Gemini 3 Pro vs Claude Opus 4.5 vs GPT-5: The Ultimate Frontier Model Comparison

The artificial intelligence landscape experienced an unprecedented release cycle in late 2025, with three frontier models launching within weeks of each other. Google's Gemini 3 Pro arrived on November 18, followed by Claude Opus 4.5 from Anthropic on November 24, both building upon OpenAI's GPT-5 release from August 7. This rapid succession of releases marks an inflection point in AI capabilities, with each model claiming state-of-the-art performance across critical benchmarks. For AI engineers and product teams building production applications, understanding the nuanced differences between these models is essential for making informed deployment decisions.
This comprehensive analysis examines how Gemini 3 Pro, Claude Opus 4.5, and GPT-5 compare across coding tasks, reasoning capabilities, multimodal understanding, and agentic workflows. We synthesize data from industry-standard benchmarks and real-world testing to provide actionable insights for teams evaluating these models for their AI applications.
Performance Benchmarks: A Detailed Comparison
Coding and Software Engineering
Real-world software engineering capabilities represent one of the most critical differentiators for production AI applications. The SWE-bench Verified benchmark measures a model's ability to resolve actual GitHub issues, testing comprehension, debugging, and integration capabilities simultaneously.
SWE-bench Verified Results:
| Model | SWE-bench Verified | Terminal-Bench 2.0 | Aider Polyglot |
|---|---|---|---|
| Claude Opus 4.5 | 80.9% | 59.3% | Not disclosed |
| Gemini 3 Pro | 76.2% | 54.2% | Not disclosed |
| GPT-5.1 | 76.3% | 47.6% | 88.0% |
| GPT-5 | 74.9% | Not disclosed | 88.0% |
According to Anthropic's official announcement, Claude Opus 4.5 became the first model to break the 80% barrier on SWE-bench Verified, establishing a meaningful performance threshold. The model demonstrates particular strength in terminal-based coding tasks, where it scored 59.3% on Terminal-bench 2.0, significantly outperforming competitors. This advantage translates directly to autonomous coding workflows that require multi-step execution and command-line proficiency.
Google's Gemini 3 Pro shows exceptional performance on algorithmic problem-solving with a LiveCodeBench Pro Elo rating of 2,439, nearly 200 points higher than GPT-5.1's 2,243. This commanding lead indicates superior capability in generating novel, efficient code from scratch. The model also demonstrates strong multimodal code generation, particularly excelling at "vibe coding" where natural language descriptions transform into interactive web applications.
GPT-5 and GPT-5.1 maintain competitive positions, with OpenAI reporting that GPT-5.1 achieves 76.3% on SWE-bench Verified with high reasoning effort. The introduction of adaptive reasoning allows the model to dynamically allocate computational resources, spending more effort on complex problems while responding quickly to simpler queries.
Graduate-Level Reasoning and Scientific Knowledge
The GPQA Diamond benchmark evaluates reasoning capabilities on PhD-level questions across physics, chemistry, and biology, problems that require deep domain expertise and multi-step logical chains.
GPQA Diamond Comparison:
| Model | GPQA Diamond (No Tools) | With Tools/Search |
|---|---|---|
| Gemini 3 Pro | 91.9% | Not disclosed |
| GPT-5 Pro | 88.4% | 89.4% |
| Claude Opus 4.5 | 87.0% | Not disclosed |
| GPT-5 | 85.7% (with thinking) | 88.1% |
Gemini 3 Pro leads significantly on pure reasoning tasks, achieving 91.9% accuracy on GPQA Diamond. Google's model also set a new benchmark on Humanity's Last Exam with 37.5% accuracy without tools, a test designed to push AI systems to their absolute limits. According to TechCrunch's coverage, this represents the highest score on record for this particularly challenging evaluation.
GPT-5 Pro demonstrates strong performance when leveraging tools, scoring 89.4% with Python support. The model's adaptive reasoning capability proves particularly valuable for scientific problems, as thinking mode boosts accuracy from 77.8% to 85.7% on complex queries. This flexibility allows developers to balance performance against latency and cost for different use cases.
Claude Opus 4.5's 87.0% score on GPQA Diamond positions it competitively, though slightly behind the leaders in pure reasoning benchmarks. However, Anthropic emphasizes that Opus 4.5's strength lies in applied reasoning within agentic workflows rather than isolated academic benchmarks.
Mathematical Reasoning
Mathematical capabilities serve as a proxy for logical reasoning and problem-solving precision. The AIME 2025 benchmark tests quantitative reasoning on challenging competition-level problems.
