Best 5 platforms to evaluate LLM-powered applications

TL;DR
Shipping reliable LLM applications requires systematic evaluation beyond manual testing. Maxim AI provides end-to-end evaluation with simulation, node-level metrics, and production feedback loops. Langfuse offers open-source evaluation with prompt management. LangSmith delivers LangChain-native testing with datasets. TruLens specializes in feedback-driven improvement. Deepchecks brings MLOps validation to LLM workflows.
Effective evaluation combines automated quality metrics, human feedback integration, regression testing, and continuous validation from development through production.
Table of Contents
- Why LLM Evaluation Differs
- Evaluation Workflow
- Best Evaluation Platforms1. Maxim AI2. Langfuse3. LangSmith4. TruLens5. Deepchecks
- Platform Comparison
- Implementation Strategy
Why LLM Evaluation Differs
Traditional software testing validates deterministic behavior with clear pass/fail criteria. LLM evaluation requires assessing subjective quality, handling probabilistic outputs, and measuring nuanced attributes like helpfulness, harmlessness, and honesty.
No Ground Truth: Unlike unit tests with expected outputs, LLM responses vary legitimately. Multiple correct answers exist for most prompts. Evaluation must distinguish between acceptable variation and actual quality degradation.
Context-Dependent Quality: The same response quality varies by use case. A concise answer suits customer support while technical documentation needs depth. Evaluation frameworks must adapt metrics to application requirements.
Multi-Dimensional Assessment: Quality encompasses accuracy, relevance, coherence, safety, cost, and latency. Optimizing one dimension often degrades others. Comprehensive evaluation tracks trade-offs across metrics.
According to Microsoft's research, successful LLM evaluation combines automated metrics, human judgment, and continuous production validation.
Evaluation Workflow
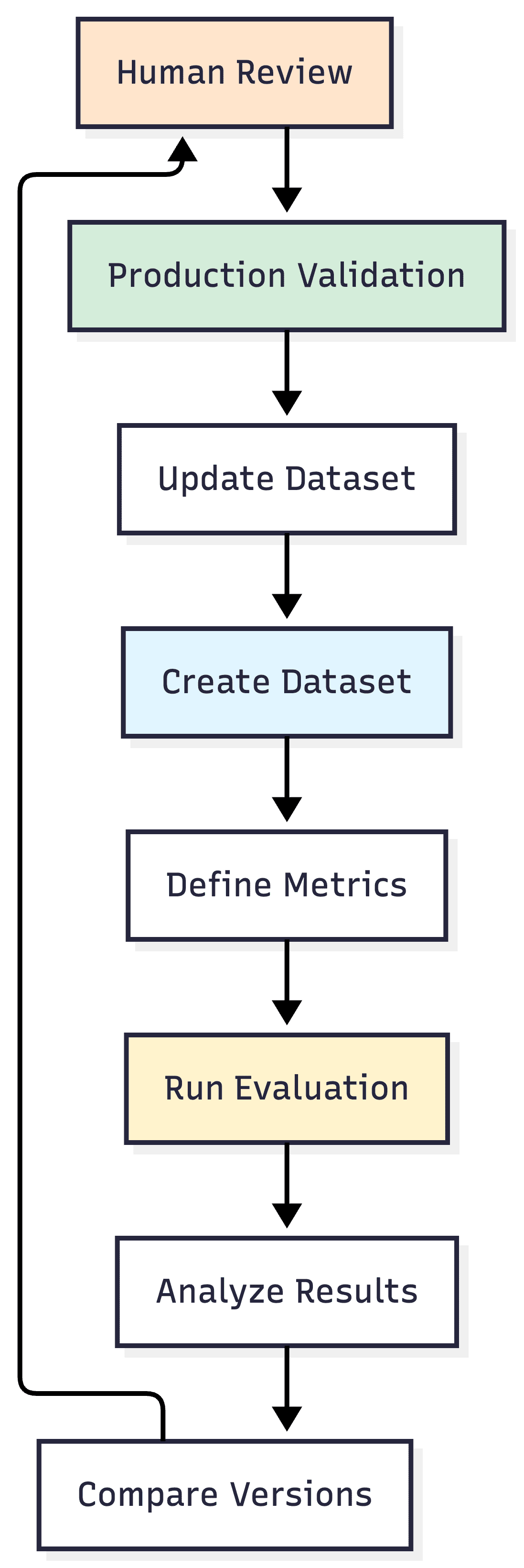
Best Evaluation Platforms
1. Maxim AI
Maxim AI provides comprehensive evaluation infrastructure built for the entire LLM application lifecycle from development through production.
