Best Practices for Prompt Management in AI Applications

In the rapidly advancing field of artificial intelligence, the quality of an AI application's output is fundamentally tied to the quality of its inputs. These inputs, known as prompts, are the instructions that guide large language models (LLMs) to produce desired results. As organizations move AI applications from experimental stages to production, managing these prompts effectively has become a critical discipline for engineering and product teams. It is a cornerstone of the broader practice of LLMOps (Large Language Model Operations).
Systematic prompt management is no longer optional; it is essential for building reliable, scalable, and secure AI systems. Ad-hoc approaches to handling prompts create significant technical debt, leading to inconsistent performance, security vulnerabilities, and major difficulties in tracking the impact of changes. This guide outlines the best practices for prompt management, covering the entire lifecycle from creation and versioning to evaluation and in-production monitoring.
What is Prompt Management and Why is it Critical?
Prompt management is the systematic process of creating, storing, testing, deploying, and monitoring the prompts used in AI applications. It treats prompts not as simple text strings but as crucial software artifacts that require the same rigor and discipline as application code.
The need for a structured approach becomes clear when teams face common challenges:
- Inconsistent Performance: Minor, untracked changes to a prompt can cause major regressions in AI quality.
- Lack of Reproducibility: Without versioning, it becomes nearly impossible to debug issues or understand why an application's behavior has changed.
- Security Risks: Poorly managed prompts can expose applications to vulnerabilities like prompt injection attacks.
- Collaboration Friction: When engineers, product managers, and domain experts lack a central place to work on prompts, workflows become slow and inefficient.
By adopting a formal management strategy, teams can mitigate these risks, accelerate development cycles, and deliver consistently high-quality AI experiences.
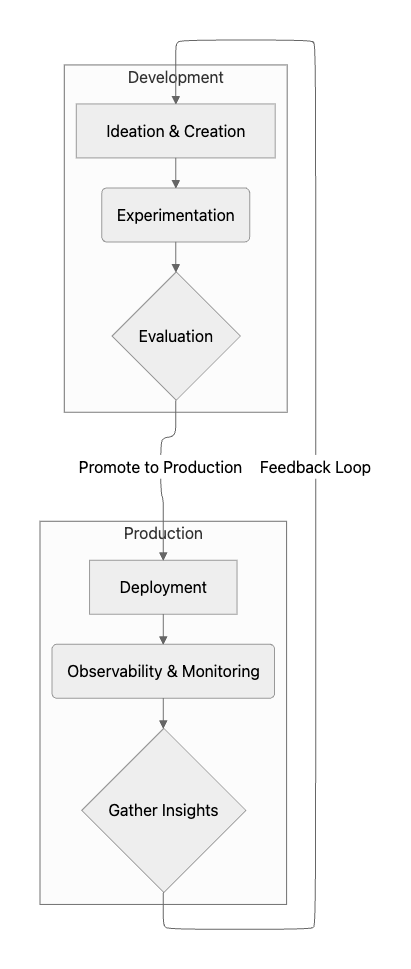
The Prompt Lifecycle: A Disciplined Approach
Treating prompts as critical software artifacts demands a rigorous, disciplined lifecycle management process. This lifecycle includes several key stages: ideation, experimentation, evaluation, deployment, and ongoing observability. A structured approach ensures quality, reproducibility, and effective collaboration between diverse teams.
This lifecycle can be visualized as a continuous feedback loop, where insights from production monitoring inform the next round of experimentation and improvement.
1. Version Control: Treat Prompts as Code
The foundational best practice for prompt management is to treat prompts as code. This means storing them in a version control system like Git. Just as source code is versioned to track its evolution, prompts must be versioned to enable rollbacks, facilitate collaboration, and maintain a clear audit trail.
This practice is a core tenet of the "Everything as Code" philosophy, which brings software development best practices to all components of a system. Storing prompts in a centralized prompt registry or repository, decoupled from the application code, allows for independent iteration and updates without requiring a full application redeployment.
Key benefits of versioning prompts:
- Reproducibility: Easily revert to a previous, better-performing version if a new iteration degrades performance.
