A Comprehensive Guide to Ensuring Reliable Performance in AI Agents

As AI agents transition from experimental prototypes to mission-critical enterprise applications, ensuring their reliability has become a strategic imperative. Recent benchmark testing shows that systematic evaluation frameworks can achieve 95% error detection and 86% error localization accuracy, demonstrating that reliable AI agents are not just aspirational, they're achievable with the right approach.
Yet building production-ready AI agents remains challenging. If each LLM call in a flight-booking agent has just a 2% failure rate, the overall system becomes completely unusable. This guide explores the frameworks, methodologies, and platform capabilities that enable teams to build AI agents that perform reliably at scale.
Understanding AI Agent Reliability
AI agent reliability encompasses multiple dimensions beyond traditional software quality metrics. Enterprise applications bring additional requirements including secure access to data and systems, a high degree of reliability for audit and compliance purposes, and complex interaction patterns.
Unlike deterministic software systems, AI agents operate in environments where identical inputs can produce different but equally valid outputs. This non-deterministic nature requires new approaches to testing, monitoring, and quality assurance that go beyond conventional software engineering practices.
Core Challenges in AI Agent Reliability
The Compound Error Problem
Research on improving reliability might have many new applications even if underlying language models don't improve, because agents need to make dozens of LLM calls where errors can compound. Each decision point in an agent's workflow represents a potential failure mode that can cascade through the entire system.
Evaluation Complexity
Agent behavior often differs between testing and production environments due to real user interaction patterns and external service dependencies. Traditional testing approaches that expect deterministic outputs fail for agent systems because identical inputs can produce different but equally valid results.
Observability Gaps
Continuous monitoring is essential for tracking agent actions, decisions, and interactions in real time to surface anomalies, unexpected behaviors, or performance drift. Without comprehensive observability, organizations struggle to troubleshoot complex AI workflows, scale reliably, or maintain the transparency necessary for stakeholder trust.
The AI Agent Reliability Lifecycle
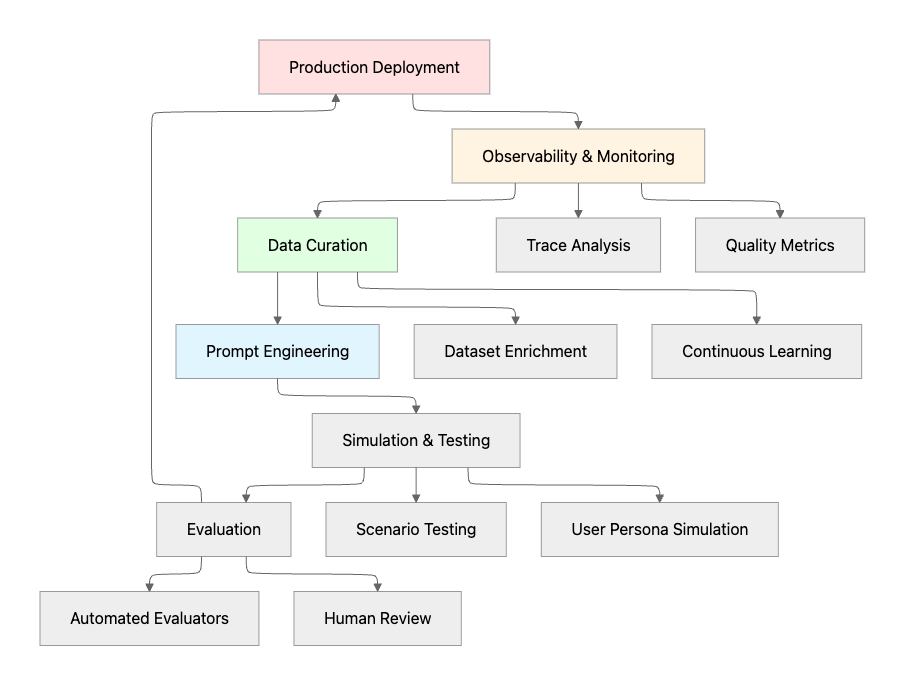
Four Pillars of Reliable AI Agents
1. Comprehensive Testing and Simulation
Test suites for AI agents must evaluate performance across multiple valid solution paths rather than expecting deterministic outputs. Effective testing strategies include:
Scenario-Based Testing: Develop test suites that assess outcome quality, measuring whether agents achieve objectives regardless of their specific approach. This requires creating diverse test scenarios that mirror real-world complexity and user variability.
