LLM-as-a-Judge vs Human-in-the-Loop Evaluations: A Complete Guide for AI Engineers

Modern LLM-powered systems don’t behave like traditional software. The same input can yield different outputs depending on sampling parameters, context, upstream tools, or even seemingly harmless prompt changes. Models are updated frequently, third‑party APIs change under the hood, and user behavior evolves over time. All of this makes behavioral quality a moving target.
In classic software, we lean on unit tests, integration tests, and exact string matching: given input X, the program should always return output Y. But with LLMs:
- Outputs are non-deterministic and probabilistic.
- Many tasks are open-ended ("write a summary", "help debug this", "play the role of a sales agent").
- There may be many acceptable outputs and no single “correct” string.
As a result, traditional software testing alone is not enough. You can (and should) still have programmatic checks—schema validation, safety filters, regression tests—but they won’t tell you whether a response is good, helpful, or on-brand.
That’s where evaluations come in. We need ways to:
- Measure quality of free-form LLM outputs at scale.
- Compare prompts, models, and architectures with meaningful metrics.
- Continuously monitor production behavior as models and traffic change.
Two complementary families of approaches have emerged:
- LLM-as-a-Judge – using powerful LLMs to automatically score, compare, or rank outputs. Surveys show that LLM judges can reach human-level agreement on many general instruction-following tasks while scaling to large test suites. (Li et al., 2024; Zheng et al., 2023)
- Human-in-the-Loop (HITL) evaluation – involving humans as the ultimate arbiter of quality, especially in specialized or high-stakes settings. (Mosqueira-Rey et al., 2022; Wu et al., 2022)
The reliability of AI applications depends on combining these strategies in a way that matches your domain, risk tolerance, and scale. This guide examines both paradigms, their trade-offs, and how to implement them effectively using Maxim AI's evaluation framework.
The Evaluation Challenge in Modern AI Systems
Evaluating AI outputs presents unique challenges that traditional software testing methods cannot adequately address.
Even for a simple question-answering or summarization system:
- The same prompt can reasonably yield multiple different—but still acceptable—answers.
- Tiny changes to prompts or context windows can create large behavioral shifts.
- Model upgrades from providers can change behavior even when your own code stays the same.
Traditional approaches like exact string matching, brittle regexes, or simple semantic similarity scores miss these nuances. They treat quality as “match vs no match” when, in reality, we care about criteria like faithfulness, helpfulness, tone, safety, and task completion.
Recent work on LLM-as-a-Judge shows that strong models can act as surprisingly reliable automatic evaluators for many general tasks, often agreeing with human preferences at rates comparable to human–human agreement. (Li et al., 2024; Zheng et al., 2023) At the same time, studies in expert domains (e.g., dietetics, mental health, and other specialized decision-making tasks) find that subject matter experts agree with LLM judges only around 60–70% of the time, underscoring the need for human oversight in specialized contexts. (Park et al., 2025)
As organizations scale their AI applications, the evaluation problem compounds:
- Volume: You may need to evaluate thousands or millions of interactions.
- Breadth: Outputs span summarization, multi-step reasoning, dialog, tool usage, and more.
- Drift: User behavior and model behavior both evolve, so evaluation must be continuous.
This gap has driven the adoption of two complementary evaluation paradigms: automated LLM-based evaluation and structured human-in-the-loop assessment.
Understanding LLM-as-a-Judge Evaluations
What is LLM-as-a-Judge?
