Requirements
together
maxim-py
python-dotenv
Env Variables
MAXIM_API_KEY=
MAXIM_LOG_REPO_ID=
TOGETHER_API_KEY=
Initialize Logger
from maxim import Maxim
logger = Maxim().logger()
Initialize Together with Maxim Instrumentation
import os
from together import Together
from dotenv import load_dotenv
from maxim import Maxim
from maxim.logger.together import instrument_together
# Load environment variables from .env file
load_dotenv()
# Configure Together & Maxim
TOGETHER_API_KEY = os.getenv('TOGETHER_API_KEY')
MAXIM_API_KEY = os.getenv('MAXIM_API_KEY')
MAXIM_LOG_REPO_ID = os.getenv('MAXIM_LOG_REPO_ID')
# Instrument Together with Maxim
instrument_together(Maxim().logger())
Make LLM Calls Using Together
from together import Together
client = Together(api_key=TOGETHER_API_KEY)
response = client.chat.completions.create(
model="meta-llama/Meta-Llama-3.1-8B-Instruct-Turbo",
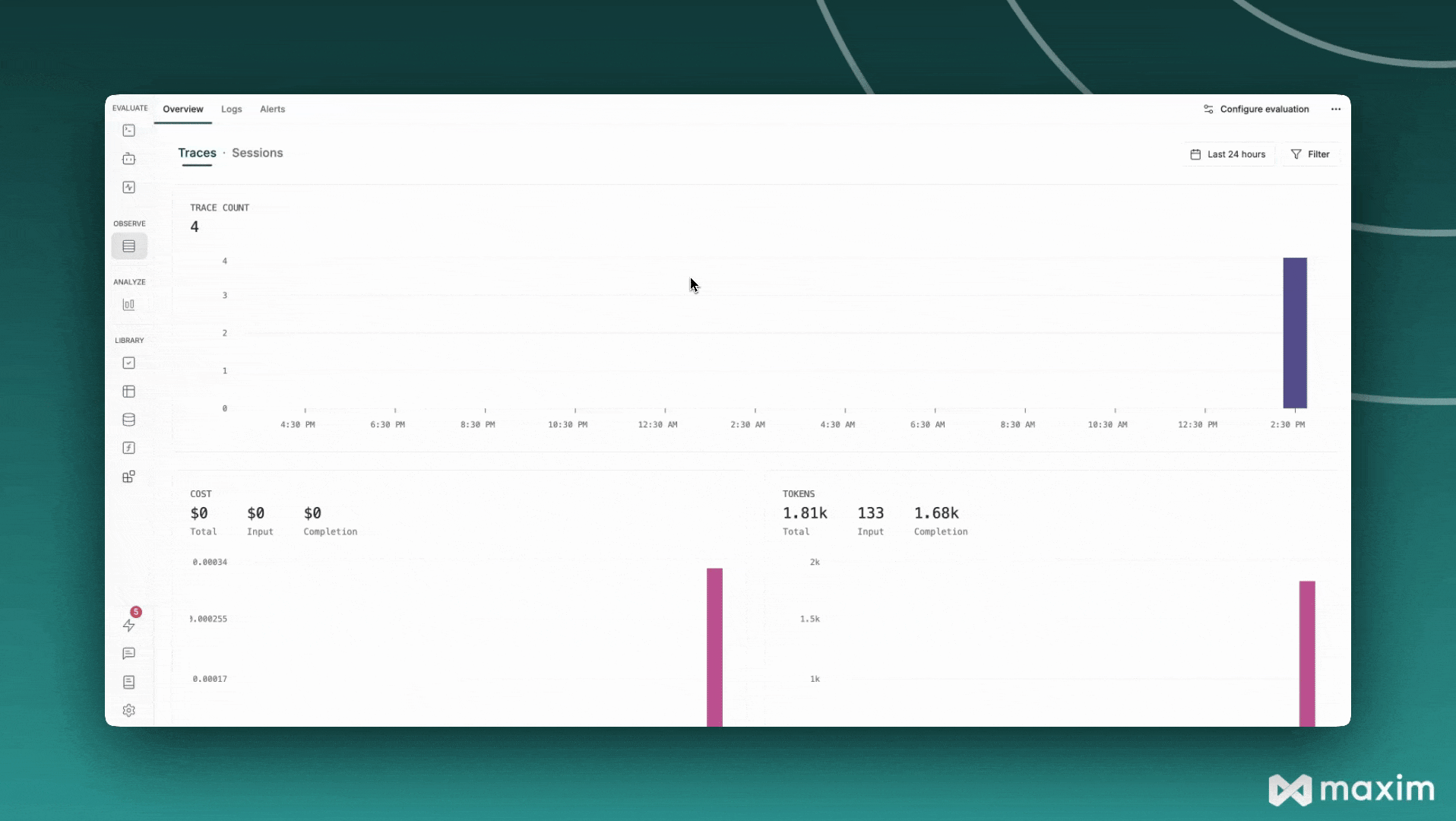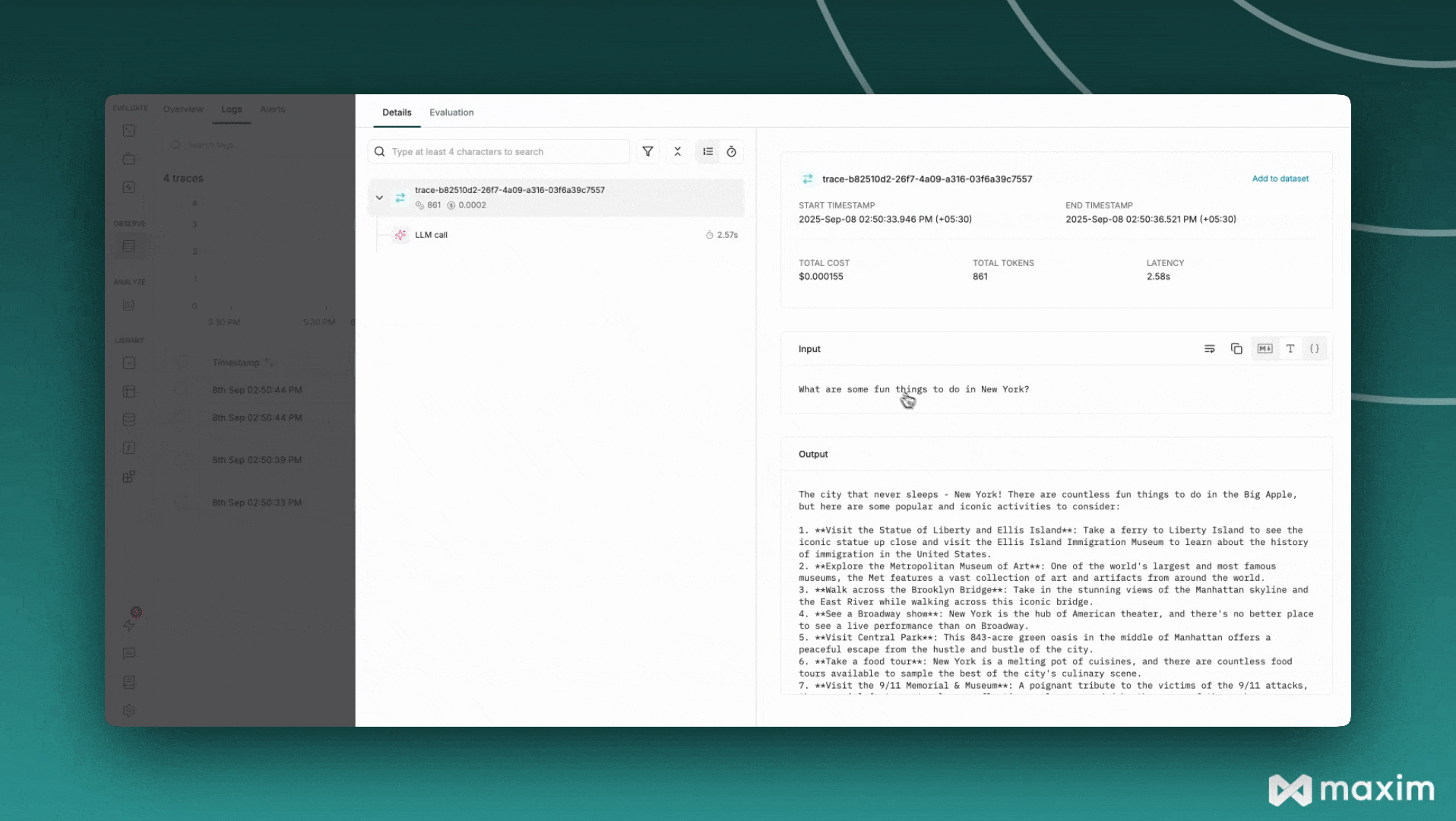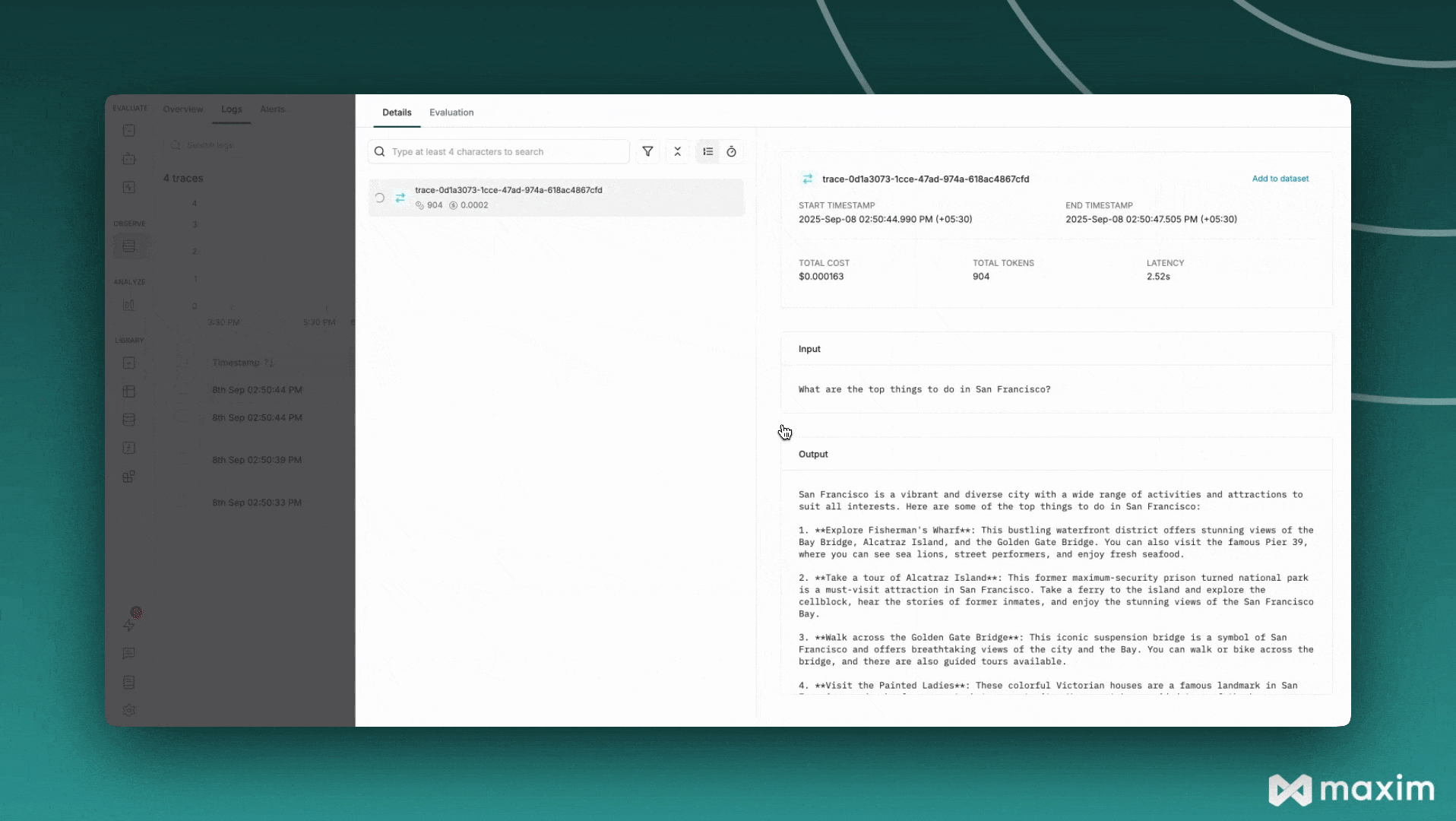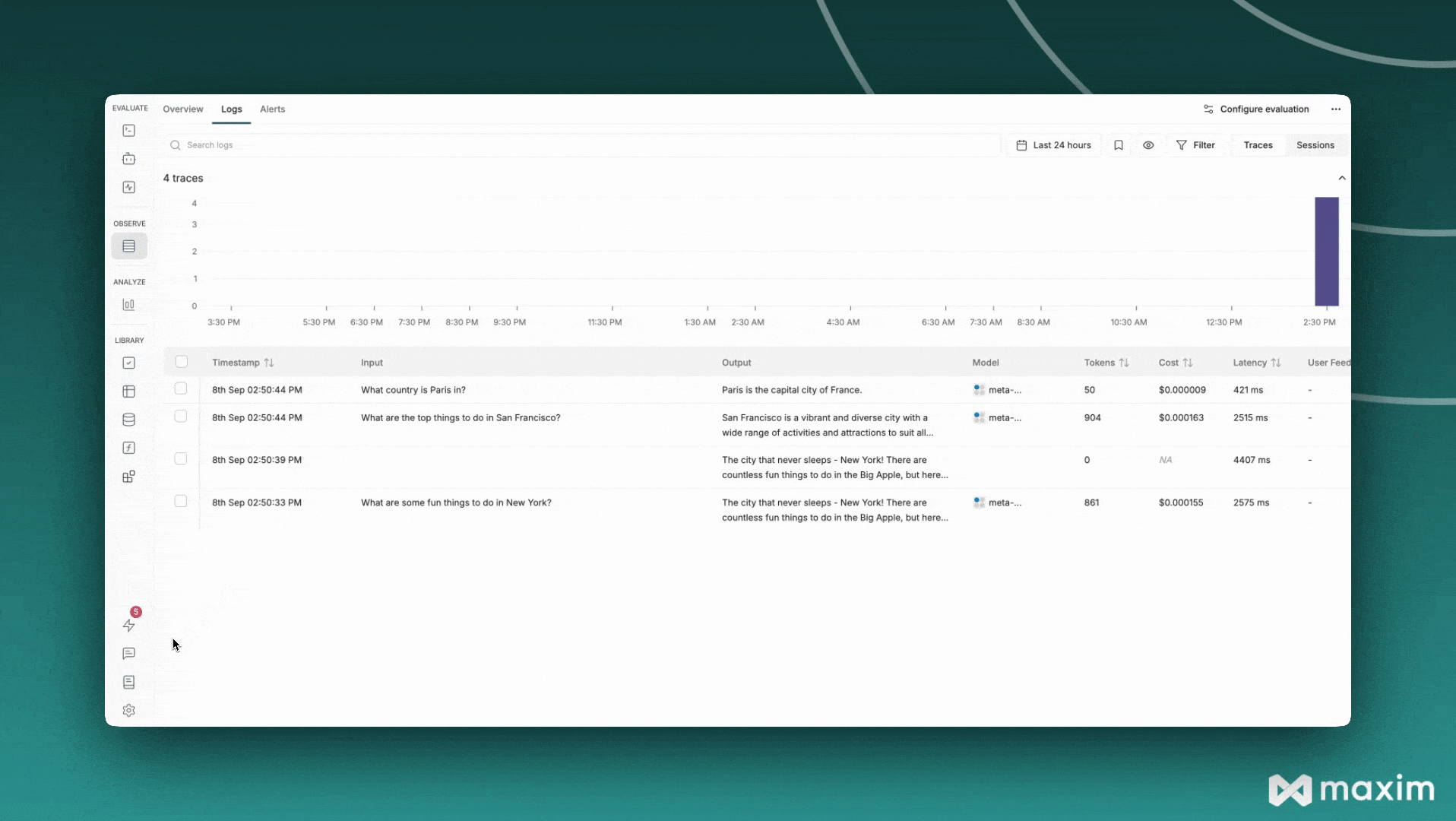
messages=[{"role": "user", "content": "What are some fun things to do in New York?"}],
)
print(response.choices[0].message.content)
Streaming Requests
from together import Together
client = Together(api_key=TOGETHER_API_KEY)
stream = client.chat.completions.create(