Mathematical Performance:
| Model | AIME 2025 (No Tools) | AIME 2025 (With Code) | MathArena Apex |
|---|---|---|---|
| Gemini 3 Pro | 95.0% | 100% | 23.4% |
| GPT-5 | 94.0% | Not disclosed | 1.0% |
| Claude Opus 4.5 | 87.0% | 100% | 1.6% |
Gemini 3 Pro achieves perfect 100% accuracy on AIME 2025 with code execution tools, matching GPT-5's reported performance. More significantly, its 95.0% accuracy without tools demonstrates robust innate mathematical intuition, making it less dependent on external computational aids. The model's 23.4% score on MathArena Apex (a benchmark featuring extremely challenging contest problems) represents state-of-the-art performance, though the task remains far from solved for any current model.
Multimodal Understanding
Multimodal capabilities enable models to process and reason across text, images, audio, and video, essential for applications ranging from document analysis to visual diagnostics.
Multimodal Benchmarks:
| Model | MMMU-Pro | Video-MMMU | ARC-AGI-2 |
|---|---|---|---|
| Gemini 3 Pro | 81.0% | 87.6% | 31.1% |
| GPT-5.1 | 85.4% (MMMU validation) | Not disclosed | 17.6% |
| Claude Opus 4.5 | Not disclosed | Not disclosed | 37.6% |
Google's Gemini 3 Pro demonstrates exceptional multimodal understanding, leveraging its unified transformer architecture that processes text, images, audio, video, and code within a single stack. This architectural advantage enables genuine cross-modal reasoning, for example, interpreting a sketch and generating working code, or analyzing video content and explaining scientific concepts embedded within.
Claude Opus 4.5 achieves the highest score on ARC-AGI-2 (37.6%), a benchmark specifically designed to test novel problem-solving abilities that cannot be memorized from training data. This visual reasoning puzzle benchmark requires abstract pattern recognition and logical inference, capabilities crucial for computer use and interface navigation tasks.
Use Case Analysis: Selecting the Right Model
Enterprise Coding and Development Workflows
For teams building AI-powered development tools, Claude Opus 4.5 emerges as the clear leader. Its 80.9% accuracy on SWE-bench Verified translates to more reliable code generation, fewer false starts, and better handling of multi-file refactoring tasks. GitHub reported that early testing shows Opus 4.5 "surpasses internal coding benchmarks while cutting token usage in half."
The model's introduction of an effort parameter allows developers to control computational investment per query, balancing performance against latency and cost. At medium effort, Opus 4.5 matches Claude Sonnet 4.5's best SWE-bench score while using 76% fewer output tokens, a significant advantage for high-volume production deployments.
Optimal for:
- Autonomous code review systems requiring high precision
- Multi-agent coding workflows where Opus 4.5 orchestrates multiple Haiku sub-agents
- Long-horizon coding tasks spanning 30+ minutes of autonomous execution
- Production environments where token efficiency directly impacts operational costs
Complex Reasoning and Scientific Applications
Gemini 3 Pro's dominance in reasoning benchmarks makes it the preferred choice for applications requiring deep analytical capabilities. Its 91.9% GPQA Diamond score and 37.5% performance on Humanity's Last Exam demonstrate unmatched capability in tackling novel, complex problems.
The model's 1 million token context window enables processing of extensive research papers, legal documents, or technical specifications without chunking. Google's announcement emphasizes that Gemini 3 Pro "significantly outperforms 2.5 Pro on every major AI benchmark" while maintaining the same underlying characteristics including multimodal inputs across text, images, audio, and video.
Optimal for:
- Scientific research assistants processing large corpus of academic papers
- Legal document analysis requiring synthesis across hundreds of pages
- Strategic business intelligence systems analyzing market research
- Healthcare diagnostics combining medical imaging with patient records
Agentic Workflows and Tool Use
Agentic applications demand reliable tool orchestration, error recovery, and long-horizon planning. Claude Opus 4.5 demonstrates exceptional performance in this domain, achieving 62.3% on MCP Atlas (scaled tool use) compared to Claude Sonnet 4.5's 43.8%.
According to Rakuten's testing, their agents achieved peak performance in just 4 iterations while competing models required 10+ attempts. This rapid convergence reduces development time and computational costs for self-improving agentic systems.
