Agent Observability: The Definitive Guide to Monitoring, Evaluating, and Perfecting Production-Grade AI Agents

Agent observability goes far beyond traditional logging or APM. It gives teams full visibility into AI agents by capturing traces, metrics, prompts, tool calls, model outputs, evaluator scores, and human feedback in real time – so you can debug failure modes, monitor quality, prevent drift, and continuously improve agents in production. This guide breaks down the five pillars of agent observability, explains why OpenTelemetry matters, shows how Maxim AI implements end-to-end tracing and evaluation, and provides a practical blueprint for moving from “black-box agents” to reliable, measurable, and enterprise-grade systems.
Agent observability is the practice of monitoring, analyzing, and understanding the internal state and behavior of AI agents in real time.
It is a technical discipline focused on making the actions, decisions, and internal processes of AI agents transparent and measurable. In the context of LLM-powered agents or multi-agent systems, observability means you can track what agents are doing, why they’re making certain decisions, and how they’re interacting with their environment or other agents.
In this deep dive you will learn:
- What makes agent observability fundamentally different from classic APM or data observability.
- The five technical pillars every monitoring stack must cover.
- An implementation blueprint anchored in open standards such as OpenTelemetry and powered by Maxim AI’s Agent Observability offering.
- The key metrics, SLAs, and evaluation workflows that separate hobby projects from enterprise-ready agents.
- Real-world case studies showing how organizations cut cost, reduced hallucinations, and shipped faster with Maxim AI.
By the end, you will walk away with a verifiable, step-by-step playbook to bring deterministic rigor to even the most autonomous AI systems.
1. Why “Just Log Everything” Fails for AI Agents
Logs and metrics have served us well for two decades of cloud-native software. But agents are different on three dimensions:
- Non-Determinism — The same prompt can yield different outputs depending on temperature, context length, and upstream vector store state.
- Long-Running Multi-Step Workflows — Agents call other agents, external tools, and LLMs, resulting in deeply nested and branching traces.
- Evaluation Ambiguity — A 200 HTTP code or low CPU usage says nothing about semantic quality. Did the agent actually answer the user’s question? Was it factually correct? Bias-free?
Relying solely on infrastructure metrics hides these failure modes until an angry user, compliance team, or front-page headline uncovers them. Enter full-fidelity agent observability, where content, context, and computation are captured in real time, evaluated through automated and optionally human review, and incorporated into ongoing quality workflows.
2. The Five Pillars of Agent Observability
Observability for AI agents spans traditional telemetry but adds two AI-specific layers. Think of it as a hierarchy of needs:
- Pillar 1: Traces
Capture every step, prompt, tool call, model invocation, retry, across distributed components. Rich traces let engineers replay a session and pinpoint where reasoning went off the rails. - Pillar 2: Metrics
Monitor latency, token usage, cost, and throughput at session, span, and model granularity. Tie these to SLAs (e.g., P95 end-to-end latency below 2 s or cost per call <$0.002). - Pillar 3: Logs & Payloads
Persist the raw prompts, completions, and intermediate tool responses. Tokenize sensitive data, but never throw away the what and why behind an agent’s action. - Pillar 4: Online Evaluations
Run automated evaluators in real time, including faithfulness, safety, PII leakage, and other model-quality checks. Compare against dynamic thresholds and trigger alerts when quality degrades. - Pillar 5: Human Review Loops
Incorporate SMEs who label or adjudicate outputs flagged as risky. Their feedback trains custom evaluators and closes the last-mile validation gap.
