How to Accelerate Your AI Agent Development Cycle: Tools and Strategies

The AI agent development landscape has reached a critical inflection point. According to Gartner's 2025 research, over 40% of agentic AI projects will be canceled by the end of 2027 due to escalating costs, unclear business value, and inadequate risk controls. Yet simultaneously, industry forecasts predict that at least 15% of day-to-day work decisions will be made autonomously through agentic AI by 2028, up from 0% in 2024.
This paradox reveals a fundamental truth: speed alone is not sufficient. The teams that succeed will be those who can accelerate their development cycles while maintaining rigorous quality standards, comprehensive testing, and robust monitoring capabilities. This guide explores proven strategies and essential tools for accelerating AI agent development without sacrificing reliability.
Understanding the AI Agent Development Lifecycle
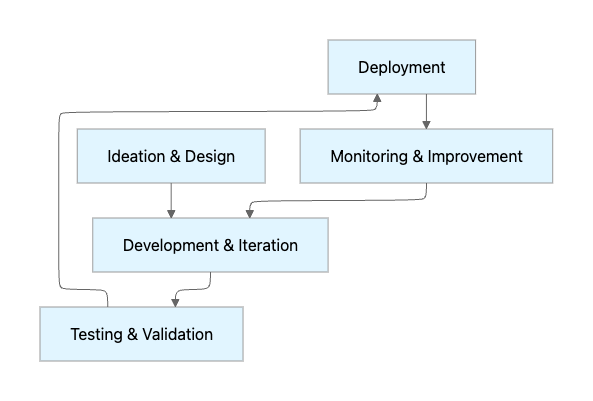
The AI Agent Development Lifecycle (ADLC) represents a significant departure from traditional software development methodologies. Unlike conventional applications that follow deterministic, rule-based logic, AI agents operate on goal-oriented, non-deterministic principles that require fundamentally different approaches to development, testing, and deployment.
The ADLC typically encompasses five critical phases:
Ideation and Design: Defining agent objectives, constraints, and boundaries while establishing explicit safety measures to prevent severe failures. This phase requires careful consideration of which use cases truly benefit from agentic approaches rather than simpler deterministic solutions.
Development and Iteration: Building the agent's core capabilities through rapid prototyping and testing. Research from LangChain's State of AI Agents Report reveals that teams struggle most with the technical know-how required to implement agents for specific use cases, making this phase particularly challenging.
Testing and Validation: Comprehensive evaluation combining automated testing, human review, and production simulation. This phase addresses the fundamental challenge that AI agents can produce different results for identical inputs due to their non-deterministic nature.
Deployment: Gradual rollout with version control and rollback capabilities. Leading companies deploy agents incrementally, starting with internal test groups before expanding to production traffic.
Monitoring and Continuous Improvement: Real-time observation of agent behavior with feedback loops for ongoing refinement. IBM research emphasizes that transparency and traceability of actions for every agent interaction becomes critical at this stage.
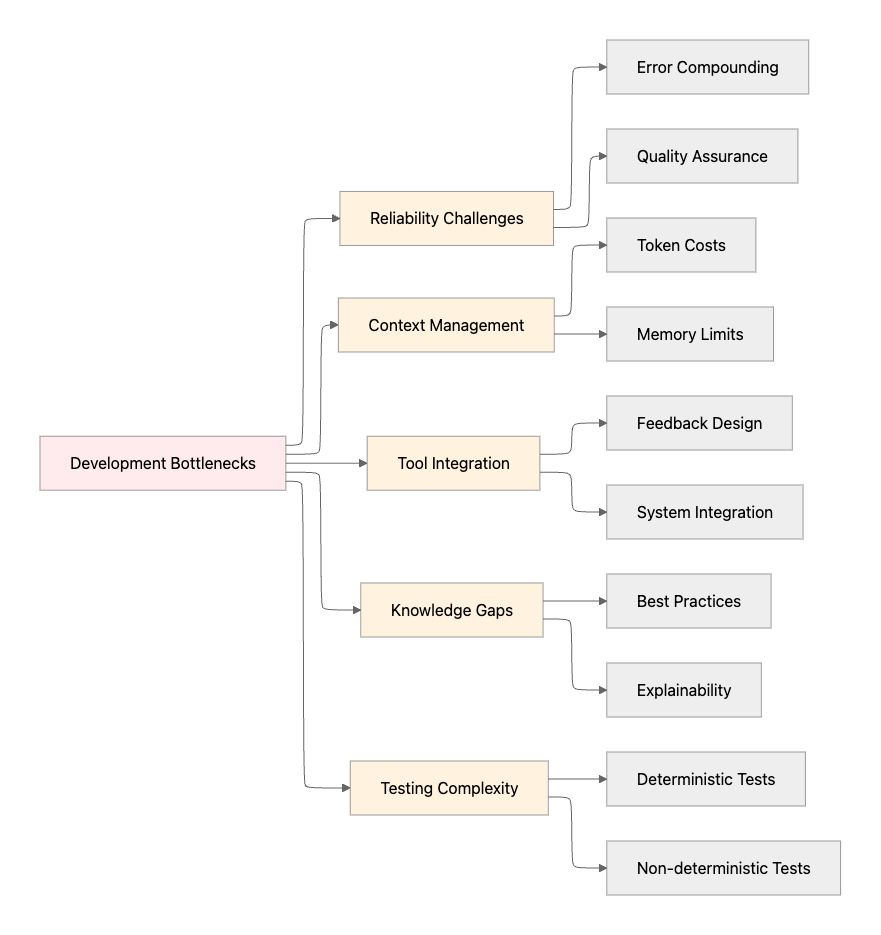
Key Bottlenecks Slowing Down AI Agent Development
Understanding the specific challenges that slow development cycles is essential for implementing effective acceleration strategies.
Reliability and Quality Assurance Challenges
Research indicates that 61% of companies have experienced accuracy issues with their AI tools, with only 17% rating their in-house models as excellent. The LangChain survey confirms that performance quality far outweighs other considerations for small companies, with 45.8% citing it as a primary concern.