Tool Use Performance:
| Model | τ2-bench (Retail) | τ2-bench (Telecom) | OSWorld (Computer Use) |
|---|---|---|---|
| Claude Opus 4.5 | 88.9% | 98.2% | 66.3% |
| Gemini 3 Pro | 85.3% | 98.0% | Not disclosed |
| GPT-5.1 | Not disclosed | Not disclosed | Not disclosed |
Opus 4.5's 66.3% score on OSWorld represents state-of-the-art computer use capabilities, the ability to operate computers, navigate interfaces, and execute tasks across desktop applications. This enables automation of knowledge work including spreadsheet manipulation, presentation creation, and complex desktop workflows.
Multimodal and Creative Applications
For applications emphasizing visual understanding, video analysis, or creative generation, Gemini 3 Pro's architectural advantages prove decisive. Its unified multimodal transformer processes multiple input types simultaneously, enabling richer context integration.
Google's developer blog highlights exceptional "vibe coding" capabilities where the model transforms natural language descriptions into fully functional, aesthetically pleasing web applications. The model tops the WebDev Arena leaderboard with 1487 Elo, demonstrating superior front-end generation capabilities.
Optimal for:
- Creative tools generating interactive visualizations from descriptions
- Educational platforms creating visual explanations from text
- Media analysis applications processing video, audio, and text simultaneously
- Design systems generating production-ready UI components from sketches
Decision Framework for Model Selection
The artificial intelligence landscape experienced an unprecedented release cycle in late 2025, with three frontier models launching within weeks of each other. Google's Gemini 3 Pro arrived on November 18, followed by Claude Opus 4.5 from Anthropic on November 24, both building upon OpenAI's GPT-5 release from August 7. This rapid succession of releases marks an inflection point in AI capabilities, with each model claiming state-of-the-art performance across critical benchmarks. For AI engineers and product teams building production applications, understanding the nuanced differences between these models is essential for making informed deployment decisions.
This comprehensive analysis examines how Gemini 3 Pro, Claude Opus 4.5, and GPT-5 compare across coding tasks, reasoning capabilities, multimodal understanding, and agentic workflows. We synthesize data from industry-standard benchmarks and real-world testing to provide actionable insights for teams evaluating these models for their AI applications.
Performance Benchmarks: A Detailed Comparison
Coding and Software Engineering
Real-world software engineering capabilities represent one of the most critical differentiators for production AI applications. The SWE-bench Verified benchmark measures a model's ability to resolve actual GitHub issues, testing comprehension, debugging, and integration capabilities simultaneously.
SWE-bench Verified Results:
| Model | SWE-bench Verified | Terminal-Bench 2.0 | Aider Polyglot |
|---|---|---|---|
| Claude Opus 4.5 | 80.9% | 59.3% | Not disclosed |
| Gemini 3 Pro | 76.2% | 54.2% | Not disclosed |
| GPT-5.1 | 76.3% | 47.6% | 88.0% |
| GPT-5 | 74.9% | Not disclosed | 88.0% |
According to Anthropic's official announcement, Claude Opus 4.5 became the first model to break the 80% barrier on SWE-bench Verified, establishing a meaningful performance threshold. The model demonstrates particular strength in terminal-based coding tasks, where it scored 59.3% on Terminal-bench 2.0, significantly outperforming competitors. This advantage translates directly to autonomous coding workflows that require multi-step execution and command-line proficiency.
Google's Gemini 3 Pro shows exceptional performance on algorithmic problem-solving with a LiveCodeBench Pro Elo rating of 2,439, nearly 200 points higher than GPT-5.1's 2,243. This commanding lead indicates superior capability in generating novel, efficient code from scratch. The model also demonstrates strong multimodal code generation, particularly excelling at "vibe coding" where natural language descriptions transform into interactive web applications.
GPT-5 and GPT-5.1 maintain competitive positions, with OpenAI reporting that GPT-5.1 achieves 76.3% on SWE-bench Verified with high reasoning effort. The introduction of adaptive reasoning allows the model to dynamically allocate computational resources, spending more effort on complex problems while responding quickly to simpler queries.
Graduate-Level Reasoning and Scientific Knowledge
The GPQA Diamond benchmark evaluates reasoning capabilities on PhD-level questions across physics, chemistry, and biology, problems that require deep domain expertise and multi-step logical chains.