Simulation and Evaluation: Simulation capabilities enable testing complex workflows before deployment. Create synthetic datasets covering edge cases, run evaluations at scale, and validate behavior across scenarios. Pre-deployment testing catches issues before users encounter them.
Node-Level Metrics: Unlike black-box evaluation, Maxim enables attaching metrics to specific nodes in LLM workflows. Evaluate retrieval quality separately from generation, assess individual agent decisions, and isolate failure points. This granularity proves essential for complex agentic systems.
Production Feedback Loops: Automatically curate production data into evaluation datasets. Agent observability captures failures with full context, human reviewers enrich with correct outputs, and expanded datasets prevent regression. This closes the loop between production monitoring and systematic improvement.
Custom and Pre-Built Evaluators: Configure evaluators for accuracy, relevance, coherence, safety, and custom metrics. Use LLM-as-judge scorers or integrate domain-specific validators. Experimentation platform enables A/B testing prompts and comparing model versions.
Cost-Aware Testing: Track token consumption and API costs during evaluation. Identify expensive workflows before production deployment. Bifrost gateway adds semantic caching reducing evaluation costs while maintaining coverage.
Collaborative Workflows: Product and engineering teams collaborate on evaluation criteria. Non-technical stakeholders define quality standards while engineers implement automated testing. This alignment ensures evaluation measures what matters to users.
Best For: Teams building complex LLM applications, organizations requiring end-to-end evaluation, companies needing tight integration between development and production quality.
Compare Maxim vs LangSmith | Compare Maxim vs Langfuse
2. Langfuse
Langfuse provides open-source evaluation capabilities with flexible deployment and comprehensive prompt management.
Prompt Management: Version control for prompts with evaluation tracking across versions. Test prompt variations systematically, compare performance metrics, and roll back problematic changes. Deployment happens without code changes, accelerating iteration.
Evaluation Framework: Run custom evaluators on datasets with support for multiple scoring approaches. Track evaluation metrics over time to identify quality drift. Integration with production traces enables evaluating real user interactions.
Dataset Creation: Build evaluation datasets from production traces or create synthetic examples. Organize test cases by use case, user segment, or failure mode. Maintain golden datasets for regression testing.
Human-in-the-Loop: Collect human feedback on LLM outputs with annotation workflows. Use feedback to improve prompts and validate automated metrics. Human judgment grounds automated evaluation in actual user needs.
Deployment Flexibility: Self-host via Docker or Kubernetes for complete data control. Alternatively, use managed cloud for simplified operations. Open-source codebase enables customization for specific requirements.
Best For: Teams prioritizing open-source tooling, organizations requiring self-hosting for compliance, development teams comfortable managing infrastructure.
3. LangSmith
LangSmith provides evaluation infrastructure purpose-built for LangChain applications with native integration.
Dataset Management: Create evaluation datasets from production traces or synthetic examples. Organize test cases by scenario, complexity, or expected behavior. Track dataset versions alongside prompt changes.
Evaluation Playground: Test prompts interactively before committing to evaluation runs. Iterate rapidly on prompt engineering with immediate feedback. Compare multiple approaches side-by-side in unified interface.
Automated Evaluators: Configure LLM-as-judge scorers for quality assessment. Use pre-built evaluators for common patterns or create custom validators. Run evaluations automatically on every prompt change.
Production Integration: Collect user feedback tied directly to traces. One-click creation of test cases from production failures ensures evaluation catches real issues. Continuous feedback improves evaluation datasets over time.
Regression Testing: Maintain baseline performance across prompt updates. Compare new versions against established benchmarks. Prevent quality degradation when shipping improvements.
Best For: LangChain-exclusive teams, organizations wanting framework-native evaluation, development teams prioritizing minimal setup friction.
4. TruLens
TruLens specializes in feedback-driven LLM evaluation with transparent quality assessment.
Feedback Functions: Define custom feedback functions evaluating specific quality dimensions. Assess groundedness, answer relevance, context relevance, and custom criteria. Modular design enables composing complex evaluation logic.
RAG Triad: Specialized evaluation for retrieval-augmented generation measuring context relevance (retrieval quality), groundedness (generation faithfulness), and answer relevance (end-to-end quality). This RAG-specific approach proves essential for knowledge-intensive applications.
Model Versioning: Track multiple model versions with comparative evaluation. Understand how updates affect quality across different dimensions. Make informed decisions about model selection and configuration.
Transparent Scoring: Unlike black-box metrics, TruLens provides explainable quality scores. Understand why responses receive specific ratings. Use transparency for debugging and improvement.