The mathematical reality of error compounding presents a significant challenge. Analysis shows that with 95% reliability per step, a 20-step workflow achieves only 36% overall success. Production environments require 99.9%+ reliability, creating substantial pressure on quality assurance processes.
Context Management and Memory Limitations
Current agents struggle with maintaining context across long conversations or complex multi-day tasks. Context windows create quadratic token costs, making long conversations prohibitively expensive at scale. This limitation forces teams to carefully design information architecture and context management strategies.
Tool Integration Complexity
The real challenge in agent development is not AI capabilities themselves but designing tools and feedback systems that agents can effectively use. Production experience reveals that every tool needs careful crafting to provide appropriate feedback without overwhelming the context window.
Knowledge Gaps and Best Practices
Industry surveys highlight that teams struggle with understanding agent behavior and explaining capabilities to stakeholders. The lack of established best practices creates uncertainty around implementation approaches, forcing teams to learn through expensive trial and error.
Evaluation and Testing Complexity
Unlike traditional software, AI agents require both deterministic and non-deterministic evaluation approaches. Teams need assertion-based evaluations for predictable elements like topic choice and action selection, alongside LLM-based evaluations for stochastic elements like response quality and hallucination detection.
Proven Strategies to Accelerate Development Cycles
Implement a Robust Evaluation Framework Early
The single biggest unlock for guaranteeing success in agentic systems is establishing a well-curated evaluation suite from the project's inception. Teams should break down agents into testable components, examining foundation model performance, tool selection accuracy, planning coherence, multi-turn conversation handling, and error recovery capabilities.
Research demonstrates that purpose-built evaluation frameworks with built-in support for conversation flows, tool usage verification, and decision tree analysis significantly reduce development time. Leading enterprises have found success with hybrid approaches that combine ReAct-based testing for agent reasoning with traditional unit tests for tool integrations.
Adopt Continuous Testing and Feedback Loops
Ongoing evaluation is crucial for AI agents, involving continuous assessment and feedback from both experts and automated systems. Teams should establish mechanisms to audit interactions regularly, providing feedback that refines and enhances agent behavior.
Sierra's approach to agent development emphasizes that customer experience teams should formally evaluate conversation samples every day, annotating them with feedback about decision correctness, language and tone appropriateness, and knowledge gaps. These annotated conversations become the basis for regression tests, ensuring agents never repeat past mistakes.
Use Simulation for Comprehensive Testing
Simulation capabilities enable teams to test agents across hundreds of scenarios before production deployment. By simulating customer interactions across real-world scenarios and user personas, teams can identify failure points and edge cases early in the development cycle.
