Debugging RAG Pipelines: Identifying Issues in Retrieval-Augmented Generation

TL;DR
Retrieval-Augmented Generation (RAG) combines retrieval and generation to produce accurate, context-rich responses, but debugging these systems can be complex. Common issues include irrelevant retrievals, hallucinations, context overflow, and latency. Effective debugging requires evaluating retrieval quality (precision, recall, MRR, MAP) and generation accuracy (faithfulness, relevance, correctness) while tracing and inspecting both stages. Platforms like Maxim AI streamline this process with tools for simulation, evaluation, observability, and CI/CD integration, enabling teams to monitor, test, and improve RAG pipelines efficiently.
Table of Contents
- Understanding RAG Architecture
- Common Issues in RAG Systems
- Debugging the Retrieval Component
- Debugging the Generation Component
- Advanced Debugging: Rerankers and Context Windows
- Evaluation and Observability: The Maxim AI Approach
- Best Practices for Debugging RAG Pipelines
- Further Reading and Resources
- Conclusion
Understanding RAG Architecture
RAG systems are fundamentally composed of two tightly integrated components: retrieval and generation. The retrieval module fetches relevant documents from an external knowledge base, while the generation module synthesizes a response using the retrieved context and the user’s query. This dual-stage design enables RAG models to overcome limitations of static training data, offering up-to-date and authoritative information.
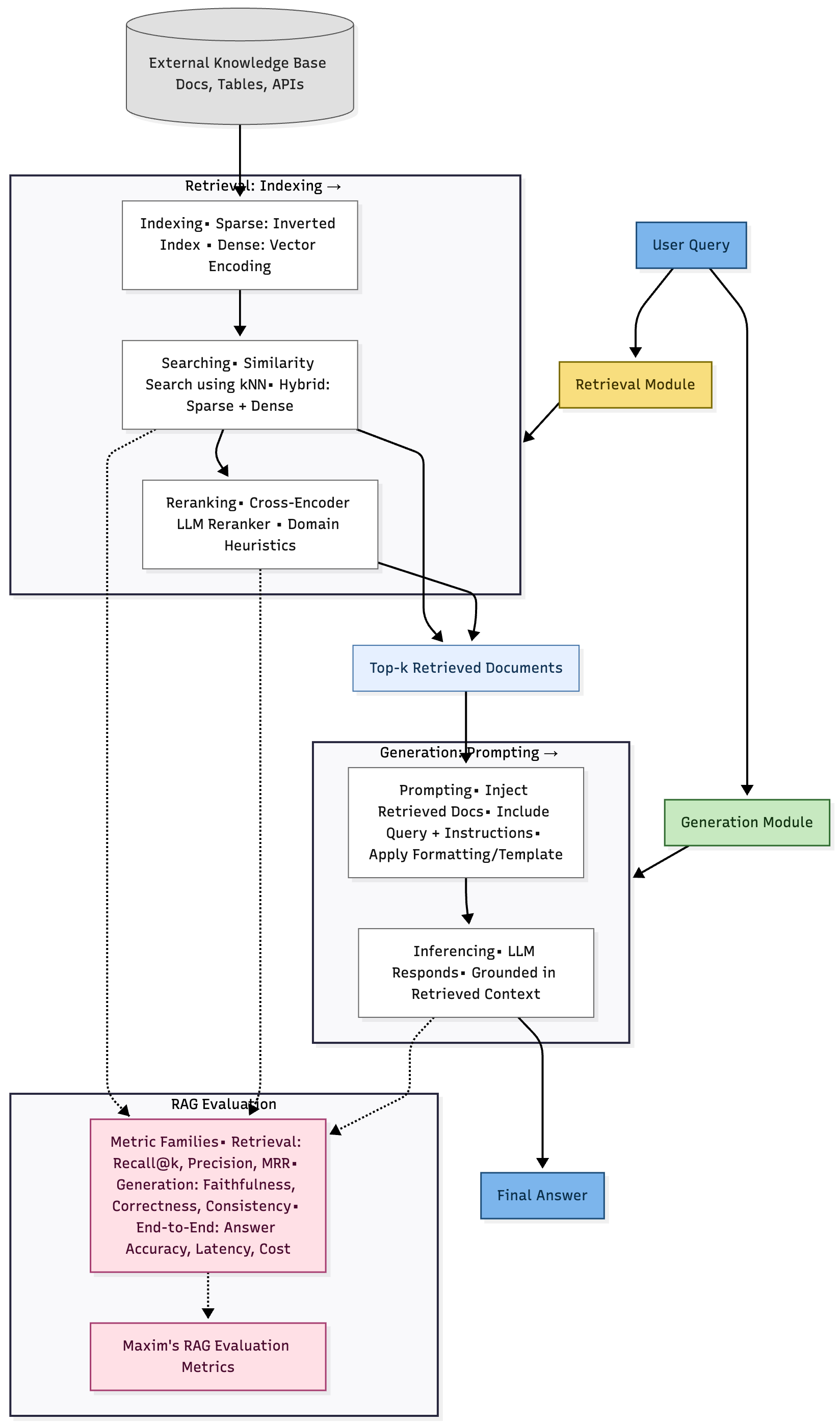
Key Phases in RAG Workflow:
- Indexing: Documents are structured for efficient retrieval, using either sparse (inverted index) or dense (vector encoding) representations.
