Prerequisites
- Node.js 18+
- OpenAI TypeScript SDK (
npm install openai) - Maxim TypeScript SDK (
npm install @maximai/maxim-js) - API keys for OpenAI and Maxim
Environment Variables
Initialize Maxim Logger
Wrap OpenAI Client
UseMaximOpenAIClient to wrap your OpenAI client for automatic tracing:
Basic Usage
Make chat completion requests using the wrapped client:Custom Headers for Tracing
You can pass custom headers to enrich your traces:Available Header Options
| Header | Type | Description |
|---|---|---|
maxim-trace-id | string | Link this generation to an existing trace |
maxim-session-id | string | Link the parent trace to an existing session |
maxim-trace-tags | string (JSON) | Custom tags for the trace (e.g., '{"env": "prod"}') |
maxim-generation-name | string | Custom name for the generation in the dashboard |
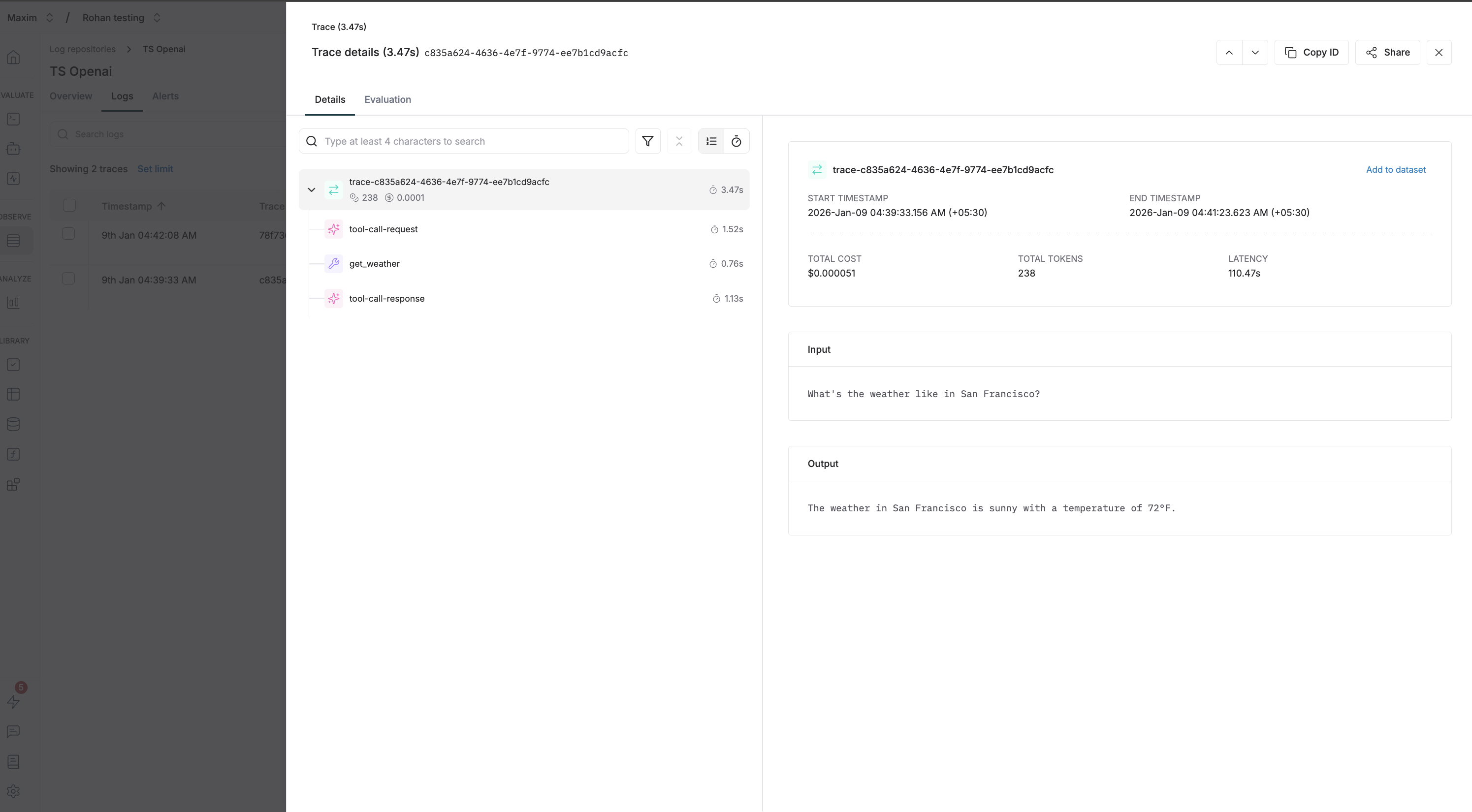
Tool Calling Example
Here’s a complete example demonstrating tool calls with tracing:Grouping Generations with Traces
Use traces to group related generations together:Streaming Support
The wrapped client supports streaming responses:Cleanup
Always clean up resources when done:What gets logged to Maxim
- Request Details: Model name, parameters, and all other settings
- Message History: Complete conversation history including user messages and assistant responses
- Response Content: Full assistant responses and metadata
- Usage Statistics: Input tokens, output tokens, total tokens consumed
- Error Handling: Any errors that occur during the request
Resources
OpenAI Chat Completions
Official OpenAI Chat Completions documentation
Maxim JS SDK
Maxim TypeScript SDK on npm