A Complete Guide to Tracing and Evaluating RAG Pipelines

Retrieval-Augmented Generation (RAG) is a powerful technique that enhances large language models (LLMs) by connecting them to external knowledge sources. First introduced in a 2020 research paper by Meta AI, this approach allows AI applications to provide more accurate, current, and contextually relevant responses. While RAG pipelines offer significant advantages, their multi-stage nature introduces complexity in debugging and performance assessment. Effectively evaluating RAG pipelines is crucial for building reliable and trustworthy AI.
This guide provides a comprehensive framework for tracing and evaluating your RAG pipelines. We will explore the inherent challenges, common failure points, the critical role of tracing for diagnostics, and the key metrics for robust evaluation. We'll also see how a unified platform can streamline this entire process, helping you ship dependable AI agents faster.
Why is Evaluating RAG Systems So Challenging?
Evaluating a RAG pipeline is not a simple task. The quality of the final output depends on a sequence of interconnected components, each with its own potential for failure. An inaccurate or irrelevant response could stem from issues at any point, making diagnostics a complex undertaking.
A typical RAG pipeline consists of several stages, each of which must perform optimally.
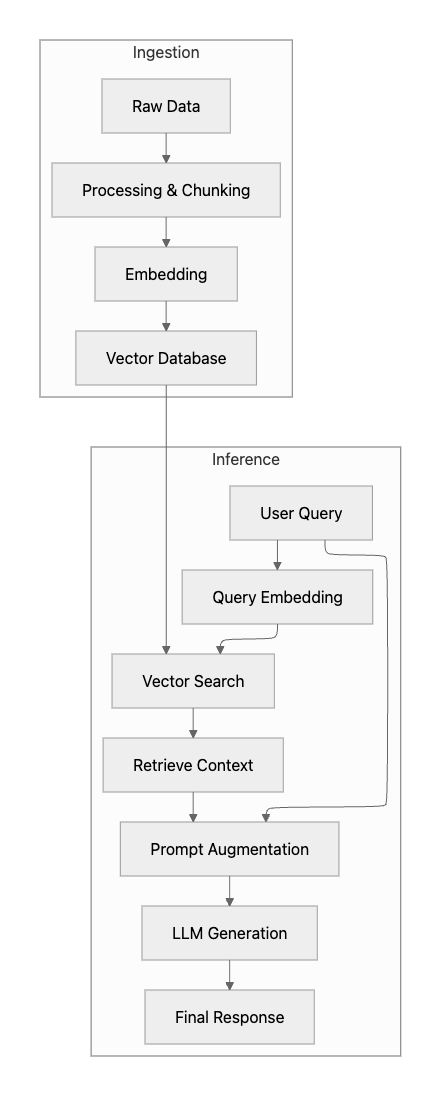
failure at any of these points can compromise the quality of the final output. For instance, poor-quality retrieval will lead to a poor-quality response, regardless of how capable the generation model is.
Common Pitfalls in RAG Evaluation
Several core challenges make evaluating RAG systems difficult:
- The Composite Nature: A RAG system is a pipeline. Pinpointing the exact source of an error requires evaluating each component both individually and as part of the whole system. A single end-to-end score can hide underlying problems in the retrieval or generation stage.
- Defining and Measuring "Relevance" and "Faithfulness": Quantifying subjective qualities is a major hurdle. How well does the retrieved context relate to the query (relevance)? And how factually consistent is the generated answer with that context (faithfulness)? These concepts are notoriously difficult to measure with simple metrics.
- Lack of Comprehensive Ground Truth Datasets: Creating high-quality evaluation datasets that include user queries, ideal retrieved passages, and reference answers is a significant and resource-intensive effort. Without this ground truth, automated evaluation becomes much harder.
- Scalability and Cost: Thorough evaluation, especially when it involves human review for nuanced quality checks, can be expensive and time-consuming. Automating this process without sacrificing quality is a key goal for teams building with RAG.
Common RAG Pipeline Failure Points
To effectively evaluate a RAG system, you must first understand where it can break. Failures often occur in one of four key areas:
- Context Retrieval is Irrelevant (Low Precision): The retriever pulls documents that are not relevant to the user's query. This is often the most common failure mode and leads the LLM to generate answers based on incorrect or unrelated information.
- Context Retrieval is Incomplete (Low Recall): The retriever fails to pull all the necessary documents required to answer the query completely. This results in answers that are factually correct but missing key information, leading to an incomplete or misleading picture for the user.