- Searching: User queries are mapped to relevant documents via similarity search, often enhanced by rerankers for improved relevance.
- Prompting: Retrieved documents are incorporated into prompts for the language model.
- Inferencing: The language model generates responses that integrate retrieved information.
For a deeper dive into RAG evaluations, refer to Maxim’s RAG Evaluation Metrics .
Common Issues in RAG Systems
Despite its promise, RAG introduces new sources of complexity. Debugging these systems requires visibility into both retrieval and generation stages. Common issues include:
- Low relevance in retrieved documents: The retrieval engine may return documents that are tangential or irrelevant to the query.
- Hallucinations in generated responses: The language model may fabricate information not present in the retrieved context.
- Context window overflow: Passing too many documents to the LLM can dilute relevance and degrade generation quality.
- Information loss in embeddings: Vector representations may miss subtle semantic distinctions, leading to poor retrieval results.
- Latency and scalability bottlenecks: Large-scale retrieval and reranking can slow down response times.
Understanding these failure modes is the first step toward effective debugging.
Debugging the Retrieval Component
1. Evaluating Retrieval Quality
The retrieval component is responsible for surfacing the most relevant documents in response to a query. Debugging retrieval issues involves:
- Relevance Analysis: Are the top-k retrieved documents truly relevant to the user query?
- Accuracy and Ranking: Are relevant documents ranked above non-relevant ones?
- Coverage: Is the system missing key sources or failing to index important content?
Metrics for Retrieval Evaluation:
- Precision and Recall: Measure the fraction of relevant documents retrieved and the proportion of retrieved documents that are relevant.
- Mean Reciprocal Rank (MRR): Focuses on the position of the first relevant document.
- Mean Average Precision (MAP): Averages precision scores across all relevant documents.
For technical details on retrieval evaluation, see Maxim’s blog on RAG Evaluation Metrics.
2. Diagnosing Retrieval Failures
Typical Issues:
- Sparse Indexing Limitations: Inverted indexes may miss semantic matches.
- Dense Embedding Challenges: Vector search can compress meaning, missing negations or subtle distinctions (e.g., “I like going to the beach” vs. “I don’t like going to the beach”).
- Metadata Quality: Poor metadata can lead to irrelevant retrievals.
Debugging Strategies:
- Query Analysis: Log and inspect queries to ensure they’re properly formulated.
- Document Inspection: Review retrieved documents for relevance and completeness.
- Embedding Visualization: Use tools to visualize vector spaces and inspect clustering of similar documents.
Platforms like Maxim AI provide distributed tracing and logging for retrieval workflows, enabling granular inspection of each retrieval event. Learn more in Building a RAG Application with Maxim AI.
Debugging the Generation Component
1. Evaluating Generation Quality
The generation module synthesizes responses using retrieved context. Debugging generation focuses on:
- Faithfulness: Does the response accurately reflect the information in retrieved documents?
- Relevance: Is the response aligned with the user’s intent and the query?
- Correctness: Is the response factually accurate?
Metrics for Generation Evaluation:
- ROUGE: Measures n-gram overlap between generated and reference responses.
- BLEU: Evaluates precision in machine translation tasks.
- BertScore: Uses embeddings to assess semantic similarity.
- LLM-as-a-Judge: Employs large language models as automated evaluators for coherence and relevance.
For more on generation metrics, refer to Maxim’s AI Agent Evaluation Metrics.
2. Diagnosing Generation Failures
Common Issues:
- Hallucinations: The model generates information not found in the context.
- Off-topic Responses: The output drifts from the user’s query.