LLM-as-a-Judge refers to systems where large language models evaluate outputs or components of AI applications for quality, relevance, and accuracy. This approach leverages the reasoning capabilities of powerful models to assess AI-generated content at scale. Surveys of LLM-based evaluation methods show that these judges can be used for pointwise scoring, pairwise preference modeling, and more complex listwise ranking setups across a wide variety of tasks. (Li et al., 2024; Li et al., 2024)
In pairwise comparisons, LLM evaluations have achieved over 80% agreement with crowdsourced human preferences on general instruction-following and dialogue tasks, which is comparable to the level of agreement between human evaluators. (Zheng et al., 2023)
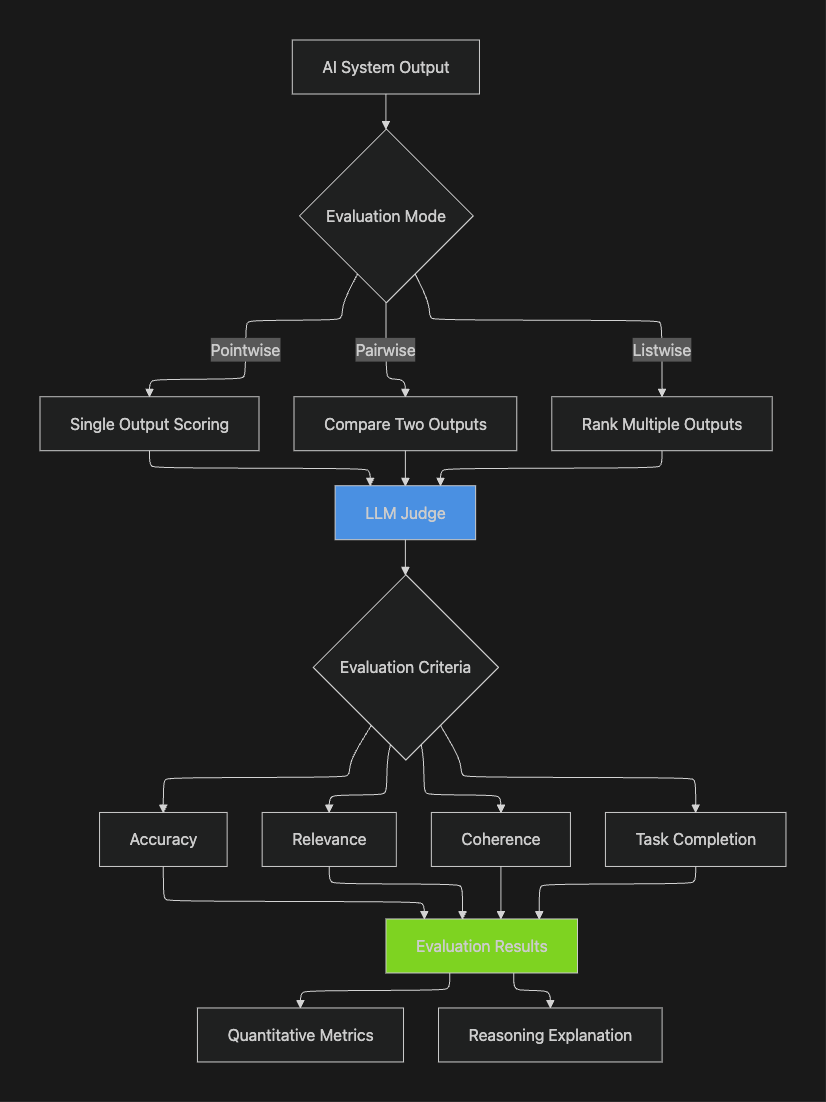
The methodology typically encompasses three primary evaluation modes:
Pointwise Evaluation: The LLM evaluates a single output independently, assigning scores or labels based on predefined criteria. This approach works well for continuous monitoring where each response needs individual assessment.
Pairwise Comparison: The LLM compares two outputs side-by-side to determine which performs better. This method proves particularly effective during development when teams need to select between model versions or prompt variations.
Listwise Ranking: The LLM evaluates and ranks multiple outputs simultaneously, useful for tasks like search result ordering or recommendation systems where relative quality matters.
Benefits of LLM-as-a-Judge
Scalability: LLM judges can evaluate thousands of outputs in minutes, making them ideal for large-scale testing and continuous production monitoring. Teams using Maxim's evaluation framework can run automated evaluations across entire test suites without manual intervention.
Consistency: Unlike human evaluators who may experience fatigue or apply subjective standards, LLM judges maintain consistent evaluation criteria across large datasets. This consistency becomes critical when comparing model performance over time.
Cost-Efficiency: With their ability to process diverse data types and provide scalable, cost-effective, and consistent assessments, LLMs present a compelling alternative to traditional expert-driven evaluations. The cost per evaluation typically ranges from $0.001 to $0.01, significantly lower than human review.
Interpretability: LLM judges can provide natural language explanations for their decisions, helping teams understand quality issues and prioritize improvements. This transparency supports faster iteration cycles.