Industry analysis shows that leading teams run large-scale simulated runs in parallel, stress-testing how agents perform under new prompts, edge cases, or tool combinations. This proactive approach prevents costly production issues and accelerates the path to reliable deployment.
Establish Clear Governance and Risk Frameworks
Organizations must incorporate AI risk into existing governance structures, creating clear policies around monitoring responsibility, incident reporting, and performance metrics tied to business goals. The NIST AI Risk Management Framework suggests assessing factors like robustness, safety, privacy, and ethics at each development phase.
IBM's watsonx.governance approach demonstrates how governance can accelerate rather than slow development. By providing a library of over 50 metrics that can be added as decorators to applications, teams can measure performance systematically without manual instrumentation overhead.
Implement Gradual Deployment Strategies
Teams should roll out agents gradually, first to internal test groups, then to controlled pilots, and finally to production traffic. Each interaction provides behavioral data that helps in evaluation and iteration. Modern platforms support controlled A/B tests that direct traffic percentages to candidate configurations, comparing task completion, speed, and hallucination rates side by side.
Research indicates that rollouts should start at 5%, with teams watching real-time dashboards and expanding only when metrics improve across the board. This approach combines regression tests with data-driven experimentation, enabling confident improvements without sacrificing stability.
Essential Tools for Faster Development
Comprehensive Observability Platforms
Real-time observability becomes essential once agents are deployed. Teams need tools that provide trace-level visibility into agent decision-making processes, enabling quick identification of failure patterns and root cause analysis.
Maxim AI's Observability suite empowers teams to monitor real-time production logs and run periodic quality checks. Key capabilities include distributed tracing across multiple repositories, real-time alerts for quality issues, and automated evaluations based on custom rules. The platform enables teams to track, debug, and resolve live issues with minimal user impact.
Advanced Evaluation and Testing Tools
Databricks research on agent evaluation emphasizes that the same evaluation metrics should be used in both development and production to ensure consistency throughout the application lifecycle. MLflow's approach demonstrates the value of integrated review apps for collecting human feedback alongside automated LLM judges.
Maxim AI's unified evaluation framework allows teams to quantify improvements or regressions across machine and human evaluations. The platform provides access to various off-the-shelf evaluators through an evaluator store, while supporting custom evaluators for specific application needs. Teams can measure prompt and workflow quality quantitatively using AI, programmatic, or statistical evaluators, then visualize evaluation runs on large test suites across multiple versions.
Simulation and Scenario Testing Platforms
Microsoft Copilot Studio's evolution demonstrates the importance of integrated simulation capabilities. The platform enables makers to upload, generate, or reuse question sets to test for accuracy and relevance, with results presented through clear pass/fail indicators and filterable views that surface quality gaps early.
Maxim AI's Simulation capabilities enable teams to use AI-powered simulations to test and improve agents across hundreds of scenarios and user personas. Key features include simulating customer interactions across real-world scenarios, evaluating agents at a conversational level by analyzing trajectory choices and task completion, and re-running simulations from any step to reproduce issues and identify root causes.
Experimentation and Prompt Management Tools
Effective experimentation tools enable rapid iteration on prompts, models, and parameters without requiring code changes. Teams need capabilities to organize and version prompts, deploy with different variables, and compare output quality across various combinations.
Maxim AI's Playground++ is built for advanced prompt engineering, enabling rapid iteration, deployment, and experimentation. Users can organize and version prompts directly from the UI for iterative improvement, deploy prompts with different deployment variables without code changes, and simplify decision-making by comparing output quality, cost, and latency across various combinations of prompts, models, and parameters.
Unified LLM Gateways
Managing multiple LLM providers creates operational complexity that slows development. Teams need infrastructure that provides unified access to multiple providers through a single interface, with automatic failover and load balancing capabilities.
Bifrost, Maxim AI's LLM gateway, unifies access to 12+ providers through a single OpenAI-compatible API. Key capabilities include automatic failover between providers, intelligent load balancing, semantic caching to reduce costs and latency, and Model Context Protocol support for enabling AI models to use external tools. The gateway's zero-configuration startup and drop-in replacement capabilities enable teams to start immediately without infrastructure overhead.
How Maxim AI Accelerates Your Development Cycle
Maxim AI provides an end-to-end platform that addresses every bottleneck in the AI agent development lifecycle, enabling teams to ship agents reliably and more than 5x faster.