Adversarial Testing: Deploy adversarial testing that exposes agent vulnerabilities through edge cases and unexpected inputs that reveal weaknesses in prompt engineering or model training. Red teaming exercises help identify failure modes before they impact production users.
User Persona Simulation: Testing must account for the full spectrum of user behaviors and interaction patterns. Agent simulation enables teams to test agents across hundreds of scenarios and user personas before deployment.
2. Robust Evaluation Frameworks
Evaluation objectives organize prior work by what to evaluate, such as behavior, capabilities, reliability, and safety, alongside evaluation processes including interaction modes, datasets, benchmarks, and metrics computation methods.
Multi-Level Evaluation: Effective evaluation requires assessing agents at multiple levels:
- Session-level: Analyze complete conversational trajectories and task completion rates
- Trace-level: Examine reasoning paths and tool usage patterns
- Span-level: Evaluate individual LLM calls and responses
Hybrid Evaluation Approaches: Microsoft Azure research identifies evaluations as a critical component that distinguishes agent observability from traditional monitoring. Combining automated evaluators with human-in-the-loop review ensures both scale and nuance.
Maxim's evaluation framework provides off-the-shelf evaluators and custom evaluation creation, enabling teams to measure quality quantitatively using AI, programmatic, or statistical evaluators while conducting human evaluations for nuanced assessments.
3. Production Observability and Monitoring
Given the non-deterministic nature of AI agents, telemetry is used as a feedback loop to continuously learn from and improve agent quality by using it as input for evaluation tools.
Essential Monitoring Metrics:
- Latency Tracking: Measure latency for tasks and individual steps by tracing agent runs, as long waiting times negatively impact user experience
- Token Usage and Cost: Since AI providers charge by token usage, tracking this metric directly impacts costs and enables optimization opportunities
- Model Drift Detection: Monitor key metrics of model drift such as changes in response patterns or variations in output quality to detect issues early
- Tool Performance: Track tool selection patterns to verify agents are choosing appropriate tools, measure tool execution latency and success rates, and identify frequently failing tools
Distributed Tracing: End-to-end tracing visualizes the complete execution path from initial prompt to final action, helping identify bottlenecks and errors. This visibility is essential for debugging complex multi-agent workflows.
Maxim's observability suite empowers teams to monitor real-time production logs with distributed tracing, automated evaluations, and real-time alerting to track quality, cost, latency, and user satisfaction continuously.
4. Strategic Prompt Management
Tiny changes in prompts—an extra line of context, a clarified constraint, a reordered instruction—often produce outsized gains in accuracy and reliability.
Version Control for Prompts: Maintain clear versions of prompts and agent workflows using semantic versioning, environment separation, and diff viewers to track token-level differences between versions.
Iterative Refinement: Prompt engineering is an iterative process requiring context awareness, specificity, and continuous testing to refine instructions based on performance.
A/B Testing at Scale: By systematically comparing different prompt versions, teams can identify the most effective configurations for their LLMs and agents in real-world scenarios.
Maxim's Experimentation platform enables rapid prompt engineering iteration, allowing teams to organize and version prompts, deploy with different variables, and compare quality across model combinations.
