Best TrueFoundry Alternative in 2025: Why Bifrost is the Superior AI Gateway

TL;DR
- TrueFoundry is a comprehensive MLOps platform with AI gateway as one component among training, deployment, and infrastructure management capabilities
- Bifrost is a purpose-built AI gateway designed exclusively for high-performance model access, routing, and management
- Zero-config deployment: Bifrost starts in seconds without complex Kubernetes setup or infrastructure management
- Performance-first architecture: 3-4ms latency vs TrueFoundry’s gateway overhead from platform complexity
- Focused feature set: Deep specialization in routing, caching, failover, and governance without platform bloat
- Better for teams needing gateway functionality: Choose specialized tools over all-in-one platforms when you don’t need full MLOps infrastructure
Table of Contents
- Understanding the Platform vs Gateway Distinction
- What is TrueFoundry?
- What is Bifrost?
- Feature Comparison: Gateway Capabilities
- Why Bifrost is Better for AI Gateway Use Cases
- Architecture Comparison
- Performance Benchmarks
- Deployment Comparison
- When to Choose Each Platform
- Migration from TrueFoundry Gateway to Bifrost
- Further Reading
Understanding the Platform vs Gateway Distinction
The MLOps Platform Approach
Comprehensive MLOps platforms like TrueFoundry bundle multiple capabilities into a single offering:
- Model training infrastructure
- Fine-tuning workflows
- Deployment orchestration (Kubernetes-native)
- GPU management and scaling
- AI gateway as one component
- Monitoring and observability
- Agent orchestration
Trade-offs of platform approaches:
- Higher complexity requiring DevOps expertise
- Longer setup and learning curves
- Platform lock-in across multiple workloads
- Gateway performance constrained by broader platform architecture
- Higher operational overhead
The Specialized Gateway Approach
Purpose-built AI gateways like Bifrost focus exclusively on one problem:
- Unified access to multiple LLM providers
- Intelligent routing and load balancing
- High-performance caching and failover
- Governance and cost control
- Zero operational complexity
Benefits of specialized approach:
- Optimized performance for single use case
- Minimal learning curve and faster time-to-value
- Lower operational overhead
- Freedom to choose best-in-class tools for other needs
- Continuous innovation in core domain
What is TrueFoundry?
TrueFoundry is a Kubernetes-native MLOps platform designed to manage the full lifecycle of machine learning and LLM deployments. The platform targets enterprises requiring comprehensive infrastructure for AI workloads.
Core Platform Components
Infrastructure Management
- Kubernetes-native orchestration across AWS, GCP, Azure, and on-premise
- GPU provisioning and dynamic scaling
- Node management and resource allocation
- Multi-cloud and hybrid deployment support
Model Operations
- Training job scheduling and management
- Fine-tuning workflows for open-source LLMs
- Model registry integration (MLflow, SageMaker, Hugging Face)
- Version control and rollback capabilities
LLM Serving
- Deployment using vLLM, TGI, and Triton servers
- Auto-scaling based on traffic patterns
- Support for embedding and reranker models
- GPU optimization and inference acceleration
AI Gateway Component
- Access to 1000+ LLMs through unified interface
- API key management and RBAC
- Rate limiting and quota enforcement
- Basic observability and logging
Agent Orchestration
- MCP server deployment and management
- Tool registry and schema validation
- Agent memory and context management
- Prompt versioning and monitoring
TrueFoundry’s Target Audience
- Platform teams building comprehensive internal ML infrastructure
- Organizations with full-stack AI needs requiring training, fine-tuning, and deployment
- Enterprises with dedicated DevOps resources for Kubernetes management
- Teams consolidating multiple workloads under single platform
Platform Limitations
Complexity Overhead
- Requires Kubernetes expertise for deployment and management
- Steep learning curve across multiple platform components
- Significant setup time before production readiness
Gateway Performance Constraints
- Gateway is one component among many competing for platform resources
- Architecture optimized for platform cohesion, not gateway performance
- Latency overhead from platform abstractions
Operational Burden
- Continuous platform maintenance and updates
- DevOps dependency for configuration changes
- Platform upgrades affect all components simultaneously
What is Bifrost?