Pre-Production Acceleration
Rapid Experimentation: Maxim's Playground++ eliminates the iteration bottleneck by enabling teams to test multiple prompt variations, models, and parameters simultaneously. Teams can compare performance metrics side-by-side, making data-driven decisions without writing code or managing complex infrastructure.
Comprehensive Simulation: Before production deployment, Maxim's simulation capabilities enable teams to test agents across hundreds of realistic scenarios. This proactive approach identifies edge cases and failure modes early, preventing costly production issues and dramatically reducing the time required to achieve production-ready quality.
Unified Evaluation Framework: Maxim's evaluation suite provides both automated and human evaluation capabilities, enabling teams to measure quality comprehensively without building custom evaluation infrastructure. The platform's evaluator store offers pre-built metrics for common use cases, while custom evaluator support ensures teams can measure exactly what matters for their applications.
Production Excellence
Real-Time Observability: Maxim's observability platform provides distributed tracing across agent interactions, enabling teams to track, debug, and resolve issues quickly. Real-time alerts ensure teams can act on production issues with minimal user impact, while automated evaluations continuously monitor quality against custom rules.
Continuous Improvement: Production data automatically feeds back into the development cycle through Maxim's data curation capabilities. Teams can enrich datasets using in-house or Maxim-managed data labeling, creating high-quality evaluation sets that drive continuous improvement without manual data management overhead.
Cross-Functional Collaboration: Unlike platforms that silo engineering teams, Maxim's user experience is anchored to how AI engineering and product teams collaborate seamlessly. Product managers can configure evaluations and create custom dashboards without code, while engineers maintain the flexibility to implement sophisticated custom logic through comprehensive SDKs.
Infrastructure Optimization
Bifrost eliminates infrastructure management overhead by providing enterprise-grade capabilities out of the box. Teams gain automatic failover, load balancing, semantic caching, and comprehensive observability without building custom solutions. The gateway's support for 12+ providers ensures teams can optimize for cost and performance without vendor lock-in.
Best Practices for Implementation
Start with High-Value, Low-Risk Use Cases
Industry experience demonstrates that teams should build organizational confidence through early wins. Begin with use cases that deliver clear value while minimizing risk exposure. This approach enables teams to develop best practices and build institutional knowledge before tackling more sensitive workflows.
Invest in Comprehensive Evaluation Infrastructure Early
The heart of successful ADLC is the agent development flywheel, which takes teams from functional pilots that produce great but unreliable results to systems that are robust and trustworthy in production. The key is moving beyond vibes-based assessment to methodical approaches anchored in well-curated evaluation suites.
Establish Clear Safety and Security Boundaries
Set explicit boundaries for agent behavior to prevent undesirable actions. Utilize fixed versions that package agent releases with all dependencies, ensuring consistency and enabling rollback capabilities. This approach, similar to infrastructure as code, facilitates robust version control and enables quick reversion if issues occur.
Implement Human-in-the-Loop Processes
Deep support for human review collection ensures agents continue aligning with human preferences. Teams should establish processes for domain experts to review agent outputs regularly, with findings automatically feeding back into evaluation datasets and training processes.
Monitor Continuously and Iterate Based on Data
Production monitoring becomes critical for maintaining system reliability and trust. Teams need ongoing surveillance to address issues like hallucination, response time, model drift, and bias. Effective monitoring enables teams to identify patterns, feed edge cases back into evaluation suites, and ensure progress doesn't come at the cost of reliability.
Conclusion
Accelerating AI agent development cycles while maintaining reliability requires a fundamental shift in approach. Teams cannot simply apply traditional software development methodologies to non-deterministic, goal-oriented systems. Success demands comprehensive evaluation frameworks, robust testing infrastructure, continuous monitoring capabilities, and tools designed specifically for the unique challenges of agentic AI.
As the AI agent market grows from $5.40 billion in 2024 to a projected $50.31 billion by 2030, the competitive advantage will belong to teams that can move quickly without sacrificing quality. The combination of proven strategies, purpose-built tools, and disciplined execution enables teams to achieve the speed necessary for market success while maintaining the reliability essential for production deployment.
Maxim AI provides the comprehensive platform necessary to accelerate every phase of the AI agent development lifecycle. From rapid experimentation and comprehensive simulation to production observability and continuous improvement, Maxim enables teams to ship agents reliably and more than 5x faster.
Ready to accelerate your AI agent development cycle? Schedule a demo to see how Maxim AI can help your team ship reliable AI agents faster, or sign up today to start building with confidence.