Building Reliable AI Agents with Maxim AI
Maxim AI provides an end-to-end platform that addresses every stage of the AI agent reliability lifecycle:
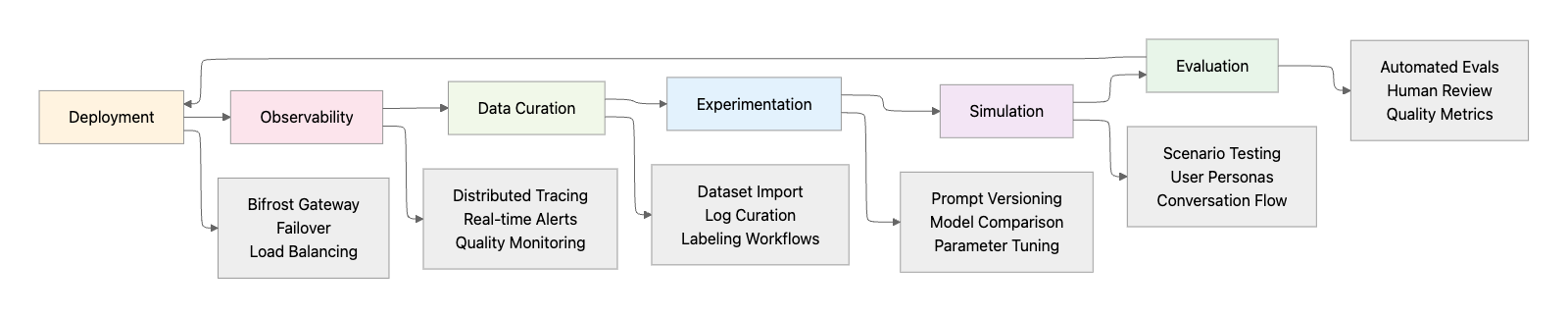
Pre-Production: Experimentation and Simulation
Advanced Prompt Engineering: Maxim's Playground++ is built for rapid iteration and experimentation. Teams can:
- Organize and version prompts directly from the UI for iterative improvement
- Deploy prompts with different deployment variables and experimentation strategies without code changes
- Compare output quality, cost, and latency across various combinations of prompts, models, and parameters
AI-Powered Simulation: Use agent simulation to:
- Simulate customer interactions across real-world scenarios and user personas
- Monitor how agents respond at every step of the conversation
- Re-run simulations from any step to reproduce issues and identify root causes
Evaluation and Quality Assurance
Maxim's unified framework for machine and human evaluations allows teams to:
- Access off-the-shelf evaluators or create custom evaluators suited to specific needs
- Measure quality quantitatively using AI, programmatic, or statistical evaluators
- Visualize evaluation runs on large test suites across multiple prompt versions
- Define and conduct human evaluations for last-mile quality checks
Production Deployment with Bifrost
Bifrost, Maxim's high-performance AI gateway, ensures reliable production deployment:
- Unified Interface: Single OpenAI-compatible API for 12+ providers (OpenAI, Anthropic, AWS Bedrock, Google Vertex, and more)
- Automatic Fallbacks: Seamless failover between providers and models with zero downtime
- Semantic Caching: Intelligent response caching based on semantic similarity to reduce costs and latency
- Load Balancing: Intelligent request distribution across multiple API keys and providers
Production Observability
Maxim's observability capabilities enable teams to:
- Track, debug, and resolve live quality issues with real-time alerts
- Create multiple repositories for production data with distributed tracing
- Measure in-production quality using automated evaluations based on custom rules
- Curate datasets with ease for evaluation and fine-tuning needs
Continuous Improvement through Data Curation
Maxim's Data Engine enables seamless data management:
- Import multi-modal datasets, including images, with a few clicks
- Continuously curate and evolve datasets from production data
- Enrich data using in-house or Maxim-managed data labeling
- Create data splits for targeted evaluations and experiments
Best Practices for Enterprise Deployment
Start with Observability from Day One
AWS guidance emphasizes starting observability from day one rather than treating it as a separate concern added after development. Implementing comprehensive tracing before production deployment prevents blind spots that make debugging nearly impossible at scale.
Adopt Standardized Instrumentation
The GenAI observability project within OpenTelemetry is developing semantic conventions for AI agent telemetry to ensure consistent monitoring across different implementations. Using OpenTelemetry-based solutions provides standardization for tracing and logging.
Implement Gradual Rollouts
Deploy agents to progressively larger user populations while monitoring reliability metrics to catch issues before they affect your entire user base. Canary deployments and staged rollouts minimize risk during production launches.
Create Continuous Feedback Loops
Observability data is the foundation of an iterative development process where production insights from online evaluation inform offline experimentation and refinement. This creates a virtuous cycle where real-world performance continuously improves agent capabilities.
Establish Governance Frameworks
Track safety metrics including policy violations and guardrail activations to ensure agents uphold standards of quality and safety. Enterprise deployments require robust governance to maintain compliance and trust.
Conclusion
Building reliable AI agents requires a systematic approach that spans the entire development lifecycle, from initial experimentation through production monitoring and continuous improvement. Organizations that implement comprehensive observability gain critical advantages: they detect and resolve issues early in development, verify agents uphold standards of quality and safety, optimize performance in production, and maintain trust and accountability.
Maxim AI provides the unified platform that AI engineering and product teams need to ship reliable agents more than 5x faster. By integrating experimentation, simulation, evaluation, observability, and data curation into a single workflow, Maxim enables teams to move from "usually works" to "never breaks."
Ready to build production-ready AI agents with confidence? Schedule a demo to see how Maxim's end-to-end platform accelerates AI agent development, or sign up today to start testing your agents.