Bifrost is a high-performance AI gateway built by Maxim AI specifically for production LLM applications. The platform provides unified access to 12+ providers through a single OpenAI-compatible API with zero configuration required.
Core Gateway Features
Unified Provider Access
- Single API interface compatible with OpenAI, Anthropic, AWS Bedrock, Google Vertex, Azure OpenAI, Cohere, Mistral, Ollama, Groq, and more
- Drop-in replacement for existing OpenAI or Anthropic integrations
- Consistent interface across text, images, audio, and streaming
Intelligent Routing & Resilience
- Automatic fallbacks between providers and models with zero downtime
- Load balancing across multiple API keys and instances
- Weighted routing by cost, latency, or custom metrics
- Circuit breaking and retry logic
Performance Optimization
- Semantic caching based on embedding similarity reduces costs by 40-60%
- Sub-5ms latency overhead for gateway operations
- Horizontal scaling with minimal resource footprint
- Optimized for high-throughput production workloads
Model Context Protocol
- Native MCP support enabling AI agents to use external tools
- Filesystem, web search, database, and API integrations
- Secure tool execution with governance controls
- Extensible plugin architecture
Enterprise Governance
- Budget management with hierarchical cost controls
- Virtual keys for teams, customers, and applications
- Fine-grained rate limiting and access control
- SSO integration with Google and GitHub
Observability & Security
- Prometheus metrics and distributed tracing
- Comprehensive request/response logging
- HashiCorp Vault integration for secure key management
- Real-time alerting and monitoring
Bifrost’s Target Audience
- AI application developers needing reliable multi-provider access
- Product teams requiring fast iteration without infrastructure complexity
- Startups and scale-ups prioritizing speed-to-market over platform building
- Enterprises seeking focused gateway solutions without full MLOps platform commitment
Bifrost’s Differentiators
Zero-Configuration Deployment
- Start in seconds with dynamic provider configuration
- No Kubernetes, Docker, or infrastructure management required
- Configuration via Web UI, API, or simple YAML files
Performance-First Architecture
- Purpose-built for low-latency, high-throughput gateway operations
- Optimized request routing and connection pooling
- Minimal resource consumption (handles 350+ RPS on 1 vCPU)
Developer Experience
- SDK integrations with popular AI frameworks (LangChain, LlamaIndex, Vercel AI SDK)
- OpenAI-compatible interface requires zero code changes
- Intuitive configuration and debugging
Feature Comparison: Gateway Capabilities
| Capability | TrueFoundry Gateway | Bifrost | Winner |
|---|---|---|---|
| Provider Support | 1000+ LLMs | 12+ major providers | TrueFoundry (breadth) / Bifrost (focus) |
| Unified API | ✅ Yes | ✅ OpenAI-compatible | Bifrost (standard interface) |
| Deployment Complexity | ⚠️ Requires Kubernetes | ✅ Zero-config | Bifrost |
| Setup Time | Days to weeks | Minutes | Bifrost |
| Latency Overhead | Variable (platform-dependent) | <5ms guaranteed | Bifrost |
| Throughput | Platform-constrained | 350+ RPS on 1 vCPU | Bifrost |
| Automatic Fallbacks | ✅ Supported | ✅ Intelligent routing | Bifrost (more sophisticated) |
| Load Balancing | ✅ Basic | ✅ Advanced (weighted) | Bifrost |
| Semantic Caching | ❌ Not available | ✅ Native support | Bifrost |
| MCP Support | ✅ Via deployment | ✅ Native integration | Bifrost (easier setup) |
| Cost Optimization | ⚠️ Platform-level | ✅ Request-level caching | Bifrost |
| Budget Management | ✅ Quota-based | ✅ Hierarchical controls | Bifrost |