Limitations and Considerations
Despite their advantages, LLM-as-a-Judge systems face several challenges that teams must consider.
Bias and Fairness: Studies comparing human and LLM judges show that both are vulnerable to subtle perturbations and can exhibit systematic biases, including Misinformation Oversight Bias, Gender Bias, Authority Bias, and Beauty Bias. (Chen et al., 2024; Li et al., 2024) Teams must regularly audit evaluations for systematic biases.
Domain Expertise Limitations: LLM-as-a-Judge evaluations show limitations for tasks requiring specialized knowledge, with agreement rates varying significantly across domains even when expert persona LLMs are used. Medical diagnoses, legal analysis, and specialized technical content often require expert human validation. (Park et al., 2025)
Prompt Sensitivity: Evaluation quality can vary significantly based on how evaluation criteria are phrased in prompts. Research on LLM-as-judge prompting shows that asking the LLM to explain its reasoning or think step-by-step through Chain-of-Thought prompting significantly improves evaluation quality. (Li et al., 2024)
Preference Leakage: Recent research exposed preference leakage, a contamination problem in LLM-as-a-judge caused by the relatedness between data generator LLMs and evaluator LLMs, showing bias toward related student models. (Zheng et al., 2023)
Understanding Human-in-the-Loop Evaluations
What is Human-in-the-Loop?
Human-in-the-loop machine learning involves researchers defining new types of interactions between humans and machine learning algorithms, where humans can be involved in the learning process through active learning, interactive machine learning, and machine teaching. In evaluation contexts, HITL places human expertise at the center of quality assessment processes. (Mosqueira-Rey et al., 2022; Wu et al., 2022)
Recent research distinguishes between Human-in-the-Loop systems where AI is in control and AI-in-the-Loop systems where humans remain in control of the system while AI supports decision-making. For evaluation purposes, the AI-in-the-Loop model often proves more appropriate, as human judgment serves as the ultimate quality arbiter. (Natarajan et al., 2024)
When Human Evaluation Becomes Essential
Human-in-the-loop evaluation becomes critical in several scenarios:
High-Stakes Decisions: Applications affecting health, safety, legal outcomes, or financial decisions require human oversight to catch errors that automated systems might miss. The consequences of false positives or negatives demand expert verification.
Nuanced Quality Judgments: Tasks requiring cultural context, emotional intelligence, or subjective aesthetic judgments benefit from human evaluation. Creative content, user experience design, and brand voice consistency often need human assessment.
Domain Expertise Requirements: Specialized fields where LLMs show reduced agreement with subject matter experts necessitate human evaluation to ensure accuracy and appropriateness. Medical content, scientific research, and regulated industries typically mandate expert review. (Park et al., 2025)
Edge Cases and Failures: When AI systems encounter unusual inputs or failure modes, human evaluators can identify root causes and categorize error types in ways that inform system improvements.
HITL Implementation Approaches
Organizations implement HITL evaluation through several mechanisms:
Expert Review Panels: Subject matter experts evaluate outputs based on domain-specific criteria. Maxim AI's human evaluation features enable teams to configure custom review workflows with multiple evaluators.
Crowdsourced Evaluation: Distributed human evaluators assess outputs at scale, providing diverse perspectives. Statistical aggregation methods like majority voting or quality-weighted averaging produce consensus judgments.
Active Learning Integration: Human-in-the-loop aims to train accurate prediction models with minimum cost by integrating human knowledge and experience, with humans providing training data and accomplishing tasks that are hard for computers. Systems can identify uncertain cases and route them to human reviewers while handling clear-cut cases automatically. (Wu et al., 2022)
Continuous Feedback Loops: Ethical evaluation within HITL systems incorporates human knowledge and experience into learning models through continuous rewards and penalties for feedback training, generating choices closest to human judgment.