- Collaboration: Allows multiple team members, including engineers and product managers, to work on prompts concurrently without conflicts.
- Audit Trail: Provides a clear history of who changed what, when, and why, which is crucial for debugging and governance.
- Experimentation: Safely test new prompt variations in separate branches without affecting the main production prompts.
2. Systematic Evaluation and Testing
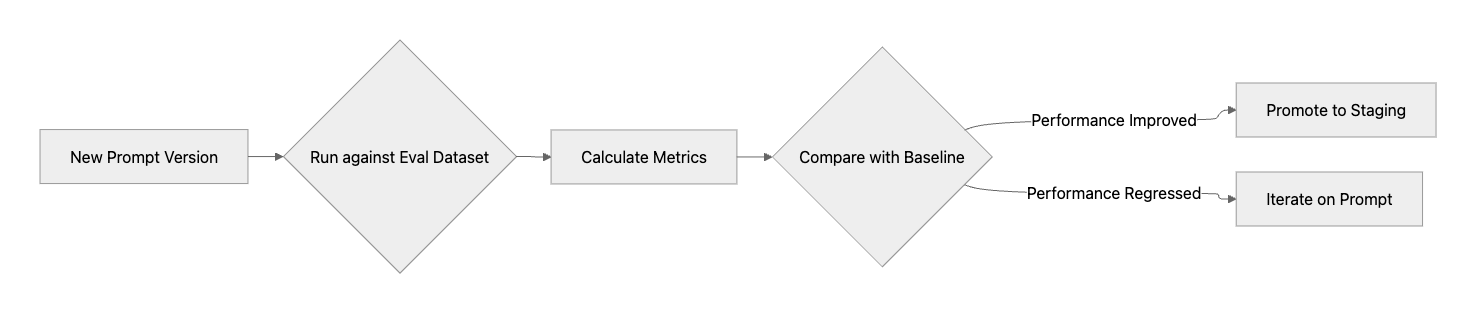
Intuition and one-off manual checks are insufficient for validating prompt effectiveness at scale. A systematic evaluation framework is necessary to quantitatively measure improvements and regressions. This involves testing prompts against standardized datasets and predefined metrics.
Core components of a robust evaluation strategy:
- Define Success Metrics: Establish clear, objective metrics to measure prompt quality. These can include accuracy, relevance, helpfulness, clarity, latency, and cost (token usage).
- Create Evaluation Datasets: Curate high-quality datasets that represent real-world scenarios and critical edge cases to test prompt performance comprehensively.
- Automate Testing: Implement automated workflows to run new prompt versions against evaluation datasets and calculate performance metrics. This creates a tight feedback loop, allowing teams to see the impact of their changes quickly.
This automated process ensures that every change is validated against a consistent benchmark before it reaches production.
Maxim AI’s evaluation framework provides a unified solution for both machine and human evaluations, offering a store of pre-built evaluators and the flexibility to create custom ones.
However, for complex AI agents, testing individual prompts is often not enough. It is crucial to test how they perform in multi-turn conversations and across various user scenarios. Maxim AI's simulation capabilities allow teams to simulate customer interactions across hundreds of scenarios and user personas, evaluating the agent's performance at a conversational level to identify points of failure.
3. Foster Cross-Functional Collaboration
Effective prompt engineering is rarely a solo effort. It requires a deep partnership between AI engineers, who understand the technical nuances of the models, and product managers or domain experts, who provide the essential business context. A successful prompt management strategy must facilitate this collaboration.
Platforms that offer a shared workspace where both technical and non-technical stakeholders can contribute are invaluable. The ideal tool allows engineers to manage prompts programmatically through an SDK while enabling product teams to review, edit, and experiment through an intuitive user interface. This breaks down silos and ensures that prompts are aligned with both technical constraints and business goals.
At Maxim AI, we've anchored our user experience to foster seamless collaboration. Features like Flexi Evals, which can be configured from the UI without code, and Custom Dashboards empower product teams to gain deep insights without creating a dependency on engineering.