- Generator Ignores Context: The retrieved context is perfect, but the LLM fails to use it properly in its response. The model might revert to its parametric knowledge, leading to an answer that doesn't reflect the provided documents.
- Generator Hallucinates or Extracts Incorrectly: The LLM either fabricates information that isn't supported by the retrieved context (hallucination) or misinterprets the information during the generation process. This directly undermines the trustworthiness of the application.
Identifying which of these failures is occurring is the first step toward fixing it. This is where tracing becomes indispensable.
What is Tracing in RAG and Why is it Critical?
To effectively debug and optimize RAG pipelines, you need deep visibility into each stage of the process. This is where tracing comes in. Tracing provides a detailed, end-to-end view of a request's journey through the entire pipeline, from the initial user query to the final generated response.
An LLM trace is a structured log that captures every significant step, or "span," in the workflow. It records intermediate operations like retrieval calls, prompt construction, and model invocations, along with their inputs, outputs, and latency.
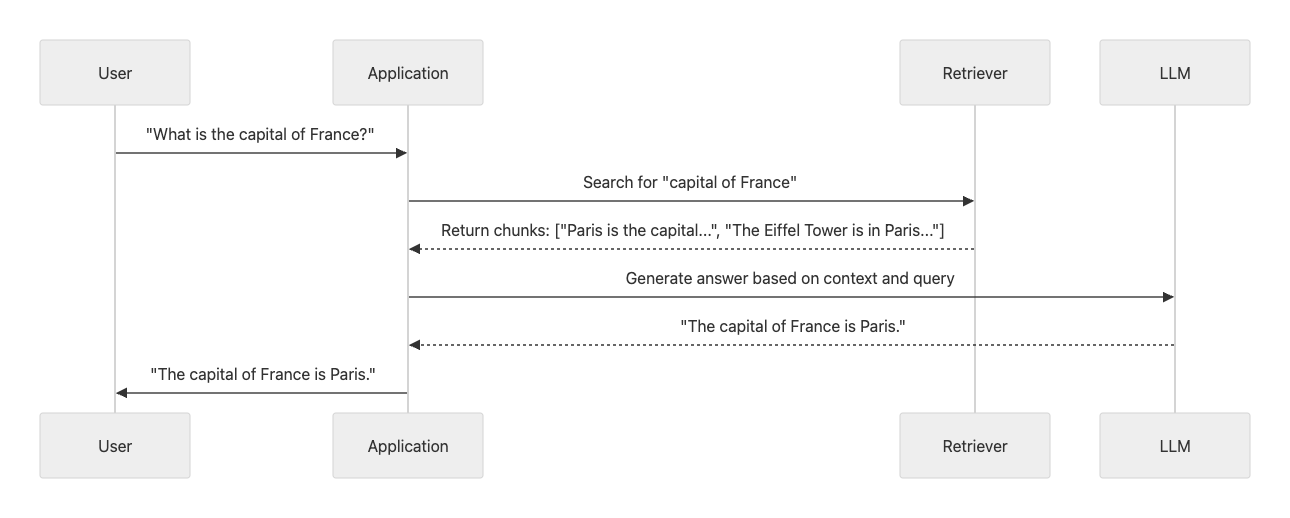
This granular view allows you to:
- Pinpoint Failure Points: By examining the inputs and outputs of each stage, you can quickly identify where a problem occurred. A trace can immediately reveal if the retriever fetched irrelevant documents or if the generator ignored the provided context.
- Optimize Performance: Tracing helps identify latency bottlenecks. By analyzing the time taken for each span, you can determine which components are slowing down the overall response time, whether it's the vector search or the LLM generation.
- Debug Complex Interactions: In complex RAG systems with multiple retrievers or post-processing steps, tracing provides a holistic view that is often lost with traditional logging. This is crucial for understanding how different components interact and influence the final output.
Key Metrics for Mastering RAG Performance
Evaluating RAG pipelines requires a combination of retrieval-focused, generation-focused, and end-to-end metrics to measure performance accurately. A robust evaluation framework should incorporate a variety of these metrics to provide a complete picture of system quality.
Retrieval-Focused Metrics
These metrics evaluate the quality of the information retrieved from the knowledge base before it ever reaches the LLM.