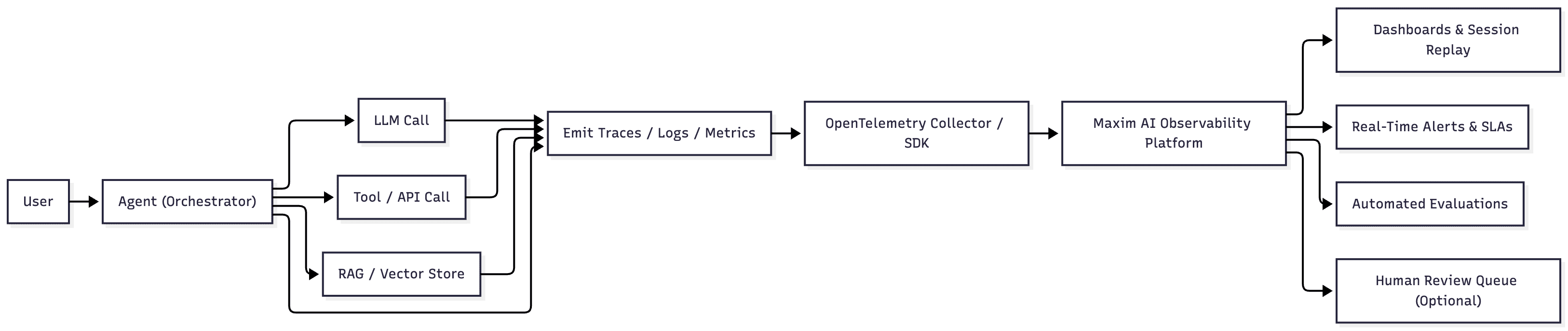
Maxim’s Agent Observability product supports all five pillars through its tracing, evaluation, logging, and review components. Explore the full spec here: https://www.getmaxim.ai/products/agent-observability.
3. Why Open Standards Matter: Building on OpenTelemetry
The observability community learned the hard way that proprietary instrumentation silos data and hinders innovation. OpenTelemetry (OTel) solves this for microservices, and in 2024 he specification introduced semantic conventions for LLM workloads, enabling consistent representation of model-related spans. Adopting OTel delivers three benefits:
- Interoperability — Stream traces to any backend - Be it Maxim, New Relic, or even your own ClickHouse cluster—without rewriting code.
- No Vendor Lock-In — Future-proof your stack as new tracing backends emerge.
- Cross-Team Language — A standard schema lets SREs, data scientists, and compliance teams speak in shared telemetry primitives.
Maxim’s SDKs are fully OTel-compatible and stateless, letting you relay existing traces into Maxim while forwarding the same stream to Grafana or New Relic.
4. Inside Maxim AI’s Agent Observability Stack
Let us peel back the curtain on the core architecture, mapped to the earlier five pillars:
| Capability | How Maxim Delivers | Reference |
|---|---|---|
| Comprehensive Tracing | Lightweight SDKs instrument OpenAI, Anthropic, LangGraph, Crew AI, and custom tool calls. Maxim’s SDKs support rich span payloads that can include prompts, responses, tool calls, and metadata. | Agent Observability |
| Visual Trace View | A hierarchical timeline shows each delegate step, prompt, model parameters, and response. Collapsible branches keep 50-step chains navigable. | Maxim Docs |
| Online Evaluations | Built-in evaluators include faithfulness, style, PII detection, and other quality checks, with support for custom evaluators. Custom evaluators can be surfaced via REST. | AI Agent Quality Evaluation |
| Human Annotation Queues | Flexible queues route flagged outputs to internal SMEs or outsourced reviewers. Annotators see conversation context without raw PII. | Evaluation Workflows for AI Agents |
| Real-Time Alerts | Define thresholds on latency, cost, or evaluator scores. Alerts pipe into Slack, PagerDuty, or webhooks for autonomous mitigation. | Docs: Alerts |
| Enterprise Deployment | SOC 2 Type 2, in-VPC deployment, role-based access controls, and SSO integrations meet strict governance demands. | Trust Center |
Because every trace includes model, version, hyper-parameters, and embeddings context, root-cause analysis collapses from hours to minutes.
5. Implementation Blueprint: From Zero to Production Observability
Step 1: Instrument the Agent Orchestrator
Add the Maxim OTel SDK to your agent runtime (LangGraph, Crew AI, or custom Python). Each LLM invocation and tool call automatically emits a span with:
span.name = "llm.call"attributes.maxim.prompt_template_idattributes.llm.temperatureattributes.llm.provider = "gpt-4o-mini"
Most implementations require adding a lightweight wrapper around your model or tool-calling layer to emit OTel-compliant spans.
Step 2: Capture Non-LLM Context
Instrument vector store queries, retrieval latency, and external API calls. Doing so surfaces whether hallucinations stem from RAG retrieval failures versus model issues.