GPQA Diamond Comparison:
| Model | GPQA Diamond (No Tools) | With Tools/Search |
|---|---|---|
| Gemini 3 Pro | 91.9% | Not disclosed |
| GPT-5 Pro | 88.4% | 89.4% |
| Claude Opus 4.5 | 87.0% | Not disclosed |
| GPT-5 | 85.7% (with thinking) | 88.1% |
Gemini 3 Pro leads significantly on pure reasoning tasks, achieving 91.9% accuracy on GPQA Diamond. Google's model also set a new benchmark on Humanity's Last Exam with 37.5% accuracy without tools, a test designed to push AI systems to their absolute limits. According to TechCrunch's coverage, this represents the highest score on record for this particularly challenging evaluation.
GPT-5 Pro demonstrates strong performance when leveraging tools, scoring 89.4% with Python support. The model's adaptive reasoning capability proves particularly valuable for scientific problems, as thinking mode boosts accuracy from 77.8% to 85.7% on complex queries. This flexibility allows developers to balance performance against latency and cost for different use cases.
Claude Opus 4.5's 87.0% score on GPQA Diamond positions it competitively, though slightly behind the leaders in pure reasoning benchmarks. However, Anthropic emphasizes that Opus 4.5's strength lies in applied reasoning within agentic workflows rather than isolated academic benchmarks.
Mathematical Reasoning
Mathematical capabilities serve as a proxy for logical reasoning and problem-solving precision. The AIME 2025 benchmark tests quantitative reasoning on challenging competition-level problems.
Mathematical Performance:
| Model | AIME 2025 (No Tools) | AIME 2025 (With Code) | MathArena Apex |
|---|---|---|---|
| Gemini 3 Pro | 95.0% | 100% | 23.4% |
| GPT-5 | 94.0% | Not disclosed | 1.0% |
| Claude Opus 4.5 | 87.0% | 100% | 1.6% |
Gemini 3 Pro achieves perfect 100% accuracy on AIME 2025 with code execution tools, matching GPT-5's reported performance. More significantly, its 95.0% accuracy without tools demonstrates robust innate mathematical intuition, making it less dependent on external computational aids. The model's 23.4% score on MathArena Apex (a benchmark featuring extremely challenging contest problems) represents state-of-the-art performance, though the task remains far from solved for any current model.
Multimodal Understanding
Multimodal capabilities enable models to process and reason across text, images, audio, and video, essential for applications ranging from document analysis to visual diagnostics.
Multimodal Benchmarks:
| Model | MMMU-Pro | Video-MMMU | ARC-AGI-2 |
|---|---|---|---|
| Gemini 3 Pro | 81.0% | 87.6% | 31.1% |
| GPT-5.1 | 85.4% (MMMU validation) | Not disclosed | 17.6% |
| Claude Opus 4.5 | Not disclosed | Not disclosed | 37.6% |
Google's Gemini 3 Pro demonstrates exceptional multimodal understanding, leveraging its unified transformer architecture that processes text, images, audio, video, and code within a single stack. This architectural advantage enables genuine cross-modal reasoning, for example, interpreting a sketch and generating working code, or analyzing video content and explaining scientific concepts embedded within.
Claude Opus 4.5 achieves the highest score on ARC-AGI-2 (37.6%), a benchmark specifically designed to test novel problem-solving abilities that cannot be memorized from training data. This visual reasoning puzzle benchmark requires abstract pattern recognition and logical inference, capabilities crucial for computer use and interface navigation tasks.
Use Case Analysis: Selecting the Right Model
Enterprise Coding and Development Workflows
For teams building AI-powered development tools, Claude Opus 4.5 emerges as the clear leader. Its 80.9% accuracy on SWE-bench Verified translates to more reliable code generation, fewer false starts, and better handling of multi-file refactoring tasks. GitHub reported that early testing shows Opus 4.5 "surpasses internal coding benchmarks while cutting token usage in half."
The model's introduction of an effort parameter allows developers to control computational investment per query, balancing performance against latency and cost. At medium effort, Opus 4.5 matches Claude Sonnet 4.5's best SWE-bench score while using 76% fewer output tokens, a significant advantage for high-volume production deployments.
Optimal for:
- Autonomous code review systems requiring high precision
- Multi-agent coding workflows where Opus 4.5 orchestrates multiple Haiku sub-agents
- Long-horizon coding tasks spanning 30+ minutes of autonomous execution
- Production environments where token efficiency directly impacts operational costs
Complex Reasoning and Scientific Applications
Gemini 3 Pro's dominance in reasoning benchmarks makes it the preferred choice for applications requiring deep analytical capabilities. Its 91.9% GPQA Diamond score and 37.5% performance on Humanity's Last Exam demonstrate unmatched capability in tackling novel, complex problems.