- Context Precision: This measures the signal-to-noise ratio of the retrieved contexts. It asks: of the documents retrieved, how many are actually relevant to the query? High precision means the retriever is not fetching irrelevant junk.
- Context Recall: This metric assesses whether all the necessary information to answer the query was present in the retrieved contexts. High recall means the retriever is successfully finding all the relevant pieces of information from the knowledge base.
- Mean Reciprocal Rank (MRR): MRR evaluates how high up in the ranking the first relevant document appears. It is particularly useful when you expect one single best document to answer the query.
- Normalized Discounted Cumulative Gain (NDCG): For more complex queries where multiple documents contribute to the answer, NDCG is a more sophisticated ranking metric. It considers the position and relevance of all retrieved documents, giving more weight to highly relevant documents that appear higher in the search results. You can find a detailed technical explanation of NDCG on resources like the Wikipedia page for the metric.
Generation-Focused Metrics
These metrics evaluate the quality of the LLM's generated response, based on the context it was given.
- Faithfulness: This measures the factual consistency of the generated answer against the retrieved context. It is one of the most important metrics for identifying hallucinations. A common technique for measuring faithfulness is to use another powerful LLM as a judge to verify that every claim in the generated answer is supported by the provided context.
- Answer Relevancy: This assesses how well the generated answer addresses the user's actual question. An answer can be faithful to the context but still fail to be useful if it doesn't directly answer the query.
- Answer Correctness: This evaluates the factual accuracy of the answer against a ground truth or reference answer. This is only possible when a ground truth dataset is available, but it provides a strong signal of overall quality.
End-to-End System Metrics
Finally, these metrics assess the overall user experience and operational efficiency.
- Latency: The total time taken from receiving the user query to delivering the final response is a critical user experience metric.
- Cost: For applications using third-party LLM APIs, tracking the cost per query is essential for managing operational expenses and ensuring the system is economically viable.
Maxim AI: An End-to-End Solution for RAG Pipeline Excellence
Maxim AI offers a comprehensive platform designed to help teams build, evaluate, and monitor their AI agents, including complex RAG pipelines, reliably and efficiently. Our end-to-end approach addresses the entire AI development lifecycle, from initial experimentation to production observability.
Streamlining Evaluation with a Unified Framework
Maxim's evaluation framework provides a unified solution for both machine and human evaluations, allowing you to quantify improvements and regressions with confidence.
- Flexible Evaluators: Access a rich library of pre-built evaluators for metrics like faithfulness, answer relevance, and context precision, or create custom evaluators tailored to your specific needs.
- Visualize and Compare Runs: Easily compare the performance of different pipeline versions across large test suites, visualizing key metrics to make informed decisions about which changes to deploy.
- Human-in-the-Loop: Define and conduct human evaluations for nuanced assessments, ensuring your AI agents align with human preferences and quality standards.
Gaining Deep Insights with Observability and Tracing
Maxim's observability suite empowers you to monitor your RAG pipelines in real-time and debug issues quickly.
- Distributed Tracing: Get a granular, end-to-end view of every request as it flows through your RAG pipeline. Our distributed tracing capabilities allow you to inspect the inputs, outputs, and latency of each component to pinpoint the root cause of any issue.
- Real-Time Monitoring and Alerts: Track key RAG performance metrics in production and set up real-time alerts to be notified of any degradation in quality, minimizing user impact.
Accelerating Development with Simulation and Experimentation
Before deploying your RAG pipeline, it's crucial to test it under a wide range of conditions.
- AI-Powered Simulation: With Maxim's agent simulation capabilities, you can test your RAG agents across hundreds of real-world scenarios, identifying potential failure points before they reach production.
- Advanced Experimentation: Our Playground++ is built for rapid iteration. Compare different retrieval strategies, prompt templates, and LLM parameters to find the optimal configuration for your pipeline.
Conclusion
Tracing and evaluating RAG pipelines are essential disciplines for building reliable, high-performing AI applications. The complexity of these multi-stage systems demands a systematic approach that combines deep visibility through tracing with a robust framework for measuring performance.
By leveraging distributed tracing and a comprehensive suite of evaluation metrics, AI engineering and product teams can effectively debug, optimize, and monitor their RAG pipelines. Platforms like Maxim AI provide the end-to-end tools necessary to streamline this process, enabling teams to ship their AI agents with confidence and speed. To know more on how you can ship reliable AI applications faster, Book a Demo or Sign Up for Maxim AI.