4. Experimentation and Optimization
The process of finding the optimal prompt is highly iterative. Teams need tools that support rapid experimentation with different models, parameters, prompt phrasing, and prompt templates. Prompt templates are reusable prompt structures with placeholders for dynamic data, which helps standardize inputs and improve consistency.
A dedicated environment for prompt engineering, often called a "playground," is essential. This environment should allow users to:
- Compare the outputs, cost, and latency of different prompt versions side by side.
- Organize and version prompts for continuous improvement.
- Seamlessly connect to various data sources and LLM providers.
- Test and refine prompt templates with different variables.
Maxim AI’s advanced experimentation environment, Playground++, is designed for this purpose. It enables teams to organize, version, and deploy prompts using different strategies without code changes, simplifying the decision-making process for optimizing AI agents.
5. Observability and In-Production Monitoring
The job is not done once a prompt is deployed. Continuous monitoring of prompt performance in a live environment is crucial for ensuring reliability and detecting issues like performance degradation or model drift. Model drift occurs when the statistical properties of the production data change over time, causing a previously accurate model to become less effective.
LLM observability involves tracking metrics, logs, and traces to gain real-time insights into how AI applications are behaving. Key areas to monitor include:
- Output Quality: Are the responses accurate, helpful, and free of hallucinations?
- Latency and Cost: Are response times and token consumption within acceptable limits?
- User Interactions: How are users interacting with the AI, and are there patterns in failed or unexpected interactions?
Maxim AI’s Observability suite empowers teams to monitor real-time production logs, run periodic quality checks, and receive alerts on issues with minimal user impact.
A critical feedback loop involves curating datasets from production data to continuously refine and improve prompts. Maxim AI’s Data Engine facilitates this by allowing teams to easily curate multimodal datasets from production logs and human feedback for further evaluation and fine-tuning.
6. Security and Governance
As AI applications become more integrated with sensitive data and critical business processes, prompt security becomes paramount. A prompt injection attack, for example, occurs when a malicious user crafts an input that tricks the LLM into ignoring its original instructions and executing the user's harmful commands instead. This can lead to data leakage, unauthorized actions, or other damaging outcomes.
Best practices for prompt security include:
- Input Sanitization: Filter and validate user inputs to remove or neutralize potentially harmful instructions before they reach the model.
- Access Controls: Implement role-based access controls to restrict who can create or modify prompts, especially those that interact with sensitive systems.
- Output Filtering: Monitor and filter the AI's output to ensure it does not contain inappropriate or sensitive information.
- Regular Testing: Conduct red-teaming exercises to proactively identify and patch vulnerabilities in your prompts and models.
Governance also involves maintaining clear documentation and metadata for each prompt, such as its purpose, owner, and version history, to ensure accountability and clarity.
Common Prompt Management Pitfalls to Avoid
Even with the best intentions, teams can fall into common traps. Avoiding these pitfalls is as important as adopting best practices.
- Hard-Coding Prompts: Embedding prompts directly in application code makes them difficult to update, track, and manage. Always externalize them into a registry or CMS.
- Working in Silos: When engineers build prompts without input from product or domain experts, the results often miss the mark on business requirements.
- Neglecting Evaluation Datasets: Relying solely on manual "spot checks" provides a false sense of security. A comprehensive evaluation dataset is non-negotiable for quality assurance.
- Forgetting About Monitoring: A prompt that performs well today may degrade tomorrow. Without production monitoring, these issues go unnoticed until they impact users.
Conclusion
Prompt management has evolved from an ad-hoc practice into a systematic engineering discipline crucial for the success of enterprise AI applications. By treating prompts as versioned code, implementing rigorous evaluation and testing, fostering cross-functional collaboration, and maintaining robust observability in production, teams can build more reliable, efficient, and secure AI agents.
Platforms like Maxim AI provide an end-to-end solution that covers the entire AI lifecycle, from experimentation and simulation to evaluation and observability. By integrating these best practices into a unified platform, Maxim AI helps teams accelerate development, improve AI quality, and ship reliable AI applications with confidence.