The model's 1 million token context window enables processing of extensive research papers, legal documents, or technical specifications without chunking. Google's announcement emphasizes that Gemini 3 Pro "significantly outperforms 2.5 Pro on every major AI benchmark" while maintaining the same underlying characteristics including multimodal inputs across text, images, audio, and video.
Optimal for:
- Scientific research assistants processing large corpus of academic papers
- Legal document analysis requiring synthesis across hundreds of pages
- Strategic business intelligence systems analyzing market research
- Healthcare diagnostics combining medical imaging with patient records
Agentic Workflows and Tool Use
Agentic applications demand reliable tool orchestration, error recovery, and long-horizon planning. Claude Opus 4.5 demonstrates exceptional performance in this domain, achieving 62.3% on MCP Atlas (scaled tool use) compared to Claude Sonnet 4.5's 43.8%.
According to Rakuten's testing, their agents achieved peak performance in just 4 iterations while competing models required 10+ attempts. This rapid convergence reduces development time and computational costs for self-improving agentic systems.
Tool Use Performance:
| Model | τ2-bench (Retail) | τ2-bench (Telecom) | OSWorld (Computer Use) |
|---|---|---|---|
| Claude Opus 4.5 | 88.9% | 98.2% | 66.3% |
| Gemini 3 Pro | 85.3% | 98.0% | Not disclosed |
| GPT-5.1 | Not disclosed | Not disclosed | Not disclosed |
Opus 4.5's 66.3% score on OSWorld represents state-of-the-art computer use capabilities, the ability to operate computers, navigate interfaces, and execute tasks across desktop applications. This enables automation of knowledge work including spreadsheet manipulation, presentation creation, and complex desktop workflows.
Multimodal and Creative Applications
For applications emphasizing visual understanding, video analysis, or creative generation, Gemini 3 Pro's architectural advantages prove decisive. Its unified multimodal transformer processes multiple input types simultaneously, enabling richer context integration.
Google's developer blog highlights exceptional "vibe coding" capabilities where the model transforms natural language descriptions into fully functional, aesthetically pleasing web applications. The model tops the WebDev Arena leaderboard with 1487 Elo, demonstrating superior front-end generation capabilities.
Optimal for:
- Creative tools generating interactive visualizations from descriptions
- Educational platforms creating visual explanations from text
- Media analysis applications processing video, audio, and text simultaneously
- Design systems generating production-ready UI components from sketches
Decision Framework for Model Selection
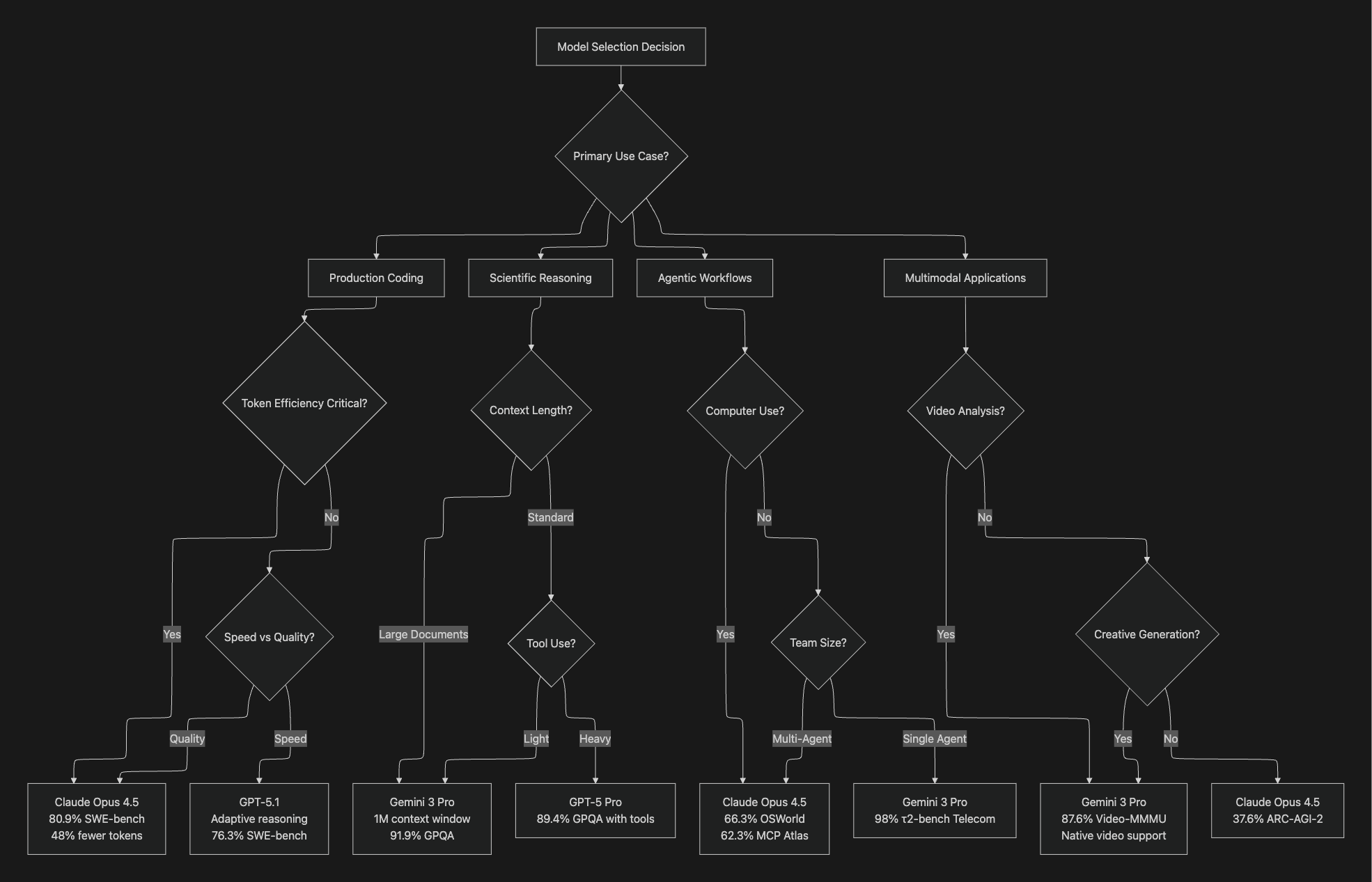
Pricing and Cost Considerations
Cost efficiency remains a critical factor for production deployments. Here's how the models compare on pricing:
API Pricing (per million tokens):
| Model | Input Tokens | Output Tokens | Relative Cost |