Comparative Analysis: LLM-as-a-Judge vs Human-in-the-Loop
The choice between evaluation approaches depends on specific application requirements, resource constraints, and quality standards. The following comparison highlights key decision factors:
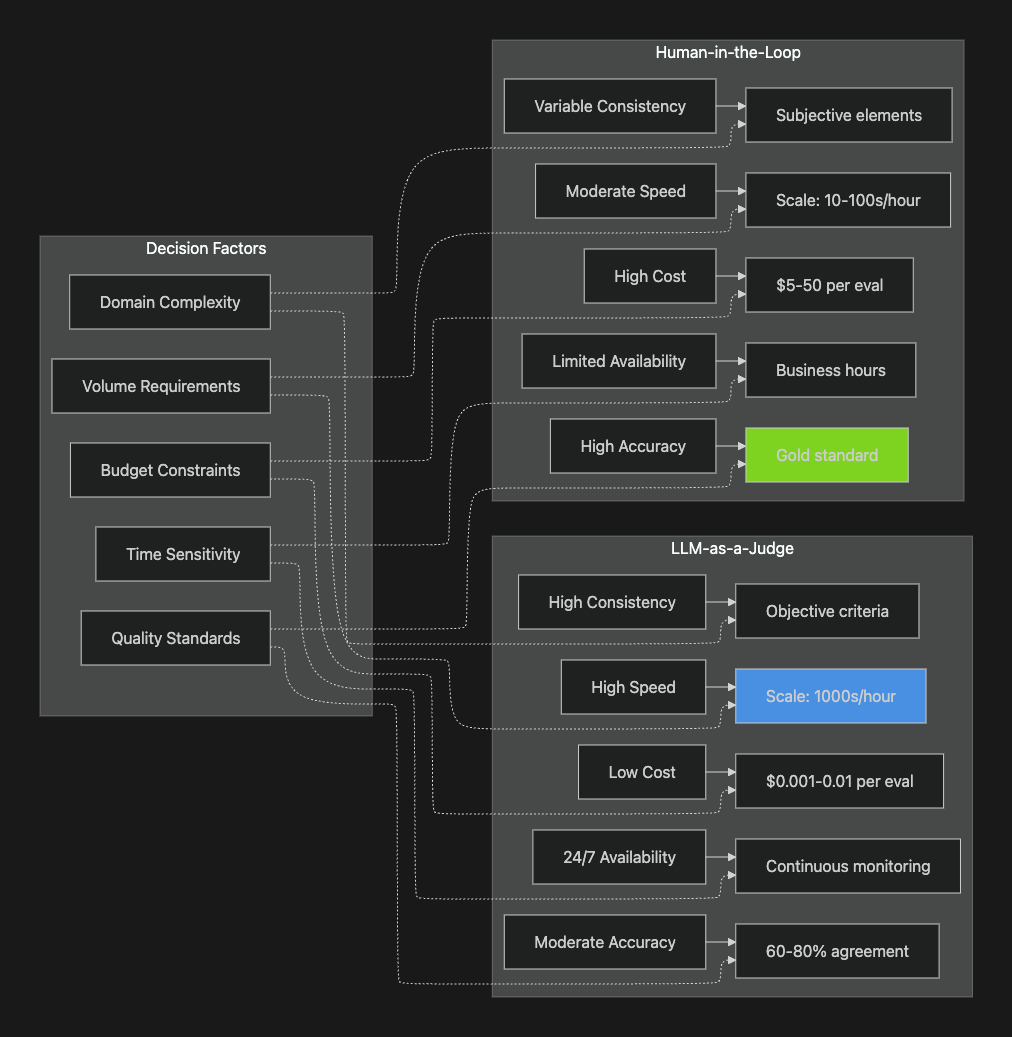
Speed and Scalability
LLM-as-a-Judge systems excel in high-volume scenarios, processing thousands of evaluations per hour with minimal latency. This capability enables continuous production monitoring and large-scale A/B testing. Human evaluation, while more limited in throughput, provides deeper analysis of complex cases that automated systems struggle to assess accurately.
Cost Considerations
The economic trade-off becomes significant at scale. LLM evaluations cost 500-5000x less than human review, making them sustainable for continuous monitoring. However, when specialized expertise is required, the cost of errors from inaccurate automated evaluation can exceed the cost of human review.