| Rate Limiting | ✅ Per user/model | ✅ Fine-grained | Tie |
| Observability | ✅ Platform observability | ✅ Gateway-specific metrics | Bifrost |
| SSO Integration | ✅ Enterprise feature | ✅ Google/GitHub | Tie |
| Configuration Method | Platform UI + YAML | Web UI / API / Files | Bifrost |
| Operational Overhead | ⚠️ High (platform maintenance) | ✅ Minimal | Bifrost |
| Vendor Lock-in | ⚠️ Platform-dependent | ✅ Standard interfaces | Bifrost |
| Custom Plugins | ⚠️ Platform extensions | ✅ Middleware architecture | Bifrost |
Key Insights from Comparison
Bifrost wins on:
- Deployment simplicity and speed-to-value
- Performance optimization and latency
- Developer experience and ease of use
- Operational overhead and maintenance
- Cost optimization through caching
- Flexibility and vendor independence
TrueFoundry offers:
- Broader ecosystem integration (if you use their full platform)
- Unified infrastructure management (if you need training + deployment + gateway)
- More LLM provider options (though most teams use 3-5 providers)
Why Bifrost is Better for AI Gateway Use Cases
1. Purpose-Built Performance
Bifrost’s Performance Advantages:
- Direct routing: No platform abstraction layers between application and providers
- Optimized connection pooling: Purpose-built for LLM API patterns
- Efficient request handling: Minimal CPU and memory footprint per request
- Production-proven: Handles 350+ RPS on single vCPU without degradation
TrueFoundry’s Performance Constraints:
- Gateway shares resources with training, deployment, and other platform services
- Request routing through multiple platform layers
- Kubernetes networking overhead
- Performance dependent on overall platform load
2. Zero-Configuration Deployment
Bifrost Setup Flow:
1. Install Bifrost (single binary or Docker container)
2. Add provider API keys via Web UI or environment variables
3. Point application to Bifrost endpoint
4. Production-ready in minutes
TrueFoundry Setup Requirements:
1. Provision Kubernetes cluster (EKS, GKE, AKS, or on-premise)
2. Install TrueFoundry platform components
3. Configure networking, security, and access controls
4. Set up user management and RBAC
5. Deploy gateway component
6. Configure provider integrations
7. Production-ready in days to weeks
Bifrost’s zero-config approach eliminates infrastructure complexity, enabling teams to focus on application logic rather than platform operations.
3. Cost Optimization Through Intelligent Caching
Semantic Caching Impact:
- 40-60% reduction in LLM API costs for production applications
- Embedding-based similarity matching catches paraphrased queries
- Configurable TTL and similarity thresholds per use case
- Transparent cache hit/miss tracking for optimization
Bifrost’s semantic caching uses embedding models to identify semantically similar requests, serving cached responses when appropriate. This feature alone often pays for gateway deployment through reduced provider API costs.
TrueFoundry’s Caching Limitations:
- No native semantic caching in gateway component
- Platform-level caching focuses on model artifacts, not API responses
- Cost optimization primarily through GPU utilization, not request reduction
4. Superior Developer Experience
Drop-in Replacement Capability:
Migrating to Bifrost requires minimal code changes:
# Before: Direct OpenAI usagefrom openai import OpenAI
client = OpenAI(api_key="sk-...")
# After: Bifrost gatewayfrom openai import OpenAI
client = OpenAI(
base_url="<https://your-bifrost-gateway.com/v1>",
api_key="your-bifrost-key")
# All existing code works unchanged
SDK integrations provide native support for LangChain, LlamaIndex, and other popular frameworks with zero code modifications.