|---|---|---|---|
| Claude Opus 4.5 | $5.00 | $25.00 | Baseline |
| Gemini 3 Pro | $2.00 | $12.00 | 60% cheaper |
| GPT-5.1 | $1.25 | $10.00 | 75% cheaper |
While GPT-5.1 offers the lowest per-token cost, actual production costs depend on token efficiency and task completion rates. VentureBeat's analysis notes that Claude Opus 4.5's dramatic token reduction (76% fewer output tokens at medium effort) can make it more cost-effective than nominally cheaper alternatives for complex tasks.
Teams should evaluate total cost of ownership including:
- Average tokens per successful task completion
- Error rates requiring retry attempts
- Human review costs for lower-quality outputs
- Development velocity improvements from better model performance
Evaluating Model Performance for Your Use Case
Benchmark scores provide valuable signal but cannot fully capture real-world performance characteristics. Teams building production AI applications require systematic evaluation frameworks tailored to their specific use cases.
The Importance of Custom Evaluations
Generic benchmarks measure broad capabilities but may not align with your application's success criteria. A model excelling at academic reasoning might struggle with your domain-specific terminology, or a strong general-purpose coder might generate code incompatible with your architectural patterns.
Maxim's evaluation platform enables teams to create custom evaluators that measure what matters for their application. Whether testing factual accuracy, hallucination rates, response coherence, or domain-specific metrics, Maxim's unified framework supports deterministic, statistical, and LLM-as-a-judge evaluation approaches.
Agent Simulation for Complex Workflows
For agentic applications, single-turn evaluations provide insufficient insight into multi-step reasoning and tool orchestration quality. Maxim's agent simulation capabilities allow teams to test AI agents across hundreds of scenarios and user personas, monitoring how the agent responds at every conversational step.
Key simulation features include:
- Conversational-level evaluation assessing complete interaction trajectories
- Task completion verification measuring if goals were successfully achieved
- Failure point identification pinpointing where agent behavior deviates
- Reproduction from any step enabling systematic debugging and improvement
Production Observability
Model selection decisions should be validated against real production data. Maxim's observability suite provides distributed tracing for AI applications, enabling teams to:
- Track quality metrics across production deployments
- Identify regression patterns when switching models
- Correlate user satisfaction with specific model behaviors
- Create feedback loops for continuous improvement
Real-time monitoring with automated quality evaluations ensures production reliability regardless of which frontier model you deploy. Custom rules can trigger alerts when quality metrics drift, enabling rapid response to issues before significant user impact.