Accuracy and Reliability
While LLM judges achieve over 80% agreement with humans in general instruction-following tasks, this performance degrades in specialized domains. Human evaluators remain the gold standard for establishing ground truth, particularly for nuanced quality dimensions that require contextual understanding. (Zheng et al., 2023; Park et al., 2025)
Consistency and Bias
LLM judges maintain consistent criteria across evaluations, but exhibit systematic biases that can affect evaluation validity. Human evaluators bring diverse perspectives but may introduce inconsistency through subjective interpretation or evaluator fatigue. Neither approach is inherently superior; both require active management of bias sources. (Chen et al., 2024)
Hybrid Evaluation Strategies: The Best of Both Worlds
Organizations increasingly adopt hybrid approaches that combine automated and human evaluation to optimize for both scale and quality. Research emphasizes human-AI symbiosis where AI becomes a co-adaptive process, with humans changing AI behavior while also adapting to use AI more effectively. (Natarajan et al., 2024)
Tiered Evaluation Architecture
A practical hybrid strategy implements multiple evaluation tiers:
Tier 1 - Automated Screening: LLM-as-a-Judge evaluates all outputs for basic quality criteria, filtering out clear failures and flagging edge cases for human review. This tier handles 80-90% of cases automatically.
Tier 2 - Human Review: Expert evaluators assess flagged outputs, edge cases, and a random sample for quality assurance. This tier provides ground truth labels that calibrate automated evaluators.
Tier 3 - Expert Validation: For critical applications, a second level of human review validates high-stakes decisions or resolves disagreements between automated and initial human assessments.
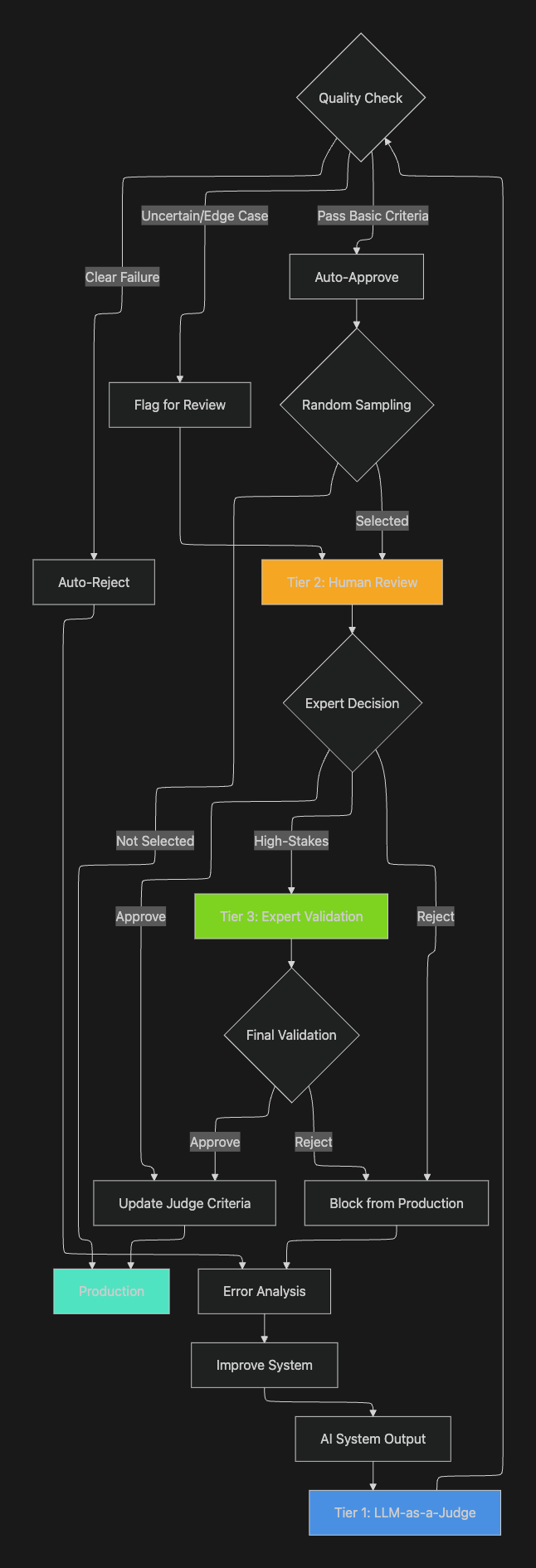
Active Learning for Evaluation
Implement active learning to minimize human evaluation burden while maximizing quality:
Uncertainty Sampling: Route outputs where LLM judges show low confidence (scores near decision boundaries) to human reviewers. This focuses human expertise on genuinely ambiguous cases.