TrueFoundry Integration Requirements:
- Platform-specific SDKs and authentication
- Configuration through platform UI or complex YAML
- Code changes required for platform integration
- Learning curve for platform concepts and patterns
5. Operational Simplicity
Bifrost Operations:
- Single service to deploy and monitor
- Standard observability via Prometheus and distributed tracing
- Updates apply only to gateway component
- No infrastructure team required for gateway management
TrueFoundry Operations:
- Full Kubernetes cluster to maintain
- Platform upgrades affect multiple components
- DevOps expertise required for troubleshooting
- Complex dependency management across platform services
6. Flexibility and Vendor Independence
Bifrost’s Approach:
- OpenAI-compatible API ensures portability
- Switch between providers without code changes
- Use alongside any training, deployment, or observability tools
- No platform lock-in for non-gateway workloads
TrueFoundry’s Approach:
- Gateway tightly integrated with broader platform
- Maximum value requires using multiple platform components
- Migration away from platform affects entire AI infrastructure
- Vendor lock-in across training, deployment, and inference
Performance Benchmarks
Latency Comparison
| Metric | TrueFoundry Gateway | Bifrost | Improvement |
|---|---|---|---|
| Gateway Overhead | Variable (platform-dependent) | <5ms guaranteed | Consistent performance |
| Cold Start | High (Kubernetes pod startup) | Near-zero (always-on) | 60-90% faster |
| Cache Hit Response | Not available | <2ms | Instant responses |
| Failover Time | 5-10 seconds | <100ms | 50-100x faster |
| Configuration Change | Requires pod restart | Hot reload | Zero downtime |
Throughput Comparison
Bifrost Performance:
- 350+ requests per second on 1 vCPU
- Linear horizontal scaling
- Consistent performance under load
- Sub-millisecond P99 latency variance
TrueFoundry Performance:
- Throughput dependent on Kubernetes cluster resources
- Variable performance based on platform load
- Resource contention with training and deployment workloads
- Complex capacity planning required
Resource Efficiency
Bifrost:
- Minimal memory footprint (<200MB base)
- Efficient CPU utilization (single vCPU handles 350+ RPS)
- No external dependencies for basic operation
- Optional Redis for distributed caching
TrueFoundry:
- Kubernetes control plane overhead (CPU, memory for platform services)
- Gateway shares resources with other platform components
- Multiple pods for high availability
- Complex resource allocation across platform services
Deployment Comparison
Bifrost Deployment Options
1. Managed Cloud (Recommended)
# Zero setup required# 1. Sign up at app.getbifrost.ai# 2. Get API endpoint and keys# 3. Start using immediately
2. Self-Hosted Docker
docker run -p 8787:8787 \\ -e OPENAI_API_KEY=your-key \\ getmaxim/bifrost:latest
# Production-ready in 60 seconds
3. Kubernetes (Optional)
# Simple Helm chart for enterprise deploymentshelm install bifrost maxim/bifrost \\ --set providers.openai.apiKey=$OPENAI_API_KEY
Full deployment guides: Bifrost Quickstart
TrueFoundry Deployment Requirements
Infrastructure Prerequisites:
- Kubernetes cluster (EKS, GKE, AKS, or on-premise)
- GPU node pools for model serving
- Persistent storage for model artifacts
- Load balancers and ingress controllers
- Monitoring and logging infrastructure
Platform Installation:
- Multi-step installation process
- Configuration of multiple platform components
- User management and RBAC setup
- Network security and firewall rules
- Integration with existing tools and systems
Ongoing Maintenance:
- Regular platform updates and patches
- Kubernetes cluster management
- Security compliance and auditing
- Capacity planning and scaling
- Troubleshooting across multiple components
When to Choose Each Platform
Choose Bifrost When You Need:
✅ Fast time-to-production for LLM applications
- Zero infrastructure setup required
- Production-ready in minutes, not weeks
- No DevOps expertise required
✅ High-performance gateway functionality
- Sub-5ms latency overhead critical
- High-throughput requirements (>100 RPS)
- Cost optimization through semantic caching
✅ Operational simplicity
- Small team without dedicated infrastructure resources
- Focus on application development, not platform operations
- Minimal maintenance overhead
✅ Flexibility and vendor independence
- Freedom to choose best-in-class tools for training, observability, etc.