Infrastructure Considerations: Bifrost Gateway
Managing multiple model providers introduces operational complexity, different APIs, authentication mechanisms, error handling patterns, and rate limits. Bifrost, Maxim's AI gateway, provides a unified interface to 12+ providers including OpenAI, Anthropic, Google Vertex, and AWS Bedrock.
Key advantages for multi-model deployments:
Automatic Failover and Load Balancing: Route requests across providers based on availability, latency, or custom rules. If one provider experiences downtime, Bifrost automatically fails over to backup models without application code changes.
Semantic Caching: Reduce costs and latency through intelligent response caching based on semantic similarity. Bifrost recognizes when queries are semantically equivalent even with different phrasing, serving cached responses when appropriate.
Unified Observability: Single dashboard for monitoring requests, latency, costs, and error rates across all providers. Bifrost's observability features integrate with Prometheus for metrics and support distributed tracing across your model stack.
Budget Management: Hierarchical cost control with virtual keys, teams, and customer budgets prevents runaway expenses. Track spending by team, project, or customer with fine-grained governance.
Performance Trajectory and Model Evolution

The accelerating release cadence reflects intense competition driving rapid capability improvements. Each model leapfrogs competitors in specific domains while maintaining competitive parity in others. This pattern suggests teams should:
- Build model-agnostic architectures: Design applications to swap models easily, avoiding tight coupling to specific providers
- Maintain systematic evaluation: Track performance across model versions to identify optimal upgrade timing
- Leverage gateway infrastructure: Use tools like Bifrost to abstract provider differences and enable rapid switching
Conclusion: Making Informed Model Selection Decisions
No single frontier model dominates across all dimensions. Claude Opus 4.5 leads in production coding and agentic workflows, Gemini 3 Pro excels at complex reasoning and multimodal understanding, while GPT-5.1 offers strong all-around performance with cost advantages.
Teams should evaluate models against their specific use cases using systematic testing frameworks. Maxim's end-to-end platform provides the evaluation, simulation, and observability tools necessary to make data-driven model selection decisions and maintain production quality as models evolve.
The rapid pace of improvement suggests that model selection strategies should emphasize flexibility and continuous evaluation rather than premature commitment to specific providers. Build infrastructure that enables experimentation, measure what matters for your application, and iterate based on production data.
Ready to systematically evaluate frontier models for your use case? Book a demo to see how Maxim's evaluation and observability platform helps teams ship AI applications 5x faster with confidence.
All benchmark data sourced from official model announcements and third-party evaluation platforms including Anthropic, Google DeepMind, OpenAI, Vals AI, and Vellum. Benchmarks represent performance as of November 2025 and may change with model updates.
Pricing and Cost Considerations
Cost efficiency remains a critical factor for production deployments. Here's how the models compare on pricing:
API Pricing (per million tokens):
| Model | Input Tokens | Output Tokens | Relative Cost |
|---|---|---|---|
| Claude Opus 4.5 | $5.00 | $25.00 | Baseline |
| Gemini 3 Pro | $2.00 | $12.00 | 60% cheaper |
| GPT-5.1 | $1.25 | $10.00 | 75% cheaper |
While GPT-5.1 offers the lowest per-token cost, actual production costs depend on token efficiency and task completion rates. VentureBeat's analysis notes that Claude Opus 4.5's dramatic token reduction (76% fewer output tokens at medium effort) can make it more cost-effective than nominally cheaper alternatives for complex tasks.
Teams should evaluate total cost of ownership including:
- Average tokens per successful task completion
- Error rates requiring retry attempts
- Human review costs for lower-quality outputs
- Development velocity improvements from better model performance
Evaluating Model Performance for Your Use Case
Benchmark scores provide valuable signal but cannot fully capture real-world performance characteristics. Teams building production AI applications require systematic evaluation frameworks tailored to their specific use cases.
The Importance of Custom Evaluations
Generic benchmarks measure broad capabilities but may not align with your application's success criteria. A model excelling at academic reasoning might struggle with your domain-specific terminology, or a strong general-purpose coder might generate code incompatible with your architectural patterns.
Maxim's evaluation platform enables teams to create custom evaluators that measure what matters for their application. Whether testing factual accuracy, hallucination rates, response coherence, or domain-specific metrics, Maxim's unified framework supports deterministic, statistical, and LLM-as-a-judge evaluation approaches.