Open-Source Foundation: Self-host for complete control. Customize feedback functions for domain-specific requirements. Community-driven development with extensive documentation.
Best For: Teams requiring explainable evaluation, RAG applications needing specialized metrics, organizations prioritizing open-source flexibility.
5. Deepchecks
Deepchecks brings MLOps validation methodologies to LLM evaluation with comprehensive quality checks.
LLM Validation Suite: Pre-built checks for common LLM issues including hallucination detection, toxicity assessment, PII exposure, and prompt injection vulnerabilities. Comprehensive validation catches issues automated metrics miss.
Data Quality: Validate training data and evaluation datasets for quality, diversity, and bias. Identify dataset issues before they affect model performance. Ensure evaluation datasets represent production distributions.
Model Comparison: Compare different models, prompts, or configurations across standardized metrics. Make data-driven decisions about model selection. Track performance trends over time.
Continuous Validation: Integrate checks into CI/CD pipelines. Automatically validate every prompt change or model update. Prevent deploying degraded quality to production.
Enterprise Features: On-premises deployment for data security. SOC 2 compliance for regulated industries. Role-based access control for team collaboration.
Best For: Enterprises requiring compliance and security, teams with established MLOps workflows, organizations prioritizing systematic validation.
Platform Comparison
| Feature | Maxim | Langfuse | LangSmith | TruLens | Deepchecks |
|---|---|---|---|---|---|
| Primary Focus | End-to-end lifecycle | Open-source eval | LangChain eval | Feedback-driven | MLOps validation |
| Node-Level Metrics | Native | Limited | Chain-level | Limited | N/A |
| Production Integration | Automated curation | Manual | One-click cases | Limited | CI/CD |
| Custom Evaluators | Extensive | Flexible | LLM-as-judge | Feedback functions | Pre-built checks |
| RAG Evaluation | Comprehensive | Standard | Standard | RAG Triad | Standard |
| Deployment | Cloud | Self-host/Cloud | Cloud | Self-host | Self-host/Cloud |
| Cost Tracking | Granular + caching | Standard | Per-request | N/A | N/A |
| Human-in-Loop | Integrated | Annotation | Feedback | Limited | Manual |
| Best For | Complex applications | Open-source priority | LangChain users | RAG systems | Enterprise MLOps |
Implementation Strategy
Phase 1: Define Quality Criteria - Establish what quality means for your application. Identify critical dimensions (accuracy, relevance, safety), define acceptable performance ranges, and align stakeholders on evaluation standards. Product requirements should drive technical metrics.
Phase 2: Build Evaluation Datasets - Create comprehensive test sets covering common cases, edge cases, adversarial inputs, and known failure modes. Start with 50-100 examples and expand based on production learnings. Reference Maxim's evaluation guide for dataset creation best practices.
Phase 3: Configure Automated Metrics - Set up evaluators for each quality dimension. Combine automated metrics (exact match, semantic similarity, cost, latency) with LLM-as-judge scorers for subjective quality. Validate automated metrics against human judgment initially.
Phase 4: Establish Baselines - Run evaluation on current production configuration. Document baseline performance across all metrics. Baselines enable detecting regression when making changes.
Phase 5: Integrate into Development - Add evaluation to development workflow. Test every prompt change before deployment. Compare new versions against baselines. Only ship improvements validated by evaluation.
Phase 6: Production Feedback Loop - Capture production failures automatically. Enrich with correct outputs through human review. Add to evaluation datasets regularly. This ensures evaluation catches real issues, not just synthetic ones.
Phase 7: Continuous Improvement - Review evaluation results weekly. Identify systematic failures requiring prompt updates or architecture changes. Track quality trends over time. Reference Maxim's AI reliability framework for systematic improvement.
Key Resources: Agent Evaluation Tools | RAG Evaluation Tools | AI Quality Evaluation | Evaluation Metrics | LLM Observability | Maxim vs Arize | Comm100 Case Study | Thoughtful Case Study
Conclusion
The five platforms represent different evaluation approaches. Maxim provides end-to-end lifecycle evaluation with production feedback loops. Langfuse offers open-source flexibility with prompt management. LangSmith delivers LangChain-native testing. TruLens specializes in transparent feedback-driven assessment. Deepchecks brings MLOps validation rigor.
Maxim's comprehensive solution combines simulation, node-level metrics, and automated production data curation, enabling teams to evaluate systematically from development through production while continuously improving evaluation datasets based on real failures.
Ready to implement systematic LLM evaluation? Book a demo with Maxim to see how end-to-end evaluation and production feedback loops improve application quality.