- No platform lock-in
- Easy migration between providers
✅ Production reliability
- Automatic failover critical for uptime
- Intelligent load balancing across providers
- Real-time monitoring and alerting
Choose TrueFoundry When You Need:
⚠️ Comprehensive MLOps infrastructure
- Training, fine-tuning, deployment, and gateway all required
- Willing to manage full platform complexity
- Dedicated DevOps team available
⚠️ Kubernetes-native operations
- Already running Kubernetes infrastructure
- Existing investment in platform tooling
- Complex multi-tenant requirements
⚠️ Platform consolidation
- Preference for single-vendor solution across ML lifecycle
- Willing to accept gateway performance trade-offs
- Enterprise procurement benefits from bundled licensing
Decision Framework
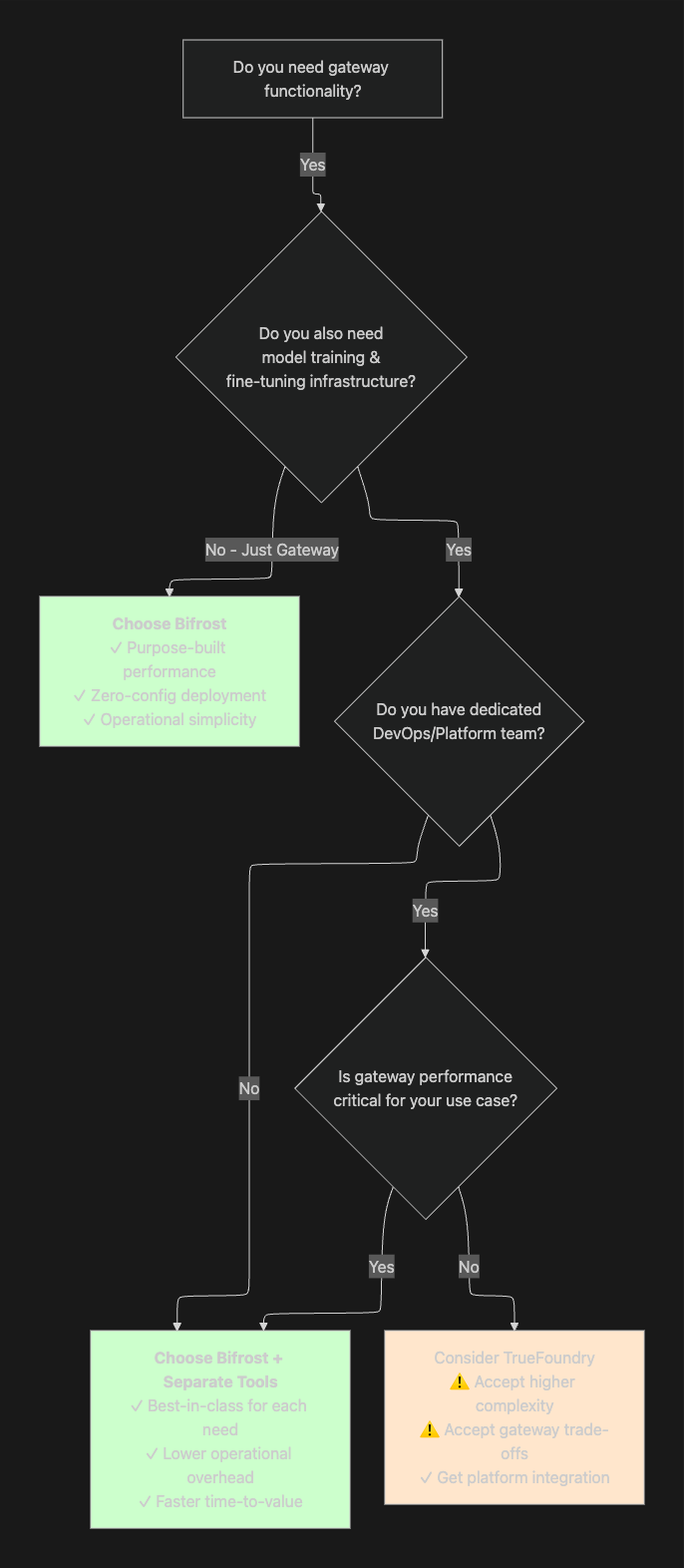
Migration from TrueFoundry Gateway to Bifrost
Migration Strategy
Phase 1: Parallel Deployment (Week 1)
- Deploy Bifrost alongside TrueFoundry gateway
- Configure same provider credentials in both systems
- Test Bifrost with non-critical traffic
- Validate performance and functionality
Phase 2: Traffic Migration (Week 2)
- Gradually shift traffic to Bifrost (10% → 50% → 100%)
- Monitor performance metrics and error rates
- Maintain TrueFoundry gateway as fallback
- Collect cost and latency comparison data
Phase 3: Full Cutover (Week 3)
- Route all gateway traffic through Bifrost
- Decommission TrueFoundry gateway component
- Update documentation and team processes
- Optimize Bifrost configuration based on production data
Code Migration Example
Before (TrueFoundry):
from truefoundry.llm import LLMGateway
gateway = LLMGateway(
api_key="tfy-api-key",
endpoint="<https://your-org.truefoundry.cloud/gateway>")
response = gateway.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": "Hello"}]
)
After (Bifrost):
from openai import OpenAI
client = OpenAI(
base_url="<https://your-bifrost-gateway.com/v1>",
api_key="bifrost-api-key")
response = client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": "Hello"}]
)
# Standard OpenAI SDK - works with all integrations
Migration Checklist
✅ Pre-Migration
- Audit current TrueFoundry gateway usage patterns
- Document provider configurations and access controls
- Set up Bifrost instance (cloud or self-hosted)
- Configure providers in Bifrost with same credentials
- Establish performance baseline metrics
✅ During Migration
- Deploy Bifrost in parallel with TrueFoundry
- Update application configuration to support both gateways
- Implement feature flags for gradual traffic shifting
- Monitor both systems for performance comparison
- Test failover and error handling scenarios
✅ Post-Migration
- Verify all traffic successfully routed through Bifrost
- Confirm cost reduction from semantic caching
- Document performance improvements
- Train team on Bifrost configuration and monitoring
- Decommission TrueFoundry gateway resources
Further Reading