Diversity Sampling: Ensure human evaluation covers diverse output types and edge cases rather than clustering around common patterns. This prevents blind spots in automated evaluation calibration.
Disagreement Resolution: When multiple LLM judges disagree, escalate to human review to establish consensus and refine evaluation criteria.
Continuous Calibration
Use human evaluation results to continuously improve LLM-as-a-Judge performance:
Feedback Integration: Human decisions become training data for refining automated evaluators. Maxim's data curation capabilities enable teams to build evaluation datasets from production feedback.
Bias Monitoring: Track systematic disagreements between human and automated evaluation to identify and address bias patterns. (Chen et al., 2024)
Criteria Refinement: Human evaluators can identify edge cases and quality dimensions that automated evaluators miss, informing prompt improvements and evaluation framework updates.
Implementing Both Approaches with Maxim AI
Maxim AI provides a comprehensive platform for implementing both LLM-as-a-Judge and human-in-the-loop evaluations within a unified workflow.
Automated LLM-Based Evaluation
Maxim's evaluator store provides off-the-shelf LLM-as-a-Judge evaluators for common quality dimensions:
- Accuracy evaluators verify factual correctness against knowledge bases
- Relevance metrics assess response appropriateness to user queries
- Coherence checks evaluate logical consistency and flow
- Safety evaluators detect harmful, biased, or inappropriate content
- Task completion metrics validate whether AI agents successfully accomplish intended objectives
Teams can also create custom LLM-based evaluators tailored to specific application requirements. These evaluators can operate at multiple granularity levels:
- Span-level evaluation: Assess individual LLM calls or tool invocations
- Trace-level evaluation: Evaluate complete request-response cycles
- Session-level evaluation: Analyze multi-turn conversations or agent trajectories
The platform supports programmatic and statistical evaluators alongside LLM judges, enabling teams to combine deterministic rules with AI-based assessment for comprehensive coverage.
Human-in-the-Loop Evaluation Workflows
Maxim's human evaluation features enable teams to configure custom review processes:
Flexible Review Assignment: Route outputs to appropriate reviewers based on domain expertise, workload, or evaluation criteria. Support for both internal team members and external expert panels.
Structured Feedback Collection: Define custom evaluation forms with quantitative scores, categorical labels, and qualitative feedback fields. Collect structured data that informs system improvements.
Consensus Mechanisms: Configure multi-reviewer workflows with majority voting, weighted averaging, or adjudication processes for handling disagreements.
Annotation Tools: Rich annotation interfaces for text, images, and multi-modal content enable detailed feedback capture.
Hybrid Evaluation Orchestration
Maxim AI's architecture supports sophisticated hybrid strategies:
Conditional Routing: Configure rules that automatically route outputs to human review based on LLM judge scores, confidence levels, or specific failure patterns detected by automated evaluators.
Quality Assurance Sampling: Automatically sample a percentage of auto-approved outputs for human review to maintain calibration and catch systematic errors.
Disagreement Analysis: Track cases where human and automated evaluations disagree, using these insights to improve automated evaluator performance.
Dataset Curation: Maxim's data engine enables teams to build evaluation datasets from production logs, human feedback, and synthetic data generation, creating a virtuous cycle of continuous improvement.
Production Integration
Deploy evaluations across the AI lifecycle:
Pre-Production Testing: Run comprehensive evaluation suites during development using Maxim's experimentation platform to compare prompt versions, model configurations, and architectural approaches.
Simulation-Based Evaluation: Use agent simulation capabilities to test AI systems across hundreds of scenarios and user personas before production deployment.
Continuous Monitoring: Leverage Maxim's observability suite to run periodic automated evaluations on production logs, with alerts for quality degradation.
Feedback Loop Closure: Connect evaluation results back to Maxim's experimentation platform to iterate on prompts and system configurations based on production performance data.