Agent Simulation for Complex Workflows
For agentic applications, single-turn evaluations provide insufficient insight into multi-step reasoning and tool orchestration quality. Maxim's agent simulation capabilities allow teams to test AI agents across hundreds of scenarios and user personas, monitoring how the agent responds at every conversational step.
Key simulation features include:
- Conversational-level evaluation assessing complete interaction trajectories
- Task completion verification measuring if goals were successfully achieved
- Failure point identification pinpointing where agent behavior deviates
- Reproduction from any step enabling systematic debugging and improvement
Production Observability
Model selection decisions should be validated against real production data. Maxim's observability suite provides distributed tracing for AI applications, enabling teams to:
- Track quality metrics across production deployments
- Identify regression patterns when switching models
- Correlate user satisfaction with specific model behaviors
- Create feedback loops for continuous improvement
Real-time monitoring with automated quality evaluations ensures production reliability regardless of which frontier model you deploy. Custom rules can trigger alerts when quality metrics drift, enabling rapid response to issues before significant user impact.
Infrastructure Considerations: Bifrost Gateway
Managing multiple model providers introduces operational complexity, different APIs, authentication mechanisms, error handling patterns, and rate limits. Bifrost, Maxim's AI gateway, provides a unified interface to 12+ providers including OpenAI, Anthropic, Google Vertex, and AWS Bedrock.
Key advantages for multi-model deployments:
Automatic Failover and Load Balancing: Route requests across providers based on availability, latency, or custom rules. If one provider experiences downtime, Bifrost automatically fails over to backup models without application code changes.
Semantic Caching: Reduce costs and latency through intelligent response caching based on semantic similarity. Bifrost recognizes when queries are semantically equivalent even with different phrasing, serving cached responses when appropriate.
Unified Observability: Single dashboard for monitoring requests, latency, costs, and error rates across all providers. Bifrost's observability features integrate with Prometheus for metrics and support distributed tracing across your model stack.
Budget Management: Hierarchical cost control with virtual keys, teams, and customer budgets prevents runaway expenses. Track spending by team, project, or customer with fine-grained governance.
Performance Trajectory and Model Evolution
graph LR
A[GPT-4o<br/>Mar 2024] --> B[Claude Sonnet 3.5<br/>Jun 2024]
B --> C[Gemini 2.5 Pro<br/>Feb 2025]
C --> D[Claude 4 Series<br/>May 2025]
D --> E[GPT-5<br/>Aug 2025]
E --> F[Claude Sonnet 4.5<br/>Sep 2025]
F --> G[Claude Haiku 4.5<br/>Oct 2025]
G --> H[GPT-5.1<br/>Nov 2025]
H --> I[Gemini 3 Pro<br/>Nov 2025]
I --> J[Claude Opus 4.5<br/>Nov 2025]
style E fill:#90EE90
style I fill:#87CEEB
style J fill:#FFB6C1
The accelerating release cadence reflects intense competition driving rapid capability improvements. Each model leapfrogs competitors in specific domains while maintaining competitive parity in others. This pattern suggests teams should:
- Build model-agnostic architectures: Design applications to swap models easily, avoiding tight coupling to specific providers
- Maintain systematic evaluation: Track performance across model versions to identify optimal upgrade timing
- Leverage gateway infrastructure: Use tools like Bifrost to abstract provider differences and enable rapid switching
Conclusion: Making Informed Model Selection Decisions
No single frontier model dominates across all dimensions. Claude Opus 4.5 leads in production coding and agentic workflows, Gemini 3 Pro excels at complex reasoning and multimodal understanding, while GPT-5.1 offers strong all-around performance with cost advantages.
Teams should evaluate models against their specific use cases using systematic testing frameworks. Maxim's end-to-end platform provides the evaluation, simulation, and observability tools necessary to make data-driven model selection decisions and maintain production quality as models evolve.
The rapid pace of improvement suggests that model selection strategies should emphasize flexibility and continuous evaluation rather than premature commitment to specific providers. Build infrastructure that enables experimentation, measure what matters for your application, and iterate based on production data.
Ready to systematically evaluate frontier models for your use case? Book a demo to see how Maxim's evaluation and observability platform helps teams ship AI applications 5x faster with confidence.
All benchmark data sourced from official model announcements and third-party evaluation platforms including Anthropic, Google DeepMind, OpenAI, Vals AI, and Vellum. Benchmarks represent performance as of November 2025 and may change with model updates.