Step 3: Configure Online Evaluators
Start with default Maxim evaluators, faithfulness and safety. For domain-specific checks (HIPAA, FINRA), upload custom evaluators using Maxim’s evaluation framework, including LLM-based or programmatic checks. Tie passing thresholds to a service-level objective (e.g., Faithfulness ≥ 0.92, rolling window 1 h).
Step 4: Wire Up Alerting and Dashboards
Route evaluator.score < 0.85 alerts to a dedicated #agent-quality Slack channel. Set cost alerts on aggregate usage (tokens × price) to catch runaway loops early.
Step 5: Close the Loop with Human Review
Create a queue for high-impact sessions, VIP users, regulatory entities, or extreme outliers, so SMEs can annotate intent satisfaction, factuality, and sentiment. Their labels retrain evaluators via Maxim’s fine-tuning APIs.
Full documentation and quick-start snippets live here: https://www.getmaxim.ai/docs/introduction/overview#3-observability.
6. Key Metrics That Matter
Traditional APM focuses on CPU, memory, and duration. Agent observability expands the lens:
| Category | Metric | Why It Matters |
|---|---|---|
| Latency | End-to-end (P50/P95), step-level | Users abandon chats after 3-5 s; dissect if bottleneck sits in RAG retrieval, model inference, or downstream API. |
| Cost | Tokens, model fees, external API spend | Cloud-LLM costs compound at scale; early drift can blow through monthly budgets in hours. |
| Quality | Faithfulness, answer relevance, completeness | Directly predicts user trust and retention. |
| Safety | Toxicity, bias, PII leakage | Compliance teams require auditable evidence. |
| Engagement | User rating, follow-up rate, conversation length | Indicates whether the agent resolves issues or generates churn. |
Maxim surfaces every metric at session, span, and agent-version granularity, enabling rapid A/B or multi-armed bandit experiments.
7. Benchmarking Maxim Against DIY and Legacy Approaches
| Requirement | DIY Build | Legacy APM | Maxim AI |
|---|---|---|---|
| LLM-Aware Tracing | Partial (custom code) | No | ✅ |
| Rich Span Payloads: | Complex storage ops | No | ✅ |
| Real-Time Quality Evaluators | Manual cron jobs | No | ✅ |
| Human-in-the-Loop Queues | Ad-hoc spreadsheets | No | ✅ |
| SOC 2 + In-VPC | Depends on team | Varies | ✅ |
While open-source toolkits (e.g., LlamaIndex + Prometheus) provide building blocks, stitching them together often eclipses the cost of a managed platform.
8. Future Trends: Autonomous Evaluation and Self-Healing Agents
The next evolution in observability merges monitoring with autonomous remediation:
- Self-Healing Agents — When evaluators detect a failure pattern, a meta-agent rewrites prompts, selects a safer model, or rolls back to a known-good version automatically.
- Contextualized Traces — Linking agent telemetry to business KPIs (cart conversion, CSAT) will let product managers experiment with prompts just like growth teams A/B test UI copy.
- Synthetic Shadow Traffic — Simulate conversations with new agent versions using historical contexts before migrating live traffic, similar to canary releases in DevOps.
Maxim already supports agent simulation and evaluation modules (https://www.getmaxim.ai/products/agent-simulation) so teams can rehearse in staging before shipping to production.
9. Maxim Observability Benefits:
- Real-time Monitoring: Track all resume analysis sessions
- Performance Insights: Monitor tool execution times and success rates
- Error Tracking: Identify and debug analysis failures
- Usage Analytics: Understand patterns in resume submissions
- Quality Assurance: Ensure consistent analysis quality
10. Getting Started Today
- Sign up for a free Maxim workspace, no credit card required: https://getmaxim.ai.
- Schedule a live demo with Maxim Here.
Further Reading
- Prompt Management in 2025: https://www.getmaxim.ai/articles/prompt-management-in-2025-how-to-organize-test-and-optimize-your-ai-prompts/
- Agent Evaluation vs. Model Evaluation: https://www.getmaxim.ai/articles/agent-evaluation-vs-model-evaluation-whats-the-difference-and-why-it-matters/
- LLM Observability 101: https://www.getmaxim.ai/articles/llm-observability-how-to-monitor-large-language-models-in-production/