Best Practices for Evaluation Strategy Selection
Start with LLM-as-a-Judge for Rapid Iteration
During early development, prioritize speed and iteration velocity. Configure LLM-as-a-Judge evaluators for key quality dimensions and use them to rapidly test variations. Accept the trade-off of moderate accuracy for high throughput during the exploration phase. (Li et al., 2024)
Establish Human-Validated Baselines
Before scaling automated evaluation, collect human judgments on a representative sample of outputs. This baseline serves three purposes:
- Calibration: Compare LLM judge performance against human gold standard
- Bias Detection: Identify systematic disagreements that indicate evaluator bias
- Criteria Refinement: Ensure automated evaluators align with actual quality requirements
Layer Evaluation Complexity
Implement multiple evaluation stages with increasing sophistication:
- Fast filters: Simple programmatic checks for formatting, length, content safety
- LLM scoring: Automated quality assessment across multiple dimensions
- Human review: Expert validation of edge cases and high-stakes decisions
This layered approach minimizes cost while maintaining quality standards.
Monitor and Adapt Continuously
Evaluation strategies require ongoing refinement as systems evolve. Track key metrics:
- Agreement rates between automated and human evaluation
- Evaluation distribution across quality scores
- Error type patterns in production
- Cost per evaluation across methods
- False positive/negative rates for automated filters
Use these metrics to adjust routing thresholds, refine evaluation criteria, and optimize the mix of automated and human evaluation.
Consider Domain-Specific Requirements
Domain complexity significantly affects appropriate evaluation approach, with specialized fields requiring higher levels of human oversight. Healthcare, legal, financial, and safety-critical applications should maintain higher ratios of human review compared to general-purpose content generation.
Document Evaluation Decisions
Maintain clear documentation of:
- Evaluation criteria and their operational definitions
- Quality thresholds for different application contexts
- Routing rules between automated and human evaluation
- Known limitations and edge cases for automated evaluators
- Human evaluator training materials and guidelines
This documentation ensures consistency as teams scale and provides audit trails for regulated industries.
Conclusion
The debate between LLM-as-a-Judge and human-in-the-loop evaluation presents a false dichotomy. Modern AI applications benefit most from thoughtful hybrid strategies that leverage automated evaluation for scale and efficiency while preserving human judgment for quality assurance and continuous improvement.
Building reliable LLM-as-a-Judge systems requires careful design and standardization, with strategies to enhance consistency, mitigate biases, and adapt to diverse assessment scenarios. Simultaneously, effective human-AI collaboration requires recognizing that the human expert is an active participant in the system, significantly influencing its overall performance. (Natarajan et al., 2024)
Organizations that successfully implement hybrid evaluation strategies achieve superior outcomes: the speed and consistency of automated evaluation combined with the accuracy and nuance of human judgment. This approach reduces evaluation costs while maintaining quality standards, enabling teams to iterate faster and deploy more reliable AI applications.
Maxim AI's evaluation platform provides the infrastructure to implement these hybrid strategies effectively, with unified support for automated evaluators, human review workflows, and continuous improvement cycles. By combining comprehensive evaluation capabilities with simulation, experimentation, and observability tools, Maxim empowers teams to ship AI agents reliably and more than 5x faster.
Ready to optimize your AI evaluation strategy? Schedule a demo to see how Maxim AI can help you implement scalable, high-quality evaluation workflows that combine the best of automated and human assessment.
References
- Li, H., et al. (2024). "A Survey on LLM-as-a-Judge." arXiv:2411.15594.
- Li, H., et al. (2024). "LLMs-as-Judges: A Comprehensive Survey on LLM-based Evaluation Methods." arXiv:2412.05579.
- Zheng, L., et al. (2023). "Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena." NeurIPS 2023.
- Chen, G.H., et al. (2024). "Humans or LLMs as the Judge? A Study on Judgement Bias." EMNLP 2024.
- Park, J., et al. (2025). "Limitations of the LLM-as-a-Judge Approach for Evaluating LLM Outputs in Expert Knowledge Tasks." IUI 2025.
- Mosqueira-Rey, E., et al. (2022). "Human-in-the-loop machine learning: a state of the art." Artificial Intelligence Review.
- Wu, X., et al. (2022). "A Survey of Human-in-the-loop for Machine Learning." arXiv:2108.00941.
- Natarajan, S., et al. (2024). "Human-in-the-loop or AI-in-the-loop? Automate or Collaborate?" arXiv:2412.14232.


