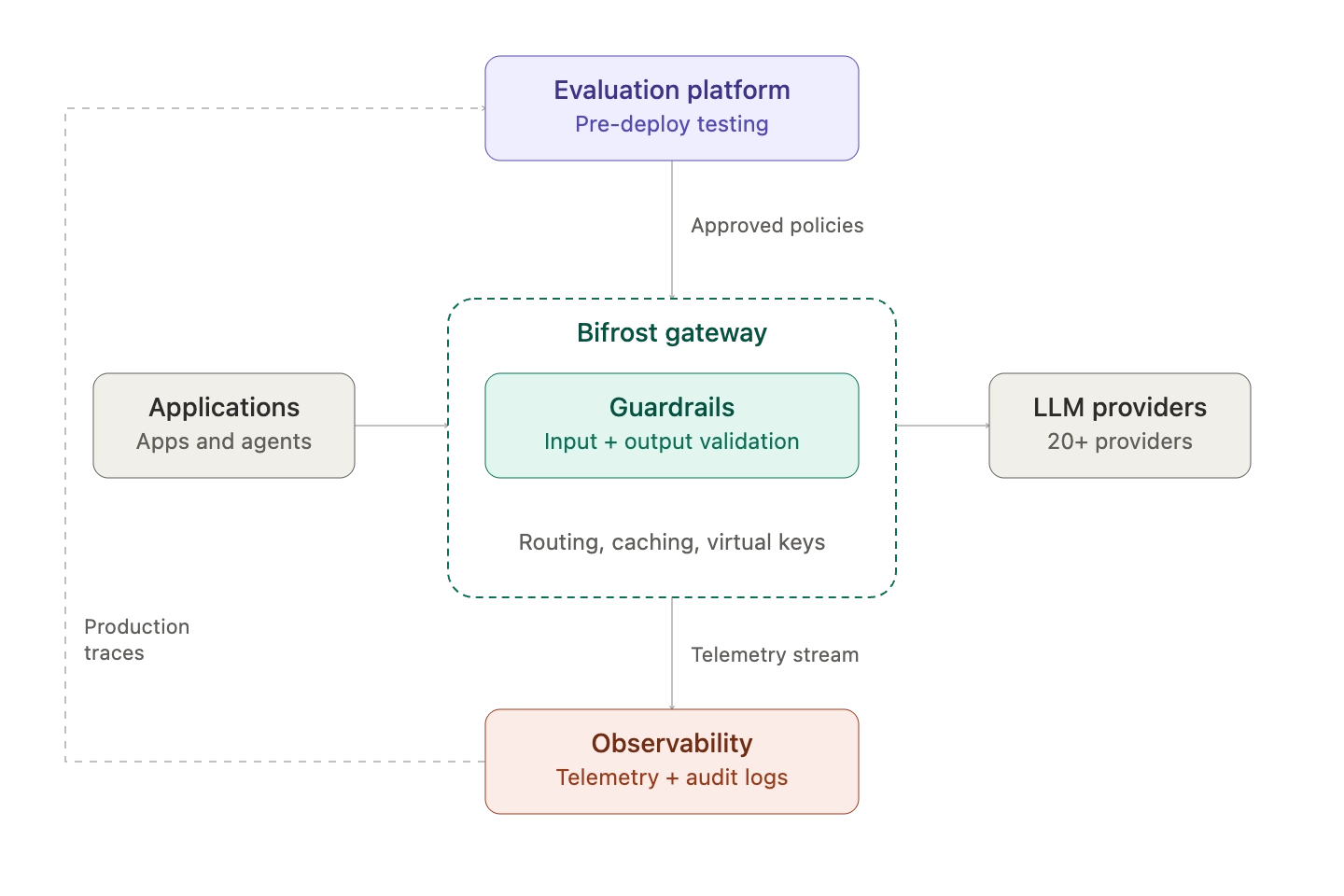
The AI safety stack delivers value only when the layers are wired together. A practical deployment looks like this:
- The evaluation suite gates every model, prompt, and agent change before it reaches production
- Bifrost sits in front of every LLM provider as the runtime enforcement point, applying guardrails and emitting telemetry
- Observability captures every request and response, with audit-grade retention for policy events
- Production traces flow back into the evaluation suite as new test cases, closing the loop
This composition gives a single answer to the questions auditors and security teams actually ask:
- "What policies were in effect at this timestamp?" (audit logs)
- "Was this request blocked, and why?" (guardrail invocation metrics)
- "How does this model perform on our adversarial suite?" (evaluation results)
- "Has performance drifted in the last 30 days?" (observability time series)
Without the gateway layer specifically, every application has to implement guardrails locally, every team interprets policy slightly differently, and the audit story fragments across services. The gateway is what turns three independent tools into a coherent stack.
Best Practices for Building an AI Safety Stack
Across deployments, a few practices show up consistently:
- Centralize enforcement at the gateway: per-application guardrails create policy drift. One enforcement point creates one audit story.
- Layer multiple guardrail providers: defense in depth applies here. Bedrock Guardrails plus Azure Content Safety catches more than either alone.
- Run guardrails on both input and output: input rules block prompt injection and PII entering the model; output rules block hallucinations, leaks, and toxic generations.
- Wire observability into evaluation: production traces are the best source of new evaluation cases.
- Use virtual keys for per-team policy: shared service accounts collapse the audit trail. Per-team identity preserves it.
- Make audit logs immutable: compliance reviews need evidence, not summaries.
- Test guardrails like code: include adversarial test cases in CI to prevent regressions when policies change.
Build Your AI Safety Stack with Bifrost
A working AI safety stack does not require three vendors and a quarter of integration work. With Bifrost at the gateway layer, guardrails, observability hooks, and audit logs are inherited by every application that points at it. Evaluation tooling plugs in upstream. The result is a single pane of glass for AI safety, governance, and compliance, running at production scale with negligible latency overhead.
To see how Bifrost can anchor your AI safety stack, book a demo with the Bifrost team.