- Fluency vs. Factuality Trade-off: Highly fluent responses may lack factual accuracy.
Debugging Techniques:
- Trace Generation Steps: Use observability platforms to log each generation event.
- Compare with Ground Truths: Benchmark outputs against curated ground truth datasets.
- Human-in-the-Loop Evaluation: Incorporate manual review for nuanced assessment.
Maxim AI’s platform supports both automated and human evaluations, streamlining the debugging process. See Evaluation Workflows for AI Agents.
Advanced Debugging: Rerankers and Context Windows
1. Incorporating Rerankers
Rerankers refine the initial set of retrieved documents, prioritizing those most relevant to the query. This two-stage retrieval system improves both accuracy and relevance.
Key Reranking Models:
- Cross-Encoder: Processes query-document pairs together for nuanced relevance scoring.
- Multi-Vector Rerankers (e.g., ColBERT): Balance efficiency and interaction by precomputing document representations and computing token-level similarities.
For practical guidance on rerankers, see Optimize Retrieval-Augmented Generation with Rerankers.
2. Managing Context Windows
LLMs have a finite context window. Overloading the model with too many documents can lead to performance degradation, often referred to as the “needle in a haystack” problem.
Debugging Context Issues:
- Monitor Document Count: Track the number of documents passed to the LLM.
- Summarization: Inject concise summaries to maximize context utility.
- Contextual Filtering: Use rerankers to select only the most relevant documents.
Research from “In Search of Needles in a 11M Haystack” highlights how model performance can degrade as context size increases.
Evaluation and Observability: The Maxim AI Approach
Debugging RAG systems demands robust evaluation and observability. Maxim AI delivers a unified platform for experiment management, simulation, evaluation, and monitoring, empowering teams to iterate rapidly and ship reliable AI agents.
Key Features:
- Experimentation Playground: Test and iterate across prompts, models, and context sources with a no-code IDE. Learn more
- Agent Simulation and Evaluation: Simulate real-world scenarios, evaluate agent quality using prebuilt and custom metrics, and automate evaluation pipelines. Explore agent simulation
- Observability and Tracing: Monitor granular traces, debug live issues, and set real-time alerts for regressions. Discover agent observability
- Human-in-the-Loop Pipelines: Integrate scalable human review alongside automated evaluations for nuanced quality checks.
- Integration with CI/CD: Seamlessly incorporate evaluation into development workflows for continuous improvement.
Case studies from leading organizations (such as Clinc’s conversational banking and Atomicwork’s enterprise support) demonstrate the impact of Maxim AI’s platform in real-world AI applications.
Best Practices for Debugging RAG pipelines
- Instrument Retrieval and Generation: Use distributed tracing and detailed logging for every step in the RAG pipeline.
- Curate Robust Datasets: Benchmark against high-quality ground truths and update datasets dynamically as requirements evolve.
- Employ Multi-modal Evaluation: Combine automated metrics with human review for comprehensive assessment.
- Leverage Rerankers and Summarization: Prioritize relevance and manage context windows to optimize LLM performance.
- Monitor in Production: Implement real-time observability and alerts to catch issues early.
- Iterate Rapidly: Use experimentation platforms to test and refine workflows across models, prompts, and tools.
- Benchmark Continuously: Utilize industry-standard datasets and benchmarks (e.g., RAGTruth, FRAMES) to measure progress.
For a detailed guide on agent quality evaluation, see AI Agent Quality Evaluation.
Further Reading and Resources
- Maxim AI Docs
- Maxim Blog: RAG Evaluation Metrics
- Maxim Blog: AI Agent Evaluation Metrics
- Maxim Blog: Evaluation Workflows for AI Agents
- MongoDB Vector Search Documentation
- LangChain Documentation
- SBERT Cross-Encoder
- ColBERT: Contextualized Late Interaction over BERT
- Arxiv: In Search of Needles in a 11M Haystack
Conclusion
Debugging RAG systems is a multifaceted challenge that demands rigorous evaluation, robust observability, and continuous iteration. By systematically instrumenting retrieval and generation workflows, employing advanced rerankers, and leveraging platforms like Maxim AI, teams can identify and resolve issues with precision, ensuring their AI agents deliver reliable, contextually accurate, and high-quality responses.
As RAG continues to shape the future of AI-powered applications, mastering its debugging strategies is essential for building systems that inspire user trust and deliver real business value. To accelerate your RAG development and debugging journey, explore Maxim AI’s platform and join a growing community of innovators pushing the boundaries of retrieval-augmented generation.