model="meta-llama/Meta-Llama-3.1-8B-Instruct-Turbo",
messages=[{"role": "user", "content": "What are some fun things to do in New York?"}],
stream=True,
)
for chunk in stream:
print(chunk.choices[0].delta.content or "", end="", flush=True)
Async Requests
import asyncio
from together import AsyncTogether
async_client = AsyncTogether(api_key=TOGETHER_API_KEY)
async def async_chat_completion():
response = await async_client.chat.completions.create(
model="meta-llama/Meta-Llama-3.1-8B-Instruct-Turbo",
messages=[{"role": "user", "content": "What are the top things to do in San Francisco?"}],
)
print(response.choices[0].message.content)
# Run the async function
asyncio.run(async_chat_completion())
Multiple Async Requests
import asyncio
from together import AsyncTogether
async_client = AsyncTogether(api_key=TOGETHER_API_KEY)
messages = [
"What are the top things to do in San Francisco?",
"What country is Paris in?",
]
async def async_chat_completion(messages):
tasks = [
async_client.chat.completions.create(
model="meta-llama/Meta-Llama-3.1-8B-Instruct-Turbo",
messages=[{"role": "user", "content": message}],
)
for message in messages
]
responses = await asyncio.gather(*tasks)
for response in responses:
print(response.choices[0].message.content)
# Run multiple async requests
asyncio.run(async_chat_completion(messages))