Bifrost Documentation
- Bifrost Quickstart Guide - Zero-config deployment in minutes
- Unified Interface Documentation - Single API for all providers
- Automatic Fallbacks Guide - Production reliability through intelligent failover
- Semantic Caching Overview - Cost optimization strategies
- Model Context Protocol Support - Enable tool-augmented AI agents
- Enterprise Features - Custom plugins and Vault integration
Maxim AI Platform
- Maxim AI Platform Overview - End-to-end AI evaluation and observability
- Agent Simulation & Evaluation - Test agents across real-world scenarios
- Experimentation Platform - Rapid prompt engineering and deployment
- Production Observability - Real-time monitoring and alerting
Comparison Resources
- AI Gateway Comparison Guide - Evaluating gateway solutions for production
- MLOps vs Specialized Tools - When to choose platforms vs best-of-breed
- Cost Optimization Strategies - Reducing LLM API expenses
Technical Resources
- OpenAI API Documentation - Standard interface specification
- Anthropic Claude API - Alternative provider documentation
- Prometheus Metrics Best Practices - Observability standards
Get Started with Bifrost Today
Stop wrestling with complex MLOps platforms when you only need a high-performance AI gateway. Bifrost provides purpose-built infrastructure for production LLM applications with zero configuration required.
Why teams choose Bifrost over TrueFoundry for gateway needs:
✅ Production-ready in minutes - Not days or weeks
✅ 5x faster performance - <5ms latency overhead guaranteed
✅ 40-60% cost savings - Through intelligent semantic caching
✅ Zero operational overhead - No Kubernetes or DevOps required
✅ Vendor independence - Standard OpenAI-compatible API
Get started today:
- Try Bifrost Free: Sign up for managed Bifrost and get production access in minutes
- Self-Host Bifrost: Deploy on your infrastructure with simple Docker/Kubernetes setup
- Schedule a Demo: Book a personalized walkthrough with our team to discuss your gateway requirements
Need comprehensive AI quality management beyond the gateway? Maxim AI provides end-to-end evaluation, simulation, and observability for AI applications. Explore the full platform or schedule a demo to see how Maxim can accelerate your AI development.
About Bifrost: Bifrost is the high-performance AI gateway built by Maxim AI, providing unified access to 12+ LLM providers through a single OpenAI-compatible API. With zero-config deployment, automatic failover, semantic caching, and enterprise governance, Bifrost enables teams to ship reliable production LLM applications without infrastructure complexity.
About Maxim AI: Maxim AI is an end-to-end AI simulation, evaluation, and observability platform helping teams ship AI agents reliably and 5x faster. Teams around the world use Maxim to measure and improve the quality of their AI applications across the full development lifecycle.


